
 商标分类
商标分类  商标转让
商标转让 
声音处理方法、声音处理装置及程序与流程
 2021-01-28 16:01:18|
2021-01-28 16:01:18| 254|
254| 起点商标网
起点商标网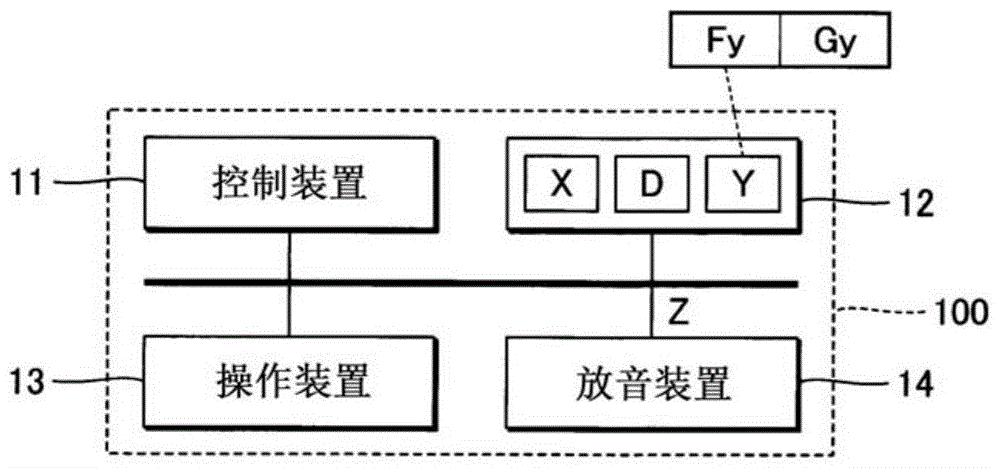
本发明涉及用于在歌唱语音等的音响中附加表现的技术。
背景技术:
以往提出了将歌唱表现等语音表现附加于语音的各种技术。例如在专利文献1中公开了生成语音信号的技术,该语音信号表示附加有各种语音表现的语音。附加于语音信号所表示的语音的语音表现由利用者从多个候选进行选择。另外,与语音表现的附加相关的参数对应于来自利用者的指示进行调整。
专利文献1:日本特开2017-41213号公报
技术实现要素:
但是,为了从多个候选中适当地选择附加于语音的语音表现,适当地调整与语音表现的附加相关的参数,需要与语音表现相关的专门知识。即使在利用者具有专门知识的情况下,也需要语音表现的选择及调整这一繁琐的作业。考虑以上的情况,本发明的优选的方式的目的在于,不需要与语音表现相关的专门知识及繁琐的作业,生成适当地附加有语音表现的听觉上自然的语音。
为了解决以上的课题,本发明的一个方式所涉及的声音处理方法,其与表示音符的音符数据相应地,对表示应附加于所述音符的声音表现的表现样本和附加该声音表现的表现期间进行确定,与所述表现样本及所述表现期间相应地确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数,执行与所述表现样本、所述表现期间和所述处理参数相对应的所述表现附加处理。
本发明的其他方式所涉及的声音处理方法,与表示应附加于音符数据所表示的音符的声音表现的表现样本和附加该声音表现的表现期间相应地,确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数,执行与所述处理参数相对应的所述表现附加处理。
本发明的一个方式所涉及的声音处理装置,具有:第1确定部,其与表示音符的音符数据相应地,对表示应附加于所述音符的声音表现的表现样本和附加该声音表现的表现期间进行确定;第2确定部,其与所述表现样本及所述表现期间相应地确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数;以及表现附加部,其执行与所述表现样本、所述表现期间和所述处理参数相对应的所述表现附加处理
本发明的其他方式所涉及的声音处理装置,具有:确定处理部,其与表示应附加于音符数据所表示的音符的声音表现的表现样本和附加该声音表现的表现期间相应地,确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数;以及表现附加部,其执行与所述处理参数相对应的所述表现附加处理。
本发明的优选的方式所涉及的程序,使计算机作为下述部分起作用:第1确定部,其与表示音符的音符数据相应地,对表示应附加于所述音符的声音表现的表现样本和附加该声音表现的表现期间进行确定;第2确定部,其与所述表现样本及所述表现期间相应地确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数;以及表现附加部,其执行与所述表现样本、所述表现期间和所述处理参数相对应的所述表现附加处理。
附图说明
图1是例示本发明的实施方式所涉及的信息处理装置的结构的框图。
图2是频谱包络概略形状的说明图。
图3是例示信息处理装置的功能性结构的框图。
图4是例示表现附加处理的具体的顺序的流程图。
图5是表现附加处理的说明图。
图6是例示信息处理装置的动作的流程图。
具体实施方式
图1是例示本发明的优选的方式所涉及的信息处理装置100的结构的框图。本实施方式的信息处理装置100是针对通过乐曲的歌唱而发音的语音(以下称为“歌唱语音”)附加各种语音表现的语音处理装置。语音表现是针对歌唱语音而附加的音响特性。如果关注乐曲的歌唱,则语音表现是与语音的发音(即歌唱)相关的音乐性表现或者表情。具体地说,气泡音(vocalfry)、咆哮声(growl)或者嘶哑声(rough)这样的歌唱表现是语音表现的优选例。此外,语音表现也改叫作音质。
