
 商标分类
商标分类  商标转让
商标转让 
一种将图像转化为声音的可穿戴助盲系统及方法与流程
 2021-01-28 15:01:10|
2021-01-28 15:01:10| 262|
262| 起点商标网
起点商标网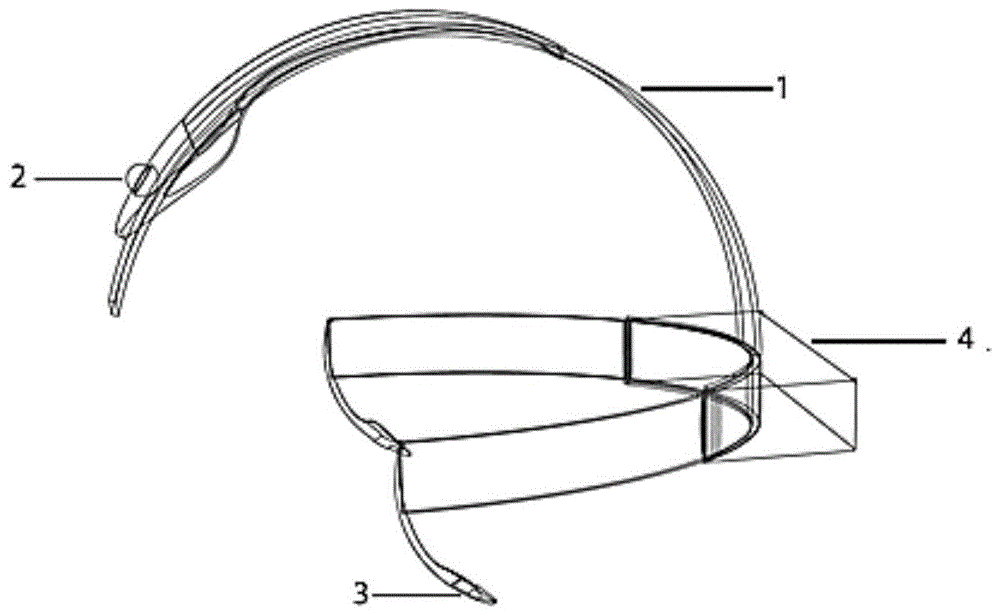
本发明涉及电子设备技术领域,特别涉及一种将图像转化为声音的可穿戴助盲系统及方法。
背景技术:
据世界卫生组织统计,全球至少有22亿人正面临视力受损或完全失明。由于盲人视力受阻,无法用眼睛体验美好的世界,因此在生活中有诸多的不便。由于无法看见眼前的事物,导致盲人单独出行困难,活动范围受限,无论是室内生活还是室外出行,都无法具备对事物足够的辨别能力。
目前,盲人可借助的助盲工具主要有导盲犬、非智能导盲杖以及智能助盲设备。其中,导盲犬需经过长时间训练,价格昂贵且饲养繁琐,在实际生活中难入公共场所。这种方式通过借助动物的感性牵引,会出现引导错误的情况,精准度无法验证,不可靠。非智能导盲杖通过敲击周围地面来判断使用者周围环境情况,这种方式不能分辨地理方位,使用者不能判断出前进方向以及周围障碍物形状、方位、速度等因素。这种方式用于单独出行是极其危险的。
而近年来各种智能助盲设备应运而生,如“震动衣服”,其利用传感器探测障碍物,并能利用振动提醒穿戴者注意避开这些障碍物;引导视觉导盲设备,其通过evtss技术可以在用户的大脑中建立一个二维视觉模型,帮助用户发现迎来的车辆和可能的障碍。这类产品由于研发成本高,技术不成熟等因素限制未能全面普及。已被广泛应用的产品,如图像识别语音描述、无障碍语音辅助系统,可帮助盲人识别物体,如动植物、交通工具、常规建筑,并通过语音播报的方式告诉盲人,如“这是一个苹果”、“左前方有一个坑,请注意避让”,但其方法的实现对图片内容的依赖程度大,对于更加具体且细致的内容,如脸上的表情、水杯的外观、家具的摆放情况等,现有技术难以表达出来。
因此,如何为盲人提供一种可呈现多样、具体、即时信息的导盲设备,以方便他们的日常生活是亟需解决的问题。
技术实现要素:
本发明提供了一种将图像转化为声音的可穿戴助盲系统及方法,以解决现有导盲设备提供的信息量有限、信息获取延时以及可靠程度低的问题。
为解决上述技术问题,本发明提供了如下技术方案:
一方面,本发明提供了一种将图像转化为声音的可穿戴助盲系统,所述系统包括:图像采集模块、图像处理及音频转换模块和音频输出模块;其中,
所述图像采集模块用于采集用户视觉范围内的环境信息,得到环境图像;
所述图像处理及音频转换模块包括图像处理单元和音频转换单元;其中,所述图像处理单元用于对所述环境图像进行预处理,所述音频转换单元用于将所述图像处理单元预处理后的图像转换为音频数据;其中,在所述音频数据中,所述环境图像中位于不同水平线上的像素点对应不同的声音频率,所述环境图像中不同亮度的像素点或距离预设参照点不同距离的像素点对应不同的音量;
所述音频输出模块用于播放所述音频转换单元生成的音频数据。
进一步地,所述可穿戴助盲系统还包括头盔;其中,所述图像采集模块、所述图像处理及音频转换模块,以及所述音频输出模块均设置在所述头盔上。
进一步地,所述图像采集模块为双目摄像头,所述图像处理及音频转换模块为树莓派处理器,所述音频输出模块为立体声耳机;其中,所述双目摄像头和立体声耳机分别与所述树莓派处理器电连接;所述树莓派处理器上设有usb供电接口,所述usb供电接口与移动电源电连接,所述移动电源用于为所述树莓派处理器供电。
进一步地,所述可穿戴助盲系统的工作模式包括图像模式和避障模式;
在所述图像模式下,所述双目摄像头仅其中一个摄像头工作,所述图像处理及音频转换模块用于将所述双目摄像头中单个摄像头采集的图像直接进行处理并转换为音频数据;
在所述避障模式下,所述双目摄像头的两个摄像头同时工作,所述图像处理及音频转换模块用于将双目摄像头获取的左右两张图像处理为一幅深度图,再对所述深度图进行处理并转换为音频数据;其中,在所述深度图中,离用户越近的地方亮度越大。
