
 商标分类
商标分类  商标转让
商标转让 
声音处理方法、声音处理装置及记录介质与流程
 2021-01-28 16:01:33|
2021-01-28 16:01:33| 299|
299| 起点商标网
起点商标网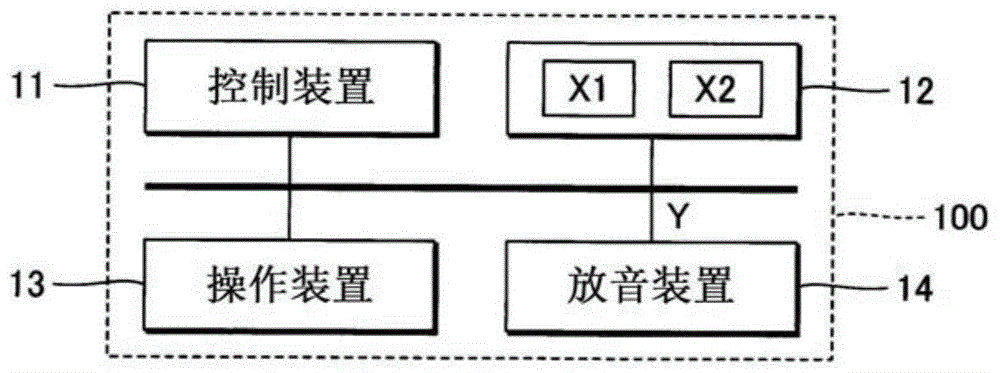
本发明涉及对表示声音的声音信号进行处理的技术。
背景技术:
以往提出了将歌唱表现等的声音表现附加于语音的各种技术。例如在专利文献1中公开了下述技术,即,使语音信号的各谐波成分在频率区域移动,由此将该语音信号所表示的语音变换为混浊声或者嘶哑声等特征性的音质的语音。
专利文献1:日本特开2014-2338号公报
技术实现要素:
但是,在专利文献1的技术中,从生成听觉上自然的声音这一观点出发,存在进一步改善的余地。考虑以上的情况,本发明的目的在于,合成听觉上自然的声音。
为了解决以上的课题,本发明的优选的方式所涉及的声音处理方法,其与第1差分和第2差分相应地使第1频谱包络概略形状变形,由此生成第3声音信号的合成频谱包络概略形状,生成与所述合成频谱包络概略形状相对应的所述第3声音信号,其中,所述第1差分是表示第1音的第1声音信号的所述第1频谱包络概略形状和所述第1声音信号中的第1时刻的第1基准频谱包络概略形状的差分,所述第2差分是表示声响特性与所述第1音存在差异的第2音的第2声音信号的第2频谱包络概略形状和所述第2声音信号中的第2时刻的第2基准频谱包络概略形状的差分,所述第3声音信号表示将所述第1音与所述第2音相应地变形的变形音。
为了解决以上的课题,本发明的优选的方式所涉及的声音处理装置具有存储器和大于或等于1个处理器,该声音处理装置具有合成处理部,其通过由所述大于或等于1个处理器执行在所述存储器中存储的指示,从而与第1差分和第2差分相应地使第1频谱包络概略形状变形,由此生成第3声音信号的合成频谱包络概略形状,生成与所述合成频谱包络概略形状相对应的所述第3声音信号,其中,所述第1差分是表示第1音的第1声音信号的第1频谱包络概略形状和所述第1声音信号中的第1时刻的第1基准频谱包络概略形状的差分,所述第2差分是表示声响特性与所述第1音存在差异的第2音的第2声音信号的第2频谱包络概略形状和所述第2声音信号中的第2时刻的第2基准频谱包络概略形状的差分,所述第3声音信号表示将所述第1音与所述第2音相应地变形的变形音。
为了解决以上的课题,本发明的优选的方式所涉及的记录介质,其记录有使计算机执行下述处理的程序:第1处理,与第1差分和第2差分相应地使第1频谱包络概略形状变形,由此生成第3声音信号的合成频谱包络概略形状,其中,所述第1差分是表示第1音的第1声音信号的所述第1频谱包络概略形状和所述第1声音信号中的第1时刻的第1基准频谱包络概略形状的差分,所述第2差分是表示声响特性与所述第1音存在差异的第2音的第2声音信号的第2频谱包络概略形状和所述第2声音信号中的第2时刻的第2基准频谱包络概略形状的差分,所述第3声音信号表示将所述第1音与所述第2音相应地变形的变形音;以及第2处理,生成与所述合成频谱包络概略形状相对应的所述第3声音信号。
附图说明
图1是例示本发明的实施方式所涉及的声音处理装置的结构的框图。
图2是例示声音处理装置的功能性结构的框图。
图3是第1声音信号中的平稳期间的说明图。
图4是例示信号解析处理的具体的顺序的流程图。
图5是歌唱语音的发音刚开始后的基本频率的时间变化。
图6是歌唱语音的发音刚要结束前的基本频率的时间变化。
图7是例示释音处理的具体的顺序的流程图。
图8是释音处理的说明图。
图9是频谱包络概略形状的说明图。
图10是例示起音处理的具体的顺序的流程图。
图11是起音处理的说明图。
具体实施方式
图1是例示本发明的优选的方式所涉及的声音处理装置100的结构的框图。本实施方式的声音处理装置100是针对由利用者歌唱乐曲的语音(以下称为“歌唱语音”)而附加各种声音表现的信号处理装置。声音表现是针对歌唱语音(第1音的例示)而附加的声响特性。关注乐曲的歌唱,声音表现是与语音的发音(即歌唱)相关的音乐性的表现或者表情。具体地说,气泡音(vocalfry)、咆哮声(growl)或者嘶哑声(rough)这样的歌唱表现是声音表现的优选例。此外,声音表现也改叫作音质。
声音表现在歌唱语音中的发音刚开始后音量不断增加的部分(以下称为“起音部”)和歌唱语音中的发音刚要结束前音量不断减少的部分(以下称为“释音部”)中特别显著。考虑以上的倾向,在本实施方式中,针对歌唱语音中的特别是起音部及释音部附加声音表现。
如图1例示那样,声音处理装置100是通过具有控制装置11、存储装置12、操作装置13和放音装置14的计算机系统实现的。例如移动电话机或者智能手机等移动式的信息终端、或者个人计算机等移动式或者固定式的信息终端适合用作声音处理装置100。操作装置13是接收来自利用者的指示的输入设备。例如,利用者进行操作的多个操作件、或者对利用者的接触进行检测的触摸面板适合用作操作装置13。
控制装置11例如是cpu(centralprocessingunit)等大于或等于1个处理器,执行各种运算处理及控制处理。本实施方式的控制装置11生成第3声音信号y,该第3声音信号y表示对歌唱语音赋予了声音表现的语音(以下称为“变形音”)。放音装置14例如是扬声器或者耳机,对由控制装置11生成的第3声音信号y所表示的变形音进行放音。此外,方便起见而省略了由控制装置11生成的第3声音信号y从数字变换为模拟的d/a变换器的图示。此外,在图1中例示出声音处理装置100具有放音装置14的结构,但也可以将与声音处理装置100分体的放音装置14通过有线或者无线而与声音处理装置100连接。
存储装置12例如是由磁性记录介质或者半导体记录介质等公知的记录介质构成的存储器,对由控制装置11执行的程序和由控制装置11使用的各种数据进行存储。此外,也可以通过多种记录介质的组合而构成存储装置12。另外,也可以准备与声音处理装置100分体的存储装置12(例如云储存器),控制装置11经由通信网而执行相对于存储装置12的写入及读出。即,也可以从声音处理装置100省略存储装置12。
