
 商标分类
商标分类  商标转让
商标转让 
基于多路声学特征数据增强的声场景分类方法与流程
 2021-01-28 16:01:48|
2021-01-28 16:01:48| 300|
300| 起点商标网
起点商标网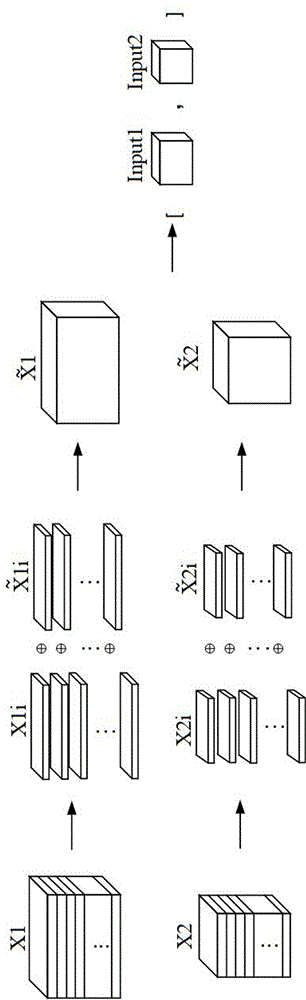
本发明涉及声场景分类技术领域,具体为基于多路声学特征数据增强的声场景分类方法。
背景技术:
现代社会中,声场景分类在许多领域中应用,如城市噪音监控,消防预警,健康状况检测等方面。声学场景分类旨在将采集到的声音按照预先定义的类别进行分类,以供后续处理。现有的声场景分类计数中,已经有科研人员做了多方面的研究;比如申请号为201910845467.9的发明专利公开一种基于网络模型融合的声场景分类方法,其重点在于模型的融合,而在输入端只采用了两种声学特征,以单输入的方式进行训练,导致其声学特征互补能力并不显著,分类精度不足的模型在实际应用中,会导致分类结果不准确;申请号为201910201430.2的发明专利公开一种基于数据增强的声场景辨识方法,其数据增强方法是基于混合增强方法提出的,但其提取的声学特征较为单一,不能探究多种声学特征对模型分类能力的影响;泛化能力不强的模型在实际应用中,会出现分类准确率不稳定,或者应用场景单一的问题。
技术实现要素:
为了解决现有技术中声场景分类存在的分类精度不足、泛化能力不够,导致在实际应用中分类结果不准确、应用场景单一的问题,本发明提供基于多路声学特征数据增强的声场景分类方法,其提高了声场景分类用分类器的准确率,同时提高了模型的泛化能力,使其能够以稳定的分类准确率应用在更多的场景中。
本发明的技术方案是这样的:基于多路声学特征数据增强的声场景分类方法,其包括以下步骤:
s1:采集待分类的原始音频样本信息,其中包括音频时长和采样频率,并对其进行预处理,获得待处理样本信息;
其特征在于,其还包括一下步骤:
s2:对所述待处理样本信息进行傅里叶变换处理后,输入到用于提取声学特征的滤波器,得到所述待处理样本信息对应的待分类样本声学特征;
s3:将所述待分类样本声学特征的数据输入到数据增强用特征生成器;
所述数据增强用特征生成器中,设置n种声学特征作为声场景分类模型的输入,且每一种声学特征对应分类模型的一个输入模块;所述数据增强用特征生成器的输出为:数据增强后特征向量
所述数据增强用特征生成器基于mixup数据增强方式,对输入的所述待分类样本声学特征的数据进行特征增强操作;输入的声学特征数据经过分批处理后生成虚拟样本,然后通过迭代器将虚拟样本图层合并到数据增强后的特征图层中,得到最终的所述数据增强后特征向量;
s4:构建声场景分类模型;
基于mcnn模型构建多支路的所述声场景分类模型;
所述声场景分类模型包括:支路网络,多个所述支路网络输出后,经融合层的concatenate合并级联处理,经主全连接层后,通过softmax函数输出分类预测;
基于vgg网络模型构建所述声场景分类模型的每个支路网络模型;
所述支路网络模型包括:三个卷积块、一个支路全连接块;
所述卷积块包括:两个卷积层、两个br层、一个最大池化层;
s5:训练所述声场景分类模型,得到训练好的所述声场景分类模型;
s6:将步骤s3中获得的所述数据增强后特征向量输入到训练好的所述声场景分类模型中,进行场景分类筛选,输出对应的最终分类预测结果。
其进一步特征在于:
步骤s2中,所述待分类样本声学特征的数据结构为二维向量,第一维数据表征音频样本的帧数信息,第二维数据表征音频样本经过特定的声学特征提取处理后的特征信息;
步骤s2中,所述滤波器提取所述待分类样本声学特征的方案包括:
设:所述待分类样本声学特征为n路,则有:
n=1时的声学特征选取方案如下:
