
 商标分类
商标分类  商标转让
商标转让 
一种基于深度学习的语音增强方法及系统与流程
 2021-01-28 15:01:13|
2021-01-28 15:01:13| 374|
374| 起点商标网
起点商标网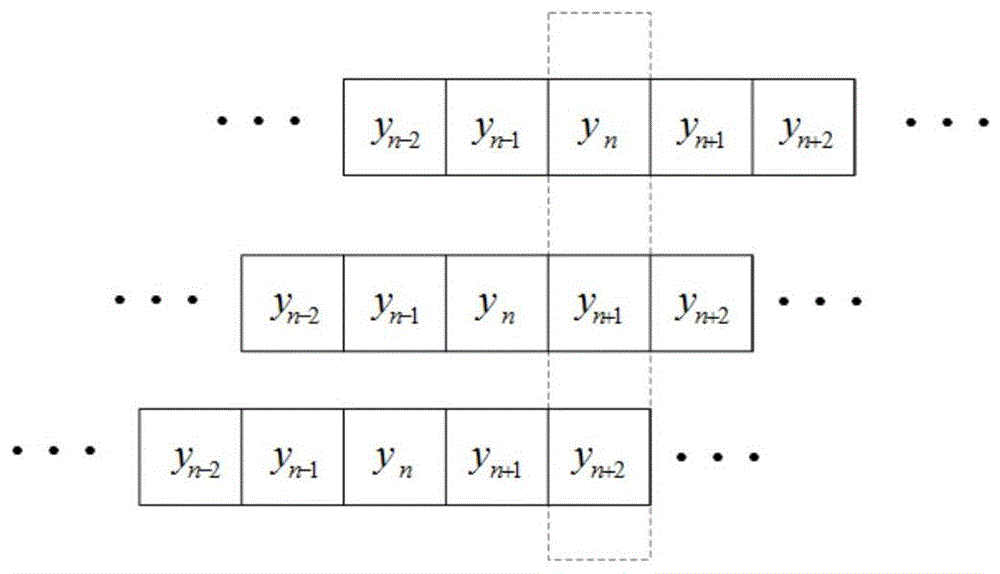
本发明涉及一种基于深度学习的语音增强方法及系统,属于语音处理技术领域。
背景技术:
传统语音增强需要对噪声信号和干净语音信号的独立性和特征分布做出假设,不合理的假设会造成噪声残留、语音失真等问题,导致语音增强效果不佳;此外,噪声本身的随机性和突变性也会影响传统语音增强方法的鲁棒性;总的来说,其对平稳噪声的抑制效果较好,且运行效率高。但是其对于非平稳噪声效果较差,且易有较大程度的失真。而基于深度神经网络的语音增强方法,由于具备强大的非线性拟合能力,对非平稳噪声表现出了更好的效果,且语音失真情况较少。
近几年基于语音识别的输入法和语义理解被大幅应用于智能手机,车载设备,可穿戴设备以及智能家居的各个电器设备中,这些设备通常都在比较复杂的声学环境中被用户所用。而复杂的噪声环境通常让语音的识别率显著下降,识别率的下降意味着这些设备无法准确理解用户的指令,这就会大幅降低用户的体验。因此,前端语音增强技术就可以确保把语音从带噪信号中分离出来,以便后端识别模型能正确识别语音的内容。
技术实现要素:
本发明的目的在于,克服现有技术存在的技术缺陷,解决上述技术问题,提出一种基于深度学习的语音增强方法及系统。
本发明具体采用如下技术方案:一种基于深度学习的语音增强方法,其特征在于,包括如下步骤:
步骤ss1:获得带噪语音的多个irm预测值的解的集合;
步骤ss2:将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪特征作为输入,预测最终的irm预测值集合
作为一种较佳的实施例,所述步骤ss1具体包括:在输入端,带噪语音在当前帧左右两边各扩d帧,即[xn-d,xn-d+1,…,xn,…,xn+d-1,xn+d],为获得对当前帧时频掩蔽的多个预测值,boosting-dnn语音增强模型,在输出端进行扩帧,目标变为[yn-d,yn-d+1,…,yn,…,yn+d-1,yn+d],在预测当前帧的时频掩蔽yn时,也预测邻域帧的时频掩蔽irm;对每一帧得到对当前帧时频掩蔽的2d+1个预测值,即从第n-d帧到第n+d帧的输出都能提供对第n帧时频掩蔽的估计;所述2d+1个irm预测值构成boosting-dnn语音增强模型对估计的解集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]。
作为一种较佳的实施例,所述将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪语音对数功率谱特征lps作为输入具体包括:将来自所述boosting-dnn语音增强模型输出的irm的解的集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]拼接带噪语音对数功率谱特征lps[xt-d,xt-d+1,…,xt,…,xt+d-1,xt+d]作为输入。
本发明还提出一种基于深度学习的语音增强系统,其特征在于,包括:
boosting-dnn语音增强模型,用于:获得噪声语音的多个irm预测值的解的集合;
ensemble-dnn集成语音增强模型,用于:将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪语音对数功率谱特征lps作为输入,预测最终的irm预测值集合