本实施方式的存储装置12对第1声音信号x1和第2声音信号x2进行存储。第1声音信号x1是表示声音处理装置100的利用者歌唱乐曲而发出的歌唱语音的声响信号。第2声音信号x2是表示除了利用者以外的歌唱者(例如歌手)附加声音表现而歌唱出的语音(以下称为“参照语音”)的声响信号。在第1声音信号x1和第2声音信号x2中声响特性(例如音质)存在差异。本实施方式的声音处理装置100通过将第2声音信号x2所表示的参照语音(第2音的例示)的声音表现附加于第1声音信号x1所表示的歌唱语音,从而生成变形音的第3声音信号y。此外,在歌唱语音和参照语音之间不考虑乐曲的差别。此外,在以上的说明中设想为歌唱语音的发声者和参照语音的发声者为不同人的情况,但歌唱语音的发声者和参照语音的发声者也可以是同一人。例如,歌唱语音是不附加声音表现而由利用者歌唱出的语音,参照语音是该利用者附加了歌唱表现的语音。
图2是例示控制装置11的功能性结构的框图。如图2例示那样,控制装置11通过执行在存储装置12中存储的程序(即针对处理器的指示的系列),从而实现用于根据第1声音信号x1和第2声音信号x2而生成第3声音信号y的多个功能(信号解析部21及合成处理部22)。此外,可以通过彼此分体构成的多个装置而实现控制装置11的功能,也可以将控制装置11的功能的一部分或者全部通过专用的电子电路实现。
信号解析部21通过第1声音信号x1的解析而生成解析数据d1,通过第2声音信号x2的解析而生成解析数据d2。由信号解析部21生成的解析数据d1及解析数据d2储存于存储装置12。
解析数据d1是表示第1声音信号x1的多个平稳期间q1的数据。如图3例示那样,解析数据d1所示的各平稳期间q1是第1声音信号x1的基本频率f1和频谱形状在时间上稳定的可变长度的期间。解析数据d1对各平稳期间q1的起点的时刻(以下称为“起点时刻”)t1_s和终点的时刻(以下称为“终点时刻”)t1_e进行指定。此外,在乐曲内位于前后的2个音符之间,基本频率f1或者频谱形状(即音位)变化的情况较多。因此,各平稳期间q1是相当于乐曲内的1个音符的期间的可能性高。
同样地,解析数据d2是表示第2声音信号x2的多个平稳期间q2的数据。各平稳期间q2是第2声音信号x2的基本频率f2和频谱形状在时间上稳定的可变长度的期间。解析数据d2对各平稳期间q2的起点时刻t2_s和终点时刻t2_e进行指定。与平稳期间q1同样地,各平稳期间q2是相当于乐曲内的1个音符的期间的可能性高。
图4是信号解析部21对第1声音信号x1进行解析的处理(以下称为“信号解析处理”)s0的流程图。例如以来自利用者的针对操作装置13的指示为契机而开始图4的信号解析处理s0。如图4例示那样,信号解析部21关于时间轴上的多个单位期间(时间帧)分别对第1声音信号x1的基本频率f1进行计算(s01)。在计算基本频率f1时任意地采用公知技术。各单位期间是与在平稳期间q1中设想的时间长度相比较而充分短的期间。
信号解析部21针对每个单位期间对表示第1声音信号x1的频谱形状的梅尔倒谱m1进行计算(s02)。梅尔倒谱m1以表示第1声音信号x1的频谱的包络线的多个系数进行表现。梅尔倒谱m1还以表示歌唱语音的音位的特征量表现。在计算梅尔倒谱m1时任意地采用公知技术。此外,作为表示第1声音信号x1的频谱形状的特征量,也可以取代梅尔倒谱m1而对mfcc(mel-frequencycepstrumcoefficients)进行计算。
信号解析部21针对每个单位期间对第1声音信号x1表示的歌唱语音的有声性进行推定(s03)。即,对歌唱语音符合有声音及无声音的哪一者进行判定。在推定有声性(有声/无声)时任意地采用公知技术。此外,关于基本频率f1的计算(s01)、梅尔倒谱m1的计算(s02)和有声性的推定(s03),顺序是任意的,以上例示出的顺序不受限定。
信号解析部21针对每个单位期间对表示基本频率f1的时间性的变化程度的第1指标δ1进行计算(s04)。例如将位于前后的2个单位期间之间的基本频率f1的差分作为第1指标δ1进行计算。基本频率f1的时间性的变化越显著,则第1指标δ1成为越大的数值。
信号解析部21针对每个单位期间对表示梅尔倒谱m1的时间性的变化程度的第2指标δ2进行计算(s05)。例如在位于前后的2个单位期间之间将梅尔倒谱m1的针对每个系数的差分关于多个系数进行合成(例如相加或者平均)得到的数值适合作为第2指标δ2。歌唱语音的频谱形状的时间性的变化越显著,则第2指标δ2成为越大的数值。例如在歌唱语音的音位变化时刻的附近,第2指标δ2成为大的数值。
信号解析部21针对每个单位期间对与第1指标δ1及第2指标δ2相对应的变动指标δ进行计算(s06)。例如针对每个单位期间对第1指标δ1和第2指标δ2的加权和进行计算而作为变动指标δ。第1指标δ1及第2指标δ2各自的加权值设定为规定的固定值、或者与来自利用者的针对操作装置13的指示相对应的可变值。如以上说明所理解那样,存在下述倾向,即,第1声音信号x1的基本频率f1或者梅尔倒谱m1(即频谱形状)的时间性的变动越大,变动指标δ成为越大的数值。
信号解析部21对第1声音信号x1中的多个平稳期间q1进行确定(s07)。本实施方式的信号解析部21与歌唱语音的有声性的推定的结果(s03)和变动指标δ相应地对平稳期间q1进行确定。具体地说,信号解析部21将推定为歌唱语音是有声音、且变动指标δ低于规定的阈值的一系列的单位期间的集合划定为平稳期间q1。将推定为歌唱语音是无声音的单位期间、或者变动指标δ超过阈值的单位期间,从平稳期间q1排除在外。如果通过以上的顺序对第1声音信号x1的各平稳期间q1进行了划定,则信号解析部21将对各平稳期间q1的起点时刻t1_s和终点时刻t1_e进行指定的解析数据d1储存于存储装置12(s08)。
信号解析部21关于表示参照语音的第2声音信号x2也执行以上说明的信号解析处理s0,由此生成解析数据d2。具体地说,信号解析部21针对第2声音信号x2的每个单位期间,执行基本频率f2的计算(s01)、梅尔倒谱m2的计算(s02)和有声性(有声/无声)的推定(s03)。信号解析部21对与表示基本频率f2的时间性的变化程度的第1指标δ1和表示梅尔倒谱m2的时间性的变化程度的第2指标δ2相对应的变动指标δ进行计算(s04-s06)。而且,信号解析部21与参照语音的有声性的推定的结果(s03)和变动指标δ相应地对第2声音信号x2的各平稳期间q2进行确定(s07)。信号解析部21将对各平稳期间q2的起点时刻t2_s和终点时刻t2_e进行指定的解析数据d2储存于存储装置12(s08)。此外,也可以与来自针对操作装置13的利用者的指示相应地对解析数据d1及解析数据d2进行编辑。具体地说,将对由利用者指示出的起点时刻t1_s及终点时刻t1_e进行指定的解析数据d1和对由利用者指示出的起点时刻t2_s及终点时刻t2_e进行指定的解析数据d2储存于存储装置12。即,省略信号解析处理s0。