进一步地,在所述图像模式下,所述图像处理单元具体用于:对所述双目摄像头采集到的环境图像依次进行以下处理:以保留短边的方式裁剪为自定义比例,降低分辨率,灰度化,降噪滤波,边缘增强以及直方图规定化。
进一步地,在所述避障模式下,所述图像处理单元具体用于:对所述双目摄像头采集到的环境图像依次进行以下处理:将所述双目摄像头获取的两张图片处理为一幅深度图,以保留短边的方式裁剪为自定义比例,降低分辨率以及直方图规定化。
进一步地,所述音频转换单元具体用于:
通过下式将所述图像处理单元预处理后的图像转换为左右声道音频数据:
其中,fl(t)表示左声道的音频数据,fr(t)表示右声道的音频数据;m表示预处理后的图像像素的总行数,n表示预处理后的图像像素的总列数;im(i,j)在所述图像模式下表示第i行第j列的像素点的亮度,在所述避障模式下表示第i行第j列的像素点距离预设参照点的距离;f(i)表示第i行像素对应的声音频率;
s(i)表示音源音量矩阵,其表达式为:
进一步地,所述可穿戴助盲系统还包括手柄,所述手柄包括:第一调节键、第二调节键、第三调节键、第四调节键、空格键、左方向键、右方向键以及接收器;其中,
所述接收器与所述图像处理及音频转换模块通信连接,用于实现所述手柄与所述图像处理及音频转换模块的通信;所述第一调节键用于调节环境图像的分辨率,所述第二调节键用于调节音频数据的播放时长,所述第三调节键用于调节音频数据的听觉效果,所述第四调节键用于调节音量大小,所述空格键用于开启所述可穿戴助盲系统,所述左方向键和右方向键用于对所述第一调节键、第二调节键、第三调节键以及第四调节键对应的调节参数进行增大或减小。
另一方面,本发明还提供了一种将图像转化为声音的可穿戴助盲方法,所述将图像转化为声音的可穿戴助盲方法包括:
采集用户视觉范围内的环境信息并对采集的环境图像进行预处理;
将预处理后的图像转换为音频数据并播放;其中,在所述音频数据中,所述环境图像中位于不同水平线上的像素点对应不同的声音频率,所述环境图像中不同亮度的像素点或距离预设参照点不同距离的像素点对应不同的音量。
进一步地,所述将预处理后的图像转换为音频数据,包括:
通过下式将预处理后的图像转换为左右声道音频数据:
其中,fl(t)表示左声道的音频数据,fr(t)表示右声道的音频数据;m表示预处理后的图像像素的总行数,n表示预处理后的图像像素的总列数;im(i,j)在所述图像模式下表示第i行第j列的像素点的亮度,在所述避障模式下表示第i行第j列的像素点距离预设参照点的距离;f(i)表示第i行像素对应的声音频率;
s(i)表示音源音量矩阵,其表达式为:
再一方面,本发明还提供了一种电子设备,其包括处理器和存储器;其中,存储器中存储有至少一条指令,所述指令由处理器加载并执行以实现上述方法。
又一方面,本发明还提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述指令由处理器加载并执行以实现上述方法。
本发明提供的技术方案带来的有益效果至少包括:
本发明提供的将图像转化为声音的可穿戴助盲系统及方法结合感官替代技术,通过数学变换将图像转化为声音,而非图像识别与语音合成的方式。盲人通过一定练习后便可在脑海中复原画面,是一种不同于通过语言描述感知外部图像的真正视觉体验。在“避障模式”下,系统的音量大小可以反映障碍物的远近,可以解决盲人因视觉缺陷引起的距离感知缺陷,帮助盲人有效躲避障碍物。
相较于传统导盲杖,本发明的可穿戴助盲系统及方法探路范围广,可以帮助盲人躲避悬垂物等障碍物,功能更多样。相较于图像识别语言合成类助盲产品,本发明的可穿戴助盲系统及方法对图像的具体内容没有要求,信息损失小,适用范围广;相较于其他感官替代类助盲产品,本发明的可穿戴助盲系统及方法分辨率高,操作方便,且成本较低;相较于人工眼球等脑机接口类产品,本发明的可穿戴助盲系统及方法安全性好,分辨率高,而且成本极低。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的头盔的结构示意图;