(1)[128维log-mel语谱图]
(2)[128维gamma-tone语谱图]
(3)[174维mfcc]
(4)[174维gfcc]
n=2时的声学特征组合方案如下:
(1)[128维log-mel语谱图,174维mfcc]
(2)[128维log-mel语谱图,128维gamma-tone语谱图]
(3)[128维log-mel语谱图,128维gfcc]
n=3时的声学特征组合方案如下:
(1)[128维log-mel语谱图,174维mfcc,128维fbank]
(2)[128维log-mel语谱图,174维mfcc,128维gamma-tone语谱图]
(3)[128维log-mel语谱图,174维mfcc,128维gfcc];
步骤s3中,n种声学特征经过数据增强后的所述数据增强后特征向量表达式为:
其中:
j=i+1,n、i、j为正整数,λ∈(0,1),xni表示第n种声学特征的第i批数据,xnj表示第n种声学特征的第j批数据,
所述卷积块中的br层包括:批归一化batch-normalization层、激活函数rectifiedlinearunit;
所述卷积块中的最大池化maxpooling层是一种通过缩小特征尺寸来减少模型参数的方式;
所述支路全连接块是利用flatten()函数将卷积操作后的特征图层扁平化为一维数据,并在扁平化处理后,经全连接层后,再将数据通dropout处理;
三个所述卷积块中,卷积核步长设置为1,卷积核通过均匀扫过特征图来实现卷积操作;
第一个所述卷积块中,两个卷积层的通道数为32,卷积核尺寸为3×3,,池化尺寸为4×4;
第二个所述卷积块中,两个卷积层的通道数为64,池化尺寸为3×3;
第三所述卷积块中,两个卷积层的两个通道数为128,池化尺寸为3×3;
所述声场景分类模型中,包括三个所述支路网络;
步骤s6中,将所述数据增强后特征向量输入到训练好的所述声场景分类模型中之前,在所述数据增强后特征向量的数据维度基础上,增加一维通道数,然后再输入到所述声场景分类模型中;
步骤s1中,所述预处理包括:预加重处理、分帧、加窗。
本发明提供的基于多路声学特征数据增强的声场景分类方法中,基于mixup数据增强方式实现数据增强用特征生成器,同时生成多种声学特征,扩充了样本数据量,从样本增强的角度,提高了分类器的泛化能力;基于mcnn模型构建了多支路的声场景分类模型,通过多路声学特征并行输入分类器进行分类操作,使得多种声学特征相互补充提高了分类器的分类精度;数据增强用特征生成器和多支路的所述声场景分类模型的结合使用,不但提升了分类器的准确率,而且提高了分类器的泛化能力,使本发明技术方案中的声场景分类方法适用于各种场景。
附图说明
图1为基于本发明技术方案的双路声学特征数据生成原理示意图;
图2为本发明中声场景分类模型的支路网络的网络结构示意图;
图3为本发明中声场景分类模型中融合层的网络结构示意图;
图4为实施例中三路特征并行输入的主体网络连接示意图。
具体实施方式
如图1~图4所示,本发明基于多路声学特征数据增强的声场景分类方法,其包括以下步骤。
s1:采集待分类的原始音频样本信息,其中包括音频时长和采样频率,并对其进行预处理,获得待处理样本信息;
预处理包括:预加重处理、分帧、加窗等处理操作;通过分帧操作将连续的音频信号转化为离散信号,通过加窗操作使这些离散信号具有较好的连续性。
s2:对待处理样本信息进行傅里叶变换处理后,输入到用于提取声学特征的滤波器,得到待处理样本信息对应的待分类样本声学特征;
待分类样本声学特征的数据结构为二维向量,第一维数据表征音频样本的帧数信息,第二维数据表征音频样本经过特定的声学特征提取处理后的特征信息;
滤波器提取待分类样本声学特征的方案包括:
设:待分类样本声学特征为n路,则有:
n=1时的声学特征选取方案如下:
(1)[128维log-mel语谱图]
(2)[128维gamma-tone语谱图]
(3)[174维mfcc]
(4)[174维gfcc]
n=2时的声学特征组合方案如下:
(1)[128维log-mel语谱图,174维mfcc]
(2)[128维log-mel语谱图,128维gamma-tone语谱图]
(3)[128维log-mel语谱图,128维gfcc]
n=3时的声学特征组合方案如下:
(1)[128维log-mel语谱图,174维mfcc,128维fbank]
(2)[128维log-mel语谱图,174维mfcc,128维gamma-tone语谱图]
(3)[128维log-mel语谱图,174维mfcc,128维gfcc]。
s3:将待分类样本声学特征的数据输入到数据增强用特征生成器;
数据增强用特征生成器中,设置n种声学特征作为声场景分类模型的输入,且每一种声学特征对应分类模型的一个输入模块;数据增强用特征生成器的输出为:数据增强后特征向量;
数据增强用特征生成器基于mixup数据增强方式,对输入的多路待分类样本声学特征的数据进行特征增强操作;
本发明技术方案中,数据增强用特征生成器以n路待分类样本声学特征为输入数据,每一种声学特征对应声场景分类模型的一个输入模块;
输入的声学特征数据经过分批处理后生成虚拟样本,然后通过迭代器将虚拟样本图层合并到数据增强后的特征图层中,得到最终的数据增强后特征向量;
n种声学特征经过数据增强后的数据增强后特征向量表达式为:
其中:
j=i+1,n、i、j为正整数,λ∈(0,1),xni表示第n种声学特征的第i批数据,xnj表示第n种声学特征的第j批数据,
如图1为本发明中双路声学特征数据生成原理示意图,以上式中n=2的情况进行说明,其中x1、x2是两种声学特征的原始图层,经过分批处理后得到x1i和x2i,各自通过生成虚拟样本得到
s4:构建声场景分类模型;
基于mcnn模型构建多支路的声场景分类模型;mcnn网络的主体是由多特征并行部分和特征融合部分构成,多特征并行部分的网络架构是由输入的声学特征的种类数决定的;
声场景分类模型包括:支路网络,多个支路网络输出后,经融合层的concatenate合并级联处理,经主全连接层后,通过softmax函数输出分类预测;
其中,softmax函数的计算公式为:
基于vgg网络模型构建声场景分类模型的每个支路网络模型;
支路网络模型包括:三个卷积块、一个支路全连接块;
卷积块包括:两个卷积层、两个br层、1个最大池化层;
卷积块中的br层包括:批归一化batch-normalization层、激活函数rectifiedlinearunit(简称relu),
其中,函数relu的计算公式为:
卷积块中的最大池化maxpooling层是一种通过缩小特征尺寸来减少模型参数的方式;
支路全连接块是利用flatten()函数将卷积操作后的特征图层扁平化为一维数据,并在扁平化处理后,经全连接层后,再将数据通过dropout处理,舍弃部分数据来降低模型出现过拟合的风险。
如图2所示实施例,三个卷积块中,卷积核步长设置为1,卷积核通过均匀扫过特征图来实现卷积操作;第一个卷积块中,两个卷积层的通道数为32,卷积核尺寸为3×3;第二个卷积块中,两个卷积层的通道数为64,池化尺寸为3×3;第三卷积块中,两个卷积层的两个通道数为128;输入的特征数据(input),经过连续的三个卷积块处理后,输出长度为256的一维特征数据。
如图3所示,本实施例中的声场景分类模型中,包括四个支路网络;