图2的合成处理部22利用第2声音信号x2的解析数据d2而使第1声音信号x1的解析数据d1变形。本实施方式的合成处理部22包含起音处理部31、释音处理部32和语音合成部33而构成。起音处理部31执行将第2声音信号x2中的起音部的声音表现附加于第1声音信号x1的起音处理s1。释音处理部32执行将第2声音信号x2中的释音部的声音表现附加于第1声音信号x1的释音处理s2。语音合成部33根据起音处理部31及释音处理部32的处理结果而合成变形音的第3声音信号y。
在图5中图示出歌唱语音的发音刚开始后的基本频率f1的时间变化。如图5例示那样,在紧跟平稳期间q1之前存在有声期间va。有声期间va是在平稳期间q1之前的有声音的期间。有声期间va是歌唱语音的声响特性(例如基本频率f1或者频谱形状)在紧跟平稳期间q1之前不稳定地变动的期间。例如,如果关注歌唱语音的发音刚开始后的平稳期间q1,则从歌唱语音的发音开始的时刻τ1_a至该平稳期间q1的起点时刻t1_s为止的起音部相当于有声期间va。此外,在以上的说明中关注了歌唱语音,但关于参照语音也同样地,在紧跟平稳期间q2之前存在有声期间va。合成处理部22(具体地说是起音处理部31)在起音处理s1中,针对第1声音信号x1中的有声期间va和紧随其后的平稳期间q1而附加第2声音信号x2中的起音部的声音表现。
在图6中图示出歌唱语音的发音刚要结束前的基本频率f1的时间变化。如图6例示那样,在紧随平稳期间q1之后存在有声期间vr。有声期间vr是平稳期间q1之后的有声音的期间。有声期间vr是歌唱语音的声响特性(例如基本频率f2或者频谱形状)紧随平稳期间q1之后不稳定地变动的期间。例如,如果关注歌唱语音的发音刚要结束前的平稳期间q1,则从该平稳期间q1的终点时刻t1_e至歌唱语音消音的时刻τ1_r为止的释音部相当于有声期间vr。此外,在以上的说明中关注了歌唱语音,但关于参照语音也同样地,在紧随平稳期间q2之后存在语音期间vr。合成处理部22(具体地说是释音处理部32)在释音处理s2中,针对第1声音信号x1中的有声期间vr和紧跟其前的平稳期间q1而附加第2声音信号x2的释音部的声音表现。
<释音处理s2>
图7是例示由释音处理部32执行的释音处理s2的具体内容的流程图。针对第1声音信号x1的每个平稳期间q1而执行图7的释音处理s2。
如果开始释音处理s2,则释音处理部32对第1声音信号x1中的处理对象的平稳期间q1是否附加第2声音信号x2的释音部的声音表现进行判定(s21)。具体地说,释音处理部32判定为针对与以下例示的条件cr1至条件cr3的任意者相符合的平稳期间q1不附加释音部的声音表现。但是,对在第1声音信号x1的平稳期间q1是否附加声音表现进行判定的条件并不限定于下面的例示。
[条件cr1]平稳期间q1的时间长度低于规定值。
[条件cr2]紧随平稳期间q1之后的无声期间的时间长度低于规定值。
[条件cr3]平稳期间q1之后的有声期间vr的时间长度超过规定值。
对时间长度充分短的平稳期间q1难以通过自然的音质附加声音表现。因此,在平稳期间q1的时间长度低于规定值的情况下(条件cr1),释音处理部32将该平稳期间q1从声音表现的附加对象排除在外。另外,在紧随平稳期间q1之后存在充分短的无声期间的情况下,该无声期间有可能是歌唱语音的中途的无声辅音的期间。而且,如果在无声辅音的期间附加声音表现,则存在觉察到听觉上的不适感这一倾向。考虑以上的倾向,在紧随平稳期间q1之后的无声期间的时间长度低于规定值的情况下(条件cr2),释音处理部32将该平稳期间q1从声音表现的附加对象排除在外。另外,在紧随平稳期间q1之后的有声期间vr的时间长度充分长的情况下,在歌唱语音中已经附加有充分的声音表现的可能性高。因此,在平稳期间q1后续的有声期间vr的时间长度充分长的情况下(条件cr3),释音处理部32将该平稳期间q1从声音表现的附加对象排除在外。在判定为在第1声音信号x1的平稳期间q1不附加声音表现的情况下(s21:no),释音处理部32不执行以下详述的处理(s22-s26)而是结束释音处理s2。
在判定为在第1声音信号x1的平稳期间q1附加第2声音信号x2的释音部的声音表现的情况下(s21:yes),释音处理部32对第2声音信号x2的多个平稳期间q2中的、与应该附加于第1声音信号x1的平稳期间q1的声音表现相对应的平稳期间q2进行选择(s22)。具体地说,释音处理部32对乐曲内的状况与处理对象的平稳期间q1近似的平稳期间q2进行选择。例如,作为关于1个平稳期间(以下称为“关注平稳期间”)而考虑的状况(context),例示出关注平稳期间的时间长度、紧随关注平稳期间之后的平稳期间的时间长度、关注平稳期间与紧随其后的平稳期间之间的音高差、关注平稳期间的音高及紧跟关注平稳期间之前的无音期间的时间长度。释音处理部32关于以上例示出的状况对平稳期间q1的差异成为最小的平稳期间q2进行选择。
释音处理部32执行用于将与按照以上的顺序选择出的平稳期间q2相对应的声音表现附加于第1声音信号x1(解析数据d1)的处理(s23-s26)。图8是释音处理部32在第1声音信号x1附加释音部的声音表现的处理的说明图。
在图8中,关于第1声音信号x1、第2声音信号x2和变形后的第3声音信号y各自一并记载有时间轴上的波形和基本频率的时间变化。在图8中,歌唱语音的平稳期间q1的起点时刻t1_s及终点时刻t1_e、紧随该平稳期间q1之后的有声期间vr的终点时刻τ1_r、与紧随该平稳期间q1之后的音符相对应的有声期间va的起点时刻τ1_a、参照语音的平稳期间q2的起点时刻t2_s及终点时刻t2_e、紧随该平稳期间q2之后的有声期间vr的终点时刻τ2_r是已知的信息。
释音处理部32在处理对象的平稳期间q1和通过步骤s22选择出的平稳期间q2之间对时间轴上的位置关系进行调整(s23)。具体地说,释音处理部32将平稳期间q2的时间轴上的位置调整为以平稳期间q1的端点(t1_s或者t1_e)为基准的位置。本实施方式的释音处理部32如图8例示那样,以使平稳期间q2的终点时刻t2_e在时间轴上与平稳期间q1的终点时刻t1_e一致的方式决定第2声音信号x2(平稳期间q2)相对于第1声音信号x1的时间轴上的位置。
<处理期间z1_r的伸长(s24)>