图2是本发明实施例提供的手柄的结构示意图;
图3是本发明实施例提供的将图像转化为声音的可穿戴助盲方法的流程图。
附图标记说明:
1、头盔;2、图像采集模块;3、音频输出模块;
4、图像处理及音频转换模块;5、手柄;6、第一调节键;7、第二调节键;
8、第三调节键;9、第四调节键;10、空格键;11、左方向键;
12、右方向键;13、接收器。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
第一实施例
请参阅图1至图3,本实施例提供了一种将图像转化为声音的可穿戴助盲系统,其包括:图像采集模块2、图像处理及音频转换模块4和音频输出模块3;
图像采集模块2用于采集用户视觉范围内的环境信息,得到环境图像;
图像处理及音频转换模块4包括图像处理单元和音频转换单元;其中,图像处理单元用于对环境图像进行预处理,音频转换单元用于将图像处理单元预处理后的图像转换为音频数据;其中,在音频数据中,环境图像中位于不同水平线上的像素点对应不同的声音频率,环境图像中不同亮度的像素点或距离预设参照点不同距离的像素点对应不同的音量;
音频输出模块3用于播放音频转换单元生成的音频数据。
进一步地,本实施例的可穿戴助盲系统还包括头盔1;上述图像采集模块2、图像处理及音频转换模块4,以及音频输出模块3均设置在头盔1上。头盔1作为载体,用于固定图像采集模块2、图像处理及音频转换模块4,以及音频输出模块3。并且为了方便用户穿戴,头盔1上有十字松紧带用于固定在使用者头部。
此外,为了方便系统的调节,本实施例的可穿戴助盲系统还包括手柄5,该手柄5包括:第一调节键6、第二调节键7、第三调节键8、第四调节键9、空格键10、左方向键11、右方向键12以及接收器13;其中,接收器13与图像处理及音频转换模块4通信连接,用于实现手柄5与图像处理及音频转换模块4的通信,空格键10用于开启系统,第一调节键6、第二调节键7、第三调节键8、第四调节键9、左方向键11以及右方向键12用于调节系统的参数和功能。
具体地,在本实施例中,上述图像采集模块2为双目摄像头,图像处理及音频转换模块4为树莓派处理器,音频输出模块3为立体声耳机;其中,双目摄像头和立体声耳机分别与树莓派处理器电连接,手柄5与树莓派处理器通过蓝牙连接;树莓派处理器上设有usb供电接口,用于连接移动电源,为树莓派处理器供电。当然,可以理解的是,上述各模块也可以采用现有的其他硬件设备实现,本实施例在此并不限定用于实现上述各模块的硬件设备的种类及型号。
上述可穿戴助盲系统的工作模式包括图像模式和避障模式;其中,在图像模式下,双目摄像头仅其中一个摄像头工作,图像处理及音频转换模块4用于将双目摄像头中单个摄像头采集的图像直接进行处理并转换为音频数据;用于使用者欣赏绘画、图案、logo等。在避障模式下,双目摄像头的两个摄像头同时工作,图像处理及音频转换模块4用于将双目摄像头获取的左右两张图像处理为一幅深度图,再对深度图进行处理并转换为音频数据;其中,在深度图中,离用户越近的地方亮度越大;用于用户在行走时躲避障碍物,保障视力不便的用户的安全或用于用户在室内感知周围事物环境。
在图像模式下,摄像头实时采集环境图像,并将采集的图像传送给图像处理单元,图像处理单元对接收到的图像进行以下处理:以保留短边的方式裁剪为自定义比例,降低分辨率,灰度化,降噪滤波,边缘增强以及直方图规定化;然后将处理后的图像传给音频转换单元。在避障模式下,摄像头实时采集双目图像,并将采集的图像传送给图像处理单元,图像处理单元对接收到的图像进行以下处理:将双目摄像头获取的两张图片处理为一幅深度图,以保留短边的方式裁剪为自定义比例,降低分辨率以及直方图规定化,检测出人脸并用矩形框标记,然后将处理后的图像传给音频转换单元。
