
 商标分类
商标分类  商标转让
商标转让 
一种基于局部保持判别投影的说话人确认方法与流程
 2021-01-28 16:01:54|
2021-01-28 16:01:54| 316|
316| 起点商标网
起点商标网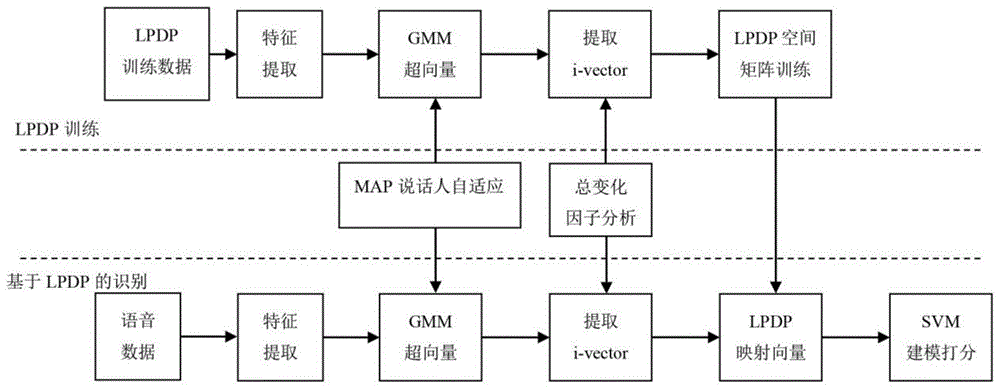
本发明涉及声纹识别技术领域,特别涉及一种基于局部保持判别投影的说话人确认方法。
背景技术:
说话人确认属于说话人识别的一个子任务,其目的在于验证某语音是否由指定的说话人所说。近年来,总变化因子分析被广泛应用于说话人确认。总变化因子分析技术不区分语音中与说话人和信道相关的信息,而将包含这两种影响因子的低维子空间进行总体分析,这个子空间称为总变化空间。通过总变化空间的映射,可以降低高斯混合模型(gaussianmixturemodel,gmm)均值超向量的维数来获得有用的信息,从而利用有限的数据很好地估计潜在变量,这个表征说话人身份的低维变量称为总变化因子向量,即i-vector。后端将i-vector作为输入特征,使用支持向量机进行建模和分类判决。
实际上,总变化因子分析仅从语音数据的全局角度进行信息分析,从本质上看只是概率主成分分析(probabilisticprincipalcomponentanalysis,ppca)的应用。为弥补这一不足,局部保持投影(localitypreservingprojection,lpp)、邻域保持嵌入(neighborhoodpreservingembedding,npe)、判别邻域嵌入(discriminantneighborhoodembedding,dne)等流形学习算法被引入到说话人确认中,通过建立包含语音数据集邻域信息的图,从而最优保持语音数据固有的局部邻域关系;结合总变化因子分析,使说话人确认的性能得到了提升。其中,lpp是一种无监督学习算法,在降维过程中不关注训练数据中的说话人标记信息,并且没有利用不同说话人语音数据之间的判别性信息,然而训练数据的说话人标记信息和语音数据的判别信息对说话人确认具有重要意义。
基于i-vector的局部保持投影(lpp)算法
1.总变化因子分析
基于总变化因子空间,语音数据中包含说话人和信道信息的gmm超向量可表示如下:
m=m+tw
其中m是无关于说话人和信道的通用背景模型ubm的均值超向量,t是由总变化矩阵定义的总变化空间,代替分开的说话人空间和信道空间,w是低维潜在变量,服从标准正态分布,称为总变化因子向量(totalvariabilityfactorvector),也称为identityvector,简称i-vector。总变化因子分析可以看作一种特征提取模块,它将语音数据投影到低阶的总变化空间t中,得到关于说话人和信道的总变化因子向量w。
2.局部保持投影算法(lpp)
给定n个训练语音数据,w={w1,w2,…,wn},其中wi∈rd,i=1,2,…,n。wi是第i条语音数据对应的i-vector。lpp的目的在于,寻求一个能构建空间中各数据之间近邻关系的最佳投影矩阵p=[p1,p2,…,pk],将语音在空间rd中的i-vector嵌入投影到一个更低维的特征空间rk(k<d)中,且在投影过程中,使语音数据间的局部邻域关系得到最优保留。在rk空间中,语音数据点wi变换成局部保持投影向量xi,且xi=ptwi。
在将局部保持投影向量作为输入特征,并经过类内协方差规整(within-classcovariancenormalization,wccn)和线性判别分析(lineardiscriminantanalysis,lda)对信道进行补偿后,利用支持向量机(supportvectormachine,svm)进行建模和分类判决。