释音处理部32使第1声音信号x1中的被附加第2声音信号x2的声音表现的期间(以下称为“处理期间”)z1_r在时间轴上进行伸缩(s24)。如图8例示那样,处理期间z1_r是从声音表现的附加开始的时刻(以下称为“合成开始时刻”)tm_r至紧随平稳期间q1之后的有声期间vr的终点时刻τ1_r为止的期间。合成开始时刻tm_r是歌唱语音的平稳期间q1的起点时刻t1_s和参照语音的平稳期间q2的起点时刻t2_s中的后方的时刻。如图8的例示那样,在平稳期间q2的起点时刻t2_s位于平稳期间q1的起点时刻t1_s的后方的情况下,将平稳期间q2的起点时刻t2_s设定为合成开始时刻tm_r。但是,合成开始时刻tm_r并不限定于起点时刻t2_s。
如图8例示那样,本实施方式的释音处理部32将第1声音信号x1的处理期间z1_r与第2声音信号x2中的表现期间z2_r的时间长度相应地伸长。表现期间z2_r是表示第2声音信号x2中的释音部的声音表现的期间,利用于该声音表现相对于第1声音信号x1的附加。如图8例示那样,表现期间z2_r是从合成开始时刻tm_r至紧随平稳期间q2之后的有声期间vr的终点时刻τ2_r为止的期间。
存在下述倾向,即,在由歌手等熟练的歌唱者歌唱出的参照语音中附加有遍及相应的时间长度的充分的声音表现,与此相对,在由不熟悉歌唱的利用者歌唱出的歌唱语音中声音表现在时间上不够。在以上的倾向中,如图8例示那样,参照语音的表现期间z2_r与歌唱语音的处理期间z1_r相比较成为较长的期间。因此,本实施方式的释音处理部32将第1声音信号x1的处理期间z1_r伸长至第2声音信号x2的表现期间z2_r的时间长度。
处理期间z1_r的伸长是通过将第1声音信号x1(歌唱语音)的任意时刻t1和变形后的第3声音信号y(变形音)的任意时刻t相互地关联的处理(映射)而实现的。在图8中图示出歌唱语音的时刻t1(纵轴)和变形音的时刻t(横轴)的对应关系。
图8的对应关系中的时刻t1是与变形音的时刻t相对应的第1声音信号x1的时刻。在图8中通过点划线一并记载的基准线l是指第1声音信号x1没有伸缩的状态(t1=t)。另外,歌唱语音的时刻t1相对于变形音的时刻t的斜率与基准线l相比较而较小的区间,是指第1声音信号x1被伸长的区间。时刻t1相对于时刻t的斜率与基准线l相比较而较大的区间,是指歌唱语音被收缩的区间。
时刻t1和时刻t的对应关系是通过以下例示的算式(1a)至算式(1c)的非线性函数表现的。
[式1]
时刻t_r如图8例示那样,是位于合成开始时刻tm_r和处理期间z1_r的终点时刻τ1_r之间的规定的时刻。例如,将平稳期间q1的起点时刻t1_s和终点时刻t1_e之间的中点((t1_s+t1_e)/2)、和合成开始时刻tm_r中的后方的时刻设定为时刻t_r。如根据算式(1a)理解那样,处理期间z1_r中的时刻t_r的前方的期间不伸缩。即,从时刻t_r起处理期间z1_r的伸长开始。
如根据算式(1b)理解那样,处理期间z1_r中的时刻t_r的后方的期间在与该时刻t_r接近的位置处伸长的程度大,以越接近终点时刻τ1_r则伸长的程度变得越小的方式在时间轴上伸长。算式(1b)的函数η(t)是非线性函数,其用于在时间轴上的越是前方则将处理期间z1_r越伸长,在时间轴上的越是后方越减小处理期间z1_r的伸长程度。具体地说,例如时刻t的2次函数(η(t)=t2)适用于函数η(t)。如以上说明所述,在本实施方式中,以在与处理期间z1_r的终点时刻τ1_r越接近的位置,伸长的程度越小的方式将处理期间z1_r在时间轴上伸长。因此,能够将歌唱语音的终点时刻τ1_r的附近的声响特性在变形音中也充分地维持。此外,存在下述倾向,在与时刻t_r接近的位置,与终点时刻τ1_r的附近相比较,不易察觉由伸长引起的听觉上的不适感。因此,即使如前述的例示那样在与时刻t_r接近的位置处使伸长的程度增大,也几乎不会降低变形音的听觉上的自然性。此外,第1声音信号x1中的从表现期间z2_r的终点时刻τ2_r至下一个有声期间vr的起点时刻τ1_a为止的期间如根据算式(1c)所理解那样,在时间轴上缩短。此外,在从终点时刻τ2_r至起点时刻τ1_a为止的期间中不存在语音,因此可以将第1声音信号x1通过局部删除而删除。
如以上的例示那样,歌唱语音的处理期间z1_r伸长至参照语音的表现期间z2_r的时间长度。另一方面,参照语音的表现期间z2_r在时间轴上不伸缩。即,与变形音的时刻t相对应的配置后的第2声音信号x2的时刻t2与该时刻t一致(t2=t)。如以上的例示那样,在本实施方式中,歌唱语音的处理期间z1_r与表现期间z2_r的时间长度相应地伸长,因此不需要进行第2声音信号x2的伸长。因此,能够将第2声音信号x2所表示的释音部的声音表现准确地附加于第1声音信号x1。
如果按照以上例示出的顺序使处理期间z1_r伸长,则释音处理部32将第1声音信号x1的伸长后的处理期间z1_r与第2声音信号x2的表现期间z2_r相应地变形(s25-s26)。具体地说,在歌唱语音的伸长后的处理期间z1_r和参照语音的表现期间z2_r之间,执行基本频率的合成(s25)和频谱包络概略形状的合成(s26)。
<基本频率的合成(s25)>
释音处理部32通过下面的算式(2)的运算对第3声音信号y的各时刻t的基本频率f(t)进行计算。
[式2]
f(t)=f1(t1)-λ1(f1(t1)-f1(t1))+λ2(f2(t2)-f2(t2))...(2)
算式(2)中的平滑基本频率f1(t1)是将第1声音信号x1的基本频率f1(t1)的时间序列在时间轴上平滑化后的频率。同样地,算式(2)的平滑基本频率f2(t2)是将第2声音信号x2的基本频率f2(t2)的时间序列在时间轴上平滑化后的频率。算式(2)的系数λ1及系数λ2设定为小于或等于1的非负值(0≤λ1≤1、0≤λ2≤1)。
如根据算式(2)理解那样,算式(2)的第2项是以与系数λ1相对应的程度从第1声音信号x1的基本频率f1(t1)减去歌唱语音的基本频率f1(t1)和平滑基本频率f1(t1)的差分的处理。另外,算式(2)的第3项是以与系数λ2相对应的程度,将参照语音的基本频率f2(t2)和平滑基本频率f2(t2)的差分附加于第1声音信号x1的基本频率f1(t1)的处理。如根据以上的说明所理解那样,释音处理部32作为将歌唱语音的基本频率f1(t1)和平滑基本频率f1(t1)的差分置换为参照语音的基本频率f2(t2)和平滑基本频率f2(t2)的差分的要素起作用。即,第1声音信号x1的伸长后的处理期间z1_r内的基本频率f1(t1)的时间变化,接近第2声音信号x2的表现期间z2_r内的基本频率f2(t2)的时间变化。
<频谱包络概略形状的合成(s26)>
