
 商标分类
商标分类  商标转让
商标转让 
全连接多尺度的残差网络及其进行声纹识别的方法与流程
 2021-01-28 16:01:44|
2021-01-28 16:01:44| 351|
351| 起点商标网
起点商标网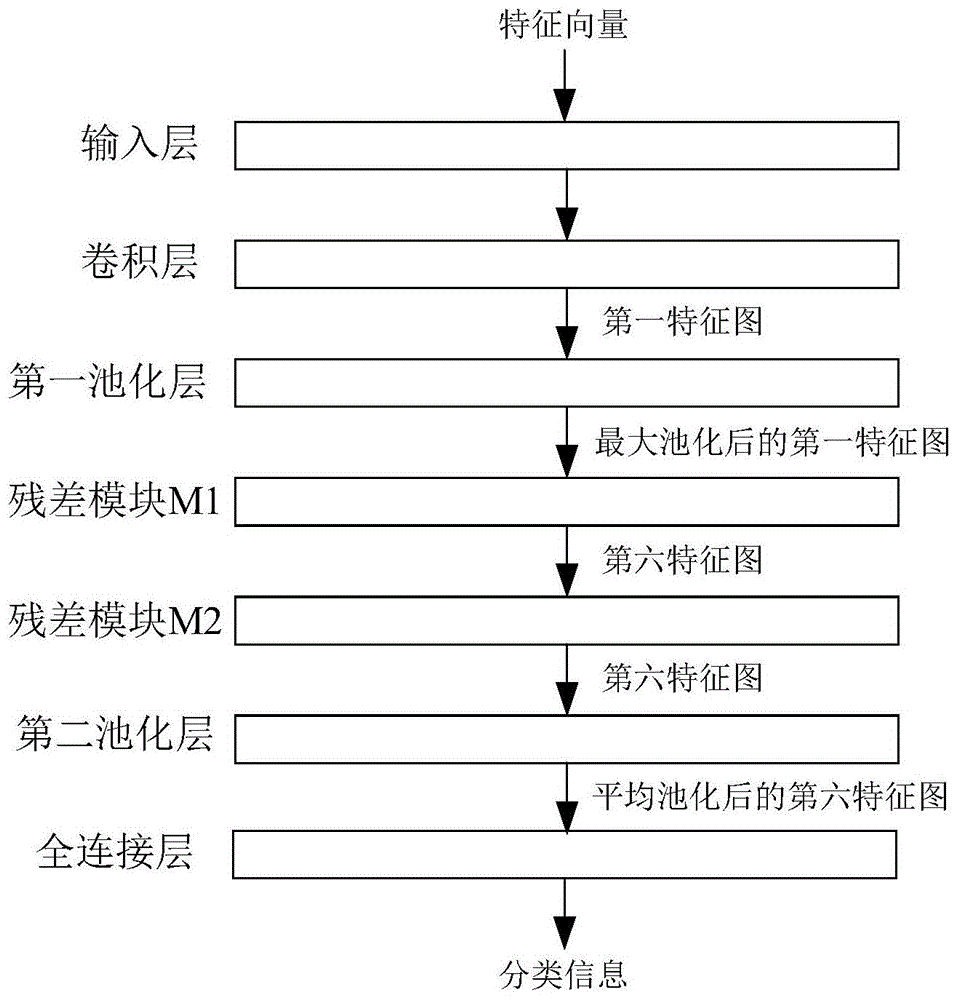
本发明涉及人工智能领域,更具体的说,涉及一种全连接多尺度的残差网络及其进行声纹识别的方法。
背景技术:
在得益于深度学习的帮助,声纹识别技术得到了快速的发展。由于深度神经网络(deepneuralnetwork,dnn)具有较强的抽象表示能力,因而在各种模式识别任务中都有显著的表现。可以把dnn的最后一个隐藏层的输出称为d-vector。类似d-vector的思想,接收时延神经网络(timedelayneuralnetwork,tdnn)最后一个隐藏层的输出并且计算其统计量,称为x-vector,d-vector和x-vector可以作为输入语音帧的说话人身份的表示。
另外,由于卷积神经网络(convolutionalneuralnetwork,cnn)具有多尺度描述图像或者语音特征的能力,在一定程度上优于dnn和tdnn,cnn在声纹识别中的应用也逐渐得到推广。
为了克服因cnn的网络层的数量过多而造成的梯度消失的问题,可以通过由多个残差模块堆叠形成的残差网络(residualnetwork,resnet)实现声纹识别。resnet的每个残差模块中,输入层和输出层之间直接连接。与传统的单向连接的神经网络相比,残差模块的输入层与输出层之间的直接连接,避免了深层网络梯度消失的问题。
希望有一种新的技术方案,以期实现更好的提取声纹特征,从而实现更为准确的声纹识别。
技术实现要素:
本发明的目的是为了解决现有技术中存在的技术问题,可以在不增加网络深度的情况下,更好的提取多尺度的特征,从而实现更为准确的进行声纹识别。
第一方面,本发明提供了一种用于声纹识别的全连接多尺度的残差网络,包括输入层,卷积层,n个依次连接的残差模块,以及全连接层;其中,
所述输入层,用于接收待识别的语音信息对应的特征向量;
所述卷积层,用于对特征向量进行卷积处理以得到第一特征图;
对于n个残差模块中的第i个残差模块,用于:
接收当前特征图,其中,当前特征图为第一特征图,或者为第i-1个残差模块输出的第六特征图,n为大于1的整数,i大于0且不大于n;以及,
根据长度和宽度均为1的第一卷积核,对当前特征图进行卷积处理以得到第二特征图;
将第二特征图划分为至少两个第三特征图,其中所述至少两个第三特征图与存在顺序关系的至少两个第二卷积核一一对应;
针对至少两个第二卷积核中任意的第j个第二卷积核,确定出第j个第二卷积核对应的至少一个第四特征图,并根据第j个卷积核对所述至少一个第四特征图进行卷积处理以得到第五特征图;其中,第j个第二卷积核对应的至少一个第四特征图,包括第j个卷积核对应的第三特征图,以及包括位于第j个第二卷积核之前的每个第二卷积核各自对应的第五特征图;根据长度和宽度均为1的第三卷积核,对所述至少两个第二卷积核各自对应的第五特征图进行卷积处理,得到并输出第六特征图;
所述全连接层,用于根据第n个残差模块输出的第六特征图,预测并输出所述声音信息对应的分类信息,所述分类信息用于指示发出所述声音信息的说话人。
优选地,所述残差网络还包括第一池化层,用于接收来自所述卷积层的第一特征图,对其接收的第一特征图进行最大池化,并将进行最大池化后的第一特征图输出至第一个残差模块。
优选地,所述残差网络还包括第二池化层,用于接收来自第n个残差模块的第六特征图,对其接收的第六特征图进行均值池化,并将进行均值池化后的第六特征图输出至所述全连接层。