语音表现在发音的起点侧的部分(以下称为“起音部”)和发音的终点侧的部分(以下称为“释音部”)存在显著化的倾向。考虑以上的倾向,在本实施方式中,针对歌唱语音中的特别是起音部及释音部附加语音表现。因此,能够在沿着与语音表现相关的实际的倾向的适当的位置处附加语音表现。此外,起音部是在发音刚开始后音量不断增加的部分,释音部是在发音刚要结束前音量不断减少的部分。
如图1例示那样,信息处理装置100是通过具有控制装置11、存储装置12、操作装置13和放音装置14的计算机系统实现的。例如移动电话机或者智能手机等移动式的信息终端、或者个人计算机等移动式或者固定式的信息终端适合用作信息处理装置100。操作装置13是接收来自利用者的指示的输入设备。例如,利用者进行操作的多个操作件、或者对利用者的接触进行检测的触摸面板适合用作操作装置13。
控制装置11例如由cpu(centralprocessingunit)等大于或等于1个处理器构成,执行各种运算处理及控制处理。本实施方式的控制装置11生成语音信号z,该语音信号z表示对歌唱语音附加有语音表现的语音(以下称为“加工语音”)。放音装置14例如是扬声器或者耳机,对由控制装置11生成的语音信号z所表示的加工语音进行放音。此外,方便起见而省略了将由控制装置11生成的语音信号z从数字变换为模拟的d/a变换器的图示。此外,在图1中例示出信息处理装置100具有放音装置14的结构,但也可以将与信息处理装置100分体的放音装置14通过有线或者无线而与信息处理装置100连接。
存储装置12例如是由磁性记录介质或者半导体记录介质等公知的记录介质构成的存储器,对由控制装置11执行的程序(即针对处理器的指示的系列)和由控制装置11使用的各种数据进行存储。此外,也可以通过多种记录介质的组合而构成存储装置12。另外,也可以准备与信息处理装置100分体的存储装置12(例如云储存器),控制装置11经由通信网而执行相对于存储装置12的写入及读出。即,也可以从信息处理装置100省略存储装置12。
本实施方式的存储装置12对语音信号x、乐曲数据d和多个表现样本y进行存储。语音信号x是表示通过乐曲的歌唱发音出的歌唱语音的音响信号。乐曲数据d是表示将由歌唱语音所表示的乐曲构成的音符的时间序列的音乐文件。即,在语音信号x和乐曲数据d之间乐曲是共通的。具体地说,乐曲数据d关于构成乐曲的多个音符的各个音符对音高、发音期间和发音强度进行指定。例如依照midi(musicalinstrumentdigitalinterface)标准的形式的文件(smf:standardmidifile)适合作为乐曲数据d。
语音信号x例如是通过收录利用者的歌唱而生成的。此外,也可以将从传送装置传送出的语音信号x存储于存储装置12。乐曲数据d是通过对语音信号x进行解析而生成的。但是,语音信号x及乐曲数据d的生成方法并不限定于以上的例示。例如,也可以与来自利用者的针对操作装置13的指示相应地对乐曲数据d进行编辑,通过利用了该乐曲数据d的公知的语音合成处理而生成语音信号x。也可以将从传送装置传送出的乐曲数据d利用于语音信号x的生成。
多个表现样本y各自是表示应附加于歌唱语音的语音表现的数据。具体地说,各表现样本y表示附加语音表现而歌唱出的语音(以下称为“参照语音”)的音响特性。语音表现的种类(例如咆哮声或者嘶哑声等的分类)关于多个表现样本y是共通的,但音量的时间上的变化或者时间长度等特性针对每个表现样本y而存在差异。在多个表现样本y中包含参照语音的起音部的表现样本y和释音部的表现样本y。此外,关于多种语音表现分别将多个表现样本y存储于存储装置12,例如可以选择性地利用与由利用者选择出的1种语音表现相对应的多个表现样本y。
