
 商标分类
商标分类  商标转让
商标转让 
上下文信息预测模型的训练方法及系统与流程
 2021-01-28 15:01:57|
2021-01-28 15:01:57| 401|
401| 起点商标网
起点商标网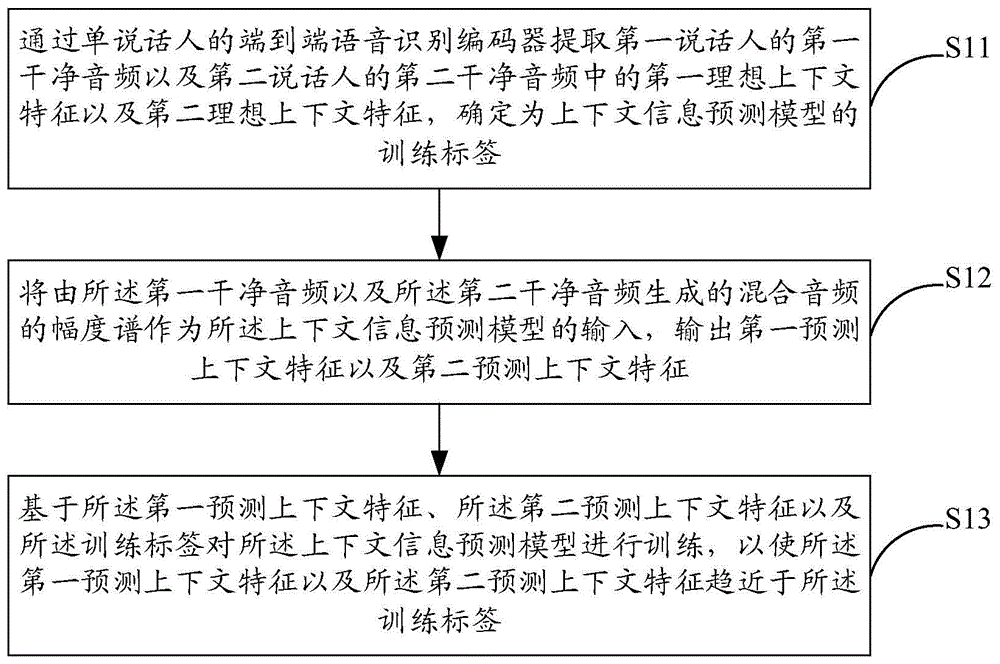
本发明涉及智能语音领域,尤其涉及一种上下文信息预测模型的训练方法及系统。
背景技术:
单声道语音分离是解决鸡尾酒会问题的基本任务。通常的语音分离包括:基于时频谱遮掩的深度学习语音分离系统、时域上直接进行分离的语音分离系统。
基于时频谱遮掩的深度学习语音分离系统在将时域信号通过短时傅里叶变换变换到时频域上,利用深度神经网络对幅度谱遮掩进行估计,然后计算分离的目标信号的幅度谱,得到估计出的声音信号。
在时域上的端到端语音分离。利用深度神经网络直接在时域上对语音信号进行分离。
在实现本发明过程中,发明人发现相关技术中至少存在如下问题:
在混合语音信号中,说话人的性别相同或声音听起来相似时,分离系统的性能会下降,没有考虑到人类的听觉机制进行建模。
技术实现要素:
为了至少解决现有技术中说话人的性别相同或声音听起来相似时,分离系统的性能会下降,并且没有考虑到听觉机制的问题。
第一方面,本发明实施例提供一种上下文信息预测模型的训练方法,包括:
通过单说话人的端到端语音识别编码器提取第一说话人的第一干净音频以及第二说话人的第二干净音频中的第一理想上下文特征以及第二理想上下文特征,确定为上下文信息预测模型的训练标签;
将由所述第一干净音频以及所述第二干净音频生成的混合音频的幅度谱作为所述上下文信息预测模型的输入,输出第一预测上下文特征以及第二预测上下文特征;
基于所述第一预测上下文特征、所述第二预测上下文特征以及所述训练标签对所述上下文信息预测模型进行训练,以使所述第一预测上下文特征以及所述第二预测上下文特征趋近于所述训练标签。
第二方面,本发明实施例提供一种基于上下文信息预测模型的语音分离方法,包括:
通过语音分离模型确定待分离语音的高维音频特征;
根据权利要求1或2所述的训练方法训练后的上下文信息预测模型确定所述待分离语音中第一说话人的第一预测上下文特征以及第二说话人的第二预测上下文特征;
通过转换网络对所述第一预测上下文特征以及所述第二预测上下文特征进行处理,将处理后的第一预测上下文特征以及所述第二预测上下文特征分别与所述高维音频特征进行拼接,确定第一分离语音特征以及第二分离语音特征;
基于所述第一分离语音特征以及第二分离语音特征确定出两个说话人的语音信息。
第三方面,本发明实施例提供一种上下文信息预测模型的训练系统,包括:
训练标签确定程序模块,用于通过单说话人的端到端语音识别编码器提取第一说话人的第一干净音频以及第二说话人的第二干净音频中的第一理想上下文特征以及第二理想上下文特征,确定为上下文信息预测模型的训练标签;
预测上下文特征确定程序模块,用于将由所述第一干净音频以及所述第二干净音频生成的混合音频的幅度谱作为所述上下文信息预测模型的输入,输出第一预测上下文特征以及第二预测上下文特征;
训练程序模块,用于基于所述第一预测上下文特征、所述第二预测上下文特征以及所述训练标签对所述上下文信息预测模型进行训练,以使所述第一预测上下文特征以及所述第二预测上下文特征趋近于所述训练标签。
第四方面,本发明实施例提供一种基于上下文信息预测模型的语音分离系统,包括:
高维音频特征确定程序模块,用于通过语音分离模型确定待分离语音的高维音频特征;
预测上下文特征确定程序模块,用于根据权利要求7所述的训练系统训练后的上下文信息预测模型确定所述待分离语音中第一说话人的第一预测上下文特征以及第二说话人的第二预测上下文特征;