另一方面,本发明提供了一种利用全连接多尺度的残差网络进行声纹识别的方法,所述残差网络包括输入层,卷积层,n个依次连接的残差模块,以及全连接层;所述方法包括:
利用所述输入层接收待识别的语音信息对应的特征向量;
利用所述卷积层对特征向量进行卷积处理以得到第一特征图;
依次利用n个残差模块中的第i个残差模块,执行:
接收当前特征图,其中,当前特征图为第一特征图,或者为第i-1个残差模块输出的第六特征图,n为大于1的整数,i大于0且不大于n;以及,
根据长度和宽度均为1的第一卷积核,对当前特征图进行卷积处理以得到第二特征图;
将第二特征图划分为至少两个第三特征图,其中所述至少两个第三特征图与存在顺序关系的至少两个第二卷积核一一对应;
针对至少两个第二卷积核中任意的第j个第二卷积核,确定出第j个第二卷积核对应的至少一个第四特征图,并根据第j个卷积核对所述至少一个第四特征图进行卷积处理以得到第五特征图;其中,第j个第二卷积核对应的至少一个第四特征图,包括第j个卷积核对应的第三特征图,以及包括位于第j个第二卷积核之前的每个第二卷积核各自对应的第五特征图;根据长度和宽度均为1的第三卷积核,对所述至少两个第二卷积核各自对应的第五特征图进行卷积处理,得到并输出第六特征图;
利用所述全连接层根据第n个残差模块输出的第六特征图,预测并输出所述声音信息对应的分类信息,所述分类信息用于指示发出所述声音信息的说话人。
优选地,所述残差网络还包括第一池化层;所述方法还包括:
利用所述第一池化层接收来自所述卷积层的第一特征图,对其接收的第一特征图进行最大池化,并将进行最大池化后的第一特征图输出至第一个残差模块。
优选地,所述残差网络还包括第二池化层;所述方法还包括:
利用所述第二池化层接收来自第n个残差模块的第六特征图,对其接收的第六特征图进行均值池化,并将进行均值池化后的第六特征图输出至所述全连接层。
根据本申请的技术方案,在残差模块中利用包括至少两个第二卷积的卷积核组,替代单个长度和宽度均为3的卷积核,可以更好的提取多尺度的特征。在每个残差模块中,可以将输入的特征图经过长度和宽度均为1的第一卷积核的卷积处理后的输出分成多组(即分成多个第三特征图),连接到后面所有的第二卷积核的输入,最后将经过多个第二卷积核输出的特征图拼接在一起,由长度和宽度均为1的第三卷积核对其进行卷积处理,实现多尺度信息的融合。如此,可以在不增加网络深度的情况下,更好的提取多尺度的特征,从而实现更为准确的进行声纹识别。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例中提供的一种用于声纹识别的全连接多尺度的残差网络的示意图;
图2为本申请实施例中提取语音信息的声学特征的过程示意图;
图3为本申请实施例中残差网络的残差模块处理特征图的过程示意图。
具体实施方式
下面结合附图和实施例,对本发明所提供的技术方案做进一步的详细描述。
图1为本申请实施例中提供的一种用于声纹识别的全连接多尺度的残差网络。如图1所示,该残差网络可以包括输入层,卷积层,n个依次连接的残差模块(也可以被表述为卷积模块),以及全连接层。可选地,该残差网络还可以包括:第一池化层,和/或,第二池化层。其中,为了方便描述,将第一个残差模块表述为残差模块m1,将第n个残差模块表述为残差模块m2,n为大于1的整数。在实际业务场景中,残差模块m1和残差模块m2之间还可以连接一个或多个残差模块。示例性的,该残差网络可以包括50个网络层,每个残差模块包括3个网络层,残差模块m1和残差模块m2之间还可以包括14个依次连接的残差模块。
本申请实施例中,可以按照如下过程训练得到如图1所示的用于声纹识别的全连接多尺度的残差网络。