本实施方式的信息处理装置100通过将表现样本y所表示的参照语音的语音表现附加于语音信号x的歌唱语音,从而生成维持了歌唱语音的音位及音高的加工语音的语音信号z。此外,基本上歌唱语音的发声者和参照语音的发声者为不同人,但歌唱语音的发声者和参照语音的发声者也可以是同一人。例如,歌唱语音是不附加语音表现而由利用者歌唱出的语音,参照语音是该利用者附加了歌唱表现的语音。
如图1例示那样,各表现样本y包含基本频率fy的时间序列和频谱包络概略形状gy的时间序列而构成。频谱包络概略形状gy如图2例示那样,是指将参照语音的频谱q1的概略形状即频谱包络q2在频率区域进一步平滑化后的强度分布。具体地说,以无法察觉到音位性(依赖于音位的差异)及个体性(依赖于发声者的差异)的程度将频谱包络q2平滑化后的强度分布是频谱包络概略形状gy。例如通过表示频谱包络q2的梅尔倒谱的多个系数中的位于低阶侧的规定个数的系数表现频谱包络概略形状gy。此外,在以上的说明中关注了表现样本y的频谱包络概略形状gy,但关于表示歌唱语音的语音信号x也能够认为是相同的定义的频谱包络概略形状gx。
图3是例示控制装置11的功能性的结构的框图。如图3例示那样,控制装置11通过执行在存储装置12中存储的程序,从而实现用于生成语音信号z的多个功能(确定处理部20及表现附加部30)。此外,也可以通过相互地分体构成的多个装置实现控制装置11的功能,也可以将控制装置11的功能的一部分或者全部通过专用的电子电路实现。
<表现附加部30>
表现附加部30关于在存储装置12中存储的语音信号x,执行用于对歌唱语音附加语音表现的处理(以下称为“表现附加处理”)s3。通过针对语音信号x的表现附加处理s3而生成加工语音的语音信号z。图4是例示表现附加处理s3的具体的顺序的流程图,图5是表现附加处理s3的说明图。
如图5例示那样,针对语音信号x中的大于或等于1个期间(以下称为“表现期间”)eb,附加从在存储装置12中存储的多个表现样本y选择出的表现样本ea。表现期间eb是由乐曲数据d指定的各音符的发音期间中的与起音部或者释音部相对应的期间。在图5中例示出对语音信号x的起音部附加表现样本ea的情况。
如图4例示那样,表现附加部30将从多个表现样本y选择出的表现样本ea以与表现期间eb相对应的伸缩率r在时间上进行伸缩(s31)。而且,表现附加部30使语音信号x中的表现期间eb内的部分与伸缩后的表现样本ea相应地变形(s32、s33)。语音信号x的变形是针对每个表现期间eb而执行的。具体地说,表现附加部30如下面详述那样,在语音信号x和表现样本ea之间,执行基本频率的合成(s32)和频谱包络概略形状的合成(s33)。此外,基本频率的合成(s32)和频谱包络概略形状的合成(s33)的顺序是任意的。
<基本频率的合成(s32)>
表现附加部30通过下面的算式(1)的运算对表现期间eb内的各时刻t的语音信号z的基本频率f(t)进行计算。
f(t)=fx(t)-αx(fx(t)-fx(t))+αy(fy(t)-fy(t))…(1)
算式(1)的基本频率fx(t)是时间轴上的时刻t下的语音信号x的基本频率(音高)。基准频率fx(t)是将基本频率fx(t)的时间序列在时间轴上进行平滑化时的时刻t下的频率。另外,算式(1)的基本频率fy(t)是伸缩后的表现样本ea中的时刻t下的基本频率fy。基准频率fy(t)是将基本频率fy(t)的时间序列在时间轴上进行平滑化时的时刻t下的频率。算式(1)的系数αx及系数αy设定为小于或等于1的非负值(0≤αx≤1、0≤αy≤1)。
如根据算式(1)所理解那样,算式(1)的第2项是以与系数αx相对应的程度从语音信号x的基本频率fx(t)减去歌唱语音的基本频率fx(t)和基准频率fx(t)的差分的处理。另外,算式(1)的第3项是以与系数αy相对应的程度,将表现样本ea的基本频率fy(t)和基准频率fy(t)的差分附加于语音信号x的基本频率fx(t)的处理。如根据以上说明所理解那样,表现附加部30将歌唱语音的基本频率fx(t)和基准频率fx(t)的差分置换为参照语音的基本频率fy(t)和基准频率fy(t)的差分。即,语音信号x的表现期间eb内的基本频率fx(t)的时间变化接近表现样本ea中的基本频率fy(t)的时间变化。
