
 商标分类
商标分类  商标转让
商标转让 
基于对数似然值归一化的说话人确认方法与流程
 2021-01-28 15:01:25|
2021-01-28 15:01:25| 315|
315| 起点商标网
起点商标网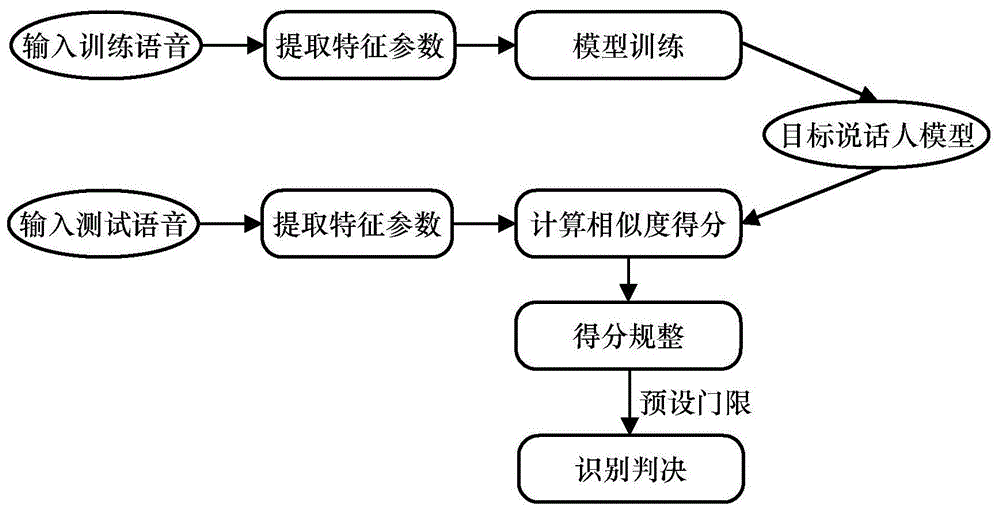
本发明涉及说话人识别技术领域,具体涉及一种基于对数似然值归一化的说话人确认方法。
背景技术:
说话人确认是判断测试语音是否属于某个预先声明的说话人,即需要将测试识别对(由测试语音和其声明的说话人身份构成)作出“true”或“false”的二类判决。但是“true”和“false”两类识别对的得分会出现严重的交叉和混叠;在这种情况下使用统一的门限对每一个识别对作“true”或“false”的判决,会严重影响说话人确认系统的性能。因此,需要在识别对原始得分的基础上进行得分规整。
目前最常用也是最典型的得分规整方法有零规整(zeronormalization,znorm)、测试规整(testnormalization,tnorm)以及两者的结合算法ztnorm等,它们通过估计“false”识别对的得分分布,对测试识别对的得分进行规整,将“false”识别对的得分规整为均值为0、方差为1的分布,从而消除不同说话人模型间的差异或不同测试语音之间的差异,有效减小两类识别对得分汇集后的混叠部分,从而提高说话人确认的系统性能。一般来说,得分规整不受限于系统所使用的说话人模型建立方法,无论是简单基础的高斯混合模型-通用背景模型(gaussianmixturemodel-universalbackgroundmodel,gmm-ubm),还是目前比较主流的联合因子分析(jointfactoranalysis,jfa)、总变化因子分析(totalvariabilityfactoranalysis)技术等,原始测试得分均需要进行得分规整,而现有的得分规整方法也都适用于基于以上不同说话人模型的确认系统。
现有的得分规整方法中,大多数都是通过规整“false”识别对得分分布的方式,以减小两类识别对得分汇集后的重叠部分,却没有有效扩大同一说话人模型或同一测试语音对应的两类识别对得分之间的差距;并且,在这些得分规整方法中,都需要预先收集和选取大量的非目标说话人语音数据来估计“false”识别对得分的均值和方差,而非目标说话人语音数据选取的好坏会影响最终得分规整的效果。
技术实现要素:
针对现有得分规整方法的以上不足,本发明提出一种对数似然值归一化得分规整算法(log-likelihoodnormalization,lln),通过扩大同一测试语音在目标说话人模型与非目标说话人模型上的得分差距,使同一测试语音对应的两类识别对得分混叠现象得到有效改善;与znorm、tnorm和ztnorm等方法相结合,可同时从不同角度解决两类识别对得分汇集后的混叠问题,从而进一步提高系统识别性能。
具体技术方案为:
基于对数似然值归一化的说话人确认方法,包括以下步骤:
假设
式中,si表示该测试语音在第i个说话人模型上的原始得分,si′是经过规整后的得分,
(1)如果i=t,则si较大,规整量ni因不包含st,故数值较小;
(2)如果i≠t,则si较小,规整量ni因包含st,故数值较大。
公式(3)中每个得分si作为e的指数是考虑目标说话人模型得分的独特性(较大且数目少),充分扩大其得分的影响,求和是利用非目标说话人模型得分的共同特点(较小且数目多),减少单个得分的影响,取对数可避免非目标说话人模型得分的规整量差距过大。
经过(3)式规整,测试语音对目标说话人模型和非目标说话人模型得分差距会进一步拉大,即可以使识别对中“true”识别对和“false”识别对的得分具有更好的区分性,从而更容易设定门限区分“true”识别对和“false”识别对,提升了系统确认性能。