上述音频转换单元实现图像到音频的转换,包含参数初始化和图像数据转音频数据两个过程,具体如下:
参数初始化:
对于预处理后的图像,设其像素的总行数为m,像素的总列数为n,i为像素点的行数,1≤i≤m,j为像素点的列数,1≤j≤n。
参数初始化过程包括分配频率矩阵f(i),分配空间位置矩阵p(j),分配音源音量矩阵s(i),设定单帧时长frametime,根据单帧时长设定窗函数wi(t),结合单帧时长、窗函数分配出现节点矩阵ap(i,j),设定波函数wa(t.f),初始化左声道音量衰减系数矩阵a(i,j)及右声道音量衰减系数矩阵a′(i,j)和延迟时间矩阵d(j)。
分配频率矩阵f(i)有三种方式,分别对应五声音阶,半音阶,全音阶三种音频方案,产生三种不同的听觉效果。
五声音阶对应的分配频率矩阵f(i)的方式为:f(i)为第i行像素对应的声音频率。从图片的上到图片的下f(i)逐渐减小。为保证符合人耳的听力范围,有20<<f(i)<<20000。默认最低频率f(m)=200hz,根据乐理中“五声音阶”中的音高确定频率,如f(m)=200hz,
半音阶对应的分配频率矩阵f(i)的方式为:f(i)为第i行像素对应的声音频率。从图片的上到图片的下f(i)逐渐减小。为保证符合人耳的听力范围,有20<<f(i)<<20000。默认最低频率f(m)=200hz,根据乐理中“半音阶”中的音高确定频率,如f(m)=200hz,
全音阶对应的分配频率矩阵f(i)的方式为:f(i)为第i行像素对应的声音频率。从图片的上到图片的下f(i)逐渐减小。为保证符合人耳的听力范围,有20<<f(i)<<20000。默认最低频率f(m)=200hz,根据乐理中“全音阶”中的音高确定频率,如f(m)=200hz,
分配空间位置矩阵p(j)是将预处理后的图像的自左到右的像素映射到声音的空间方位上,p(j)第j列像素的角位置,以正前方为0rad,优选地,可从
分配音源音量矩阵s(i)是将预处理后的图像对应的自亮到暗的像素映射到声音自高到低的响度上得到的,由于相同振幅下,不同频率的信号能量不同,使得同振幅下高频率的声音听觉上音量更大,因此为使相同亮度像素点对应的音频在听觉上具有相同的音量,采取适当减小高频率声音的音量而增大低频率声音的音量的方式,s(i)随着f(i)的增大而减小。同时,为了平衡不同分辨率下输出音频的音量大小,s(i)应随着m和n的增大而减小。优选地,可令但不限于
设定单帧时长frametime是自定义规定整张图片转为音频的时长,为兼顾转化的帧速率与音频的可听辨性,优选地,可使但不限于0.2≤frametime≤5。
根据单帧时长设定窗函数wi(t)是用于限定单个像素点对应的单个音的播放时间,控制每个音在播放过程中的音量的变化情况,优选地,窗函数可以设置为但不限于如下函数:
其中,wi(t)为窗函数,t为时间,frametime为单帧时长,n为正整数。
结合单帧时长、窗函数分配出现节点矩阵是由于在分配频率矩阵过程中同一水平方向上不同的像素点转化为具有相同频率的声音,而相同频率的声音会相互干扰,因此设置同一水平方向上不同的像素点对应的音频的播放次序,优选地,本实施例中采用但不限于从左到右依次播放的形式。
设定波函数wa(t,f)是设置影响声音音色的函数,其表示未加窗函数时声音的波形,优选地,波函数可以设置为但不限于如下形式:
wa(t,f)=sin(2πft)
其中,t为时间,f为频率。