释音处理部32在歌唱语音的伸长后的处理期间z1_r和参照语音的表现期间z2_r之间,合成频谱包络概略形状。第1声音信号x1的频谱包络概略形状g1如图9例示那样,是指将第1声音信号x1的频谱g1的概略形状即频谱包络g2在频率区域进一步平滑化后的强度分布。具体地说,以无法察觉到音位性(依赖于音位的差异)及个体性(依赖于发声者的差异)的程度将频谱包络g2平滑化后的强度分布是频谱包络概略形状g1。例如通过表示频谱包络g2的梅尔倒谱的多个系数中的位于低阶侧的规定个数的系数表现频谱包络概略形状g1。在以上的说明中关注了第1声音信号x1的频谱包络概略形状g1,但第2声音信号x2的频谱包络概略形状g2也是同样的。
释音处理部32通过下面的算式(3)的运算对第3声音信号y的各时刻t的频谱包络概略形状(以下称为“合成频谱包络概略形状”)g(t)进行计算。
[式3]
g(t)=g1(t1)-μ1(g1(t1)-g1_ref)+μ2(g2(t2)-g2_ref)...(3)
算式(3)的记号g1_ref是基准频谱包络概略形状。第1声音信号x1的多个频谱包络概略形状g1中的、特定的时刻的1个频谱包络概略形状g1作为基准频谱包络概略形状g1_ref(第1基准频谱包络概略形状的例示)被利用。具体地说,基准频谱包络概略形状g1_ref是第1声音信号x1的合成开始时刻tm_r(第1时刻的例示)的频谱包络概略形状g1(tm_r)。即,基准频谱包络概略形状g1_ref被提取的时刻位于平稳期间q1的起点时刻t1_s及平稳期间q2的起点时刻t2_s中的后方的时刻。此外,基准频谱包络概略形状g1_ref被提取的时刻并不限定于合成开始时刻tm_r。例如,平稳期间q1内的任意时刻的频谱包络概略形状g1作为基准频谱包络概略形状g1_ref被利用。
同样地,算式(3)的基准频谱包络概略形状g2_ref是第2声音信号x2的多个频谱包络概略形状g2中的、特定的时刻的1个频谱包络概略形状g2。具体地说,基准频谱包络概略形状g2_ref是第2声音信号x2的合成开始时刻tm_r(第2时刻的例示)的频谱包络概略形状g2(tm_r)。即,基准频谱包络概略形状g2_ref被提取的时刻位于平稳期间q1的起点时刻t1_s及平稳期间q2的起点时刻t2_s中的后方的时刻。此外,基准频谱包络概略形状g2_ref被提取的时刻并不限定于合成开始时刻tm_r。例如,平稳期间q1内的任意时刻的频谱包络概略形状g2作为基准频谱包络概略形状g2_ref被利用。
算式(3)的系数μ1及系数μ2设定为小于或等于1的非负值(0≤μ1≤1、0≤μ2≤1)。算式(3)的第2项是以与系数μ1(第1系数的例示)相对应的程度,从第1声音信号x1的频谱包络概略形状g1(t1)减去歌唱语音的频谱包络概略形状g1(t1)和基准频谱包络概略形状g1_ref的差分的处理。另外,算式(3)的第3项是以与系数μ2(第2系数的例示)相对应的程度,将参照语音的频谱包络概略形状g2(t2)和基准频谱包络概略形状g2_ref的差分附加于第1声音信号x1的频谱包络概略形状g1(t1)的处理。如根据以上的说明所理解那样,与歌唱语音的频谱包络概略形状g1(t1)与基准频谱包络概略形状g1_ref的差分(第1差分的例示)以及参照语音的频谱包络概略形状g2(t2)与基准频谱包络概略形状g2_ref的差分(第2差分的例示)相应地,释音处理部32使频谱包络概略形状g1(t1)变形,由此对第3声音信号y的合成频谱包络概略形状g(t)进行计算。具体地说,释音处理部32作为将歌唱语音的频谱包络概略形状g1(t1)与基准频谱包络概略形状g1_ref的差分(第1差分的例示)置换为参照语音的频谱包络概略形状g2(t2)与基准频谱包络概略形状g2_ref的差分(第2差分的例示)的要素起作用。以上说明的步骤s26是“第1处理”的一个例子。
<起音处理s1>
图10是例示由起音处理部31执行的起音处理s1的具体内容的流程图。针对第1声音信号x1的每个平稳期间q1而执行图10的起音处理s1。此外,起音处理s1的具体的顺序与释音处理s2相同。
如果开始起音处理s1,则起音处理部31对第1声音信号x1中的处理对象的平稳期间q1是否附加第2声音信号x2的起音部的声音表现进行判定(s11)。具体地说,起音处理部31判定为关于与以下例示的条件ca1至条件ca5的任意者相符合的平稳期间q1不附加起音部的声音表现。但是,对在第1声音信号x1的平稳期间q1是否附加声音表现进行判定的条件并不限定于下面的例示。
[条件ca1]平稳期间q1的时间长度低于规定值。
[条件ca2]在平稳期间q1内平滑化后的基本频率f1的变动幅度超过规定值。
[条件ca3]在平稳期间q1中的包含起点的规定长度的期间内平滑化后的基本频率f1的变动幅度超过规定值。
[条件ca4]紧跟平稳期间q1之前的有声期间va的时间长度超过规定值。
[条件ca5]紧跟平稳期间q1之前的有声期间va中的基本频率f1的变动幅度超过规定值。
条件ca1与前述的条件cr1同样地,是考虑在时间长度充分短的平稳期间q1难以通过自然的音质附加声音表现这一情况的条件。另外,在平稳期间q1内基本频率f1大幅地变动的情况下,在歌唱语音中附加有充分的声音表现的可能性高。因此,平滑后的基本频率f1的变动幅度超过规定值的平稳期间q1从声音表现的附加对象被排除在外(条件ca2)。条件ca3是与条件ca2相同的内容,是关注于平稳期间q1中的特别是与起音部接近的期间的条件。另外,在紧跟平稳期间q1之前的有声期间va的时间长度充分长的情况、或者在有声期间va内基本频率f1大幅地变动的情况下,在歌唱语音中已经附加有充分的声音表现的可能性高。因此,紧跟之前的有声期间va的时间长度超过规定值的平稳期间q1(条件ca4)和有声期间va内的基本频率f1的变动幅度超过规定值的平稳期间q1(条件ca5),从声音表现的附加对象被排除在外。在判定为在平稳期间q1不附加声音表现的情况下(s11:yes),起音处理部31不执行以下详述的处理(s12-s16)而是结束起音处理s1。
在判定为在第1声音信号x1的平稳期间q1附加第2声音信号x2的起音部的声音表现的情况下(s11:yes),起音处理部31对第2声音信号x2的多个平稳期间q2中的、与应该附加于平稳期间q1的声音表现相对应的平稳期间q2进行选择(s12)。起音处理部31对平稳期间q2进行选择的方法与释音处理部32对平稳期间q2进行选择的方法相同。
起音处理部31执行用于将与按照以上的顺序选择出的平稳期间q2相对应的声音表现附加于第1声音信号x1的处理(s13-s16)。图11是起音处理部31在第1声音信号x1附加起音部的声音表现的处理的说明图。