在i-vector基础上使用lpp算法,实现总变化因子分析技术与lpp算法的有效结合,使语音数据样本的全局结构和局部邻域结构都得到保留,因此系统的识别性能会有显著提升。但lpp算法在降维过程中,没有利用语音数据已知的说话人标记信息,因此局部保持投影空间矩阵p虽具有较强的描述性,但判别能力不强,从而对系统的识别性能有一定程度影响。
技术实现要素:
本发明针对现有技术的缺陷,提供了一种基于局部保持判别投影的说话人确认方法,解决了现有技术中存在的缺陷。
为了实现以上发明目的,本发明采取的技术方案如下:
一种基于局部保持判别投影的说话人确认方法,包括:给定n个具有身份信息标记的训练语音数据,其对应的i-vector构成向量集w={w1,w2,…,wn},其中wi∈rd,i=1,2,…,n。lpdp的目的在于,寻求一个最优的局部保持判别投影空间矩阵a=[a1,a2,…,ak],将语音在空间rd中的i-vector嵌入投影到更低维的特征空间rk(k<d)中。在rk空间中语音数据点xi变换为yi,且yi=atwi。
进一步地,所述局部保持判别投影空间矩阵a的训练步骤如下:
步骤1:确定语音数据样本wi的邻域。wi的邻域由所有与wi的相似度小于其平均相似度的语音数据样本点构成,即
其中ms(wi)为wi与所有语音数据样本点的平均相似度,n(wi)表示wi的邻域语音数据样本点。
步骤2:构建邻域图的两个子图:类内图gin和类外图gout。类内图gin由每个语音数据样本点及其邻域内同类(同一说话人)语音数据样本点构成;类外图gout由每个语音数据样本点及其邻域内不同类(不同说话人)语音数据样本点构成。
步骤3:计算类内图gin和类外图gout中每条边上的权重,进而得到类内图权重矩阵win和类外图权重矩阵wout。
(a)在类内图gin中,语音数据样本点wi和wj之间边上的权重记为
(b)在类外图gout中,语音数据样本点wi和wj之间边上的权重为
其中spk(wi)表示语音数据样本wi的说话人标注信息,t取所有语音数据样本点对距离的均值。
步骤4:计算局部保持判别投影变换矩阵a。lpdp的思想是,在嵌入空间中,同一说话人的语音数据样本投影后类内散度最小,即同一说话人的语音数据样本之间距离尽可能小;不同说话人的语音数据样本投影后类间散度最大,即不同说话人的语音数据样本尽可能彼此远离。为达到的这两个目标,整合成以下两个最优化问题:
其中lin=din-win为类内图的拉普拉斯算子,din为对角阵,
利用约束条件atxdoutxta=i,可将(5)和(6)整合为一个最优化问题:
该最优化问题可进一步向广义特征值求解问题转化,即
xhxta=λxdoutxta(8)
通过求解式(8),可获得局部保持判别投影空间矩阵a=[a1,a2,...,ak],其中,a1,a2,…,ak是上述问题中对应于前k个最大特征值的特征向量。
与现有技术相比,本发明的优点在于:
保持同一说话人语音数据固有的流形局部结构,缩小同一说话人语音数据间的距离;同时扩大不同说话人语音数据之间的距离,增强嵌入空间的判别能力。
附图说明
图1是本发明实施例说话人确认方法的流程图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下根据附图并列举实施例,对本发明做进一步详细说明。
如图1所示,局部保持判别投影(lpdp)是一种有效的流形学习方法,已在人脸识别中成功应用。lpdp的基本思想是,将lpp算法中的最近邻域图分为类内图和类外图两种,保持同一说话人语音数据的局部邻域关系,缩小同一说话人语音数据样本之间的距离;同时强调不同说话人之间的判别信息,扩大不同说话人语音数据彼此的距离。结合总变化因子分析,一方面可以将语音数据的特征结构从全局和局部更全面地解析;同时又能体现不同说话人语音数据之间的差异,增强了嵌入空间的判别能力。