四个支路网络输出的四路特征数据从支路全连接块输出后,经过融合层的concatenate处理,将四个长度为256的一维特征数据拼接成一个长度为1024的合成特征数据,然后将合并后的特征数据再通过全连接处理,得到长度为256的一维特征数据,送入dropout处理来降低模型过拟合的概率,最后通过归一化指数函数softmax处理后,输出最终分类预测结果。
s5:训练声场景分类模型,得到训练好的声场景分类模型。
s6:将步骤s3中获得的数据增强后特征向量在原有数据维度基础上增加一维通道数,将二维特征向量扩展为三维向量,即,原有二维数据:第一维数据表征音频样本的帧数信息、第二维数据表征音频样本经过特定的声学特征提取处理后的特征信息的基础上添加1维通道数来适应网络中的卷积操作,然后输入到训练好的声场景分类模型中,进行场景分类筛选,输出对应的最终分类预测结果。
如图4所示,为本发明中主体网络的连接示意图,以三种声学特征数据并行输入为例进行说明。三种声学特征,即n=3,根据步骤s2中的声学特征组合方案中,n=3时的有三种方案,实时是任选一种都可以;本实施例中选取第三种方案,即:分别选取128维log-mel语谱图、174维mfcc,以及128维gfcc,作为三个支路网络的输入;
其中:mfcc特征向量的尺寸为(174,174),log-mel语谱图特征向量的尺寸为(174,128),gfcc特征向量的尺寸为(173,128)。
经过数据增强用特征生成器处理过的数据增强后特征向量输入到声场景分类模型中,输入之前需要增加一维通道数,来适应网络中的卷积操作,即将三种特征向量均扩展为三维向量(如:mfcc特征向量扩展为(174,174,1))。
数据增强后特征向量输入到声场景分类模型的三个支路网络中后,在每一个支路网络中,首先经过三组通道数递增的卷积块;其中,第一组卷积块中包含两个通道数为32,卷积核尺寸为3,卷积核滑动步长为1的卷积层以及两组br层处理,卷积核通过均匀扫过特征图来实现卷积操作;以一个卷积核的卷积操作为例,其计算公式为:
求和∑表示卷积层前向传播的过程,i表示输入的特征图,s表示输出的特征图,k表示卷积核,*表示卷积运算,(i,j)表示特征图上的特征向量,(m,n)表示卷积核的尺寸。
经过第一组卷积处理后的数据采用maxpooling池化处理,设置池化尺寸为4×4;第二组卷积块的参数设置较第一组卷积块只改变了通道个数和池化尺寸,其两个通道数为64,对应的maxpooling池化尺寸为3×3;第三组卷积块层的参数设置较第二组卷积块层只改变了通道个数,其两个通道数为128。从第三个卷积块层输出的特征图层进入支路全连接块,先通过flatten处理将特征图层扁平化为一维数据,再经过全连接(dense(256))处理得到长度为256的一维特征数据,最后通过dropout处理来降低模型过拟合的概率。
三路特征数据分别从支路全连接块输出进入到融合层,经过concatenate处理,将三个长度为256的一维特征数据拼接成一个长度为786的合成特征数据,三路特征数据从支路全连接块输出的结果分别记为l1,l2,l3,拼接后的特征数据记为l,则l的表达式为:
l=concate([l1,l2,l3])
式中concate([l1,l2,l3])表示使用concatenation层进行三路的一维特征信息数据合并。
然后将合并后的特征数据再通过主全连接层(dense(256))处理,得到长度为256的一维特征数据,同时dropout处理来降低模型过拟合的概率,最后通过归一化指数函数softmax处理后,输出最终分类预测结果。
在window10系统、显卡gtx1660ti、cpu为i7-9750h、内存32g的实验环境下;采用keras+tensorflow作为深度学习框架,采用城市声音事件分类标准数据集urbansound8k,其中fold1-9作为训练集,训练集样本个数为7895;测试集为fold10中wav音频文件,样本个数为838。分别进行是否经过数据增强对模型影响的对比实验,以及多声学特征和单一声学特征对模型影响的对比试验。再通过环境音频数据集esc10来检验多声学特征数据增强方法的泛化能力。