分离语音特征确定程序模块,用于通过转换网络对所述第一预测上下文特征以及所述第二预测上下文特征进行处理,将处理后的第一预测上下文特征以及所述第二预测上下文特征分别与所述高维音频特征进行拼接,确定第一分离语音特征以及第二分离语音特征;
语音分离程序模块,用于基于所述第一分离语音特征以及第二分离语音特征确定出两个说话人的语音信息。
第五方面,提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的上下文信息预测模型的训练方法以及基于上下文信息预测模型的语音分离方法的步骤。
第六方面,本发明实施例提供一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现本发明任一实施例的上下文信息预测模型的训练方法以及基于上下文信息预测模型的语音分离方法的步骤。
本发明实施例的有益效果在于:受人类对语音分离的机制的理解和启发,提出了一种具有上下文语言理解的新型语音分离架构。首先设计上下文嵌入预测模型,以直接从混合语音中提取每个目标说话者的上下文语言信息。然后将提取的上下文嵌入合并到单声道语音分离系统中,以获得更好的性能。该方法在t-f掩蔽和时域体系结构上都得到了评估,并且在这两种情况下都可以观察到一致且显着的改进。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一实施例提供的一种上下文信息预测模型的训练方法的流程图;
图2是本发明一实施例提供的一种上下文信息预测模型的训练方法的上下文信息预测模型结构图;
图3是本发明一实施例提供的一种基于上下文信息预测模型的语音分离方法的流程图;
图4是本发明一实施例提供的一种基于上下文信息预测模型的语音分离方法的上下文信息融入不同的语音分离模型结构图;
图5是本发明一实施例提供的一种基于上下文信息预测模型的语音分离方法的关于t-f掩蔽结构的结果数据图;
图6是本发明一实施例提供的一种基于上下文信息预测模型的语音分离方法的时域网络结构的结果数据图;
图7是本发明一实施例提供的一种上下文信息预测模型的训练系统的结构示意图;
图8是本发明一实施例提供的一种基于上下文信息预测模型的语音分离系统的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示为本发明一实施例提供的一种上下文信息预测模型的训练方法的流程图,包括如下步骤:
s11:通过单说话人的端到端语音识别编码器提取第一说话人的第一干净音频以及第二说话人的第二干净音频中的第一理想上下文特征以及第二理想上下文特征,确定为上下文信息预测模型的训练标签;
s12:将由所述第一干净音频以及所述第二干净音频生成的混合音频的幅度谱作为所述上下文信息预测模型的输入,输出第一预测上下文特征以及第二预测上下文特征;
s13:基于所述第一预测上下文特征、所述第二预测上下文特征以及所述训练标签对所述上下文信息预测模型进行训练,以使所述第一预测上下文特征以及所述第二预测上下文特征趋近于所述训练标签。
在本实施方式中,在真实的鸡尾酒会场景中,为了从混合的声音中分辨目标说话人的声音,人们不但会仔细听取声音,同时也会尝试着去理解目标说话人正在谈论的内容。对人类听觉机制的研究发现,人类的大脑中有相关的神经中枢,可以根据语音的上下文信息对被噪声覆盖的声音进行还原。
对于步骤s11,直接从混合音频中获取出目标说话人的上下文信息比较困难。因此首先,考虑更简单的情况,使用端到端语音识别系统可以从干净的音频中提取出说话人的上下文信息,这种上下文信息称之为理想上下文信息。