所述boosting-dnn语音增强模型的输入端接带噪语音,所述boosting-dnn语音增强模型的输出端拼接所述带噪语音的带噪特征后与所述ensemble-dnn集成语音增强模型的输入端通讯连接。
作为一种较佳的实施例,所述获得噪声语音的多个irm预测值的解的集合具体包括:在输入端,噪声语音在当前帧左右两边各扩d帧,即[xn-d,xn-d+1,…,xn,…,xn+d-1,xn+d],为获得对当前帧时频掩蔽的多个预测值,boosting-dnn语音增强模型,在输出端进行扩帧,目标变为[yn-d,yn-d+1,…,yn,…,yn+d-1,yn+d],在预测当前帧的时频掩蔽yn时,也预测邻域帧的时频掩蔽irm;对每一帧得到对当前帧时频掩蔽的2d+1个预测值,即从第n-d帧到第n+d帧的输出都能提供对第n帧时频掩蔽的估计;所述2d+1个irm预测值构成boosting-dnn语音增强模型对估计的解集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]。
作为一种较佳的实施例,所述将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪语音对数功率谱特征lps作为输入具体包括:将来自所述boosting-dnn语音增强模型输出的irm的解的集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]拼接带噪语音对数功率谱特征lps[xt-d,xt-d+1,…,xt,…,xt+d-1,xt+d]作为输入。
本发明所达到的有益效果:本发明针对如何解决复杂的噪声环境通常让语音的识别率显著下降,识别率的下降意味着这些设备无法准确理解用户的指令,导致大幅降低用户的体验的技术问题,通过设计一种基于深度学习的语音增强方法及系统,将boosting-dnn语音增强模型和ensemble-dnn集成语音增强模型这两个dnn串接起来的方式,有效的解决了一个神经网络由于层次太深训练不稳定的现象,构建一种非常深的网络结构,从实际的实验效果来看,也明显优于只采用一个神经网络的方法,彻底解决前端语音增强技术就可以确保把语音从带噪信号中分离出来,以便后端识别模型能正确识别语音的内容。
附图说明
图1是本发明的boosting-dnn语音增强模型的拓扑图。
图2是本发明的一种基于深度学习的语音增强方法的原理拓扑图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例1:如图1和图2所示,本发明提出一种基于深度学习的语音增强方法,其特征在于,包括如下步骤:
步骤ss1:获得带噪语音的多个irm预测值的解的集合;
步骤ss2:将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪特征作为输入,预测最终的irm预测值集合
作为一种较佳的实施例,所述步骤ss1具体包括:在输入端,带噪语音在当前帧左右两边各扩d帧,即[xn-d,xn-d+1,…,xn,…,xn+d-1,xn+d],为获得对当前帧时频掩蔽的多个预测值,boosting-dnn语音增强模型,在输出端进行扩帧,目标变为[yn-d,yn-d+1,…,yn,…,yn+d-1,yn+d],在预测当前帧的时频掩蔽yn时,也预测邻域帧的时频掩蔽irm;对每一帧得到对当前帧时频掩蔽的2d+1个预测值,即从第n-d帧到第n+d帧的输出都能提供对第n帧时频掩蔽的估计;所述2d+1个irm预测值构成boosting-dnn语音增强模型对估计的解集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]。