利用本发明技术方案的mcnn网络模型(表中标记为mcnn)、应用于两种声学特征并行输入的dcnn网络模型(表中标记为dcnn)以及应用于一种声学特征输入的cnn网络模型(表中标记为cnn),提取的5种声学特征数据,在urbansound8k数据集上进行声场景分类实验,并对比分类准确率的变化情况,具体结果如表1多声学特征输入数据增强实验(urbansound8k数据集)所示:
表1:多声学特征输入数据增强实验(urbansound8k数据集)
传统的音频数据分类方法中,主要采用单一的声学特征作为系统输入,或者通过维度拼接的方式将不同的声学特征输入网络,这种方法在特征导入的过程中容易造成内存占用率过大的情况,在进行数据增强的过程中也会耗费大量的时间,表1中给出不同声学特征输入的声场景分类准确率对比以及体现上述提及数据增强方法的对比准确率。
可以从表1中的实验数据看出,在未做数据增强处理且网络模型相同的情况下,单一声学特征的分类准确率最高可达到83.63%(对应cnn模型-128维gamma-tone语谱图的未数据增强的分类准确率);而多种声学特征并行输入方法的分类准确率最高可以达到84.83%(对应mcnn网络模型-[128维log-mel语谱图,174维mfcc,128维gfcc]的未数据增强项目的分类准确率)。
而在做数据增强处理且网络模型相同的情况下,单一声学特征的分类准确率最高可达到86.26%(对应cnn模型-128维log-mel语谱图,的数据增强的分类准确率),而多种声学特征并行输入方法的分类准确率最高可以达到88.29%(对应mcnn网络模型-[128维log-mel语谱图,174维mfcc,128维gfcc]的数据增强项目的分类准确率);
可知,多种声学特征并行输入网络较单一声学特征输入在分类准确率方面有一定的提升,且经过数据增强后的模型准确率较未经过数据增强的模型(即,本发明技术方案)准确率有一定的提升。
为了验证多特征数据增强方法的泛化能力,利用上述实验中的声学特征组合方法,在esc10数据集上进行消融实验,具体结果如下表2:多声学特征输入数据增强实验(esc10数据集)所示:
表2:多声学特征输入数据增强实验(esc10数据集)
根据表2中的实验结果可知,在未做数据增强处理且网络模型相同的情况下,单一声学特征的分类准确率最高可达到91.25%(对应cnn模型-128维gamma-tone语谱图的未数据增强的分类准确率),而多种声学特征并行输入方法的分类准确率最高可以达到93.75%(对应mcnn网络模型-[128维log-mel语谱图,174维mfcc,128维gfcc]的未数据增强项目的分类准确率)。
而在做数据增强处理且网络模型相同的情况下,单一声学特征的分类准确率最高可达到93.75%(对应cnn模型-128维gamma-tone语谱图的数据增强的分类准确率),而多种声学特征并行输入方法的分类准确率最高可以达到96.25%(对应mcnn网络模型-[128维log-mel语谱图,174维mfcc,128维gfcc]的数据增强项目的分类准确率);
可知,多种声学特征并行输入网络较单一声学特征输入在分类准确率方面有一定的提升,且经过数据增强后的模型准确率较未经过数据增强的模型(本发明技术方案)准确率有一定的提升。
综上所述,本发明提供的方案,在处理音频数据时,引入了多种声学特性、以及数据增强方式,使得分类系统的准确率以及泛化能力都有一定的提升。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