图2展示了上下文信息预测模型的训练过程,从第一说话人的第一干净音频x1和第二说话人的第二干净音频x2的声学特征中,通过预训练好的端到端语音识别编码器,从而提取理想的第一上下文特征e1和第二上下文特征e2,其不黑用作上下文信息预测模型的训练标签。
所述上下文信息预测模型包括:混合编码器、说话人区分编码器以及上下文编码器。
对于步骤s12,在图2的右半部分是上下文信息预测模型,其接受由x1与x2生成的混合音频y的幅度谱|y|作为输入。在混合中,可以仅仅将x1与x2进行混合,也可以在混合中加入一些预设噪音,可以根据项目需求自行设定。
作为一种实施方式,在本实施例中,所述将由所述第一干净音频以及所述第二干净音频生成的混合音频的幅度谱作为所述上下文信息预测模型的输入包括:
将所述混合音频的幅度谱通过混合编码器处理后分别输入至两个不同的说话人区分编码器进行编码,生成第一编码以及第二编码;
通过共享参数的上下文编码器对所述第一编码以及第二编码进行编码,确定出第一说话人的第一预测上下文特征以及第二说话人第二预测上下文特征。
在本实施方式中,将幅度谱|y|经过一个混合编码器编码,再经由两个不同的说话人区分编码器编码,最后通过共享参数的上下文编码器进行编码,预测出目标说话人的上下文信息
对于步骤s13,基于步骤s12确定的第一预测上下文特征
其中,
通过该实施方式可以看出,在模型设计中,从混合的音频信号中理解各个目标说话人的上下文信息。即从混合的音频信号中直接理解各个目标说话人的上下文内容。从而为语音分离模型提供了说话人的上下文信息,提升语音分离性能。
如图3所示为本发明一实施例提供的一种基于上下文信息预测模型的语音分离方法的流程图,包括如下步骤:
s21:通过语音分离模型确定待分离语音的高维音频特征;
s22:根据权利要求1或2所述的训练方法训练后的上下文信息预测模型确定所述待分离语音中第一说话人的第一预测上下文特征以及第二说话人的第二预测上下文特征;
s23:通过转换网络对所述第一预测上下文特征以及所述第二预测上下文特征进行处理,将处理后的第一预测上下文特征以及所述第二预测上下文特征分别与所述高维音频特征进行拼接,确定第一分离语音特征以及第二分离语音特征;
s24:基于所述第一分离语音特征以及第二分离语音特征确定出两个说话人的语音信息。
在本实施方式中,在可以通过上下文信息预测模型获取到预测的上下文信息后,可以将上下文信息融入语音分离系统。图4展示了将上下文信息融入两个不同语音分离系统的过程。
对于步骤s21,首先确定待分离的语音,将待分离语音输入至语音分离模型中,确定出待分离语音的高维音频特征。语音分离模型包括:时频域模型或时域模型。时频域模型包括:基于深度残差网络的基线系统、基于双向长短时记忆的基线系统。
对于步骤s22,通过训练好的上下文信息预测模型确定所述待分离语音中第一说话人的预测上下文特征
对于步骤s23,图4中/左边m1、masknet(遮掩预测网络)、sepnet(分离网络)等标注的部分为时频域模型中存在的部分,/右边m1、separator(分离器)、encoder(编码器)等标注的部分表示的时域模型中存在的部分。在这两种模型中,上下文信息融入的方式一致,使用转换网络(transformnet)对上下文信息进行了处理,然后和模型中的高维音频特征yr/w进行了拼接。
对于步骤s24,基于步骤s23确定的第一分离语音特征以及第二分离语音特征确定出两个说话人的语音信息。
通过该实施方式可以看出,通过设计模型从混合的音频信号中理解各个目标说话人的上下文信息。将提取的上下文信息融入语音分离系统,从而提高语音分离系统的性能。在时频域遮掩方法以及时域方法上都进行了上下文信息的融入,均取得了不错的性能提升。
对上述方法进行具体说明,
基于监督学习的单声道语音分离,考虑线性混合的单声道信号y(n),其中s个说话人同时讲话:
其中,xs(n),s=1,…s是来自每个说话人的单独的源信号。单声道语音分离的目标是从嘈杂的语音y(n)中估计每个说话者的
基于监督深度学习的t-f域掩蔽是语音分离中的常规方法,分离通常以三个步骤进行。首先,混合语音信号通过stft变换转换为t-f域。在t-f域中,混合信号可以写为:
其次,幅度谱由深度学习模型处理以预测每个说话者的t-f掩码
最后,估计的幅度
在基于深度学习的t-f掩码方法中,存在各种用于估计t-f掩码的深度学习模型。在本方法中,分别在双向长短期记忆(blstm,bidirectionallongshort-termmemory)和深度残差网络(resnet,residualnetwork)上进行了实验。对于掩模功能,以前的工作已经比较了不同的掩模变体,本方法选择了相敏掩模(psm),因为它表现出更好的性能。
tasnet是最近被提出来直接在时域中分离目标语音。在tasnet中,stft/istft模块被基于神经网络的编码器/解码器结构代替。tasnet的分离过程可以表述为:
w=encoder(y)
[m1,…,ms]=separator(w)
其中y={y(i),...,y(i+c)}是混合语音y(n)的一个块,c是块大小。混合语音y被编码器网络编码为高级音频表示。然后,分离器网络为每个说话人预测高级掩码m1,...,ms。掩码ms逐元素乘以高级音频表示w。最后,解码器网络为时域中的每个说话人重建估计的音频块
与t-f屏蔽方法相比,时域方法具有许多优势。它可以直接在时域中预测声音波形,因此可以避免t-f域中的相位预测问题。另外,由于网络输出波形,因此语音分离中的评估指标,例如源失真比(sdr)和比例不变源噪比(si-snr)可以是直接用作训练目标。tasnet在提出时,其性能优于当时所有的t-f域方法。在我们的方法中,还将提出的上下文理解方法整合到tasnet中,以证明本方法的有效性。
置换不变训练,在监督训练过程中,分离模型同时为每个目标说话者输出s个预测语音流,同时输入相同的混合语音。对于每个预测语音,相应的参考语音是事先未知的。为了解决这个标签模糊性问题,提出了置换不变训练(pit)方法。在pit方法中,使用了预测语音和参考语音的最佳排列:
其中p表示{1,…,s}上所有置换的集合。π(s)是置换π的第s个元素。l是网络输出o的损失函数和参考标号r。那么,优化对象可以定义为:
在本文中,对于t-f方法,
对于时域方法,
语音分离中的上下文语境理解,直接从混合语音中提取每个说话者的上下文信息并不是一项简单的任务。另一方面,已经存在从干净的语音中提取语言知识的方法。在基于注意力的单说话人端到端自动语音识别(e2easr,end-to-endautomaticspeechrecognition)中,编码器被认为是对来自输入声学特征的上下文信息进行编码。
通过利用单说话人端到端语音识别模型,提出了一种基于混合语音的上下文学习方法,以实现多方上下文嵌入。如图2所示,训练好的单说话人e2e-asr编码器用于从说话人语音xs中提取数据上下文嵌入es。上下文嵌入被用作上下文嵌入预测模型中的标签。为了确保所提出的上下文嵌入预测模型具有对上下文的长期依赖性进行建模的能力,在构建模型时会参考多方对话e2e-asr模型。它包括三个阶段:
h=encodermin(|y|)
首先,混合幅度谱|y|由混合编码器encodermix处理。它将输入的混合信号编码为中间表示形式h。其次,中间表示形式h然后由s个单独的说话人区分(sd)编码器,编码器进行处理。输出gs(s=1,···s)是与每个讲话者的语音相对应的高级表示。最后,高级表示gs由共享权重上下文编码器编码,encoderctx用于预测每个说话者的上下文语言嵌入
