
 商标分类
商标分类  商标转让
商标转让 
利用改进的音调滞后估计的似ACELP隐藏中的自适应码本的改进隐藏的装置及方法与流程
 2021-01-28 15:01:45|
2021-01-28 15:01:45| 243|
243| 起点商标网
起点商标网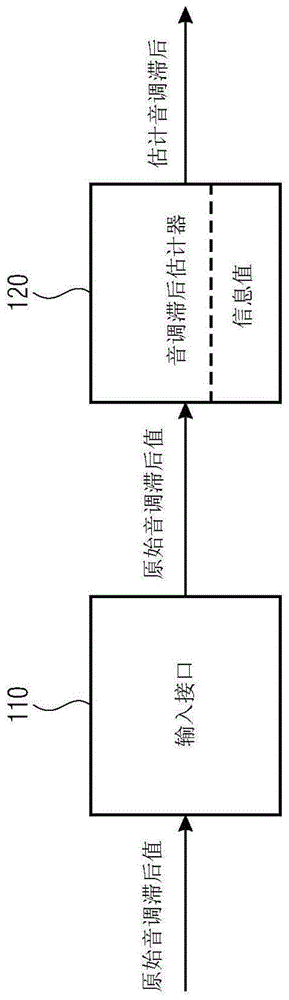
本申请是申请人为弗朗霍夫应用科学研究促进协会、申请日为2014年6月16日、申请号为201480035427.3、发明名称为“利用改进的音调滞后估计的似acelp隐藏中的自适应码本的改进隐藏的装置及方法”的分案申请。
本发明涉及音频信号处理,特别是语音处理,并且更特别地涉及用于似acelp(似代数码激励线性预测)隐藏中的自适应码本的改进隐藏的装置以及方法。
背景技术:
音频信号处理变得越来越重要。在音频信号处理领域中,隐藏技术扮演重要角色。当帧丢失或损坏时,由于丢失或损坏的帧而丢失的信息必须被放回。在语音信号处理中,尤其是,当考虑到acelp或似acelp语音编解码器时,音调信息是非常重要的。音调预测技术以及脉冲再同步化技术是所需的。
关于音调重建,现有技术中存在不同的音调外推技术。
这些技术中的一种是基于重复的技术。多数的现有编解码器应用基于简单重复的隐藏方法,这意味着在包丢失之前最后正确地接收的音调周期被重复,直至良好的帧到达且可从比特流中解码出新的音调信息为止。或者,应用音调稳定性逻辑,根据其,选择在包丢失之前已被接收一些时间的音调值。遵循基于重复的方法的编解码器是,例如,g.719(参看[itu08b,8.6])、g.729(参看[itu12,4.4])、amr(参看[3gp12a,6.2.3.1],[itu03])、amr-wb(参看[3gp12b,6.2.3.4.2])以及amr-wb+(acelp及tcx20(似acelp)隐藏)(参看[3gp09]);(amr=自适应多速率;amr-wb=自适应多速率宽带)。
现有技术的另一种音调重建技术是自时间域的音调推导。对于一些编解码器,音调是隐藏所必须的,但是未被嵌入比特流中。因此,基于先前帧的时域信号计算音调,以便计算音调周期,然后在隐藏期间保持音调周期恒定。遵循这种方法的编解码器是,例如,g.722,参看,尤其是,g.722附录3(参看[itu06a,iii.6.6及iii.6.7])以及g.722附录4(参看[itu07,iv.6.1.2.5])。
现有技术的又一种音调重建技术是基于外推。一些现有的编解码器应用音调外推方法并且执行特定算法以在包丢失时依据外推的音调估计而改变音调。这些方法将参照g.718以及g.729.1在下面更详细地说明。
首先,g.718被考虑(参看[itu08a])。未来音调的估计通过外推被进行以支持声门脉冲再同步化模块。这个可能的未来音调值的信息用于同步化隐藏的激励的声门脉冲。
仅当最后的良好帧不是无声的时进行音调外推。g.718的音调外推是基于编码器具有平滑的音调轮廓的假设。所述外推基于消音之前的最后七个子帧的音调滞后
在g.718中,浮动音调值的历史更新在每个正确地接收的帧之后被进行。为了这个目的,仅当核心模式不是无声的时更新音调值。在丢失帧的情况中,浮动音调滞后之间的差根据公式(1)被计算:
在公式(1)中,
根据g.718,差值
由于值
通过公式(3)得到参数fcorr:
其中dmax=231是考虑的音调滞后的最大值。
在g.718中,根据以下限定得到指示最大绝对差值的位置imax:
并且如下所示计算对于这个最大差值的比率:
如果这个比率大于或等于5,则最后正确接收的帧的第4个子帧的音调被用于待隐藏的所有子帧。如果这个比率大于或等于5,这意味着所述算法是不够可靠的以外推所述音调,并且所述声门脉冲再同步化将不会被进行。
如果rmax小于5,则另外的处理被进行以实现最佳可能外推。三种不同的方法被用于外推未来音调。为了在可能的音调外推算法之间做选择,计算偏差参数fcorr2,其取决于因子fcorr以及最大音调变化的位置imax。但是,首先,修改平均浮动音调差值以从平均值中移除太大的音调差值:
如果fcorr<0.98且如果imax=3,则根据公式(5)确定平均部分音调差值
以移除关于两个帧之间的过渡的音调差值。
如果fcorr<≥0.98或如果imax≠3,则根据公式(6)计算平均部分音调差值
并且最大浮动音调差值被这个新的平均值替代:
使用这个浮动音调差值的新平均值,如下计算标准偏差fcorr2:
其中isf在第一情况中等于4,在第二情况中等于6。
依据这个新参数,在外推未来音调的三种方法之间做选择:
如果
如果0.945<fcorr2<0.99并且
公式中的参数imem取决于
否则,音调演变被考虑是稳定的并且如下所示确定外推音调dext:
在这个处理之后,音调滞后被限制在34以及231之间(值指示最小以及最大允许的音调滞后)。
现在,为说了基于外推的音调重建技术的另一示例,g.729.1被考虑(参看[itu06b])。
g.729.1的特征为无前向误差隐藏信息(例如,相位信息)是可解码的情况中的音调外推方法(参看[gao])。例如,如果两个连续帧丢失(一个超级帧由四个帧组成,可以是acelp或tcx20),则这种情况出现。也有可能是tcx40或tcx80帧及其几乎所有组合。
当在有声区域中丢失一个或多个帧时,先前的音调信息通常被用于重建当前丢失的帧。当前估计的音调的精确性可能直接地影响与原始信号对齐的相位,并且其对于当前丢失的帧以及在丢失帧之后接收到的帧的重建质量是关键的。使用多个过去的音调之后而不是仅复制先前的音调滞后将导致统计上较佳的音调估计。在g.729.1编码器中,用于fec(前向误差校正)的音调外推由基于过去五个音调值的线性外推组成。过去五个音调值是p(i),对于i=0,1,2,3,4,其中p(4)是最近的音调值。根据公式(9)定义外推模型:
p′(i)=a+i·b(9)
然后,如公式(10)被定义对于丢失帧中的第一子帧的外推音调数值:
p′(5)=a+5·b(10)
为了确定系数a以及b,误差e被最小化,其中根据公式(11)定义误差e:
通过设定
得到a和b:
下面,对如[mcz11]中所提出的用于amr-wb编解码器的现有帧删除隐藏概念进行说明。这个帧删除隐藏概念是基于音调和增益线性预测。所述文章提出基于最小均方误差准则,在帧丢失情况中的线性音调内推/外推法。
根据这个帧删除隐藏概念,在解码器侧,当删除帧之前的最后有效帧(过去帧)的类型与删除帧之后的最先帧(未来帧)的类型相同时,定义音调p(i),其中i=-n,-n+1,...,0,1,...,n+4,n+5,并且其中n是删除帧的过去以及未来子帧的数量。p(1),p(2),p(3),p(4)是删除帧中的四个子帧的四个音调,p(0),p(-1),...,p(-n)是过去子帧的音调,并且p(5),p(6),...,p(n+5)是未来子帧的音调。线性预测模型p’(i)=a+b·i被采用。对于i=1,2,3,4;p’(1),p’(2),p’(3),p’(4)是对于删除帧的预测音调。mms准则(mms=最小均方)被考虑以根据内推方法而推导出两个预测系数a以及b的值。根据这种方法,误差e被定义位:
接着,系数a以及b可通过计算如下公式得到:
可根据公式(14e)计算对于删除帧的最后四个子帧的音调滞后:
p′(1)=a+b·1:p′(2)=a+b·2
p′(3)=a+b·3;p′(4)=a+b·4(14e)
结果发现,n=4提供最好的结果。n=4表示5个过去子帧以及5个未来子帧被用于内推。
但是,当过去帧的类型与未来帧的类型不同时,例如,当过去帧是有声的但是未来帧是无声的时,只有过去帧或未来帧的有声音调被用于使用上述外推方法而预测删除帧的音调。
现在,考虑现有技术中的脉冲再同步化,尤其是参考g.718及g.729.1。脉冲再同步化的方法在[vjgs12]中进行了描述。
首先,说明建构激励的周期部分。
对于在正确地接收除了无声之外的帧之后的删除帧的隐藏,通过重复先前帧的被低通滤波的最后音调周期建构激励的周期部分。
使用来自先前帧的末端的激励信号的被低通滤波段的简单复制而完成周期部分的建构。
音调周期长度被四舍五入(round)至最接近整数:
tc=round(最后音调)(15a)
考虑最后音调周期长度是tp,则被复制的段的长度tr可以例如根据公式(15b)被定义:
对于一个帧和一个额外的子帧建构周期部分。
例如,帧中有m个子帧,子帧长度是
其中l是帧长度,也表示为lframe:l=lframe。
图3示出语音信号的建构周期部分。
t[0]是激励的建构周期部分中的第一最大脉冲的位置。其他脉冲的位置利用下式给出:
t[i]=t[0]+itc(16a)
对应于
t[i]=t[0]+itr(16b)
在激励的周期部分的建构之后,声门脉冲再同步化被进行以校正丢失帧的最后脉冲的估计目标位置(p)与其在激励的建构周期部分中的实际位置(t[k])之间的差。
基于丢失帧之前的最后七个子帧的音调滞后外推音调滞后演变。每个子帧中的演变音调滞后是:
p[i]=round(tc+(i+1)δ),0≤i<m(17a)
其中
且text(也表示为dext)是外推音调,如上面对于dext的描述。
在帧长度内发现具有恒定音调的音调周期(tc)内的总样本数量和与具有演变音调p[i]的音调周期内的总样本数量和之间的差(表示为d)。文献中没有说明如何发现d。
在g.718的源码中(参看[itu08a]),是使用下面的算法(其中m是帧中的子帧的数量)发现d:
帧长度内的建构周期部分中的脉冲加上未来帧中的第一脉冲的数量是n。文献中没有说明如何发现n。
在g.718的源码中(参看[itu08a]),根据以下公式发现n:
通过以下公式确定属于丢失帧的激励的建构周期部分中的最后脉冲的位置t[n]:
估计的最后脉冲位置p是:
p=t[n]+d(19a)
最后脉冲位置的实际位置t[k]是最接近估计的目标位置p的激励的建构周期部分中的脉冲的位置(包含在当前帧之后的第一脉冲的搜寻中):
通过增加或移除全部音调周期的最小能量区域中的样本进行声门脉冲再同步化。通过以下的差值确定被增加或移除的样本的数量:
diff=p-t[k](19c)
使用滑动5-样本窗口确定最小能量区域。最小能量位置被设定在窗口中间,在其处能量是最小的。在两个音调脉冲之间从t[i]+tc/8至t[i+1]-tc/4进行搜寻。有nmin=n-1个最小能量区域。
如果nmin=1,则仅有一个最小能量区域且在该位置插入或删除diff个样本。
对于nmin>1,在开始处增加或移除较少样本,朝向帧结束部分增加或删除较多样本。使用下面的递归关系发现脉冲t[i]与t[i+1]之间被移除或被增加的样本的数量:
如果r[i]<r[i-1],则r[i]与r[i-1]的值互换。
技术实现要素:
本发明的目的在于提供用于音频信号处理的改进的概念,特别地,提供用于语音处理的改进的概念,并且更特别地,提供改进的隐藏概念。
本发明的目的通过根据以下描述的装置,方法以及计算机程序而实现。
提供一种用于确定估计音调滞后的装置。所述装置包括:用于接收多个原始音调滞后值的输入接口,以及用于估计所述估计音调滞后的音调滞后估计器。所述音调滞后估计器用于依据多个原始音调滞后值以及依据多个信息值估计所述估计音调滞后,其中对于所述多个原始音调滞后值中的每个原始音调滞后值,所述多个信息值中的信息值被指定给所述原始音调滞后值。
根据实施例,所述音调滞后估计器,例如,可用于依据所述多个原始音调滞后值以及依据作为所述多个信息值的多个音调增益值估计所述估计音调滞后,其中对于所述多个原始音调滞后值中的每个原始音调滞后值,所述多个音调增益值中的音调增益值被指定给所述原始音调滞后值。
在特定实施例中,所述多个音调增益值中的每个,例如,可以是自适应码本增益。
在实施例中,所述音调滞后估计器,例如,可以用于通过最小化误差函数而估计所述估计音调滞后。
根据实施例,所述音调滞后估计器,例如,可用于通过最小化下列误差函数而通过确定两个参数a、b以估计所述估计音调滞后,
其中a是实数,其中b是实数,其中k是具有k≥2的整数,以及其中p(i)是第i个原始音调滞后值,其中gp(i)是被指定给第i个音调滞后值p(i)的第i个音调增益值。
在实施例中,所述音调滞后估计器,例如,可用于通过最小化下列误差函数而通过确定两个个参数a、b以估计所述估计音调滞后,
其中a是实数,其中b是实数,其中p(i)是第i个原始音调滞后值,其中gp(i)是被指定给所述第i个音调滞后值p(i)的第i个音调增益值。
根据实施例,所述音调滞后估计器,例如,可用于根据p=a·i+b确定所述估计音调滞后p。
在实施例中,所述音调滞后估计器,例如,可用于依据所述多个原始音调滞后值依据依据作为所述多个信息值的多个时间值估计所述估计音调滞后,其中对于所述多个原始音调滞后值中的每个原始音调滞后值,所述多个时间值中的时间值被指定给所述原始音调滞后值。
根据实施例,所述音调滞后估计器,例如,可用于通过最小化误差函数而估计所述估计音调滞后。
在实施例中,所述音调滞后估计器,例如,可用于通过最小化下列误差函数而通过确定两个参数a、b以估计所述估计音调滞后,
其中a是实数,其中b是实数,其中k是具有k≥2的整数,并且其中p(i)是第i个原始音调滞后值,其中timepassed(i)是被指定给所述第i个音调滞后值p(i)的第i个时间值。
根据实施例,所述音调滞后估计器,例如,可用于通过最小化下列误差函数而通过确定两个参数a、b以估计所述估计音调滞后,
其中a是实数,其中b是实数,其中p(i)是第i个原始音调滞后值,其中timepassed(i)是被指定给所述第i个音调滞后值p(i)的第i个时间值。
在实施例中,所述音调滞后估计器,例如,可用于根据p=a·i+b确定所述估计音调滞后p。
而且,提供一种用于确定估计音调滞后的方法。所述方法包括:
接收多个原始音调滞后值;以及
估计所述估计音调滞后。
依据多个原始音调滞后值以及依据多个信息值而进行估计所述估计音调滞后,其中对于所述多个原始音调滞后值中的每个原始音调滞后值,所述多个信息值中的信息值被指定给所述原始音调滞后值。
此外,提供一种计算机程序,当其在计算机或信号处理器上被执行时,用于实现上述方法。
此外,提供一种用于重建包括语音信号的帧作为重建帧的装置,所述重建帧与一个或多个可用帧相关联,所述一个或多个可用帧是所述重建帧的一个或多个先前帧以及所述重建帧的一个或多个后续帧中的至少一个,其中所述一个或多个可用帧包括作为一个或多个可用音调周期的一个或多个音调周期。所述装置包括:确定单元,用于确定样本数量差,所述样本数量差指示所述一个或多个可用音调周期中的一个的样本数量与待重建的第一音调周期的样本数量之间的差。并且,所述装置包括帧重建器,所述帧重建器用于通过依据所述样本数量差以及依据所述一个或多个可用音调周期中的一个的样本重建待被重建作为第一重建音调周期的所述第一音调周期,而重建所述重建帧。所述帧重建器用于重建所述重建帧,以使得所述重建帧完全地或部分地包括所述第一重建音调周期,以使得所述重建帧完全地或部分地包括第二重建音调周期,以及以使得所述第一重建音调周期的样本数量不同于所述第二重建音调周期的样本数量。
根据实施例,所述确定单元,例如,可用于确定对于待被重建的多个音调周期中的每个的样本数量差,以使得所述音调周期中的每个的样本数量差指示所述一个或多个可用音调周期中的一个的样本数量与待被重建的所述音调周期的样本数量之间的差。所述帧重建器,例如,可用于依据待被重建的所述音调周期的所述样本数量差以及依据所述一个或多个可用音调周期中的一个的样本重建待被重建的所述多个音调周期中的每个音调周期,从而重建所述重建帧。
在实施例中,所述帧重建器,例如,可用于依据所述一个或多个可用音调周期中的一个生成中间帧。所述帧重建器,例如,可用于修改所述中间帧以得到所述重建帧。
根据实施例,所述确定单元,例如,可用于确定指示多少样本将从所述中间帧移除或多少样本将被增加至所述中间帧的帧差值(d;s)。此外,所述帧重建器,例如,可用于当所述帧差值指示第一样本应从所述帧被移除时,将所述第一样本从所述中间帧移除以得到所述重建帧。此外,所述帧重建器,例如,可用于当所述帧差值(d;s)指示第二样本应被增加至所述帧时,将所述第二样本增加至所述中间帧以得到所述重建帧。
在实施例中,所述帧重建器,例如,可用于当所述帧差值指示所述第一样本应从所述帧移除时,将所述第一样本从所述中间帧移除,因而从所述中间帧移除的所述第一样本的数量由所述帧差值指示。此外,所述帧重建器,例如,可用于当所述帧差值指示所述第二样本应被增加至所述帧时,将所述第二样本增加至所述中间帧,因而被增加至所述中间帧的所述第二样本的数量由所述帧差值指示。
根据实施例,所述确定单元,例如,可用于确定帧差量s,因而适用下列公式:
其中l指示所述重建帧的样本数量,其中m指示所述重建帧的子帧的数量,其中tr指示所述一个或多个可用音调周期中的一个的四舍五入的音调周期长度,并且其中p[i]指示所述重建帧的第i个子帧的重建音调周期的音调周期长度。
在实施例中,所述帧重建器,例如,可适于依据所述一个或多个可用音调周期中的一个生成中间帧。此外,所述帧重建器,例如,可适于生成所述中间帧,使得所述中间帧包括第一部分中间音调周期、一个或多个其他中间音调周期、以及第二部分中间音调周期。此外,所述第一部分中间音调周期可例如取决于所述一个或多个可用音调周期中的一个的样本中的一个或多个,其中所述一个或多个其他中间音调周期中的每个取决于所述一个或多个可用音调周期中的所述一个的全部样本,并且其中所述第二部分中间音调周期取决于所述一个或多个可用音调周期中的所述一个的所述样本中的一个或多个。此外,所述确定单元,例如,可用于确定指示多少样本将从所述第一部分中间音调周期移除或被增加至所述第一部分中间音调周期的开始部分差量,并且其中所述帧重建器用于依据所述开始部分差量,从所述第一部分中间音调周期移除一个或多个第一样本,或增加一个或多个第一样本至所述第一部分中间音调周期。此外,所述确定单元,例如,可用于确定对于所述其他中间音调周期中的每个的音调周期差量,所述音调周期差量指示多少样本将从所述其他中间音调周期中的所述一个移除或被增加至所述其他中间音调周期中的所述一个。此外,所述帧重建器,例如,可用于依据所述音调周期差量,从所述其他中间音调周期中的所述一个移除一个或多个第二样本,或增加一个或多个第二样本至所述其他中间音调周期中的所述一个。此外,所述确定单元,例如,可用于确定指示多少样本将从所述第二部分中间音调周期移除或被增加至所述第二部分中间音调周期的结束部分差量,并且其中所述帧重建器用于依据所述结束部分差量,从所述第二部分中间音调周期移除一个或多个第三样本,或增加一个或多个第三样本至所述第二部分中间音调周期。
根据实施例,所述帧重建器,例如,可用于依据所述一个或多个可用音调周期中的所述一个生成中间帧。此外,所述确定单元,例如,可适于确定所述中间帧包括的语音信号的一个或多个低能量信号部分,其中所述一个或多个低能量信号部分中的每个是所述中间帧内的语音信号的第一信号部分,其中所述语音信号的能量低于所述中间帧包括的语音信号的第二信号部分中的能量。此外,所述帧重建器,例如,可用于从所述语音信号的所述一个或多个低能量信号部分中的至少一个移除一个或多个样本,或增加一个或多个样本至所述语音信号的所述一个或多个低能量信号部分中的至少一个,以得到所述重建帧。