起音处理部31在处理对象的平稳期间q1和通过步骤s12选择出的平稳期间q2之间对时间轴上的位置关系进行调整(s13)。具体地说,起音处理部31如图11例示那样,以使平稳期间q2的起点时刻t2_s在时间轴上与平稳期间q1的起点时刻t1_s一致的方式,决定第2声音信号x2(平稳期间q2)相对于第1声音信号x1的时间轴上的位置。
<处理期间z1_a的伸长>
起音处理部31将第1声音信号x1中的附加第2声音信号x2的声音表现的处理期间z1_a在时间轴上伸长(s14)。处理期间z1_a是从紧跟平稳期间q1之前的有声期间va的起点时刻τ1_a至声音表现的附加结束的时刻(以下称为“合成结束时刻”)tm_a为止的期间。合成结束时刻tm_a例如是平稳期间q1的起点时刻t1_s(平稳期间q2的起点时刻t2_s)。即,在起音处理s1中,平稳期间q1的前方的有声期间va作为处理期间z1_a而被伸长。如前所述,平稳期间q1是相当于乐曲的音符的期间。如果构成为将有声期间va伸长,平稳期间q1不伸长,则能抑制平稳期间q1的起点时刻t1_s的变化。即,能够减少歌唱语音中的音符的起始在前后移动的可能性。
如图11例示那样,本实施方式的起音处理部31将第1声音信号x1的处理期间z1_a与第2声音信号x2中的表现期间z2_a的时间长度相应地伸长。表现期间z2_a是第2声音信号x2中的表示起音部的声音表现的期间,利用于该声音表现相对于第1声音信号x1的附加。如图11例示那样,表现期间z2_a是紧跟平稳期间q2之前的有声期间va。
具体地说,起音处理部31将第1声音信号x1的处理期间z1_a伸长至第2声音信号x2的表现期间z2_a的时间长度。在图11中图示出歌唱语音的时刻t1(纵轴)和变形音的时刻t(横轴)的对应关系。
如图11例示那样,在本实施方式中,以在与处理期间z1_a的起点时刻τ1_a越接近的位置,伸长的程度越小的方式将处理期间z1_a在时间轴上伸长。因此,将歌唱语音的起点时刻τ1_a的附近的声响特性在变形音中也能够充分维持。另一方面,参照语音的表现期间z2_a在时间轴上不伸缩。因此,能够将第2声音信号x2表示的起音部的声音表现准确地附加于第1声音信号x1。
如果按照以上例示出的顺序使处理期间z1_a伸长,则起音处理部31使第1声音信号x1的伸长后的处理期间z1_a与第2声音信号x2的表现期间z2_a相应地变形(s15-s16)。具体地说,在歌唱语音的伸长后的处理期间z1_a和参照语音的表现期间z2_a之间,执行基本频率的合成(s25)和频谱包络概略形状的合成(s26)。
具体地说,起音处理部31通过与前述的算式(2)相同的运算,根据第1声音信号x1的基本频率f1(t1)和第2声音信号x2的基本频率f2(t2)而对第3声音信号y的基本频率f(t)进行计算(s15)。即,起音处理部31以与系数λ1相对应的程度,从第1声音信号x1的基本频率f1(t1)减去基本频率f1(t1)与平滑后的基本频率f1(t1)的差分,以与系数λ2相对应的程度将基本频率f2(t2)与平滑后的基本频率f2(t2)的差分附加于第1声音信号x1的基本频率f1(t1),由此对第3声音信号y的基本频率f(t)进行计算。因此,第1声音信号x1的伸长后的处理期间z1_a内的基本频率f1(t1)的时间变化,接近第2声音信号x2中的表现期间z2_a内的基本频率f2(t2)的时间变化。
另外,起音处理部31在歌唱语音的伸长后的处理期间z1_a和参照语音的表现期间z2_a之间合成频谱包络概略形状(s16)。具体地说,起音处理部31通过与前述的算式(3)相同的运算,根据第1声音信号x1的频谱包络概略形状g1(t1)和第2声音信号x2的频谱包络概略形状g2(t2)对第3声音信号y的合成频谱包络概略形状g(t)进行计算。以上说明的步骤s16是“第1处理”的一个例子。
在起音处理s1中应用于算式(3)的基准频谱包络概略形状g1_ref是第1声音信号x1中的合成结束时刻tm_a(第1时刻的例示)的频谱包络概略形状g1(tm_a)。即,基准频谱包络概略形状g1_ref被提取的时刻位于平稳期间q1的起点时刻t1_s。
同样地,在起音处理s1中应用于算式(3)的基准频谱包络概略形状g2_ref是第2声音信号x2中的合成结束时刻tm_a(第2时刻的例示)的频谱包络概略形状g2(tm_a)。即,基准频谱包络概略形状g2_ref被提取的时刻位于平稳期间q1的起点时刻t1_s。
如根据以上的说明所理解那样,本实施方式的起音处理部31及释音处理部32各自在以平稳期间q1的端点(起点时刻t1_s或者终点时刻t1_e)为基准的时间轴上的位置处利用第2声音信号x2(解析数据d2)使第1声音信号x1(解析数据d1)变形。通过以上例示出的起音处理s1及释音处理s2,生成表示变形音的第3声音信号y的基本频率f(t)的时间序列和合成频谱包络概略形状g(t)的时间序列。图2的语音合成部33根据第3声音信号y的基本频率f(t)的时间序列和合成频谱包络概略形状g(t)的时间序列而生成第3声音信号y。由语音合成部33生成第3声音信号y的处理是“第2处理”的一个例子。
图2的语音合成部33利用起音处理s1及释音处理s2的结果(即变形后的解析数据)而合成变形音的第3声音信号y。具体地说,语音合成部33将根据第1声音信号x1而计算的各频谱g1调整为沿着合成频谱包络概略形状g(t),而且,将第1声音信号x1的基本频率f1调整为基本频率f(t)。频谱g1及基本频率f1的调整例如是在频率区域执行的。语音合成部33将以上例示出的调整后的频谱变换为时间区域,由此合成第3声音信号y。
如以上说明所述,在本实施方式中,第1声音信号x1的频谱包络概略形状g1(t1)与基准频谱包络概略形状g1_ref的差分(g1(t1)-g1_ref)、以及第2声音信号x2的频谱包络概略形状g2(t2)与基准频谱包络概略形状g2_ref的差分(g2(t2)-g2_ref),合成于第1声音信号x1的频谱包络概略形状g1(t1)。因此,在第1声音信号x1中的、利用第2声音信号x2而变形的期间(处理期间z1_a或者z1_r)和该期间的前后的期间的边界处能够生成声响特性连续的在听觉上自然的变形音。
另外,在本实施方式中,对第1声音信号x1中的基本频率f1及频谱形状在时间上稳定的平稳期间q1进行确定,利用以平稳期间q1的端点(起点时刻t1_s或者终点时刻t1_e)为基准而配置的第2声音信号x2而使第1声音信号x1变形。因此,第1声音信号x1的适当期间与第2声音信号x2相应地变形,能够生成听觉上自然的变形音。