其中,
然后将上下文语言嵌入合并到语音分离框架中。上下文嵌入es和预测上下文嵌入
图4说明了如何将上下文语言嵌入合并到t-f屏蔽方法和时域方法(tasnet)中。在这两个框架中,上下文嵌入
在t-f掩蔽方法(图4中,/左边标记)中,首先通过分离网络(sepnet)处理混合幅度,以获得高级音频表示yr。sepnet是blstm或resnet。然后,将音频表示yr与上下文表示
在时域方法中(图4中,/右边标记),还通过合并上下文嵌入来扩展tasnet。该过程类似于t-f掩蔽方法中的过程。首先,通过作为一维卷积神经网络(cnn)的编码器将混合语音块y编码为音频表示w。将上下文表示
对上述方法进行试验,实验全部在《华尔街日报》(wsj)语料库上进行。原始的80小时wsj数据集用于训练单说话人e2e-asr模型,该模型用于生成上下文信息嵌入。e2e-asr模型的编码器由4层类似于vgg(vgg卷积网络是一个比较有名的牛津大学vgg组提出的神经网络结构,这里使用了类似的结构的网络。所以称为vgg-like)的cnn和5层带有投影的双向长短时记忆元神经网络(blstmp)组成。在blstmp中,每层包含512个单元。培训过程遵循espnet工具包中的wsj标准流程。e2e-asr模型的输入是80维对数梅尔滤波器组系数以及3维音高特征。使用单说话人e2e-asr编码器提取的理想上下文信息表示为512维。
在语音分离任务中,使用wsj0-2mix语料库。它来自wsj0语料库。wsj0-2mix包含30小时训练集,10小时验证集和5小时测试集。每个样本都包含两个不同说话人的语音混合,其中一个说话人相对于另一个说话人的信噪比(snr)在[-5,-5]db之间均匀选择。音频的采样频率为8khz。在t-f掩膜方法中,stft的窗口长度为40ms,而移码为10ms。stft光谱的每个帧均为161维。在时域方法中,音频在训练时全部被裁剪为固定长度的4s。在推理期间,整个音频将由tasnet直接处理。
在图2所示的上下文嵌入预测模型中,混合编码器是4层类似于vgg的cnn。sd编码器是单独的2层blstm,每层中有512个隐藏单元。上下文编码器是1层blstm,每层中有512个隐藏单元。上下文嵌入预测模型中blstm的退出率设置为0.5。
在t-f掩膜模型中(图4),transformnet是一个5层1-dresnet,每层具有512个通道。我们采用两种模型来实现sepnet。第一个是10层一维resnet,其中每个层具有1024个一维卷积通道。sepnet的另一种实现是2层blstm。blstm的每一层包含512个单位,dropout(随机丢弃率)为0.5。masknet是单独的5层resnet,其卷积通道数为512。masknets之后的投影层将输出投影到161维,与幅度谱相同。
实现非因果的完全卷积tasnet(conv-tasnet)作为本方法的时域基线模型。卷积块中的通道数为512,瓶颈通道数为256。卷积堆栈的重复数为3,每个重复包含5个卷积块。当合并上下文信息时,上下文嵌入首先由transformnet处理,它是一个5层512通道1-dresnet。transformnet还可以在时间范围内对上下文嵌入进行上采样,使其长度与高级表示w的长度相同。
信噪比(sdr),短时目标清晰度(stoi)和语音质量得分的感知评估(pesq)被用作实验中的评估指标。sdr是一种信号级别指标,用于量化信号增强和干扰减少的程度。stoi和pesq是感知级别的指标,分别评估语音的清晰度和语音质量。