<频谱包络概略形状的合成(s33)>
表现附加部30通过下面的算式(2)的运算对表现期间eb内的各时刻t下的语音信号z的频谱包络概略形状g(t)进行计算。
g(t)=gx(t)-βx(gx(t)-gx)+βy(gy(t)-gy)…(2)
算式(2)的频谱包络概略形状gx(t)是时间轴上的时刻t下的语音信号x的频谱包络的概略形状。基准频谱包络概略形状gx是表现期间eb内的确定的时刻下的语音信号x的频谱包络概略形状gx(t)。例如,表现期间eb的端点(例如起点或者终点)处的频谱包络概略形状gx(t)被利用为基准频谱包络概略形状gx。此外,也可以将表现期间eb内的频谱包络概略形状gx(t)的代表值(例如平均值)利用为基准频谱包络概略形状gx。
算式(2)的频谱包络概略形状gy(t)是时间轴上的时刻t下的表现样本ea的频谱包络概略形状gy。基准频谱包络概略形状gy是表现期间eb内的确定的时刻下的语音信号x的频谱包络概略形状gy(t)。例如,表现样本ea的端点(例如起点或者终点)处的频谱包络概略形状gy(t)被利用为基准频谱包络概略形状gy。此外,也可以将表现样本ea内的频谱包络概略形状gy(t)的代表值(例如平均值)利用为基准频谱包络概略形状gy。
算式(2)的系数βx及系数βy设定为小于或等于1的非负值(0≤βx≤1、0≤βy≤1)。算式(2)的第2项是以与系数βx相对应的程度从语音信号x的频谱包络概略形状gx(t)减去歌唱语音的频谱包络概略形状gx(t)和基准频谱包络概略形状gx的差分的处理。另外,算式(2)的第3项是以与系数βy相对应的程度将表现样本ea的频谱包络概略形状gy(t)和基准频谱包络概略形状gy的差分附加于语音信号x的频谱包络概略形状gx(t)的处理。如根据以上的说明所理解那样,表现附加部30将歌唱语音的频谱包络概略形状gx(t)和基准频谱包络概略形状gx的差分置换为表现样本ea的频谱包络概略形状gy(t)和基准频谱包络概略形状gy的差分。
表现附加部30利用以上例示出的处理的结果(即基本频率f(t)及频谱包络概略形状g(t)),生成加工语音的语音信号z(s34)。具体地说,表现附加部30将语音信号x的各频谱调整为沿着算式(2)的频谱包络概略形状g(t),且将语音信号x的基本频率fx(t)调整为基本频率f(t)。语音信号x的频谱及基本频率fx(t)的调整例如在频率区域中执行。表现附加部30通过将以上例示出的调整后的频谱置换为时间区域而生成语音信号z(s35)。
如以上例示那样,在表现附加处理s3中,语音信号x中的表现期间eb内的基本频率fx(t)的时间序列,与对应于表现样本ea的基本频率fy(t)的时间序列和系数αx及系数αy相应地变更。另外,在表现附加处理s3中,语音信号x中的表现期间eb内的频谱包络概略形状gx(t)的时间序列,与对应于表现样本ea的频谱包络概略形状gy(t)的时间序列和系数βx及系数βy相应地变更。表现附加处理s3的具体的顺序如上所述。
<确定处理部20>
图3的确定处理部20关于由乐曲数据d指定的各音符,对表现样本ea、表现期间eb和处理参数ec进行确定。具体地说,关于由乐曲数据d指定的多个音符中的应附加语音表现的各音符,对表现样本ea、表现期间eb和处理参数ec进行确定。处理参数ec是与表现附加处理s3相关的参数。具体地说,处理参数ec如图4例示那样,包含应用于表现样本ea的伸缩(s31)的伸缩率r、应用于基本频率fx(t)的调整(s32)的系数αx及系数αy、以及应用于频谱包络概略形状gx(t)的调整(s33)的系数βx及系数βy。
如图3例示那样,本实施方式的确定处理部20具有第1确定部21和第2确定部22。第1确定部21与表示由乐曲数据d指定的各音符的音符数据n相应地对表现样本ea和表现期间eb进行确定。具体地说,第1确定部21输出表示表现样本ea的识别信息和表示表现期间eb的起点和/或终点的时刻的时刻数据。音符数据n是表示构成乐曲数据d所表示的乐曲的各音符的状况(关联性)的数据。具体地说,各音符的音符数据n例如对与该音符本身相关的信息(音高、时间长度、发音强度)和与其他音符之间的关系相关的信息(例如前后的无音期间的时间长度、与前后的音符的音高差)进行指定。控制装置11通过对乐曲数据d进行解析而生成各音符的音符数据n。