本发明的方法相对于znorm、tnorm和ztnorm的优势在于扩大了同一测试语音在目标说话人模型与非目标说话人模型上的得分差距,使同一测试语音对应的两类识别对得分混叠现象得到有效改善;并且可以直接对测试得分进行规整,不需要引入先验知识,因此不需要预留训练数据。
附图说明
图1为实施例说话人确认系统;
图2为实施例测试语音在不同说话人模型上得分;
图3(a)lln规整前识别对得分分布曲线;
图3(b)lln规整后识别对得分分布曲线。
具体实施方式
结合实施例说明本发明的具体技术方案。
本实施例采用的说话人确认系统如图1所示,主要分为三部分:提取特征、建立模型和打分判决。
本实施例采用的说话人确认系统的评价指标:
在说话人确认系统中,每一次测试,就是将一组识别对进行“true”和“false”判决的过程。当本是“false”的识别对判决为“true”(非目标说话人被接受)时,称之为“虚警”(falsealarm);当本是“true”的识别对判决为“false”(目标说话人被拒绝)时,称之为“漏检”(miss),这两种错判出现的概率分别称为虚警率和漏检率。
(1)等错率(equalerrorrate,eer)
实际应用中,应同时降低虚警率和漏检率,然而这两种错误概率相互约束,随着判决门限设定的不同,两者呈相反趋势变化,只有当虚警率和漏检率大致相等的时候,系统的性能被认为达到了最大发挥,此时的错误率称为等错率(eer)。
(2)最小检测代价(minimumvalueofdetectioncostfunction,mindcf)
不同的应用场景对虚警率和漏检率要求不一样,系统门限的设定会按需调整,为了对不同情况下系统性能进行更加贴切地描述,引入了检测代价函数(detectioncostfunction,dcf)的概念,其数学表达式为:
式中cm和cfa分别是漏检率pm|t和虚警率pfa|nt对应的代价,pt是测试中应该判决为“true”的识别对出现的概率,(1-pt)是应该判决为“false”的识别对出现的概率。检测代价函数是描述识别错误发生后损失大小的一个函数,可以很好地表示系统的性能。设定门限可以得到该门限对应的dcf值,遍历判决门限,获得最小检测代价(mindcf),这是目前美国国家标准技术研究院说话人识别评测(nistsre)中最重要的指标。
对比例
采用现有技术的零规整(znorm)和测试规整(tnorm):
znorm方法是用大量非目标说话人语音对目标说话人模型打分,计算出对应于目标说话人模型λ的辅助参数均值μλ和方差σλ,用来规整得分分布的差异,其得分规整公式如下:
式中sλ是测试语音对模型λ的原始得分,
tnorm是用测试语音对大量非目标说话人模型计算得分,得到对应于测试语音的辅助参数,同样是均值和方差,用来减少测试语音环境不同对得分分布的影响,最终得分公式同(2)。
对于说话人确认系统,znorm参数计算在模型训练阶段完成,tnorm参数计算在测试阶段完成。ztnorm是在得分域将训练模型和测试语音的信息结合起来,即将znorm和tnorm相结合的得分规整方法。上述三种得分规整方法的不足之处是没有有效扩大同一说话人模型或同一测试语音对应的两类识别对得分之间的差距;并且必须引入先验知识,需要将训练数据中的一小部分预留出来作为开发集,用来估计得分规整时需要的参数,而开发集选取的好坏会影响最终得分规整的效果。
实施例
采用本发明的对数似然值归一化(log-likelihoodnormalization,lln):
假设
式中,si表示该测试语音在第i个说话人模型上的原始得分,si′是经过规整后的得分,
实验验证:
本发明实验在nistsre2008核心测试集(short2-short3)的电话训练、电话测试(tel-tel)情况下开展。实验主要针对女声测试集,该测试情况下共23385个测试对,涉及1674个测试语音和1140个目标说话人模型,在lln得分规整阶段,每个识别对得分都是基于测试语音数据与全部1140个说话人模型的匹配得分经公式(3)得到。