所提出的方法在t-f掩蔽架构上的评估,首先在t-f掩蔽架构上评估了所提出的上下文理解方法。resnet和blstm相对基准是通过pit建立的。如图5所示,blstm模型是一个相对较强的基线,并且也可以与以前的工作中的系统进行比较。为了评估所提出方法的上限,将使用单说话人语音从单说话人asr编码器中提取的上下文信息嵌入合并到语音分离模型中。如图5所示,通过在训练和评估中引入上下文信息嵌入,可以在基于blstm的t-f掩蔽系统中观察到sdr的相对改善约36%。由于上下文信息嵌入实际上在实际评估中不可用,因此更改为在评估中使用预测的上下文嵌入。图5比较并列出了培训和测试中不同的上下文嵌入用法。结果表明,在实际测试中直接使用来自混合语音的预测上下文嵌入仍然可以获得很大的改进,并且在训练阶段同时使用预测上下文信息嵌入可以获得最佳的系统性能。
在tasnet体系结构上进一步评估了该新方法,该体系结构是当前语音分离的最新体系结构,其结果如图6所示。使用tasnet进行与图5类似的实验。可以看出,在这种更强大的体系结构中,使用新提出的方法还可以获得一致的改进和相同的结论。最好的系统可以在基本tasnet上获得10%的sdr改进。
在方法中,受人类对语音分离的机制的理解和启发,提出了一种具有上下文语言理解的新型语音分离架构。首先设计上下文嵌入预测模型,以直接从混合语音中提取每个目标说话者的上下文语言信息。然后将提取的上下文嵌入合并到单声道语音分离系统中,以获得更好的性能。该方法在t-f掩蔽和时域tasnet体系结构上都得到了评估,并且在这两种情况下都可以观察到一致且显着的改进。将来,将探索其他情境学习方法进行语音分离,并开发更好的上下文知识整合方法。
如图7所示为本发明一实施例提供的一种上下文信息预测模型的训练系统的结构示意图,该系统可执行上述任意实施例所述的上下文信息预测模型的训练方法,并配置在终端中。
本实施例提供的一种上下文信息预测模型的训练系统包括:训练标签确定程序模块11,预测上下文特征确定程序模块12和训练程序模块13。
其中,训练标签确定程序模块11用于通过单说话人的端到端语音识别编码器提取第一说话人的第一干净音频以及第二说话人的第二干净音频中的第一理想上下文特征以及第二理想上下文特征,确定为上下文信息预测模型的训练标签;预测上下文特征确定程序模块12用于将由所述第一干净音频以及所述第二干净音频生成的混合音频的幅度谱作为所述上下文信息预测模型的输入,输出第一预测上下文特征以及第二预测上下文特征;训练程序模块13用于基于所述第一预测上下文特征、所述第二预测上下文特征以及所述训练标签对所述上下文信息预测模型进行训练,以使所述第一预测上下文特征以及所述第二预测上下文特征趋近于所述训练标签。
本发明实施例还提供了一种非易失性计算机存储介质,计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的上下文信息预测模型的训练方法;
作为一种实施方式,本发明的非易失性计算机存储介质存储有计算机可执行指令,计算机可执行指令设置为:
通过单说话人的端到端语音识别编码器提取第一说话人的第一干净音频以及第二说话人的第二干净音频中的第一理想上下文特征以及第二理想上下文特征,确定为上下文信息预测模型的训练标签;
将由所述第一干净音频以及所述第二干净音频生成的混合音频的幅度谱作为所述上下文信息预测模型的输入,输出第一预测上下文特征以及第二预测上下文特征;
基于所述第一预测上下文特征、所述第二预测上下文特征以及所述训练标签对所述上下文信息预测模型进行训练,以使所述第一预测上下文特征以及所述第二预测上下文特征趋近于所述训练标签。
如图8所示为本发明一实施例提供的一种基于上下文信息预测模型的语音分离系统的结构示意图,该系统可执行上述任意实施例所述的基于上下文信息预测模型的语音分离方法,并配置在终端中。