本实施方式的第1确定部21关于由音符数据n指定的音符而确定是否附加语音表现,关于被确定为附加语音表现的各音符而确定表现样本ea和表现期间eb。此外,向确定处理部20供给的各音符的音符数据n可以是仅对与该音符相关的信息(音高、时间长度、发音强度)进行指定的数据。与其他音符之间的关系相关的信息是根据与各音符相关的信息而生成,并提供给第1确定部21及第2确定部22的。
第2确定部22针对被确定为附加语音表现的每个音符,与表示由第1确定部21进行确定的结果(表现样本ea及表现期间eb)的控制数据c相应地确定处理参数ec。本实施方式的控制数据c包含表示由第1确定部21关于1个音符而确定出的表现样本ea及表现期间eb的数据、以及该音符的音符数据n而构成。由第1确定部21确定出的表现样本ea及表现期间eb和由第2确定部22确定出的处理参数ec如前面所述,应用于由表现附加部30进行的表现附加处理s3。此外,在第1确定部21输出仅表示表现期间eb的起点及终点中的一者的时刻数据的结构中,第2确定部22也可以将表现期间eb的起点和终点的时间差(即持续长度)确定为处理参数ec。
在通过确定处理部20进行各信息的确定时利用训练好的模型(m1、m2)。具体地说,第1确定部21通过将各音符的音符数据n输入至第1训练好的模型m1,从而确定表现样本ea及表现期间eb。第2确定部22通过将附加语音表现的各音符的控制数据c输入至第2训练好的模型m2,从而确定处理参数ec。
第1训练好的模型m1及第2训练好的模型m2是通过机器学习而生成的统计估计模型。具体地说,第1训练好的模型m1是对音符数据n和表现样本ea及表现期间eb的关系进行了训练(学习)的模型。第2训练好的模型m2是对控制数据c和处理参数ec的关系进行了训练(学习)的模型。例如神经网络等各种统计估计模型适合利用为第1训练好的模型m1及第2训练好的模型m2。第1训练好的模型m1及第2训练好的模型m2各自是通过使控制装置11执行根据输入数据而生成输出数据的运算的程序(例如构成人工智能软件的程序模块)和应用于该运算的多个系数的组合而实现的。多个系数通过利用了大量教师数据的机器学习(特别是深层学习)进行设定而保存于存储装置12。
作为构成第1训练好的模型m1及第2训练好的模型m2的神经网络,例如利用cnn(convolutionalneuralnetwork)或者rnn(recurrentneuralnetwork)等各种模型。另外,也可以利用包含lstm(longshort-termmemory)或者attention等附加性要素的神经网络。此外,也可以将除了以上例示出的神经网络以外的统计估计模型利用为第1训练好的模型m1及第2训练好的模型。例如利用决策树或者隐马尔可夫模型等各种模型。
第1训练好的模型m1将音符数据n作为输入数据,输出表现样本ea和表现期间eb。第1训练好的模型m1是通过利用了使音符数据n和表现样本ea及表现期间eb相关联的多个教师数据的机器学习而生成的。具体地说,以使关于多个教师数据而减小(理想情况为最小化)在将教师数据所包含的音符数据n输入至暂定的结构及系数的模型时所输出的表现样本ea及表现期间eb与由该教师数据指定的表现样本ea及表现期间eb之间的差异(即损耗函数)的方式对各系数反复地进行调整,由此设定第1训练好的模型m1的多个系数。此外,也可以通过省略系数小的节点,从而简化模型的结构。通过以上例示出的机器学习,第1训练好的模型m1基于多个教师数据中的音符数据n和表现样本ea及表现期间eb之间潜在的关系,针对未知的音符数据n而确定在统计上妥当的表现样本ea及表现期间eb。即,对与由音符数据n指定的各音符的状况(关联性)相适合的表现样本ea及表现期间eb进行确定。