初始化音量衰减系数矩阵a(i,j)及a′(i,j)和延迟时间矩阵d(j)是使用hrtf(head-relatedtransferfunction,头相关传输函数)进行计算并初始化;音量衰减系数是在对应的位置及频率下,声音从声源处传播到人耳的过程中,由于头部遮挡、声音传播的方向所引起的干涉和衍射造成的声音衰减系数,与音源音量成正比,与空间位置和频率有关;延迟时间矩阵是像素点对应的声音传到右耳的时间相对于传到左耳的延时;hrtf是描述一个线性时不变(lti)声滤波系统的频域传输函数,声源发出的声波经头部、耳廓、躯干等散射后到达双耳的物理过程可视为一个线性时不变(lti)的声滤波系统,因此物理过程可由hrtf完全描述;优选地,hrtf选用最简单的计算模型,即将头视为一个刚性圆球,将双耳简化为球面上相对于水平面上的两点,用刚性圆球对平面入射波的raylei散射公式计算,表达式如下:
其中,hls(θ,ω)和hrs(θ,ω)分别为上述条件下左右耳的raylei散射公式,pm(sinθ)阶勒让德多项式,hm(ka)为m阶第一类球汉克尔函数,k为波数,a为头半径,θ为声源的方位(θ=0为正前方,
上述各参数在设备初始化时生成,生成后保持不变,直到人为修改相关设置或设备重新启动。
图像数据转音频数据:
图像数据转音频数据过程是利用图像-音频转换算法将预处理后的图像转化为代表音频的左右声道音频数据;其中,图像-音频转换算法如下:
其中,t表示播放时间,0≤t<frametime,各个参数代表的含义如下:
fl(t):左声道的音频数据(声源的振动位置随时间t的变化关系);
fr(t):右声道的音频数据;
m:预处理后的图像像素的总行数;
n:预处理后的图像像素的总列数;
i:第i行像素点;
j:第j列像素点;
im(i,j)在图像模式下表示第i行第j列的像素点的亮度,在避障模式下表示第i行第j列的像素点距离预设参照点的距离,距离越近值越大;
f(i):频率矩阵;
s(i):音源音量矩阵;
wi(t):窗函数;
ap(i,j):出现节点矩阵;
wa(t,f):波函数;
a(i,j):左声道的音量衰减系数矩阵;
a′(i,j):右声道的音量衰减系数矩阵;
d(j):延迟时间矩阵。
基于上述,本实施例的手柄5的第一调节键6用于调节图像的分辨率,第二调节键7用于调节单帧时长,第三调节键8用于调节音频数据的听觉效果,包括:五声音阶,半音阶,全音阶三种音频方案用于产生不同听觉效果;第四调节键9用于调节音频数据的音量大小,左方向键11和右方向键12用于对第一调节键6、第二调节键7、第三调节键8以及第四调节键9所对应的调节参数进行增大或减小。例如,如果想要调整音频数据的音量大小,则首先按下第四调节键9,然后再按左方向键11以减小音量,或按右方向键12以增大音量。
本实施例的可穿戴助盲系统的使用过程包括以下步骤:
步骤一,使用者通过头盔1上的十字松紧带将设备固定在头部,双目摄像头的拍摄方向与用户眼睛视觉方向相同;
步骤二,使用者按下手柄5的空格键10启动系统,双目摄像头获取图像,系统将采集的图像处理为二维矩阵,并转化为音频在立体声耳机中输出,此时使用者听到的声音即反映了当前双目摄像头摄取的环境状况;
步骤三,使用者需要对听到的声音进行辨析,图像位置的上中下与声音频率的高中低相对应,同时在获取图像所转变的灰度图像中,亮度越亮,响度越大。通过双耳效应,声音会传向左耳和右耳,让使用者产生立体感。
步骤四,使用者可依据步骤三的原理,对现场进行判断,若收到音量过小或过大,按手柄5的第四调节键9进行调整;若分辨率过小或过大,按手柄5的第一调节键6进行调整;若更换不同的听觉效果,则按手柄5的第三调节键8进行调整;若设置单帧时长,则按手柄5的第二调节键7进行调整。
综上,本实施例的将图像转化为声音的可穿戴助盲系统能够使盲人在具有一定训练的情况下,为盲人提供直观具体的视觉认知,让盲人快速地获取环境信息,快速上手。有效克服了现有技术中的种种缺点,具有高度产业利用价值。
第二实施例
本实施例提供了一种将图像转化为声音的可穿戴助盲方法,所述将图像转化为声音的可穿戴助盲方法包括:
s101,采集用户视觉范围内的环境信息并对采集的环境图像进行预处理;
s102,将预处理后的图像转换为音频数据;其中,在音频数据中,环境图像中位于不同水平线上的像素点对应不同的声音频率,环境图像中不同亮度的像素点或距离预设参照点不同距离的像素点对应不同的音量;