在特定的实施例中,所述帧重建器,例如,可用于生成所述中间帧,以使得所述中间帧包括一个或多个重建音调周期,以使得所述一个或多个重建音调周期的每个取决于所述一个或多个可用音调周期中的所述一个。此外,所述确定单元,例如,可用于确定应从所述一个或多个重建音调周期中的每个移除的样本的数量。此外,所述确定单元,例如,可用于确定所述一个或多个低能量信号部分的每个,以使得对于所述一个或多个低能量信号部分中的每个,所述低能量信号部分的样本的数量取决于应从所述一个或多个重建音调周期中的一个移除的样本的数量,其中所述低能量信号部分位于所述一个或多个重建音调周期中的一个内。
在实施例中,所述确定单元,例如,可用于确定待被重建作为重建帧的所述帧的语音信号的一个或多个脉冲的位置。此外,所述帧重建器,例如,可用于依据所述语音信号的所述一个或多个脉冲的所述位置重建所述重建帧。
根据实施例,所述确定单元,例如,可用于确定待被重建作为重建帧的所述帧的语音信号的两个或更多个脉冲的位置,其中t[0]是带被重建作为重建帧的所述帧的语音信号的所述两个或更多个脉冲中的一个的位置,以及其中所述确定单元用于根据下列公式确定所述语音信号的所述两个或更多个脉冲中的其他脉冲的位置(t[i]):
t[i]=t[0]+itr
其中tr指示所述一个或多个可用音调周期中的所述一个的四舍五入的长度并且其中i是整数。
根据实施例,所述确定单元,例如,可用于确定待被重建作为所述重建帧的所述帧的音信号的最后脉冲的索引k,以使得
其中l指示所述重建帧的样本的数量,其中s指示所述帧差量,其中t[0]指示待被重建作为所述重建帧的所述帧的语音信号的脉冲(不同于所述语音信号的所述最后脉冲)的位置,其是,并且其中tr指示所述一个或多个可用音调周期中的所述一个的四舍五入的长度。
在实施例中,所述确定单元,例如,可用于通过确定参数δ而重建待被重建作为所述重建帧的帧,其中所述参数δ根据下列公式被定义:
其中待被重建作为所述重建帧的所述帧包括m个子帧,其中tp指示所述一个或多个可用音调周期中的所述一个的长度,并且其中text指示待被重建作为所述重建帧的所述帧的待被重建的音调周期中的一个的长度。
根据实施例,所述确定单元,例如,可用于通过基于下列公式确定所述一个或多个可用音调周期中的所述一个的四舍五入的长度tr,以重建所述重建帧:
其中tp指示所述一个或多个可用音调周期中的所述一个的长度。
在实施例中,所述确定单元,例如,可用于通过应用下列公式而重建所述重建帧:
其中tp指示所述一个或多个可用音调周期中的所述一个的长度,其中tr指示所述一个或多个可用音调周期中的所述一个的四舍五入的长度,其中带被重建作为所述重建帧的所述帧包括m个子帧,其中待被重建作为所述重建帧的所述帧包括l个样本,以及其中δ是实数,其指示所述一个或多个可用音调周期中的所述一个的样本数量与待被重建的一个或多个音调周期中的一个的样本数量之间的差。
此外,提供一种用于重建包括语音信号的帧作为重建帧的方法,所述重建帧与一个或多个可用帧相关联,所述一个或多个可用帧是所述重建帧的一个或多个先前帧以及所述重建帧的一个或多个后续帧中的至少一个,其中所述一个或多个可用帧包括作为一个或多个可用音调周期的一个或多个音调周期。所述方法包括:
-确定样本数量差
-通过依据所述样本数量差
重建所述重建帧被进行,以使得所述重建帧完全地或部分地包括所述第一重建音调周期,以使得所述重建帧完全地或部分地包括第二重建音调周期,以及以使得所述第一重建音调周期的所述样本数量不同于所述第二重建音调周期的样本数量。
此外,提供一种计算机程序,当其在计算机或信号处理器上被执行时,用于实现上述方法。
此外,提供一种用于重建包括语音信号的帧的系统。所述系统包括根据上述或下述实施例中的一个的用于确定估计音调滞后的装置,以及用于重建所述帧的装置,其中所述用于重建所述帧的装置用于依据所述估计音调滞后重建所述帧。所述估计音调滞后是所述语音信号的音调滞后。
在实施例中,所述重建帧,例如,与一个或多个可用帧相关联,所述一个或多个可用帧是所述重建帧的一个或多个先前帧以及所述重建帧的一个或多个后续帧中的至少一个,其中所述一个或多个可用帧包括作为一个或多个可用音调周期的一个或多个音调周期。所述用于重建所述帧的装置,例如,可以是根据上述或下述实施例中的一个的用于重建帧的装置。
本发明是基于现有技术具有重要缺点的发现。g.718(参看[itu08a])与g.729.1(参看[itu06b])均在帧丢失情况下使用音调外推技术。这是必须的,因为在帧丢失情况下,音调滞后也丢失。根据g.718与g.729.1,通过考虑最后两个帧中的音调演变而外推音调。但是,通过g.718和g.729.1重建的音调滞后不是非常精确,例如,且时常产生显著地不同于真实音调滞后的重建音调滞后。
本发明实施例提供更精确的音调滞后重建。为了这个目的,与g.718与g.729.1相比,一些实施例考虑关于音调信息的可靠度的信息。
根据现有技术,外推技术所依据的音调信息包括最后八个正确地接收的音调滞后,对其的编码模式不同于无声情况。但是,现有技术中,有声特性可能很弱,其通过低音调增益(与低预测增益相对应)指示。在现有技术中,当外推是基于具有不同的音调增益的音调滞后时,外推将不能够输出合理结果或者甚至根本失效且将回退至简单的音调滞后重复方法。
实施例是基于这样的发现:这些现有技术缺点的原因是在编码器侧,音调滞后是关于使音调增益最大化而选择的以便使自适应码本的编码增益最大化,但是,在语音特性弱的情况下,音调滞后可能不精确地指示基本频率,因为语音信号中的噪声导致音调滞后估计变得不精确。
因此,在隐藏过程中,根据实施例,依据先前接收的用于这个外推的滞后的可靠度,对音调滞后外推的应用进行加权。
根据一些实施例,过去的自适应码本增益(音调增益)可以被采用作为可靠度测量。
根据本发明的一些其他实施例,根据音调滞后被接收之后过去多远的权重被用作为可靠度测量。例如,高权重被应用于更近的滞后,低权重被应用于较久前被接收的滞后。
根据实施例,提供加权音调预测概念。与现有技术相比,本发明实施例提供的音调预测对于其基于的音调滞后的每个使用可靠度测量,使得预测结果更有效且稳定。特别地,所述音调增益可被用作可靠度的指标。可选地或额外地,根据一些实施例,音调滞后的正确接收之后已经过去的时间,例如,可用作指标。
关于脉冲再同步化,本发明是基于这样的发现:关于声门脉冲再同步化的现有技术的缺点之一是音调外推不考虑多少脉冲(音调周期)应被构建于隐藏的帧中。
根据现有技术,音调外推被进行以使得音调中的改变仅预期在子帧的边界处。
根据实施例,当进行声门脉冲再同步化时,可以考虑不同于连续音调改变的音调改变。
本发明实施例是基于发现g.718与g.729.1具有以下的缺点:
首先,在现有技术中,当计算d时,假设在帧内有整数数量的音调周期。因为d定义隐藏帧中的最后脉冲的位置,当在所述帧内有非整数数量的音调周期时,所述最后脉冲的位置将不正确。这在图6与图7中示出。图6示出样本移除前的语音信号。图7示出样本移除后的语音信号。此外,现有技术采用的计算d的算法是效率低的。
此外,现有技术的计算需要激励的建构周期部分中的脉冲数量n。这增加不需要的计算复杂性。
此外,在现有技术中,激励的建构周期部分中的脉冲数量n的计算不考虑第一脉冲的位置。
图4与图5中表示的信号具有相同的音调周期长度tc。
图4示出帧内具有3个脉冲的语音信号。
相对地,图5示出帧内仅具有2个脉冲的语音信号。
图4与5示出的这些示例示出脉冲数量取决于第一脉冲位置。
此外,根据现有技术,检查激励的建构周期部分中的第n个脉冲的位置t[n-1]是否在帧长度内,虽然n被定义为包括下一帧中的第一脉冲。
此外,根据现有技术,在第一脉冲之前以及在最后脉冲之后没有样本被增加或被移除。本发明实施例是基于发现这导致第一完全音调周期的长度中可能有突变的缺点,此外,这进一步地导致最后脉冲之后的音调周期的长度可能比最后脉冲之前的最后完全音调周期的长度长的缺点,即使当音调滞后减少时(参看图6与7)。
实施例是基于发现当下列情况时,脉冲t[k]=p-diff与t[n]=p-d不相等:
-
-t[k]在未来帧中且仅在移除d个样本之后,它才移动至当前帧。
-在增加-d(d<0)个样本之后,t[n]移动至未来帧。
这将导致隐藏式帧中的脉冲的错误位置。
此外,实施例是基于发现现有技术中,d的最大值受限于用于编码音调滞后的最小允许值。这是约束,其限制其他问题的发生,但是其也限制音调中的可能改变且因此限制脉冲再同步化。
此外,实施例是基于发现现有技术中,使用整数的音调滞后建构周期部分,且这产生具有恒定音调的音调信号的隐藏中的显著恶化及谐波的频率偏移。这个恶化可参看图8,其中图8示出当使用四舍五入的音调滞后时被再同步化的语音信号的时间-频率表示。
实施例还基于发现现有技术的多数问题发生于通过图6与7示出的示例描述的情况,其中d个样本被移除。此处考虑对d的最大值没有限制,以便使问题容易地可见。当对d有限制时问题也发生,但不是如此显然可见。取代连续地增加音调,在音调的突然增加后接着得到突然减少。实施例是基于发现这发生,因为没有样本在最后脉冲之前及之后被移除,这间接地也因没有考虑在移除d个样本之后脉冲t[2]在帧内移动而导致。在这个示例中也发生n的误差计算。
根据实施例,提供改进的脉冲再同步化概念。实施例提供单声道信号(包括语音)的改进的隐藏,与标准g.718(参看[itu08a])和g.729.1(参看[itu06b])中描述的现有技术相比,其是有利的。所提供的实施例适用于具有恒定音调的信号,以及适用于具有变化音调的信号。
除此之外,根据实施例,提供三种技术:
根据实施例提供的第一技术,提供对于脉冲的搜索概念,与g.718和g.729.1相比,其在建构周期部分中的脉冲数量(表示为n)的计算中考虑第一脉冲的位置。