在利用于第1训练好的模型m1的机器学习的多个教师数据中,取代表现样本ea及表现期间eb,还存在表示不附加语音表现的数据与音符数据n相关联的教师数据。因此,第1训练好的模型m1有时针对各音符的音符数据n,输出不对该音符附加语音表现这样的结果。例如,不对发音期间的时间长度短的音符附加语音表现。
第2训练好的模型m2将包含通过第1确定部21得到的确定结果和音符数据n在内的控制数据c作为输入数据而输出至处理参数ec。第2训练好的模型m2是通过利用了使控制数据c和处理参数ec相关联的多个教师数据的机器学习而生成的。具体地说,以使关于多个教师数据而减小(理想情况为最小化)在将教师数据所包含的控制数据c输入至暂定的结构及系数的模型时所输出的处理参数ec与由该教师数据指定的处理参数ec之间的差异(即损耗函数)的方式对各系数反复地进行调整,由此设定第2训练好的模型m2的多个系数。此外,也可以通过省略系数小的节点,从而简化模型的结构。通过以上例示出的机器学习,第2训练好的模型m2基于多个教师数据中的控制数据c和处理参数ec之间潜在的关系,针对未知的控制数据c(表现样本ea、表现期间eb及音符数据n)而确定在统计上妥当的处理参数ec。即,关于附加语音表现的各表现期间eb,对与附加于该表现期间eb的表现样本ea和该表现期间eb所属的音符的状况(关联性)相适合的处理参数ec进行确定。
图6是例示信息处理装置100的具体的动作的顺序的流程图。例如与来自利用者的针对操作装置13的操作相应地开始图6的处理,关于由乐曲数据d按照时间序列指定的多个音符的各个音符,依次执行图6的处理。
如果开始图6的处理,则确定处理部20与各音符的音符数据n相应地对表现样本ea、表现期间eb和处理参数ec进行确定(s1、s2)。具体地说,第1确定部21与音符数据n相应地对表现样本ea和表现期间eb进行确定(s1)。第2确定部22与控制数据c相应地对处理参数ec进行确定(s2)。表现附加部30通过应用了由确定处理部20确定出的表现样本ea、表现期间eb和处理参数ec的表现附加处理而生成加工语音的语音信号z(s3)。表现附加处理s3的具体的顺序如前所述。由表现附加部30生成的语音信号z供给至放音装置14,由此对加工语音进行放音。
如以上说明所述,在本实施方式中,表现样本ea、表现期间eb和处理参数ec与音符数据n相应地被确定,因此利用者无需执行表现样本ea及表现期间eb的指定和处理参数ec的设定。因此,不需要与语音表现相关的专门的知识、或者与语音表现相关的繁琐的作业,就能够生成适当地附加了语音表现的听觉上自然的语音。
在本实施方式中,通过将音符数据n输入至第1训练好的模型m1而确定表现样本ea及表现期间eb,通过将包含表现样本ea及表现期间eb在内的控制数据c输入至第2训练好的模型m2而确定处理参数ec。因此,关于未知的音符数据n,能够适当地确定表现样本ea、表现期间eb和处理参数ec。另外,语音信号x的基本频率fx(t)及频谱包络概略形状gx(t)与表现样本ea相应地变更,因此能够生成听觉上自然的语音的语音信号z。
<变形例>
下面,例示对以上的方式附加的具体的变形方式。可以将从下面的例示中任意地选择出的大于或等于2个方式在不相互矛盾的范围适当地合并。
(1)在前述的方式中例示出的音符数据n例如对与音符本身相关的信息(音高、时间长度、发音强度)和与其他音符之间的关系相关的信息(例如前后的无音期间的时间长度、与前后的音符之间的音高差)进行指定。音符数据n所表示的信息并不限定于以上的例示。例如,也可以利用对乐曲的演奏速度、或者指定于音符的音位(例如表示歌词的文字)进行指定的音符数据n。
(2)在前述的方式中,例示出确定处理部20具有第1确定部21和第2确定部22的结构,但对通过第1确定部21进行的表现样本ea及表现期间eb的确定和通过第2确定部22进行的处理参数ec的确定进行了区分的结构不是必须的。即,也可以是确定处理部20向训练好的模型输入音符数据n,由此对表现样本ea、表现期间eb和处理参数ec进行确定。