本实施例提供的一种上下文信息预测模型的训练系统包括:高维音频特征确定程序模块21,预测上下文特征确定程序模块22,分离语音特征确定程序模块23和语音分离程序模块24。
其中,高维音频特征确定程序模块21用于通过语音分离模型确定待分离语音的高维音频特征;预测上下文特征确定程序模块22用于根据权利要求7所述的训练系统训练后的上下文信息预测模型确定所述待分离语音中第一说话人的第一预测上下文特征以及第二说话人的第二预测上下文特征;分离语音特征确定程序模块23用于通过转换网络对所述第一预测上下文特征以及所述第二预测上下文特征进行处理,将处理后的第一预测上下文特征以及所述第二预测上下文特征分别与所述高维音频特征进行拼接,确定第一分离语音特征以及第二分离语音特征;语音分离程序模块24用于基于所述第一分离语音特征以及第二分离语音特征确定出两个说话人的语音信息。
本发明实施例还提供了一种非易失性计算机存储介质,计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的基于上下文信息预测模型的语音分离方法;
作为一种实施方式,本发明的非易失性计算机存储介质存储有计算机可执行指令,计算机可执行指令设置为:
通过语音分离模型确定待分离语音的高维音频特征;
根据权利要求1或2所述的训练方法训练后的上下文信息预测模型确定所述待分离语音中第一说话人的第一预测上下文特征以及第二说话人的第二预测上下文特征;
通过转换网络对所述第一预测上下文特征以及所述第二预测上下文特征进行处理,将处理后的第一预测上下文特征以及所述第二预测上下文特征分别与所述高维音频特征进行拼接,确定第一分离语音特征以及第二分离语音特征;
基于所述第一分离语音特征以及第二分离语音特征确定出两个说话人的语音信息。
作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本发明实施例中的方法对应的程序指令/模块。一个或者多个程序指令存储在非易失性计算机可读存储介质中,当被处理器执行时,执行上述任意方法实施例中的上下文信息预测模型的训练方法。
非易失性计算机可读存储介质可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据装置的使用所创建的数据等。此外,非易失性计算机可读存储介质可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,非易失性计算机可读存储介质可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
本发明实施例还提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的上下文信息预测模型的训练方法的步骤。
本申请实施例的客户端以多种形式存在,包括但不限于:
(1)移动通信设备:这类设备的特点是具备移动通信功能,并且以提供话音、数据通信为主要目标。这类终端包括:智能手机、多媒体手机、功能性手机,以及低端手机等。
(2)超移动个人计算机设备:这类设备属于个人计算机的范畴,有计算和处理功能,一般也具备移动上网特性。这类终端包括:pda、mid和umpc设备等,例如平板电脑。
(3)便携式娱乐设备:这类设备可以显示和播放多媒体内容。该类设备包括:音频、视频播放器,掌上游戏机,电子书,以及智能玩具和便携式车载导航设备。
(4)其他具有数据处理功能的电子装置。
在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”,不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