将lpdp应用于说话人确认的思路与lpp类似。给定n个具有身份信息标记的训练语音数据,其对应的i-vector构成向量集w={w1,w2,…,wn},其中wi∈rd,i=1,2,…,n。lpdp的目的在于,寻求一个最优的局部保持判别投影空间矩阵a=[a1,a2,…,ak],将语音在空间rd中的i-vector嵌入投影到更低维的特征空间rk(k<d)中。在rk空间中语音数据点xi变换为yi,且yi=atwi。
其中局部保持判别投影空间矩阵a的训练步骤如下:
步骤1:确定语音数据样本wi的邻域。wi的邻域由所有与wi的相似度小于其平均相似度的语音数据样本点构成,即
其中ms(wi)为wi与所有语音数据样本点的平均相似度,n(wi)表示wi的邻域语音数据样本点。
步骤2:构建邻域图的两个子图:类内图gin和类外图gout。类内图gin由每个语音数据样本点及其邻域内同类(同一说话人)语音数据样本点构成;类外图gout由每个语音数据样本点及其邻域内不同类(不同说话人)语音数据样本点构成。
步骤3:计算类内图gin和类外图gout中每条边上的权重,进而得到类内图权重矩阵win和类外图权重矩阵wout。
(a)在类内图gin中,语音数据样本点wi和wj之间边上的权重记为
(b)在类外图gout中,语音数据样本点wi和wj之间边上的权重为
其中spk(wi)表示语音数据样本wi的说话人标注信息,t取所有语音数据样本点对距离的均值。
步骤4:计算局部保持判别投影变换矩阵a。lpdp的思想是,在嵌入空间中,同一说话人的语音数据样本投影后类内散度最小,即同一说话人的语音数据样本之间距离尽可能小;不同说话人的语音数据样本投影后类间散度最大,即不同说话人的语音数据样本尽可能彼此远离。为达到的这两个目标,整合成以下两个最优化问题:
其中lin=din-win为类内图的拉普拉斯算子,din为对角阵,
利用约束条件atxdoutxta=i,可将(5)和(6)整合为一个最优化问题:
该最优化问题可进一步向广义特征值求解问题转化,即
xhxta=λxdoutxta(8)
通过求解式(8),可获得局部保持判别投影空间矩阵a=[a1,a2,...,ak],其中,a1,a2,…,ak是上述问题中对应于前k个最大特征值的特征向量。
实验
1.实验配置
在nistsre2010电话训练、电话测试核心测试集上进行实验,实验将等错误率(equalerrorrate,eer)和最小检测错误代价(minimumdetectcostfunction,mindcf)两个指标作为系统性能的衡量标准.
2.实验结果
为验证本文提出的lpdp算法的性能,将该算法与传统的lpp算法和总变化因子分析算法在测试集上进行了实验比较.
表1给出了三种算法的性能比较.由表1分析可知,将lpp算法作用于i-vector,相当于将总变化因子分析技术与lpp算法有效结合,可以同时保持语音数据样本的全局结构和局部邻域结构,因此相对于只能保持语音数据全局结构的总变化因子分析而言,lpp能使系统性能得到明显提升;lpdp在lpp基础上,有效利用语音数据的说话人标记信息,通过优化,保持同一说话人语音数据固有的流形局部结构,同时扩大不同说话人语音数据之间的距离,增强嵌入空间的判别能力,因此进一步提升了系统性能.相对于lpp,lpdp系统在男、女声测试集上的eer分别降低了16.36%和29.33%,mindcf分别降低了13.04%和8.67%.
表1lpdp、lpp、总变化因子分析的eer和mindcf比较
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的实施方法,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