s103,播放转换出的音频数据。
进一步地,上述将预处理后的图像转换为音频数据,包括:
通过下式将预处理后的图像转换为左右声道音频数据:
其中,fl(t)表示左声道的音频数据,fr(t)表示右声道的音频数据;m表示预处理后的图像像素的总行数,n表示预处理后的图像像素的总列数;im(i,j)在图像模式下表示第i行第j列的像素点的亮度,在避障模式下表示第i行第j列的像素点距离预设参照点的距离;f(i)表示第i行像素对应的声音频率;
s(i)表示音源音量矩阵,其表达式为:
综上,本实施例的将图像转化为声音的可穿戴助盲方法能够使盲人在具有一定训练的情况下,为盲人提供直观具体的视觉认知,让盲人快速地获取环境信息,快速上手。有效克服了现有技术中的种种缺点,具有高度产业利用价值。
第三实施例
本实施例提供一种电子设备,其包括处理器和存储器;其中,存储器中存储有至少一条指令,所述指令由处理器加载并执行,以实现第二实施例的方法。
该电子设备可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(centralprocessingunits,cpu)和一个或一个以上的存储器,其中,存储器中存储有至少一条指令,所述指令由处理器加载并执行以下步骤:
s101,控制图像采集设备采集用户视觉范围内的环境信息,并对图像采集设备所采集的环境图像进行预处理;
s102,将预处理后的图像转换为音频数据;其中,在音频数据中,环境图像中位于不同水平线上的像素点对应不同的声音频率,环境图像中不同亮度的像素点或距离预设参照点不同距离的像素点对应不同的音量;
s103,控制音频播放设备对转换出的音频数据进行播放。
综上,本实施例的电子设备通过执行上述助盲方法能够使盲人在具有一定训练的情况下,为盲人提供直观具体的视觉认知,让盲人快速地获取环境信息,快速上手。有效克服了现有技术中的种种缺点,具有高度产业利用价值。
第四实施例
本实施例提供一种计算机可读存储介质,该存储介质中存储有至少一条指令,所述指令由处理器加载并执行,以实现上述方法。其中,该计算机可读存储介质可以是rom、随机存取存储器(ram)、cd-rom、磁带、软盘和光数据存储设备等。其内存储的指令可由终端中的处理器加载并执行以下步骤:
s101,控制图像采集设备采集用户视觉范围内的环境信息,并对图像采集设备所采集的环境图像进行预处理;
s102,将预处理后的图像转换为音频数据;其中,在音频数据中,环境图像中位于不同水平线上的像素点对应不同的声音频率,环境图像中不同亮度的像素点或距离预设参照点不同距离的像素点对应不同的音量;
s103,控制音频播放设备对转换出的音频数据进行播放。
综上,本实施例的计算机可读存储介质所存储的程序能够使盲人在具有一定训练的情况下,为盲人提供直观具体的视觉认知,让盲人快速地获取环境信息,快速上手。有效克服了现有技术中的种种缺点,具有高度产业利用价值。
此外,需要说明的是,本发明可提供为方法、装置或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质上实施的计算机程序产品的形式。
本发明实施例是参照根据本发明实施例的方法、终端设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的相同要素。
最后需要说明的是,以上所述是本发明优选实施方式,应当指出,尽管已描述了本发明优选实施例,但对于本技术领域的技术人员来说,一旦得知了本发明的基本创造性概念,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明实施例范围的所有变更和修改。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