在本实施方式中,第1声音信号x1的处理期间(z1_a或者z1_r)与第2声音信号x2的表现期间(z2_a或者z2_r)的时间长度相应地伸长,因此不需要第2声音信号x2的伸长。因此,参照语音的声响特性(例如声音表现)准确地附加于第1声音信号x1,能够生成听觉上自然的变形音。
<变形例>
下面,对在以上例示出的各方式中附加的具体的变形方式进行例示。可以将从下面的例示中任意地选择出的2个以上的方式在不相互矛盾的范围适当地合并。
(1)在前述的方式中,利用根据第1指标δ1和第2指标δ2而计算的变动指标δ确定出第1声音信号x1的平稳期间q1,但与第1指标δ1和第2指标δ2相应地确定平稳期间q1的方法并不限定于以上的例示。例如,信号解析部21对与第1指标δ1相对应的第1暂定期间和与第2指标δ2相对应的第2暂定期间进行确定。第1暂定期间例如是第1指标δ1低于阈值的有声音的期间。即,基本频率f1在时间上稳定的期间被确定为第1暂定期间。第2暂定期间例如是第2指标δ2低于阈值的有声音的期间。即,频谱形状在时间上稳定的期间被确定为第2暂定期间。信号解析部21将第1暂定期间和第2暂定期间相互地重复的期间确定为平稳期间q1。即,第1声音信号x1中的基本频率f1和频谱形状这两者在时间上稳定的期间被确定为平稳期间q1。如根据以上的说明所理解那样,在确定平稳期间q1时可以省略变动指标δ的计算。此外,在以上的说明中关注于平稳期间q1的确定,但关于第2声音信号x2中的平稳期间q2的确定也是同样的。
(2)在前述的方式中,将第1声音信号x1中的基本频率f1及频谱形状这两者在时间上稳定的期间确定为平稳期间q1,但也可以将第1声音信号x1中的基本频率f1及频谱形状中的一者在时间上稳定的期间确定为平稳期间q1。同样地,也可以将第2声音信号x2中的基本频率f2及频谱形状中的一者在时间上稳定的期间确定为平稳期间q2。
(3)在前述的方式中,将第1声音信号x1中的合成开始时刻tm_r或者合成结束时刻tm_a的频谱包络概略形状g1利用为基准频谱包络概略形状g1_ref,但基准频谱包络概略形状g1_ref被提取的时刻(第1时刻)并不限定于以上的例示。例如,也可以将平稳期间q1的端点(起点时刻t1_s或者终点时刻t1_e)的频谱包络概略形状g1作为基准频谱包络概略形状g1_ref。但是,基准频谱包络概略形状g1_ref被提取的第1时刻,优选是第1声音信号x1中的频谱形状稳定的平稳期间q1内的时刻。
关于基准频谱包络概略形状g2_ref也是同样的。即,在前述的方式中,将第2声音信号x2中的合成开始时刻tm_r或者合成结束时刻tm_a的频谱包络概略形状g2利用为基准频谱包络概略形状g2_ref,但基准频谱包络概略形状g2_ref被提取的时刻(第2时刻)并不限定于以上的例示。例如,也可以将平稳期间q2的端点(起点时刻t2_s或者终点时刻t2_e)的频谱包络概略形状g2作为基准频谱包络概略形状g2_ref。但是,基准频谱包络概略形状g2_ref被提取的第2时刻,优选是第2声音信号x2中的频谱形状稳定的平稳期间q2内的时刻。
另外,第1声音信号x1中的基准频谱包络概略形状g1_ref被提取的第1时刻和第2声音信号x2中的基准频谱包络概略形状g2_ref被提取的第2时刻也可以是时间轴上的不同的时刻。
(4)在前述的方式中,对表示由声音处理装置100的利用者歌唱出的歌唱语音的第1声音信号x1进行了处理,但第1声音信号x1所表示的语音并不限定于利用者的歌唱语音。例如也可以对通过片段连接型或者统计模型的公知的语音合成技术合成的第1声音信号x1进行处理。另外,也可以对从光盘等记录介质读出的第1声音信号x1进行处理。关于第2声音信号x2也是同样地,通过任意的方法而取得。
另外,第1声音信号x1及第2声音信号x2所表示的声响,并不限定于狭义的语音(即人类发出的语言声音)。例如,在表示乐器的演奏音的第1声音信号x1中附加各种声音表现(例如演奏表现)的情况下也可以应用本发明。例如,针对表示没有附加演奏表现的单调的演奏音的第1声音信号x1,利用第2声音信号x2而附加颤音等演奏表现。
(5)前述的方式所涉及的声音处理装置100的功能如前述那样,是通过由大于或等于1个处理器执行在存储器中存储的指示(程序)而实现的。以上的程序以储存于计算机可读取的记录介质的方式被提供而能够安装于计算机。记录介质例如是非易失性(non-transitory)的记录介质,优选例为cd-rom等光学式记录介质(光盘),但也包含半导体记录介质或者磁记录介质等公知的任意形式的记录介质。此外,非易失性的记录介质包含除了暂时性的传输信号(transitory,propagatingsignal)以外的任意的记录介质,并不是将易失性的记录介质排除在外。另外,在传送装置经由通信网对程序进行传送的结构中,在该传送装置中对程序进行存储的存储装置相当于前述的非易失性的记录介质。
<附记>
根据以上例示出的方式,例如掌握下面的结构。
本发明的优选的方式(第1方式)所涉及的声音处理方法,其与表示第1音的第1声音信号的第1频谱包络概略形状与所述第1声音信号中的第1时刻的第1基准频谱包络概略形状的差分即第1差分、以及表示声响特性与所述第1音存在差异的第2音的第2声音信号的第2频谱包络概略形状和所述第2声音信号中的第2时刻的第2基准频谱包络概略形状的差分即第2差分相应地使所述第1频谱包络概略形状变形,由此生成表示将所述第1音与所述第2音相应地变形的变形音的第3声音信号中的合成频谱包络概略形状,生成与所述合成频谱包络概略形状相对应的所述第3声音信号。在以上的方式中,将第1声音信号的第1频谱包络概略形状和第1基准频谱包络概略形状之间的第1差分、以及第2声音信号的频谱包络概略形状和第2基准频谱包络概略形状之间的第2差分合成为第1频谱包络概略形状,由此生成将第1音与第2音相应地变形的变形音的合成频谱包络概略形状。因此,能够生成第1声音信号中的合成了第2声音信号的期间和该期间的前后的期间的边界处声响特性连续的听觉上自然的变形音。
此外,频谱包络概略形状是频谱包络的概略形状。具体地说,以无法察觉到音位性(音位间的差异)及个体性(说话者之间的差异)的程度将频谱包络进行了平滑化的频率轴上的强度分布相当于频谱包络概略形状。通过表示频谱的概略形状的梅尔倒谱的多个系数中的位于低阶侧的规定个数的系数而表现频谱包络概略形状。