首先,可以对训练集中的每条语音信息分别进行加噪处理,对未进行加噪处理的语音信息和进行加噪处理后的语音信息,均提取其64维声学特征filterbank(fbank)。
具体地,请参考图2,提取fbank的过程可以包括:
接收输入语音,输入语音可以是训练集中的未进行加噪处理的语音信息,也可以是进行加噪处理后的语音信息。
对输入语音进行预加重,加强高频。
对预加重后的输入语音进行分帧,将不定长度的输入语音切分成固定长度的小段语音帧。
对固定长度的小段语音进行加窗。由于语音在长范围内是不停变动的,没有固定的特性无法做处理,所以将每一帧语音代入窗函数,窗外的值设定为0,其目的是消除各帧语音两端可能会造成的信号不连续性。这样可以降低傅里叶变换后旁瓣的强度,取得更高质量的频谱。
进行快速傅里叶变换(fft),由于进行分帧及加窗后的小段语音信息仍然是时域信号,需要将其转变为频域信号,傅里叶变换将信号转为频域可以将复杂声波分成各种频率的声波,方便神经网络进行学习。最终结果是个频率范围内的重要程度(能量)。
fft后的频域信号进到梅尔滤波器,在mel频谱上进行倒谱分析,获得mel频率倒谱系数mfcc。
对数功率,取mel频率倒谱系数mfcc的对数。
mel频率倒谱系数mfcc的对数提取fbank特征。
接着,统计训练集中所有语音信息的帧长,然后选取(min(1/2max(帧长),min(帧长)),max(1/2max(帧长),min(帧长)))的区间作为块的大小,对每一批大小的语音信息进行特征图输入大小的统一。
接着,在远场场景下,对每一条语音信息的64维声学特征fbank进行随机的特征掩蔽,掩蔽的方法为,对输入特征的数值进行5%到15%范围的随机置零。
接着,搭建初始化的全连接多尺度的残差网络,比如搭建50层的全连接多尺度残差网络(fc-res2net)。
接着,可以根据各语音信息的64维声学特征,采用交叉熵函数(crossentropy)作为损失函数,用随机梯度下降作为优化器,进行梯度计算,同时对损失函数计算出的梯度反向传播,更新残差网络的参数。
表1
如上表1所示,50层fc-res2net的结构可以包含[3,4,6,3]一共16个残差模块。训练过程中,输入层可以将经过随机特征掩蔽过的64维声学特征fbank的特征向量,传入到卷积层进行卷积处理,其中,卷积层的卷积核为长宽尺寸都为7,通道数为16,步长为2的卷积核。卷积处理后得到的特征图进入到第一池化层,进行最大池化处理,其中,最大池化使用的卷积核为长宽尺寸都为3,通道数为16的卷积核。接着,最大池化后的特征图进入第一个残差模块,从第一个残差模块的输入开始,到最后一个残差模块结束,再经过一个二维的第二池化层,这样,一个批(batch)大小的语音信息的所有声学特征被表示成了一个维度是(batchsize)×512维的特征向量。再经过一个全连接的分类层,得到预测的分类信息。
初始化的全连接多尺度的残差网络在经过多次迭代更新之后,即可得到用于进行声纹识别的全连接多尺度的残差网络。
在得到用于进行声纹识别的全连接多尺度的残差网络之后,即可利用该残差网络进行声纹识别。请参考图1,其具体过程可以包括:
首先,对于待识别的语音信息,可以获取该语音信息的64维的特征向量。
接着,可以利用输入层接收待识别的语音信息对应的特征向量,并将特征向量传输至卷积层。
接着,可以利用卷积层对特征向量进行卷积处理以得到第一特征图,并将第一特征图输出至其连接的第一池化层。
接着,可以利用接收来自卷积层的第一特征图,对其接收的第一特征图进行最大池化,并将进行最大池化后的第一特征图输出至第一个残差模块。请参考图1,第一特征图可以被输出至残差模块m1。
接着,请参考图3,利用n个残差模块中的第i个残差模块,执行a1和a2:
a1:接收当前特征图,其中,当前特征图为第一特征图,或者为第i-1个残差模块输出的第六特征图,n为大于1的整数,i大于0且不大于n。示例性的,执行a1的残差模块为残差模块m1,则当前特征图为来自第一池化层的第一特征图;执行a1的残差模块为残差模块m2,则当前特征图为来自第n-1个残差模块的第六特征图。
a2:根据长度和宽度均为1的第一卷积核,对当前特征图进行卷积处理以得到第二特征图。
a3,将第二特征图划分为至少两个第三特征图,其中所述至少两个第三特征图与存在顺序关系的至少两个第二卷积核一一对应。
可以理解,第二卷积核的数量为至少两个,这里并不对第二卷积核的具体数量以及每个第二卷积核的尺寸进行限制。示例性的,第二卷积核的数量可以为4个,每个第二卷积核的长度和宽度均为3。
以存在顺序关系的至少两个第二卷积核依次为第二卷积核f1、f2、f3、f4共4个卷积核为例,可以将第二特征图依次划分为4组,或者说将第二特征图划分为4个第三特征图。这样,可以得到f1对应的第三特征图x1,f2对应的第三特征图x2,f3对应的第三特征图x3,f4对应的第三特征图x4。
a4:针对至少两个第二卷积核中任意的第j个第二卷积核,确定出第j个第二卷积核对应的至少一个第四特征图,并根据第j个卷积核对所述至少一个第四特征图进行卷积处理以得到第五特征图;其中,第j个第二卷积核对应的至少一个第四特征图,包括第j个卷积核对应的第三特征图,以及包括位于第j个第二卷积核之前的每个第二卷积核各自对应的第五特征图。
请参考图3,对于第一个第二卷积核f1,其对应的至少一个第四特征图可以包括其自身对应的第三特征图x1;根据f1对x1进行卷积处理,可以得到f1对应的第五特征图y1。对于第二个第二卷积核f2,其对应的至少一个第四特征图可以包括其自身对应的第三特征图x2,以及f1对应的第五特征图y1;根据f2对x2和y1进行卷积处理,可以得到f2对应的第五特征图y2。对于第三个第二卷积核f3,其对应的至少一个第四特征图可以包括其自身对应的第三特征图x3,以及f1对应的第五特征图y1、f2对应的第五特征图y2;根据f3对x3、y1和y2进行卷积处理,可以得到f3对应的第五特征图y3。对于第四个第二卷积核f4,其对应的至少一个第四特征图可以包括其自身对应的第三特征图x4,以及f1对应的第五特征图y1、f2对应的第五特征图y2、f3对应的第五特征图y3;根据f4对x4、y1、y2和y3进行卷积处理,可以得到f4对应的第五特征图y4。
a5:根据长度和宽度均为1的第三卷积核,对所述至少两个第二卷积核各自对应的第五特征图进行卷积处理,得到并输出第六特征图。示例性的,可以对第二卷积核x1对应的第五特征图y1、第二卷积核x2对应的第五特征图y2、第二卷积核x3对应的第五特征图y3以及第二卷积核x4对应的第五特征图y4进行卷积处理,得到并输出第六特征图。
接着,利用第二池化层接收来自第n个残差模块的第六特征图,对其接收的第六特征图进行均值池化,并将进行均值池化后的第六特征图输出至所述全连接层。
最后,利用所述全连接层根据第n个残差模块输出的第六特征图,预测并输出所述声音信息对应的分类信息,所述分类信息用于指示发出所述声音信息的说话人。
在此处所提供的说明书中,说明了大量的具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下完成实现。在一些示例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若对本发明的这些修改和变型属于本发明权利要求及其同等技术的范围之内,则本发明也意图包含这些改动和变型在内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



