
 商标分类
商标分类  商标转让
商标转让 
一种基于智能语音机器人的虚假宣传治理应用方法及装置与流程
 2021-01-28 15:01:02|
2021-01-28 15:01:02| 307|
307| 起点商标网
起点商标网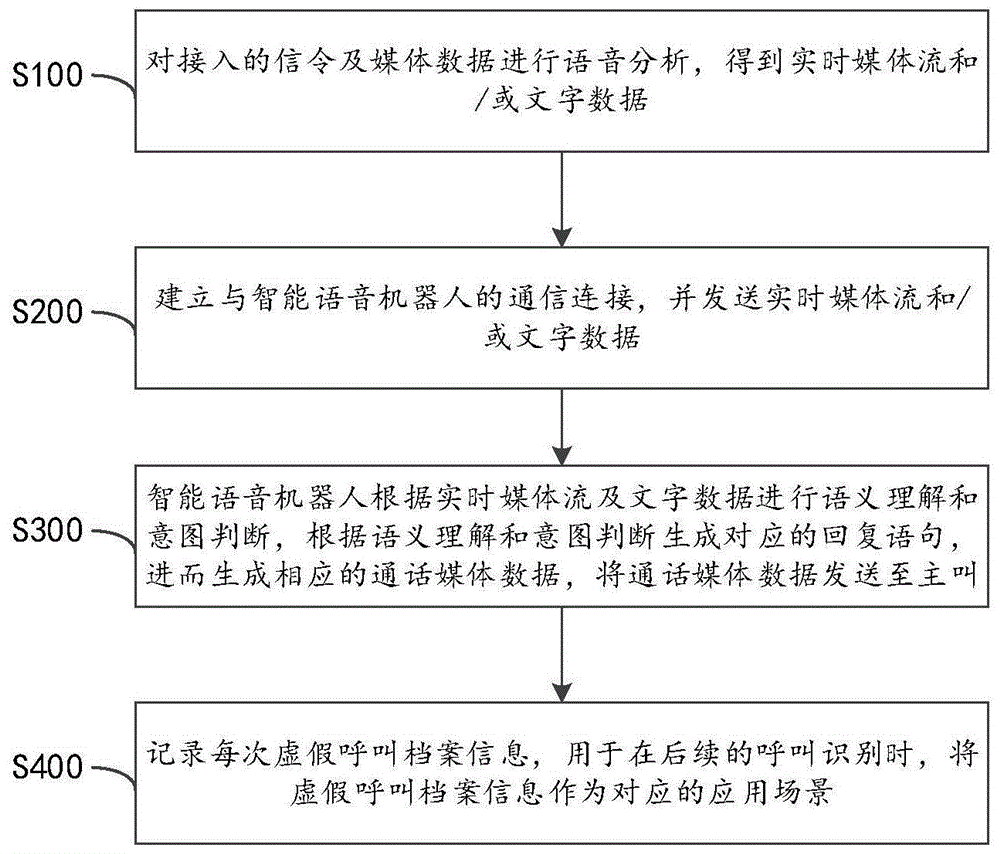
本发明涉及通信及语音识别领域,具体涉及了一种基于智能语音机器人的虚假宣传治理应用方法及装置。
背景技术:
目前,随着人工智能的发展,智能语音机器人已经大规模进入企业营销应用中。智能语音机器人多行业场景应用,涵盖服务行业、电商行业、金融行业、房地产行业、汽车行业、教育培训等领域,主要应用于企业的电话营销场景、客服售后场景、电话通知场景中,比如金融信贷行业应用场景;智能语音机器人是一种能够增强企业当前业务效率的营销策略,也是ai时代助力企业业绩持续高增长的助推剂。当然,随着进步和发展,智能语音机器人也在不断的提升和完善。
目前已有厂家推出应用接听机器人、外呼机器人等一系列智能语音机器人,在商业应用中也起动一定效果。但在虚假宣传治理中,应用尚比较少,特别是对虚假宣传活动的源头治理,还没有一种行之有效手段应对,也不能积极有效治理,更不利于业务开展。
技术实现要素:
本发明的目的在于至少解决现有技术中存在的技术问题之一,提供了一种基于智能语音机器人的虚假宣传治理应用方法及装置,对接入虚假语音进行识别,并通过智能语音机器人与虚假宣传进行交互,解决了现有技术的不足。
本发明的技术方案包括一种基于智能语音机器人的虚假宣传治理应用方法,其特征在于,该方法包括:s100,对接入的信令及媒体数据进行语音分析,得到实时媒体流和/或文字数据;s200,建立与智能语音机器人的通信连接,并发送所述实时媒体流和/或文字数据;s300,智能语音机器人根据实时媒体流及文字数据进行语义理解和意图判断,根据所述语义理解和意图判断生成对应的回复语句,进而生成相应的通话媒体数据,将通话媒体数据发送至主叫;s400,记录每次虚假呼叫档案信息,用于在后续的呼叫识别时,将虚假呼叫档案信息作为对应的应用场景。
根据所述的一种基于智能语音机器人的虚假宣传治理应用方法,其中信令符合电信网信令数据接入符合电信网统一标准接口。
根据所述的一种基于智能语音机器人的虚假宣传治理应用方法,其中信令符合电信网信令数据接入符合电信网统一标准接口。s100还包括,若信令识别为符合虚假宣传特征的信令消息,则直接将被叫释放。
根据所述的一种基于智能语音机器人的虚假宣传治理应用方法,其中媒体数据的接入及传输符合电信网媒体接口规范协议。
根据所述的一种基于智能语音机器人的虚假宣传治理应用方法,其中s200通过调用智能语音机器人的接口将实时媒体流和/或文字进行发送。
根据所述的一种基于智能语音机器人的虚假宣传治理应用方法,其中s300具体包括:s310,基于jieba分词、lstm模型及规则匹配对所述实时媒体流和/或文字数据的单句意图、整体意图及真实意图进行语义理解识别;s320,根据所述单句意图、所述整体意图及所述真实意图中的至少一个自动生成对应的回复内容;s330,根据回复内容匹配对应的场景模型,模拟出对应的媒体流和/或文字数据并回送至主叫。
根据所述的一种基于智能语音机器人的虚假宣传治理应用方法,其中s310具体包括:s311,预设语料库并进行预处理,对所述实时媒体流和/或文字数据通过分词工具进行处理,并将得到语句、分词结果、关键词及预处理内容保存;s312,通过将语料库训练来完成词向量模型的构建,并将词向量模型以及对应的词向量字典、索引字典进行保存;s313,训练lstm模型并进行保存数据,使用分词工具对文字数据进行hmm以及搜索模式分词提取关键词;s314,对文字数据的句子中的关键词进行快速全局搜索,取得最大匹配分值的词语所在类别完成意图理解。