根据另一实施例提供的第二技术,提供用于搜索脉冲的算法,与g.718和g.729.1相比,其不需要建构周期部分中的脉冲的数量(表示为n),考虑第一脉冲的位置,并且直接地计算隐藏帧中的最后脉冲索引(表示为k)。
根据又一实施例提供的第三技术,不需要脉冲搜索。依据这第三技术,周期部分的建构与样本的移除或增加相结合,因此与现有技术相比实现较小的复杂度。
另外地或可选地,一些实施例对于上述技术以及g.718与g.729.1的技术提供以下的改变:
-音调滞后的小数部分,例如,可用于建构具有恒定音调的信号的周期部分。
-对于帧内的非整数数量的音调周期,例如,可计算隐藏帧中的最后脉冲的预期位置的偏移。
-例如,也可在第一脉冲之前以及在最后脉冲之后增加或移除样本。
-如果仅有一个脉冲,也可例如增加或移除样本。
-被移除或增加的样本的数量,例如,也可随着音调的预测线性改变而线性地改变。
附图说明
下面,将参考附图更详细地描述本发明实施例,其中:
图1示出根据实施例的用于确定估计音调滞后的装置,
图2a示出根据实施例的用于重建包括语音信号的帧作为重建帧的装置,
图2b示出包括多个脉冲的语音信号,
图2c示出根据实施例的用于重建包括语音信号的帧的系统,
图3示出语音信号的建构周期部分,
图4示出帧中具有三个脉冲的语音信号,
图5示出帧中具有两个脉冲的语音信号,
图6示出样本移除前的语音信号,
图7示出样本移除后的图6的语音信号,
图8示出使用四舍五入的音调滞后被再同步化的语音信号的时间-频率表示,
图9示出使用具有小数部分的未四舍五入的音调滞后被再同步化的语音信号的时间-频率表示,
图10示出音调滞后示图,其中使用现有技术重建音调滞后,
图11示出音调滞后示图,其中根据实施例重建音调滞后,
图12示出移除样本前的语音信号,以及
图13示出图12的语音信号,另外示出δ0至δ3。
具体实施方式
图1示出根据实施例的用于确定估计音调滞后的装置。该装置包括用于接收多个原始音调滞后值的输入接口110,以及用于估计估计音调滞后的音调滞后估计器120。音调滞后估计器120用于依据多个原始音调滞后值以及依据多个信息值估计估计音调滞后,其中对于多个原始音调滞后值中的每个原始音调滞后值,多个信息值中的信息值被指定给原始音调滞后值。
根据实施例,音调滞后估计器120,例如,可用于依据多个原始音调滞后值以及依据作为多个信息值的多个音调增益值估计估计音调滞后,其中对于多个原始音调滞后值中的每个原始音调滞后值,多个音调增益值中的音调增益值被指定给原始音调滞后值。
在特定的实施例中,多个音调增益值中的每个是自适应码本增益。
在实施例中,音调滞后估计器120,例如,可用于最小化误差函数而估计估计音调滞后。
根据实施例,音调滞后估计器120,例如,可用于通过最小化下列误差函数而通过确定两个参数a、b以估计估计音调滞后,
其中a是实数,其中b是实数,其中k是具有k≥2的整数,以及其中p(i)是第i个原始音调滞后值,其中gp(i)是被指定给第i个音调滞后值p(i)的第i个音调增益值。
在实施例中,音调滞后估计器120,例如,可用于通过最小化下列误差函数而通过确定两个参数a、b以估计估计音调滞后,
其中a是实数,其中b是实数,其中p(i)是第i个原始音调滞后值,其中gp(i)是被指定给第i个音调滞后值p(i)的第i个音调增益值。
根据实施例,音调滞后估计器120,例如,可用于根据p=a·i+b确定估计音调滞后p。
在实施例中,音调滞后估计器120,例如,可用于依据多个原始音调滞后值以及依据作为多个信息值的多个时间值估计估计音调滞后,其中对于多个原始音调滞后值中的每个原始音调滞后值,多个时间值中的时间值被指定给所述原始音调滞后值。
根据实施例,音调滞后估计器120,例如,可用于通过最小化误差函数而估计估计音调滞后。
在实施例中,音调滞后估计器120,例如,可用于通过最小化下列误差函数而通过确定两个参数a、b以估计估计音调滞后,
其中a是实数,其中b是实数,其中k是具有k≥2的整数,并且其中p(i)是第i个原始音调滞后值,其中timepassed(i)是被指定给第i个音调滞后值p(i)的第i个时间值。
根据实施例,音调滞后估计器120,例如,可用于通过最小化下列误差函数而通过确定两个参数a、b以估计估计音调滞后,
其中a是实数,其中b是实数,其中p(i)是第i个原始音调滞后值,其中timepassed(i)是被指定给第i个音调滞后值p(i)的第i个时间值。
在实施例中,音调滞后估计器120用于根据p=a·i+b确定估计音调滞后p。
下面,关于公式(20)-(24b)描述提供加权音调预测的实施例。
首先,参考公式(20)-(22c)描述采用根据音调增益进行加权的加权音调预测实施例。根据这些实施例中的一些,为克服现有技术缺点,采用音调增益对音调滞后加权以进行音调预测。
在一些实施例中,音调增益可以是标准g.729中定义的自适应码本增益gp(参看[itu12],尤其是章节3.7.3,更尤其是公式(43))。在g.729中,根据下式确定自适应码本增益:
其中,x(n)是目标信号且通过根据下式对v(n)与h(n)进行卷积而得到y(n):
其中v(n)是自适应码本向量,其中y(n)是滤波后的自适应码本向量,且其中h(n-i)是加权合成滤波器的脉冲响应,如g.729(参看[itu12])中所定义。
类似地,在一些实施例中,音调增益可以是标准g.718中定义的自适应码本增益gp(参看[itu08a],尤其是章节6.8.4.1.4.1,更尤其是公式(170))。在g.718中,根据下式确定自适应码本增益:
其中x(n)是目标信号,且yk(n)是延迟k的过去滤波的激励。
例如,参看[itu08a],章节6.8.4.1.4.1,公式(171),定义了如何定义yk(n)。
类似地,在一些实施例中,音调增益可以是amr标准中定义的自适应码本增益gp(参看[3gp12b]),其中根据下式定义作为音调增益的自适应增益gp:
其中y(n)是滤波后的自适应码本向量。
在一些特定的实施例中,例如,可使用音调增益对音调滞后加权,例如,在进行音调预测之前。
为了这个目的,根据实施例,例如,可引入长度8的第二缓冲器保存音调增益,其在相同的子帧处被采取作为音调滞后。在实施例中,例如,可使用完全相同的规则对缓冲器更新以作为音调滞后的更新。一个可能的实现是在各个帧的结束处更新两个缓冲器(保存最后八个子帧的音调滞后与音调增益),不论这个帧是无误差还是容易产生误差。
从现有技术已知有两种不同的预测策略,其可被增强以使用加权音调预测:
一些实施例提供g.718标准的预测策略的显著发明的改进。在g.718中,在包丢失的情况下,缓冲器可以以元素的方式彼此相乘,以便如果相关的音调增益是高的则对音调之后加权高系数,如果相关的音调增益是低的则对它加权低系数。然后,根据g.718,像平常一样进行音调预测(参看[itu08a,部分7.11.1.3],关于g.718的描述)。
一些实施例提供g.729.1标准的预测策略的显著发明的改进。根据实施例,对用于g.729.1的预测音调的算法(参看[itu06b],关于g.729.1的说明)进行修改以便使用加权预测。
根据一些实施例,目标是最小化误差函数:
其中gp(i)保持过去子帧的音调增益且p(i)保持对应的音调滞后。
在发明公式(20)中,gp(i)代表加权系数。在上面的示例中,每个gp(i)代表来自过去子帧中的一个的音调增益。
下面,提供根据实施例的等式,其说明如何推导出系数a与b,其可被用于根据a+i·b预测音调滞后,其中i是待被预测的子帧的子帧数量。
例如,为了基于对最后五个子帧p(0),...,p(4)的预测得到第一预测子帧,预测音调值p(5)将是:
p(5)=a+5·b。
为了推导出系数a与b,误差函数,例如,可以被推导(导数)且可以被设定为零:
现有技术未公开实施例提供的本发明的加权技术。特别地,现有技术未采用加权系数gp(i)。
因此,现有技术中,未采用加权系数gp(i)推导误差函数以及将误差函数的导数设定为0,将导致:
(参看[itu06b,7.6.5])。
相对地,当使用所提供的实施例的加权预测方法时,例如,具有加权系数gp(i)的公式(20)的加权预测方法,a与b成为:
根据特定的实施例,a,b,c,d;e,f,g,h,i,j和k,例如,可具有以下的值:
图10及图11示出提出的音调外推的优越性能。
其中,图10示出音调滞后示图,其中采用现有技术的概念重建音调滞后。相对地,图11示出音调滞后示图,其中根据实施例重建音调滞后。
特别地,图10示出现有技术的标准g.718与g.729.1的性能,而图11示出实施例所提供的概念的性能。
横轴指示子帧数量。实线1010示出编码器音调滞后,其嵌入在比特流中,且其在灰色段的区域1030中丢失。左纵轴代表音调滞后轴。右纵轴代表音调增益轴。实线1010示出音调滞后,而虚线1021、1022、1023示出音调增益。
灰色矩形1030指示帧丢失。因为发生在灰色段的区域1030中的帧丢失,关于这个区域中的音调滞后与音调增益的信息在解码器侧无法得到且必须被重建。
图10中,通过点虚线部分1011示出使用g.718标准隐藏的音调滞后。通过实线部分1012示出使用g.729.1标准隐藏的音调滞后。可清楚看出,使用所提供的音调预测(图11,实线部分1013)基本与丢失的编码器音调滞后相一致,因此优于g.718与g.729.1技术。
下面,参考公式(23a)-(24b)说明使用取决于过去时间的加权的实施例。
为克服现有技术的缺点,一些实施例在进行音调预测之前对音调滞后应用时间加权。应用时间加权可通过最小化这个误差函数而实现:
其中timepassed(i)代表在正确地接收音调滞后之后已经过去的时间量的倒数,p(i)保持相应的音调滞后。
一些实施例,例如,可对较近的滞后应用高权重,对较久前接受到的滞后应用较小的权重。
根据一些实施例,接着可以利用公式(21a)推导出a与b。
为得到第一预测子帧,一些实施例,例如,可基于最后五个子帧p(0),...,p(4)进行预测。例如,可以根据下式得到预测音调值p(5):
p(5)=a+5·b(23b)
例如,如果
timepassed=[1/51/41/31/21]
(根据子帧延迟的时间加权),这将导致:
下面,描述提供脉冲再同步化的实施例。
图2a示出实施例的用于重建包括语音信号的帧作为重建帧的装置。所述重建帧与一个或多个可用帧相关联,所述一个或多个可用帧是重建帧的一个或多个先前帧以及重建帧的一个或多个后续帧中的至少一个,其中一个或多个可用帧包括作为一个或多个可用音调周期的一个或多个音调周期。
装置包括确定单元210,其用于确定样本数量差
此外,装置包括帧重建器(220),其用于通过依据样本数量差
帧重建器(220)用于重建重建帧,以使得重建帧完全地或部分地包括第一重建音调周期,以使得重建帧完全地或部分地包括第二重建音调周期,以及以使得第一重建音调周期的样本数量不同于第二重建音调周期的样本数量。
通过重建应被重建的音调周期的样本中的一些或全部而进行重建音调周期。如果待被重建的音调周期完全地由丢失帧组成,则音调周期的所有样本,例如,必须被重建。如果待被重建的音调周期仅部分地由丢失帧组成,且如果音调周期的一些样本是可用的,例如,由于它们由另一帧组成,则例如,仅重建丢失的帧包括的音调周期的样本对于重建音调周期是足够的。
图2b示出图2a的装置的功能。特别地,图2b示出包括脉冲211、212、213、214、215、216、217的语音信号222。
语音信号222的第一部分由帧n-1组成。语音信号222的第二部分由帧n组成。语音信号222的第三部分由帧n+1组成。
在图2b中,帧n-1先于帧n且帧n+1后于帧n。这意味着,帧n-1包括,与帧n的语音信号的部分相比,时间上较早发生的语音信号的部分;帧n+1包括,与帧n的语音信号的部分相比,时间上较后发生的语音信号的部分。
在图2b的示例中,假设帧n丢失或毁坏,因此,仅先前于帧n的帧(“先前帧”)与后续于帧n的帧(“后续帧”)是可用的(“可用帧”)。
例如,可如下定义音调周期:音调周期开始于脉冲211、212、213等中的一个且结束于语音信号中的紧接着的后续脉冲。例如,脉冲211与212定义音调周期201。脉冲212与213定义音调周期202。脉冲213与214定义音调周期203,等等。
本领域技术人员熟知的例如采用音调周期的其他开始与结束点的音调周期的其他定义也可以被考虑。
在图2b的示例中,帧n在接收器处是不可用的或损坏的。因此,接收器知道帧n-1的脉冲211与212以及音调周期201。此外接收器知道帧n+1的脉冲216与217以及音调周期206。但是,必须重建包括脉冲213、214与215的帧n,其完全地包括音调周期203与204且其部分地包括音调周期202与205。
根据一些实施例,可以依据可用帧(例如,先前帧n-1或后续帧n+1)的至少一个音调周期(“可用音调周期”)的样本重建帧n。例如,可周期性地重复复制帧n-1的音调周期201的样本以重建丢失或损坏的帧的样本。通过周期性地重复复制音调周期的样本,复制音调周期自身,例如,如果音调周期是c,则
样本(x+i·c)=样本(x);i是整数。
在实施例中,复制来自帧n-1的结束部分的样本。被复制第n-1帧的部分的长度等于(或几乎等于)音调周期201的长度。但是来自201与202的样本用于复制。当第n-1帧只有一个脉冲时这可能需特别仔细考虑。
在一些实施例中,复制的样本被修改。
本发明还基于这样的发现:通过周期性地重复复制音调周期的样本,当(完全地或部分地)被丢失帧(n)包括的音调周期(音调周期202、203、204与205)的大小不同于被复制的可用音调周期(此处:音调周期201)的大小时,丢失帧n的脉冲213、214、215移动至错误位置。
例如,图2b中,通过δ1指示音调周期201与音调周期202之间的差,通过δ2指示音调周期201与音调周期203之间的差,通过δ3指示音调周期201与音调周期204之间的差,通过δ4指示音调周期201与音调周期205之间的差。
图2b中,可看出,帧n-1的音调周期201显著地大于音调周期206。此外,(部分地或完全地)被帧n包括的音调周期202、203、204与205的每个均小于音调周期201且大于音调周期206。此外,较接近于大音调周期201的音调周期(例如,音调周期202)大于较接近于小音调周期206的音调周期(例如,音调周期205)。
根据本发明的这些发现,根据实施例,帧重建器220用于重建重建帧,以使得第一重建音调周期的样本数量不同于被重建帧部分地或完全地包括的第二重建音调周期的样本数量。
例如,根据一些实施例,帧的重建取决于样本数量差,所述样本数量差指示一个或多个可用音调周期中的一个(例如,音调周期201)的样本数量与待被重建的第一音调周期(例如,音调周期202、203、204、205)的样本数量之间的差。
例如,根据实施例,音调周期201的样本,例如,可被周期性地重复复制。
接着,样本数量差指示多少样本应从与待被重建的第一音调周期相对应的周期性重复的复制中删除,或多少样本应被增加至与待被重建的第一音调周期相对应的周期性重复的复制中。
图2b中,每个样本数量指示多少样本应从周期性重复的复制中删除。但是,在其他的示例中,样本数量可以指示多少样本应被增加至周期性重复的复制。例如,在一些实施例中,可以通过增加具有零振幅的样本至对应的音调周期而增加样本。在其他的实施例中,可以通过复制音调周期的其他样本,例如,通过复制与待被增加的样本的位置相邻的样本而增加样本至音调周期。
虽然上面已经描述在其中已经周期性地重复复制丢失帧或损坏帧之前的帧的音调周期的样本的实施例,但是在其他的实施例中,周期性地重复复制在丢失帧或损坏帧后的帧的音调周期的样本以重建丢失帧。类似地应用如上与如下所述的相同原理。
可以对于待被重建的每个音调周期确定这个样本数量差。接着,每个音调周期的样本数量差指示多少样本应从与待被重建的相应音调周期对应的周期性重复的复制中删除,或多少样本应被增加至与待被重建的相应音调周期对应的周期性重复的复制。
根据实施例,确定单元210,例如,可用于确定对于待被重建的多个音调周期中的每个的样本数量差,以使得音调周期中的每个的样本数量差指示一个或多个可用音调周期中的所述一个的样本数量与待被重建的所述音调周期的样本数量之间的差。帧重建器220,例如,可用于依据待被重建的所述音调周期的样本数量差以及依据一个或多个可用音调周期中的所述一个的样本重建待被重建的多个音调周期的每个音调周期,从而重建重建帧。
在实施例中,帧重建器220,例如,可用于依据一个或多个可用音调周期中的所述一个生成中间帧。帧重建器220,例如,可用于修改中间帧以得到重建帧。
根据实施例,确定单元210,例如,可用于确定指示多少样本将从中间帧移除或多少样本将被增加至中间帧的帧差值(d;s)。此外,帧重建器220,例如,可用于当帧差值指示第一样本应从帧移除时,将第一样本从中间帧移除以得到重建帧。此外,帧重建器220,例如,可用于当帧差值(d;s)指示第二样本应被增加至帧时,将第二样本增加至中间帧以得到重建帧。
在实施例中,帧重建器220,例如,可用于当帧差值指示第一样本应从帧移除时,将第一样本从中间帧移除,因而从中间帧移除的第一样本数量由帧差值指示。此外,帧重建器220,例如,可用于当帧差值指示第二样本应被增加至帧时,将第二样本增加至中间帧,因而被增加至中间帧的第二样本的数量由帧差值指示。
根据实施例,确定单元210,例如,可用于确定帧差量s,因而适用下列公式:
其中l指示重建帧的样本的数量,其中m指示重建帧的子帧的数量,其中tr指示一个或多个可用音调周期的所述一个的四舍五入的音调周期长度,并且其中p[i]指示重建帧的第i个子帧的重建音调周期的音调周期长度。
在实施例中,帧重建器220,例如,可适于依据一个或多个可用音调周期中的所述一个生成中间帧。此外,帧重建器220,例如,可适于生成中间帧,以便中间帧包括第一部分中间音调周期、一个或多个其他中间音调周期、以及第二部分中间音调周期。此外,第一部分中间音调周期,例如,取决于一个或多个可用音调周期的所述一个的样本中的一个或多个,其中所述一个或多个其他中间音调周期中的每个取决于一个或多个可用音调周期中的所述一个的所有样本,并且其中第二部分中间音调周期取决于一个或多个可用音调周期中的所述一个的样本中的一个或多个。此外,确定单元210,例如,可用于确定指示多少样本将从所述第一部分中间音调周期移除或增加至第一部分中间音调周期的开始部分差量,并且其中帧重建器220用于依据开始部分差量,从第一部分中间音调周期移除一个或多个第一样本,或增加一个或多个第一样本至第一部分中间音调周期。此外,确定单元210,例如,可用于对于其他中间音调周期中的每个确定音调周期差量,所述音调周期差量指示多少样本将从其他中间音调周期中所述一个移除或增加至其他中间音调周期中的所述一个。此外,帧重建器220,例如,可用于依据音调周期差量,从其他中间音调周期中的所述一个移除一个或多个第二样本,或增加一个或多个第二样本至其他中间音调周期中的所述一个。此外,确定单元210,例如,可用于确定指示多少样本将从第二部分中间音调周期移除或增加至第二部分中间音调周期的结束部分差量,并且其中帧重建器220用于依据结束部分差量,从第二部分中间音调周期移除一个或多个第三样本,或增加一个或多个第三样本至第二部分中间音调周期。