在第1方式的优选例(第2方式)中,对所述第2声音信号相对于所述第1声音信号的时间上的位置进行调整,以使得在所述第1声音信号的频谱形状在时间上稳定的第1平稳期间和所述第2声音信号的频谱形状在时间上稳定的第2平稳期间之间它们的终点一致,所述第1时刻是所述第1平稳期间内的时刻,所述第2时刻是所述第2平稳期间内的时刻,所述合成频谱包络概略形状是在所述第1声音信号和所述调整后的所述第2声音信号之间生成的。在第2方式的优选例(第3方式)中,所述第1时刻及所述第2时刻是所述第1平稳期间的起点及所述第2平稳期间的起点中的后方的时刻。在以上的方式中,在第1平稳期间和第2平稳期间之间使它们终点一致时,第1平稳期间的起点及第2平稳期间的起点中的后方的时刻被选定为第1时刻及第2时刻。因此,能够一边在第1平稳期间及第2平稳期间的起点处维持声响特性的连续性,一边生成将第2音中的释音部的声响特性附加于第1音的变形音。
在第1方式的优选例(第4方式)中,对所述第2声音信号相对于所述第1声音信号的时间上的位置进行调整,以使得在所述第1声音信号的频谱形状在时间上稳定的第1平稳期间和所述第2声音信号的频谱形状在时间上稳定的第2平稳期间之间它们的起点一致,所述第1时刻是所述第1平稳期间内的时刻,所述第2时刻是所述第2平稳期间内的时刻,所述合成频谱包络概略形状是在所述第1声音信号和所述调整后的所述第2声音信号之间生成的。在第4方式的优选例(第5方式)中,所述第1时刻及所述第2时刻是所述第1平稳期间的起点。在以上的方式中,在第1平稳期间和第2平稳期间之间使它们的起点一致时,第1平稳期间的起点(第2平稳期间的起点)被选定为第1时刻及第2时刻。因此,能够一边抑制第1平稳期间的起点的移动,一边生成将第2音的发音点附近处的声响特性附加于第1音的变形音。
在第2方式至第5方式的任一方式的优选例(第6方式)中,所述第1平稳期间是与表示所述第1声音信号的基本频率的变化程度的第1指标和表示所述第1声音信号的所述频谱形状的变化程度的第2指标相应地确定的。根据以上的方式,能够将基本频率和频谱形状这两者在时间上稳定的期间确定为第1平稳期间。此外,例如设想下述结构,即,对与第1指标和第2指标相对应的变动指标进行计算,与该变动指标相应地确定第1平稳期间。另外,也能够与第1指标相应地确定第1暂定期间,与第2指标相应地确定第2暂定期间,根据第1暂定期间和第2暂定期间而确定第1平稳期间。
在第1方式至第6方式的任一方式的优选例(第7方式)中,在生成所述合成频谱包络概略形状时,相对于所述第1频谱包络概略形状,减去对所述第1差分乘以第1系数而得到的结果,加上对所述第2差分乘以第2系数而得到的结果。在以上的方式中,从第1频谱包络概略形状减去对第1差分乘以第1系数而得到的结果,将对第2差分乘以第2系数而得到的结果与第1频谱包络概略形状相加,由此生成合成频谱包络概略形状的时间序列。因此,能够减少第1音的声音表现,并且生成将第2音的声音表现有效附加的变形音。
在第1方式至第7方式的任一方式的优选例(第8方式)中,在生成所述合成频谱包络概略形状时,将所述第1声音信号的处理期间与所述第2声音信号中的应该应用于所述第1声音信号的变形的表现期间的时间长度相应地伸长,将所述伸长后的处理期间的所述第1频谱包络概略形状与所述伸长后的处理期间的所述第1差分和所述表现期间的所述第2差分相应地变形,由此生成所述合成频谱包络概略形状。
本发明的优选的方式(第9方式)所涉及的声音处理装置,其具有存储器和大于或等于1个处理器,该声音处理装置通过由所述大于或等于1个处理器执行在所述存储器中存储的指示,从而与表示第1音的第1声音信号的第1频谱包络概略形状和所述第1声音信号中的第1时刻的第1基准频谱包络概略形状的差分即第1差分、以及表示声响特性与所述第1音存在差异的第2音的第2声音信号的第2频谱包络概略形状和所述第2声音信号中的第2时刻的第2基准频谱包络概略形状的差分即第2差分相应地使所述第1频谱包络概略形状变形,由此生成表示将所述第1音与所述第2音相应地变形的变形音的第3声音信号的合成频谱包络概略形状,生成与所述合成频谱包络概略形状相对应的所述第3声音信号。
在第9方式的优选例(第10方式)中,对所述第2声音信号相对于所述第1声音信号的时间上的位置进行调整,以使得在所述第1声音信号的频谱形状在时间上稳定的第1平稳期间和所述第2声音信号的频谱形状在时间上稳定的第2平稳期间之间它们的终点一致,所述第1时刻是所述第1平稳期间内的时刻,所述第2时刻是所述第2平稳期间内的时刻,所述合成频谱包络概略形状是在所述第1声音信号和所述调整后的所述第2声音信号之间生成的。在第10方式的优选例(第11方式)中,所述第1时刻及所述第2时刻是所述第1平稳期间的起点及所述第2平稳期间的起点中的后方的时刻。
在第9方式的优选例(第12方式)中,对所述第2声音信号相对于所述第1声音信号的时间上的位置进行调整,以使得在所述第1声音信号的频谱形状在时间上稳定的第1平稳期间和所述第2声音信号的频谱形状在时间上稳定的第2平稳期间之间它们的起点一致,所述第1时刻是所述第1平稳期间内的时刻,所述第2时刻是所述第2平稳期间内的时刻,所述合成频谱包络概略形状是在所述第1声音信号和所述调整后的所述第2声音信号之间生成的。在第12方式的优选例(第13方式)中,所述第1时刻及所述第2时刻是所述第1平稳期间的起点。
在第9方式至第13方式的任一方式的优选例(第14方式)中,所述大于或等于1个处理器进行下述处理,即,相对于所述第1频谱包络概略形状,减去对所述第1差分乘以第1系数而得到的结果,加上对所述第2差分乘以第2系数而得到的结果。
本发明的优选的方式(第15方式)所涉及的记录介质是计算机可读取的记录介质,其记录有使计算机执行下述处理的程序:第1处理,与表示第1音的第1声音信号的第1频谱包络概略形状和所述第1声音信号中的第1时刻的第1基准频谱包络概略形状的差分即第1差分、以及表示声响特性与所述第1音存在差异的第2音的第2声音信号的第2频谱包络概略形状和所述第2声音信号中的第2时刻的第2基准频谱包络概略形状的差分即第2差分相应地使所述第1频谱包络概略形状变形,由此生成表示将所述第1音与所述第2音相应地变形的变形音的第3声音信号中的合成频谱包络概略形状;以及第2处理,生成与所述合成频谱包络概略形状相对应的所述第3声音信号。
标号的说明
100…声音处理装置,11…控制装置,12…存储装置,13…操作装置,14…放音装置,21…信号解析部,22…合成处理部,31…起音处理部,32…释音处理部,33…语音合成部。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