根据所述的一种基于智能语音机器人的虚假宣传治理应用方法,该方法还包括:s315,若未在模型库中找到记录的文字,则进行lstm模型预测或word2vec相似词类别加权平均预测;s316,采用lstm算法,对上下文语境进行的理解,以及,采用word2vec相似词类别加权,寻找在词库中已经存在的与现有关键词相似的词集,通过相似度加权平均的方式进行意图理解。
本发明的技术方案还包括一种基于智能语音机器人的虚假宣传治理应用装置,该装置包括接入端及智能语音机器人,其特征在于:所述接入端用于对接入的信令及媒体数据进行语音分析,得到实时媒体流和/或文字数据,建立与智能语音机器人的通信连接,并发送所述实时媒体流和/或文字数据;以及,还用于记录每次虚假呼叫档案信息,用于在后续的呼叫识别时,将虚假呼叫档案信息作为对应的应用场景;所述智能语音机器人根据实时媒体流和/或文字数据进行语义理解和意图判断,根据所述语义理解和意图判断生成对应的回复语句,进而生成相应的通话媒体数据,将通话媒体数据进行回送。
本发明的有益效果为:引入智能语音机器人进行语音互动,可有效占用虚假宣传源头的通话时间,间接的减少了受害人等接通次数;对虚假宣传源头进行干扰,降低其诈骗成功率。
附图说明
下面结合附图和实施例对本发明进一步地说明;
图1所示为根据本发明实施方式的总体流程图;
图2所示为根据本发明实施方式的交互示意图;
图3所示为根据本发明实施方式的语义理解流程图;
图4所示为根据本发明实施方式的介质装置图。
具体实施方式
本部分将详细描述本发明的具体实施例,本发明之较佳实施例在附图中示出,附图的作用在于用图形补充说明书文字部分的描述,使人能够直观地、形象地理解本发明的每个技术特征和整体技术方案,但其不能理解为对本发明保护范围的限制。
在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。
在本发明的描述中,对方法步骤的连续标号是为了方便审查和理解,结合本发明的整体技术方案以及各个步骤之间的逻辑关系,调整步骤之间的实施顺序并不会影响本发明技术方案所达到的技术效果。
术语解释:
lstm:长短时记忆神经网络算法;
word2vec:一群用来产生词向量的相关模型,这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本;
jieba分词:一种分词工具,可以对中文文本进行分词、词性标注、关键词抽取等功能,并且支持自定义词典。
本发明的描述中,除非另有明确的限定,设置等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。
图1所示为根据本发明实施方式的总体流程图。该流程包括:s100,对接入的信令及媒体数据进行语音分析,得到实时媒体流和/或文字数据;s200,建立与智能语音机器人的通信连接,并发送实时媒体流和/或文字数据;s300,智能语音机器人根据实时媒体流及文字数据进行语义理解和意图判断,根据语义理解和意图判断生成对应的回复语句,进而生成相应的通话媒体数据,将通话媒体数据发送至主叫;s400,记录每次虚假呼叫档案信息,用于在后续的呼叫识别时,将虚假呼叫档案信息作为对应的应用场景。
图2所示为根据本发明实施方式的交互示意图,结合图2,具体作出以下流程描述:
(1)按照某种策略,将符合虚假宣传特征的信令消息实时进行信令控制,对于确属于虚假宣传源的引入通话,可直接将被叫释放。
(2)通过每天接入,在经过语音分析后,将实时媒体流或文字通过接口调用,输出给智能语音机器人。
(3)智能语音机器人根据媒体流信息,理解词义后,生成与虚假宣传源对话的媒体信息内容,并送入媒体注入模块。
(4)智能语音机器人可以根据不同的号码,采取变声、魔音等特效处理,生成相应的通话媒体数据。
(5)媒体的注入将媒体数据按照规范格式送入到传输线路。
(6)建立该呼叫档案信息,保持该应用场景,为后续追踪做基础。
其中,信令接入、媒体数据接入、智能语音机器人。信令接入模块为电信网信令数据接入,为电信网统一标准接口;
媒体数据接入模块兼容当前电信网媒体接口规范协议;
智能语音机器人功能包括语义理解、意图理解、对话维护、语音合成等。
语义理解基于jieba分词、lstm模型等自相关模型、规则匹配等实现单句意图识别、整体意图识别、真实意图识别等功能。
单句意图识别针对用户说的每一句话判断其意图,并根据语气、停顿时间进行积极回应与互动,并根据媒体内容词义理解,生成回复内容;
整轮意图识别用于在一通电话结束后判断用户的整体意向;
真实意图识别用来判断用户回复后机器接下来应该怎么回复;
语音合成,根据词义理解,根据语音合成算法合成语音,预先设定几种模型,如声调的变化如变声、魔音,身份的变化如老年人、成年人、小孩、男女说话等;并按照虚假宣传场景模型完成灵活业务互动,使得虚假宣传源头认为是在和真实的用户通话,由于长时间的占用其通话座席。
其中,智能语音机器人中的智能语音机器人示例如下:
人工预先设置不同场景的内容回复,形成一些对话模型,网上经常出现的场景举例如下:
1、发短信告知家里人,称出现了意外,现在不能和通话等方式进行虚假宣传;
2、以中奖为由,让先提交各种费用;
3、利用朋友的信息向借钱;
4、一些骚扰信息里面会推销某种购物产品;
5、冒充银行发来的信息会以账户密码泄露需要重新设置为由进行虚假宣传等。
智能语音机器人根据预设置的场景流程,实时进行语音分析和灵活对话互动,达到欺骗虚假宣传源的目的。
其中,接入端为智能设备,用于完成信令接收及发送,例如手机、平板电脑。
图3所示为根据本发明实施方式的语义理解流程图,具体的,包括以下步骤:s311,预设语料库并进行预处理,对实时媒体流和/或文字数据通过分词工具进行处理,并将得到语句、分词结果、关键词及预处理内容保存;s312,通过将语料库训练来完成词向量模型的构建,并将词向量模型以及对应的词向量字典、索引字典进行保存;s313,训练lstm模型并进行保存数据,使用分词工具对文字数据进行hmm以及搜索模式分词提取关键词;s314,对文字数据的句子中的关键词进行快速全局搜索,取得最大匹配分值的词语所在类别完成意图理解;s315,若未在模型库中找到记录的文字,则进行lstm模型预测或word2vec相似词类别加权平均预测;s316,采用lstm算法,对上下文语境进行的理解,以及,采用word2vec相似词类别加权,寻找在词库中已经存在的与现有关键词相似的词集,通过相似度加权平均的方式进行意图理解。
图4所示为根据本发明实施方式的介质装置图。结合图2,接入端及智能语音机器人均设置有如图4所示的存储器100及处理器200,存储器100用于存储语音识别的文字数据和媒体流数据,处理器用于执行如图1所示的流程。
上面结合附图对本发明实施例作了详细说明,但是本发明不限于上述实施例,在技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