作为一种较佳的实施例,所述将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪语音对数功率谱特征lps作为输入具体包括:将来自所述boosting-dnn语音增强模型输出的irm的解的集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]拼接带噪语音对数功率谱特征lps[xt-d,xt-d+1,…,xt,…,xt+d-1,xt+d]作为输入。
实施例2:本发明还提出一种基于深度学习的语音增强系统,其特征在于,包括:
boosting-dnn语音增强模型,用于:获得噪声语音的多个irm预测值的解的集合;
ensemble-dnn集成语音增强模型,用于:将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪语音对数功率谱特征lps作为输入,预测最终的irm预测值集合
所述boosting-dnn语音增强模型的输入端接带噪语音,所述boosting-dnn语音增强模型的输出端拼接所述带噪语音的带噪特征后与所述ensemble-dnn集成语音增强模型的输入端通讯连接。
作为一种较佳的实施例,所述获得噪声语音的多个irm预测值的解的集合具体包括:在输入端,噪声语音在当前帧左右两边各扩d帧,即[xn-d,xn-d+1,…,xn,…,xn+d-1,xn+d],为获得对当前帧时频掩蔽的多个预测值,boosting-dnn语音增强模型,在输出端进行扩帧,目标变为[yn-d,yn-d+1,…,yn,…,yn+d-1,yn+d],在预测当前帧的时频掩蔽yn时,也预测邻域帧的时频掩蔽irm;对每一帧得到对当前帧时频掩蔽的2d+1个预测值,即从第n-d帧到第n+d帧的输出都能提供对第n帧时频掩蔽的估计;所述2d+1个irm预测值构成boosting-dnn语音增强模型对估计的解集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]。
作为一种较佳的实施例,所述将来自所述boosting-dnn语音增强模型输出的irm的解的集合拼接带噪语音对数功率谱特征lps作为输入具体包括:将来自所述boosting-dnn语音增强模型输出的irm的解的集合[yt-d,yt-d+1,…,yt,…,yt+d-1,yt+d]拼接带噪语音对数功率谱特征lps[xt-d,xt-d+1,…,xt,…,xt+d-1,xt+d]作为输入。
ensemble-dnn利用集成学习的理念,可以被看作干净语音的强预测器,它将许多较弱的回归函数(boosting-dnn的输出)组合成一个强的回归函数。
需要说明的是:两个dnn串接起来的方式,有效解决一个网络由于层次太深训练不稳定的现象,可以认为是一种非常深的网络结构;从实际的实验效果来看,也明显优于只采用一个神经网络的方法。
在神经网络训练过程中,dropout是一种训练深度神经网络时常用的算法,能有效地防止神经网络的过拟合、增强神经网络的泛化能力。当前对dropout的解释包括集成学习、正则化策略、朴素贝叶斯理论等等。我们合理地利用dropout策略,也可以一定程度上地提升语音增强模型的泛化能力。
目前常用的基于深度学习的语音增强算法主要从输入特征、优化目标、模型结构这三方面展开的。如基于深度神经网络(dnn)的语音增强算法,利用dnn建立噪声和干净语音之间的映射函数,采用全局均衡方差和噪声感知训练的方法来估计干净语音的对数功率谱。通过训练长短(longshort-termmemoryrecurrentneuralnetwork,lstmrnn)来估计带噪语音中的干净语音和噪声特征,最后通过掩蔽的方法将噪声部分从带噪频谱中去除掉的语音增强算法。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