本实验中所使用的特征为36维的梅尔频率倒谱系数(melfrequencycepstralcoefficents,mfcc)特征,其每帧特征由18维的基本倒谱系数及其一次差分(delta)构成。首先用音素解码器来对语音数据进行语音活动性检测(voiceactivitydetection,vad),以去除数据中的静音部分,然后根据25ms的窗长和10ms的窗移提取36维的mfcc特征。由于得分规整方法具有普适性,不受限于系统所使用的说话人建模方法,且目前主流的说话人建模技术大多基于gmm-ubm模型,因此,本实验的说话人建模方法选用简单基础的gmm-ubm。使用nistsre20041side的目标说话人训练数据训练与性别相关的ubm,ubm高斯数为1023。并利用本征信道(eigenchannel)技术在模型域做了信道补偿,训练eigenchannel信道空间的数据,选择的是nistsre2004、2005以及2006的电话语音数据,包含755个说话人的数据,共9855个语音文件。另外,从nistsre2006的数据中挑选了340条数据用于tnorm得分规整和340条数据用于znorm得分规整,基本上保证这两个小数据集每个说话人只有一条语音数据。
表1比较了znorm、tnorm、ztnorm和lln不同得分规整方法的实验结果。从表1可以看出,lln在不需要开发集的条件下,具有良好的规整性能,相比无得分规整的情况,eer相对提升9.7%,mindcf相对提升4.57%,本身的规整性能可以和znorm、tnorm相当。
表1nistsre2008测试集上znorm、tnorm和lln性能比较
表2是在znorm、tnorm和ztnorm基础上做lln规整的实验结果。结合表1和表2中的实验结果可以看出,lln可以大幅度提升原有说话人确认系统的性能。在znorm基础上做lln和不做lln相比,系统的eer和mindcf分别有20.45%和24.44%的性能提升;在tnorm基础上做lln和不做lln相比,系统的eer和mindcf分别有5.59%和9.98%的性能提升;在ztnorm基础上做lln和不做lln相比,系统的eer和mindcf分别有11.7%和18.69%的性能提升。
表2nistsre2008测试集上做lln的性能
图2对比了lln规整前后某测试语音在15个说话人模型上的得分变化。其中,spk13为该测试语音的目标说话人,其余为非目标说话人。从图中可以看出经lln规整后,测试语音对目标说话人模型和非目标说话人模型得分差距会进一步拉大。如果门限保持不变,相比lln规整前,系统的虚警率会明显降低。
随机选取500个“true”识别对和500个“false”识别对,比较lln规整前后的得分分布,如图3(a)和图3(b)所示。从图中可以看出经lln规整后,“false”识别对的得分分布明显向左偏移,而“true”识别对的得分分布变化不明显,“true”识别对和“false”识别对的得分差距拉大,区分性增强,有效降低了虚警率,因此用统一的门限进行判决时会更有优势。lln虽然不会改变同一测试语音在每个目标说话人上得分的排序,但可以有效降低eer和mindcf。
结果表明,本发明提出基于对数似然值归一化(lln)的得分规整方法,对测试得分进行了有效的规整,与已有的znorm、tnorm和ztnorm得分规整方法能够很好互补,使说话人确认系统的性能进一步提高。在下一步工作中,将在其它说话人确认系统上验证lln得分规整方法的有效性。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