(3)在前述的方式中,例示出具有对表现样本ea及表现期间eb进行确定的第1确定部21和对处理参数ec进行确定的第2确定部22的结构,但也可以省略第1确定部21及第2确定部22中的一者。例如在省略了第1确定部21的结构中,通过针对操作装置13的操作而由利用者指示表现样本ea及表现期间eb。另外,例如在省略了第2确定部22的结构中,通过针对操作装置13的操作而由利用者设定处理参数ec。如根据以上的说明所理解那样,信息处理装置100也可以仅具有第1确定部21及第2确定部22中的一者。
(4)在前述的方式中,与音符数据n相应地判定出是否对各音符附加语音表现,但也可以还参考除了音符数据n以外的信息,判定是否附加语音表现。例如,还设想到下述结构,即,在语音信号x的表现期间eb中的特征量的变动大的情况下(即,在语音表现充分地附加于歌唱语音的情况下)不附加语音表现。
(5)在前述的方式中,对表示歌唱语音的语音信号x附加了语音表现,但应附加表现的音响并不限定于歌唱语音。例如,在针对通过乐器的演奏而发音的乐音附加各种演奏表现的情况下也应用本发明。即,表现附加处理s3统括地表现为对表示音响的音响信号(例如语音信号或者乐音信号)中的表现期间内的部分附加声音表现(例如歌唱表现或者演奏表现)的处理。
(6)在前述的方式中,例示出包含伸缩率r、系数αx、系数αy、系数βx及系数βy在内的处理参数ec,但处理参数ec所包含的参数的种类或者总数并不限定于以上的例示。例如,也可以由第2确定部22确定系数αx及系数αy中的一者,通过从1减去该系数而计算另一者。同样地,也可以由第2确定部22确定系数βx及系数βy中的一者,通过从1减去该系数而计算另一者。另外,在将伸缩率r固定为规定值的结构中,从由第2确定部22确定的处理参数ec将伸缩率r排除在外。
(7)前述的方式所涉及的信息处理装置100的功能如前述那样,是通过控制装置11等的处理器和在存储器中存储的程序的协同动作而实现的。前述的方式所涉及的程序以收容于计算机可读取的记录介质中的方式被提供而安装于计算机。记录介质例如是非易失性(non-transitory)的记录介质,优选例为cd-rom等光学式记录介质(光盘),但也包含半导体记录介质或者磁记录介质等公知的任意形式的记录介质。此外,非易失性的记录介质包含除了暂时性的传输信号(transitory,propagatingsignal)以外的任意的记录介质,并不是将易失性的记录介质排除在外。另外,在传送装置经由通信网而传送程序的结构中,在该传送装置中存储程序的存储装置相当于前述的非易失性的记录介质。
<附记>
根据以上例示出的方式,例如掌握以下的结构。
本发明的一个方式(第1方式)所涉及的声音处理方法,与表示音符的音符数据相应地,对表示应附加于所述音符的声音表现的表现样本和附加该声音表现的表现期间进行确定,与所述表现样本及所述表现期间相应地确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数,执行与所述表现样本、所述表现期间和所述处理参数相对应的所述表现附加处理。根据以上的方式,与音符数据相应地确定表现样本及表现期间和表现附加处理的处理参数,因此无需由利用者设定表现样本、表现期间和处理参数。因此,不需要与声音表现相关的专门的知识、或者与声音表现相关的繁琐的作业,就能够生成适当地附加了声音表现的听觉上自然的音响。
在第1方式的一个例子(第2方式)中,在所述表现样本及所述表现期间的确定时,通过将所述音符数据输入至第1训练好的模型,从而确定所述表现样本及所述表现期间。
在第2方式的一个例子(第3方式)中,在所述处理参数的确定时,通过将表示所述表现样本及所述表现期间的控制数据输入至第2训练好的模型,从而确定所述处理参数。
在第1方式至第3方式的任一个例子(第4方式)中,在所述表现期间的确定时,将包含所述音符的起点的起音部、或者包含所述音符的终点的释音部确定为所述表现期间。
在第1方式至第4方式的任一个例子(第5方式)中,在所述表现附加处理中,与对应于所述表现样本的基本频率和所述处理参数相应地对所述表现期间内的所述音响信号的基本频率进行变更,与对应于所述表现样本的频谱包络概略形状和所述处理参数相应地对所述表现期间内的所述音响信号的频谱包络概略形状进行变更。