根据实施例,帧重建器220,例如,可用于依据一个或多个可用音调周期中的所述一个生成中间帧。此外,确定单元210,例如,可适于确定被中间帧包括的语音信号的一个或多个低能量信号部分,其中一个或多个低能量信号部分中的每个是中间帧内的语音信号的第一信号部分,其中所述语音信号的能量低于被中间帧包括的语音信号的第二信号部分中的能量。此外,帧重建器220,例如,可用于从语音信号的一个或多个低能量信号部分中的至少一个移除一个或多个样本,或增加一个或多个样本至语音信号的一个或多个低能量信号部分中的至少一个,以得到重建帧。
在特定实施例中,帧重建器220,例如,可用于生成中间帧,以使得中间帧包括一个或多个重建音调周期,以使得一个或多个重建音调周期中的每个取决于一个或多个可用音调周期中的所述一个。此外,确定单元210,例如,可用于确定应从一个或多个重建音调周期中的每个移除的样本的数量。此外,确定单元210,例如,可用于确定一个或多个低能量信号部分中的每个,以使得对于一个或多个低能量信号部分中的每个,所述低能量信号部分的样本的数量取决于应从一个或多个重建音调周期中的一个移除的样本的数量,其中所述低能量信号部分位于一个或多个重建音调周期中的所述一个内。
在实施例中,确定单元210,例如,可用于确定待被重建作为重建帧的帧的语音信号的一个或多个脉冲的位置。此外,帧重建器220,例如,可用于依据语音信号的一个或多个脉冲的位置重建重建帧。
根据实施例,确定单元210,例如,可用于确定待被重建作为重建帧的帧的语音信号的两个或更多个脉冲的位置,其中t[0]是待被重建作为重建帧的帧的语音信号的两个或更多个脉冲中的一个的位置,以及其中确定单元210用于根据下列公式确定语音信号的两个或更多个脉冲中的其他脉冲的位置(t[i]):
t[i]=t[0]+itr
其中tr指示一个或多个可用音调周期中的所述一个的四舍五入的长度,并且其中i是整数。
根据实施例,确定单元210,例如,可用于确定待被重建作为重建帧的帧的语音信号的最后脉冲的索引k,以使得
其中l指示重建帧的样本的数量,其中s指示帧差值,其中t[0]指示待被重建作为重建帧的帧的语音信号的脉冲的位置,其不同于语音信号的最后脉冲,并且其中tr指示一个或多个可用音调周期中的所述一个的四舍五入的长度。
在实施例中,确定单元210,例如,可用于通过确定参数δ而重建待被重建作为重建帧的帧,其中根据下列公式定义参数δ:
其中待被重建作为重建帧的帧包括m个子帧,其中tp指示一个或多个可用音调周期中的所述一个的长度,并且其中text指示待被重建作为重建帧的帧的待被重建的音调周期中的一个的长度。
根据实施例,确定单元210,例如,可用于通过基于下列公式确定一个或多个可用音调周期中的所述一个的四舍五入长度tr而重建所述重建帧:
其中tp指示一个或多个可用音调周期中的所述一个的长度。
在实施例中,确定单元210,例如,可用于通过应用下列公式而重建所述重建帧:
其中tp指示一个或多个可用音调周期中的所述一个的长度,其中tr指示一个或多个可用音调周期中的所述一个的四舍五入的长度,其中待被重建作为重建帧的帧包括m个子帧,其中待被重建作为重建帧的帧包括l个样本,以及其中δ是实数,其指示一个或多个可用音调周期中的所述一个的样本数量与待被重建的一个或多个音调周期中的一个的样本数量之间的差。
接着,更详细地说明实施例。
下面,参考公式(25)-(63)说明第一组脉冲再同步化实施例。
在这些实施例中,如果没有音调改变,则使用最后音调滞后而不四舍五入,保留小数部分。使用非整数音调与内推(例如参看[mtta90])建构周期部分。与使用四舍五入的音调滞后相比,这将减小谐波的频率偏移,且因此显著地改进具有恒定音调的音调或有声信号的隐藏。
通过图8与图9示出优点,分别使用四舍五入的音调滞后和未四舍五入的分数的音调滞后隐藏表示具有帧丢失的调音管的信号。此处,图8示出使用四舍五入的音调滞后的被再同步化的语音信号的时间-频率表示。相对地,图9示出使用具有小数部分的未四舍五入的音调滞后的被再同步化的语音信号的时间-频率表示。
当使用音调的小数部分时将有增加的计算复杂性。这应不影响最差情况复杂性,因不需要声门脉冲再同步化。
如果没有预测音调改变,则不需要下面说明的处理。
如果音调改变被预测,参考公式(25)-(63)说明的实施例提供用于确定d的概念,d是在具有恒定音调的音调周期(tc)内的样本的总数量和与具有演变音调的音调周期p[i]内的样本的总数量和之间的差。
下面,如公式(15a)中定义tc:tc=四舍五入(最后音调)。
根据实施例,可以使用更快且更精确的算法(用于确定d的方法的快速算法)确定差d,如下所述。
例如,这种算法可基于下面的原理:
-在每个子帧i中:对于(长度为tc)的每个音调周期,应移除tc-p[i]个样本(或如果tc-p[i]<0,增加tc-p[i]个样本)。
-每个子帧中有
-因此,对于每个子帧,
根据一些实施例,没有进行四舍五入且使用分数音调。那么:
-p[i]=tc+(i+1)δ。
-因此,对于每个子帧i,如果δ<0,
-因此,
根据一些其他实施例,进行四舍五入。对于整数音调(m是帧中的子帧的数量),如下所示定义d:
根据实施例,相应地提供用于计算d的算法:
在另一实施例中,算法的最后一行被如下所取代:
d=(short)floor(l_frame-ftmp*(float)l_subfr/t_c+0.5);
根据实施例,根据下面公式发现最后脉冲t[n]:
n=i|t[0]+itc<l_frame∧t[0]+(i+1)tc≥l_frame(26)
根据实施例,采用计算n的公式。根据公式(26)得到这个公式:
并且然后,最后脉冲具有索引n-1。
根据这个公式,对于图4以及图5所示的示例可计算n。
下面,描述对于最后脉冲不进行明确搜寻,但是考虑脉冲位置的概念。这个概念不需要n(建构周期性部分中的最后脉冲的索引)。
激励(t[k])的建构周期部分中的实际最后脉冲位置确定完全音调周期的数量k,其中样本被移除(或被增加)。
图12示出移除d个样本前的最后脉冲t[2]的位置。关于参考公式(25)-(63)所描述的实施例,附图标记1210指示d。
在图12的示例中,最后脉冲的索引k是2并且有2个将自其中移除样本的完全音调周期。
在从长度为l_frame+d的信号移除d个样本之后,没有样本来自l_frame+d个样本之外的原始信号。因此t[k]在l_frame+d样本内,并且因此通过公式(28)确定k:
k=i|t[i]<lframe+d≤t[i+1](28)
从公式(17)以及公式(28),得到:
t[0]+ktc<lframe+d≤t[0]+(k+1)tc(29)
即,
从公式(30),得到:
在编解码器(例如,使用至少20毫秒的帧,并且在其中语音的最低基本频率是,例如,至少40hz)中,在多数情况下,至少一个脉冲存在于除了无声(unvoiced)之外的隐藏帧中。
下面,参考公式(32)-(46)说明具有至少两个脉冲(k≥1)的情况。
假设,脉冲之间的每个完整的第i个音调周期中,应移除δi个样本,其中δi被定义为:
δi=δ+(i-1)a,1≤i≤k,(32)
其中a是未知的变量,其需要根据已知的变量被表示。
假设,在第一脉冲前应移除δ0个样本,其中δ0被定义为:
假设,在最后脉冲之后应移除δk+1个样本,其中δk+1被定义为:
最后两个假设符合考虑部分第一和最后音调周期的长度的公式(32)。
δi值的每个是样本数量差。而且,δ0是样本数量差。此外,δk+1是样本数量差。
图13示出图12的语音信号,另外地说明δ0至δ3。在图13的示例中,示意性地表示每个音调周期中将被移除的样本的数量,其中k=2。关于参考公式(25)-(63)描述的实施例,附图标记1210指示d。
于是,将被移除的样本的总数量d根据下式与δi相关:
从公式(32)-(35),可以得到d为:
公式(36)等效于:
假设,隐藏帧中的最后完全音调周期具有p[m-1]的长度,即:
δk=tc-p[m-1](38)
从公式(32)以及公式(38),得到:
δ=tc-p[m-1]-(k-1)a(39)
此外,从公式(37)以及公式(39),得到:
公式(40)等效于:
从公式(17)以及公式(41),得到:
公式(42)等效于:
此外,从公式(43),得到:
公式(44)等效于:
此外,公式(45)等效于:
根据实施例,现在基于公式(32)-(34)、(39)及(46)计算,在第一脉冲之前、和/或在脉冲之间和/或在最后脉冲之后,将移除或增加多少样本。
在实施例中,在最小能量区域中移除或增加样本。
根据实施例,例如,将被移除的样本的数量,如下被四舍五入:
下面,参考公式(47)-(55)说明具有一个脉冲(k=0)的情况。
如果在隐藏帧中仅有一个脉冲,则在脉冲前将移除δ0个样本:
其中δ与a是需要根据已知变量表示的未知变量。在脉冲后将移除δ1个样本,其中:
于是,给出将被移除的样本的总数量:
d=δ0+δ1(49)
从公式(47)-(49),得到:
公式(50)等效于:
dtc=δ(l+d)-at[0](51)
假设脉冲前的音调周期与脉冲后的音调周期的比率与最后子帧中的音调滞后与先前接收到的帧中的第一子帧中的音调滞后之间的比率相同:
从公式(52),得到:
此外,从公式(51)以及公式(53),得到:
公式(54)等效于:
在脉冲前,有
下面,参考公式(56)-(63)说明不要脉冲(位置)搜索的根据实施例的简化概念。
t[i]指示第i个音调周期的长度。在从信号移除d个样本之后,得到k个完全音调周期与1个部分(至完整)音调周期。
因此:
由于在移除一些样本之后从长度tc的音调周期得到长度t[i]的音调周期,且由于被移除样本的总数量是d,于是得到:
ktc<l+d≤(k+1)tc(57)
接着得到:
而且,得到:
根据实施例,音调滞后的线性改变可以被假设为:
t[i]=tc-(i+1)δ,0≤i≤k
在实施例中,在第k个音调周期中移除(k+1)δ个样本。
根据实施例,第k个音调周期的部分中,移除样本之后保留在帧中的
因此,被移除的样本的总数量是:
公式(60)等效于:
而且,公式(61)等效于:
此外,公式(62)等效于:
根据实施例,在最小能量的位置处移除(i+1)δ个样本。不需要知道脉冲的位置,因为在保存一个音调周期的循环缓冲中完成了对于最小能量位置的搜索。
如果最小能量位置在第一脉冲之后且如果不移除第一脉冲之前的样本,则可发生音调滞后如(tc+δ),tc,tc,(tc-δ),(tc-2δ)(最后接收到的帧中有2个音调周期且隐藏帧中有3个音调周期)演变的情况。因此,将有中断。在最后脉冲之后可能出现类似的中断,但是其发生的时间与第一脉冲前的中断发生的时间不同。
另一方面,如果脉冲较接近隐藏帧开始部分,则最小能量区域将更可能出现在第一脉冲之后。如果第一脉冲较接近隐藏帧开始部分,将更可能是最后接收帧中的最后音调周期大于tc。为了减低音调改变中断的可能性,应使用加权,以提供最小区域较接近音调周期的开始部分或结束部分的优点。
根据实施例,描述所提供的概念的实施,其中进行以下方法步骤中的一个或多个或全部:
1.在临时缓冲器b中,存储来自最后接收帧的结束部分的低通滤波的tc个样本,并行搜索最小能量区域。在搜索最小能量区域时,临时缓冲器被考虑为循环缓冲器。(这可以意味着最小能量区域可以由来自音调周期开始部分的一些样本和结束部分的一些样本组成。)最小能量区域,例如,可以是长度为
2.从临时缓冲器b复制样本至帧,跳过在最小能量区域处的
3.对于第i个音调周期(0<i<k),从第(i-1)个音调周期复制样本,跳过在最小能量区域处的
4.对于第k个音调周期,使用加权搜索第(k-1)个音调周期中的新的最小区域,提供最小区域较接近音调周期的结束的优点。接着从第(k-1)个音调周期复制样本,跳过最小能量区域处的
如果需要增加样本,通过考虑d<0与δ<0,增加总共|d|个样本,在最小能量位置处在第k个周期中增加(k+1)|δ|个样本,可以使用等效步骤。
如上面关于“用于确定d的方法的快速算法”所述,在子帧电平处可使用分数音调以推导出d,因为不管怎样使用近似音调周期长度。
下面,参考公式(64)-(113)说明第二组脉冲再同步化实施例。第一组的这些实施例采用公式(15b)的定义,
其中,最后音调周期长度是tp,且被复制的片段的长度是tr。
如果下面不定义第二组脉冲再同步化实施例使用的一些参数,则本发明实施例可以采用关于上面定义的第一组脉冲再同步化实施例提供给这些参数的定义(参看公式(25)-(63))。
第二组脉冲再同步化实施例的公式(64)-(113)中的一些可以重新定义先前已经关于第一组脉冲再同步化实施例使用的一些参数。在这种情况下,所提供的重新限定的定义应用于第二脉冲再同步化实施例。
如上所述,根据一些实施例,例如,可对于一个帧与一个额外的子帧,建构周期部分,其中帧长度表示为l=lframe。
例如,帧中有m个子帧,子帧长度是
如先前所述,t[0]是激励的建构周期部分中的第一最大脉冲的位置。其他脉冲的位置由下式给出:
t[i]=t[0]+itr。
根据实施例,依据激励的周期部分的建构,例如,在激励的周期部分的建构之后,进行声门脉冲再同步化以校正丢失帧中的最后脉冲的估计目标位置(p)与其在激励的建构周期部分中的实际位置(t[k])之间的差。
例如,可通过音调滞后演变的估计间接地确定丢失帧中最后脉冲的估计目标位置(p)。例如,基于丢失帧前的最后七个子帧的音调滞后外推得到音调滞后演变。每个子帧中的演变音调滞后是:
p[i]=tp+(i+1)δ,0≤i<m(64)
其中
并且,text是外推的音调且i是子帧索引。例如,可使用加权线性拟合或来自g.718的方法或来自g.729.1的方法或用于音调内推的任何其他的方法(例如,考虑未来帧的一个或多个音调)进行音调外推。音调外推也可是非线性的。在实施例中,可以如上面确定textt的相同方式确定text。
具有演变音调(p[i])的音调周期内的样本总数量和与具有恒定音调(tp)的音调周期内的样本总数量和之间的帧长度差表示为s。
根据实施例,如果text>tp,则s个样本应被增加至帧,如果text<tp,则-s个样本应从帧移除。在增加或移除|s|个样本之后,隐藏帧中的最后脉冲将在估计目标位置(p)处。
如果text=tp,不需要帧内的样本增加或移除。
根据一些实施例,通过在所有音调周期的最小能量区域中增加或移除样本而完成声门脉冲再同步化。
下面,参考公式(66)-(69)说明根据实施例的计算参数s。
根据一些实施例,例如,可基于下面的原理计算差s:
-在每个子帧i中,(如果p[i]-tr>0),对于每个音调周期(长度tr),应增加p[i]-tr个样本;(或者,如果p[i]-tr<0,应移除p[i]-tr个样本)。
-每个子帧中有
-因此,在第i个子帧中,应移除
因此,根据实施例,符合公式(64),例如,可依据公式(66)计算s:
公式(66)等效于:
其中公式(67)等效于:
且其中公式(68)等效于:
注意,如果text>tp,则s是正的且应增加赝本,如果text<tp,则s是负的且应移除样本。因此,被移除或被增加的样本的数量可表示为|s|。
下面,参考公式(70)-(73)说明根据实施例的计算最后脉冲的索引。
激励的建构周期部分中的实际最后脉冲位置(t[k])确定完全音调周期的数量k,其中样本被移除(或被增加)。
图12示出移除样本前的语音信号。
在图12示出的示例中,最后脉冲的索引k是2且有应从其移除样本的两个完全音调周期。关于参考公式(64)-(113)说明的实施例,附图标记1210指示|s|。
在从长度l-s的信号移除|s|个样本之后,其中l=l_frame,或在增加|s|个样本至长度l-s的信号之后,在l-s个样本之外没有来自原始信号的样本。应注意,如果样本被增加则s是正的,如果样本被移除则s是负的。因此如果样本被增加则l-s<l,如果样本被移除则l-s>l。因此t[k]必须在l-s个样本内,因此通过下式确定k:
k=i|t[i]<l-s≤t[i+1](70)
从公式(15b)与公式(70),得到:
t[0]+ktr<l-s≤t[0]+(k+1)tr(71)
即:
根据实施例,例如,可基于公式(72)确定k:
例如,在采用例如至少20毫秒的帧,且采用语音的至少40hz的最低基本频率的编解码器中,在多数情况下,至少一个脉冲存在于除了无声之外的隐藏帧中。
下面,参考公式(74)-(99)说明根据实施例的计算最小区域中被移除的样本数量。
例如,可假设脉冲之间的每个完全第i个音调周期中应移除(或增加)δi个样本,其中δi被定义如下:
δi=δ+(i-1)a,1≤i≤k(74)
且其中a是未知变量,例如,可通过已知变量表示。
此外,例如,可假设在第一脉冲之前应移除(或增加)
此外,例如,可假设在最后脉冲之后应移除(或增加)
最后两个假设符合考虑部分第一和最后音调周期的长度的公式(74)。
图13的示例中示意性地表示每个音调周期中将被移除(或被增加)的样本的数量,其中k=2。图13示出每个音调周期中被移除的样本的示意性表示。关于参考公式(64)-(113)说明的实施例,附图标记1210指示|s|。
将被移除(或被增加)的样本的总数量s根据下式与δi相关:
从公式(74)-(77),得到:
公式(78)等效于:
此外,公式(79)等效于:
此外,公式(80)等效于:
此外,考虑公式(16b),则公式(81)等效于:
根据实施例,可假设在最后脉冲之后的完全音调周期中移除(或增加)的样本的数量由下式给出:
δk+1=|tr-p[m-1]|=|tr-text|(83)
从公式(74)与公式(83),得到:
δ=|tr-text|-ka(84)
从公式(82)与公式(84),得到:
公式(85)等效于:
此外,公式(86)等效于:
此外,公式(87)等效于:
从公式(16b)与公式(88),得到:
公式(89)等效于:
此外,公式(90)等效于:
此外,公式(91)等效于:
此外,公式(92)等效于:
由公式(93),得到:
因此,例如,基于公式(94),根据实施例:
-计算在第一脉冲之前将移除和/或增加多少样本,和/或
-计算在脉冲之间将移除和/或增加多少样本,和/或
-计算在最后脉冲之后将移除和/或增加多少样本。
根据一些实施例,例如,可在最小能量区域中移除或增加样本。
由公式(85)与公式(94),得到:
公式(95)等效于:
此外,由公式(84)与公式(94),得到:
δi=δ+(i-1)a=|tr-text|-ka+(i-1)a,1≤i≤k(97)
公式(97)等效于:
δi=|tr-text|-(k+1-i)a,1≤i≤k(98)
根据实施例,可基于公式(97)计算在最后脉冲之后被移除的样本的数量:
应注意,根据实施例,
由于复杂性理由,在一些实施例中,要求增加或移除整数数量的样本且因此,在这种实施例中,
下面,参考公式(100)-(113)说明根据实施例的用于脉冲再同步化的算法。
根据实施例,这个算法的输入参数例如可为:
l-帧长度
m-子帧的数量
tp-最后接收帧的结束处的音调周期长度
text-隐藏帧的结束处的音调周期长度
src_exc-通过复制来自最后接收帧的结束部分的激励信号的低通滤波的最后音调周期而生成的输入激励信号,如上所述
dst_exc-对于脉冲再同步化,使用此处说明的算法从src_exc生成输出激励信号
根据实施例,这个算法可以包括以下步骤中的一个或多个或全部:
-基于公式(65),计算每子帧音调改变:
-基于公式(15b),计算四舍五入的开始音调:
-基于公式(69),计算被增加的样本的数量(如果负的则是被移除):
-发现激励src_exc的建构周期部分中的前tr个样本中的第一最大脉冲的位置t[0]。
-基于公式(73),得到再同步化帧dst_exc中的最后脉冲的索引:
-基于公式(94),计算a-连续周期之间将被增加或被移除的样本的增量:
-基于公式(96),计算在第一脉冲之前将被增加或被移除的样本的数量:
-将在第一脉冲之前被增加或被移除的样本的数量向下舍入且将小数部分保存在存储器中:
-基于公式(98),对于2个脉冲之间的每个区域,计算被增加或被移除的样本的数量:
δi=|tr-text|-(k+1-i)a,1≤i≤k(108)
-考虑从先前的舍入留下的小数部分,将2个脉冲之间被增加或被移除的样本的数量向下舍入:
f=δi-δ′i(110)
-如果对于一些i,由于增加的f,δ′i>δ′i-1,则交换δ′i与δ′i-1的值。
-基于公式(99),计算在最后脉冲之后将被增加或被移除之样本数量:
-接着,计算在最小能量区域之间将被增加或被移除的样本的最大数量:
-发现src_exc中的前两个脉冲之间最小能量段的位置pmin[1],其具有δmax的长度。对于两个脉冲之间的每个连续最小能量段,通过下式计算位置:
pmin[i]=pmin[1]+(i-1)tr,1<i≤k(113)
-如果pmin[1]>tr,则使用pmin[0]=pmin[1]-tr计算src_exc中的第一脉冲之前的最小能量段的位置。否则,发现src_exc中的第一脉冲之前的最小能量段的位置pmin[0],其具有δ′0的长度。
-如果pmin[1]+ktr<l-s,则使用pmin[k+1]=pmin[1]+ktr计算src_exc中的最后脉冲之后的最小能量段的位置。否则,发现src_exc中的最后脉冲之后的最小能量段的位置pmin[k+1],其具有δ′k+1长度。
-如果在隐藏激励信号dst_exc中仅有一个脉冲,即如果k等于0,限制对于pmin[1]至l-s的搜索,则pmin[1]表明src_exc中的最后脉冲之后的最小能量段的位置。
-如果s>0,在位置pmin[i](0≤i≤k+1)处增加δ′i个样本至信号src_exc,并将其存储在dst_exc中,否则如果s<0,在位置pmin[i](0≤i≤k+1)处从信号src_exc移除δ′i个样本并将其存储在dst_exc中。有k+2个在其处移除或增加样本的区域。
图2c示出实施例的用于重建包括语音信号的帧的系统。系统包括根据上述实施例中的一个的用于确定估计音调滞后的装置100,以及用于重建帧的装置200,其中用于重建帧的装置用于依据估计音调滞后重建帧。估计音调滞后是语音信号的音调滞后。
在实施例中,重建帧,例如,可与一个或多个可用帧相关联,所述一个或多个可用帧是重建帧的一个或多个先前帧与重建帧的一个或多个后续帧中的至少一个,其中一个或多个可用帧包括作为一个或多个可用音调周期的一个或多个音调周期。用于重建帧的装置200,例如,可以是根据上述实施例中的一个的用于重建帧的装置。
虽然一些方面已在系统的背景下被说明,应清楚,这些方面也表示对应方法的描述,其中块或装置对应方法步骤或方法步骤的特征。类似地,在方法步骤的背景下描述的方面也代表对应装置的对应块或项或特征的描述。
本发明的分解信号可存储在数字存储介质上或可在传输介质(例如无线传输介质或有线传输介质如因特网)上传输。
依据某些实施需要,本发明实施例可以通过硬件或软件实现。可使用其上具有电子可读控制信号且与可编程计算机系统协作以便进行各个方法的数字存储介质,例如软盘、dvd、cd、rom、prom、eprom、eeprom或闪存,进行实现。
根据本发明的一些实施例包括具有电子可读控制信号的非暂时性数据载体,其能够配与可编程计算机系统协作,以便进行此处说明的方法中的一个。
通常,本发明实施例可被实现为具有程序代码的计算机程序产品,当计算机程序产品在计算机上运行时,程序代码可操作用于进行方法中的一个。程序代码,例如,可以存储在机器可读载体上。
其他实施例包括存储在机器可读载体上用于进行此处描述的方法中的一个的计算机程序。
换言之,本发明方法的实施例因此是计算机程序,其具有用于当所述计算机程序在计算机上运行时执行此处说明的方法中的一个的程序代码。
因此,本发明方法的进一步实施例是包括记录在其上的用于进行此处描述的方法中的一个的计算机程序的数据载体(或数字存储介质,或计算机可读介质)。
因此,本发明方法的进一步实施例是表示用于进行此处描述的方法中的一个的计算机程序的数据流或信号序列。数据流或信号序列,例如,可以被配置为通过数据通信连接,例如通过因特网,进行传递。
进一步的实施例包括处理元件,例如,计算机或可编程逻辑装置,其用于或适于执行此处描述的方法中的一个。
进一步的实施例包括计算机,其具有安装在其上用于进行此处说明的方法中的一个的计算机程序。
在一些实施例中,可编程逻辑装置(例如,现场可编程门阵列)可用于进行此处说明的方法的一些或所有功能。在一些实施例中,现场可编程门阵列可与微处理器协作以便进行此处说明的方法中的一个。通常,方法优选地由硬件设备执行。
上面描述的实施例仅是本发明原理的示例。应理解,此处说明的配置和细节的修改和变化对于本领域其他技术人员是明显的。因此,本发明仅受所附权利要求的范围的限制,而不受通过此处的实施例的描述和说明而表示的具体细节的限制。
参考文献
[3gp09]3gpp;技术规范组服务和系统方面,扩展的自适应多速率快带(amr-wb+)编解码器,3gppts26.290,第三代合作伙伴计划,2009.
[3gp12a],自适应多速率(amr)语音编解码器;丢失帧的误差隐藏(11版),3gppts26.091,第三代合作伙伴计划,2012年9月.
[3gp12b],语音编解码器语音处理功能;自适应多速率宽带(amrwb)语音编解码器;错误或丢失帧的误差隐藏,3gppts26.191,第三代合作伙伴计划,2012年9月.
[gao]yanggao,pitchpredictionforpacketlossconcealment,欧洲专利2002427b1.
[itu03]itu-t,widebandcodingofspeechataround16kbit/susingadaptivemulti-ratewideband(amr-wb),推荐itu-tg.722.2,itu的电信标准化部,2003年6月.
[itu06a],g.722附录iii:ahigh-complexityalgorithmforpacketlossconcealmentforg.722,itu-t推荐,itu-t,2006年11月.
[itu06b],g.729.1:g.729-basedembeddedvariablebit-ratecoder:an8-32kbit/sscalablewidebandcoderbitstreaminteroperablewithg.729,推荐itu-tg.729.1,itu的电信标准化部,2006年5月.
[itu07],g.722附录iv:alow-complexityalgorithmforpacketlossconcealmentwithg.722,itu-t推荐,itu-t,2007年8月.
[itu08a],g.718:frameerrorrobustnarrow-bandandwidebandembeddedvariablebit-ratecodingofspeechandaudiofrom8-32kbit/s,推荐itu-tg.718,itu的电信标准化部,2008年6月.
[itu08b],g.719:low-complexity,full-bandaudiocodingforhigh-quality,conversationalapplications,推荐itu-tg.719,itu的电信标准化部,2008年6月.
[itu12],g.729:codingofspeechat8kbit/susingconjugate-structurealgebraic-code-excitedlinearprediction(cs-acelp),推荐itu-tg.729,itu的电信标准化部,2012年6月.
[mcz11]xinwenmu,hexinchen,和yanzhao,aframeerasureconcealmentmethodbasedonpitchandgainlinearpredictionfbramr-wbcodec,消费电子(icce),2011ieee国际会议,2011年1月,815-816页.
[mtta90]j.s.marques,i.trancoso,j.m.tribolet,和l.b.almeida,improvedpitchpredictionwithfractionaldelaysincelpcoding,acoustics,speech,andsignalprocessing,1990.icassp-90.,1990国际会议,1990,665-668页,卷2.
[vjgs12]tommyvaillancourt,milanjelinek,philippegournay,和redwansalami,methodanddeviceforefficientframeerasureconcealmentinspeechcodecs,us8,255,207b2,2012.
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