本发明的一个方式(第6方式)所涉及的声音处理方法,与表示应附加于音符数据所表示的音符的声音表现的表现样本和附加该声音表现的表现期间相应地,确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数,执行与所述处理参数相对应的所述表现附加处理。根据以上的方式,与表现样本和表现期间相应地确定表现附加处理的处理参数,无需由利用者设定处理参数。因此,不需要与声音表现相关的专门的知识、或者与声音表现相关的繁琐的作业,就能够生成适当地附加了声音表现的听觉上自然的音响。
本发明的一个方式(第7方式)所涉及的声音处理装置,具有:第1确定部,其与表示音符的音符数据相应地,对表示应附加于所述音符的声音表现的表现样本和附加该声音表现的表现期间进行确定;第2确定部,其与所述表现样本及所述表现期间相应地确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数;以及表现附加部,其执行与所述表现样本、所述表现期间和所述处理参数相对应的所述表现附加处理。根据以上的方式,与音符数据相应地确定表现样本及表现期间和表现附加处理的处理参数,无需由利用者设定表现样本、表现期间和处理参数。因此,不需要与声音表现相关的专门的知识、或者与声音表现相关的繁琐的作业,就能够生成适当地附加了声音表现的听觉上自然的音响。
在第7方式的一个例子(第8方式)中,所述第1确定部通过将所述音符数据输入至第1训练好的模型,从而确定所述表现样本及所述表现期间。
在第8方式的一个例子(第9方式)中,所述第2确定部通过将表示所述表现样本及所述表现期间的控制数据输入至第2训练好的模型,从而确定所述处理参数。
在第7方式至第9方式的任一个例子(第10方式)中,所述第1确定部将包含所述音符的起点的起音部、或者包含所述音符的终点的释音部确定为所述表现期间。
在第7方式至第10方式的任一个例子(第11方式)中,所述表现附加部,与对应于所述表现样本的基本频率和所述处理参数相应地对所述表现期间内的所述音响信号的基本频率进行变更,与对应于所述表现样本的频谱包络概略形状和所述处理参数相应地对所述表现期间内的所述音响信号的频谱包络概略形状进行变更。
本发明的一个方式(第12方式)所涉及的声音处理装置,具有:确定处理部,其与表示应附加于音符数据所表示的音符的声音表现的表现样本和附加该声音表现的表现期间相应地,确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数;以及表现附加部,其执行与所述处理参数相对应的所述表现附加处理。根据以上的方式,与表现样本和表现期间相应地确定表现附加处理的处理参数,无需由利用者设定处理参数。因此,不需要与声音表现相关的专门的知识、或者与声音表现相关的繁琐的作业,就能够生成适当地附加了声音表现的听觉上自然的音响。
本发明的一个方式(第13方式)所涉及的程序,使计算机作为下述部分起作用:第1确定部,其与表示音符的音符数据相应地,对表示应附加于所述音符的声音表现的表现样本和附加该声音表现的表现期间进行确定;第2确定部,其与所述表现样本及所述表现期间相应地确定与对音响信号中的所述表现期间内的部分附加所述声音表现的表现附加处理相关的处理参数;以及表现附加部,其执行与所述表现样本、所述表现期间和所述处理参数相对应的所述表现附加处理。根据以上的方式,与音符数据相应地确定表现样本及表现期间和表现附加处理的处理参数,无需由利用者设定表现样本、表现期间和处理参数。因此,不需要与声音表现相关的专门的知识、或者与声音表现相关的繁琐的作业,就能够生成适当地附加了声音表现的听觉上自然的音响。
标号的说明
100…信息处理装置,11…控制装置,12…存储装置,13…操作装置,14…放音装置,20…确定处理部,21…第1确定部,22…第2确定部,30…表现附加部。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



