
 商标分类
商标分类  商标转让
商标转让 
一种带情感和韵律的语音转换方法及装置与流程
 2021-01-28 15:01:11|
2021-01-28 15:01:11| 251|
251| 起点商标网
起点商标网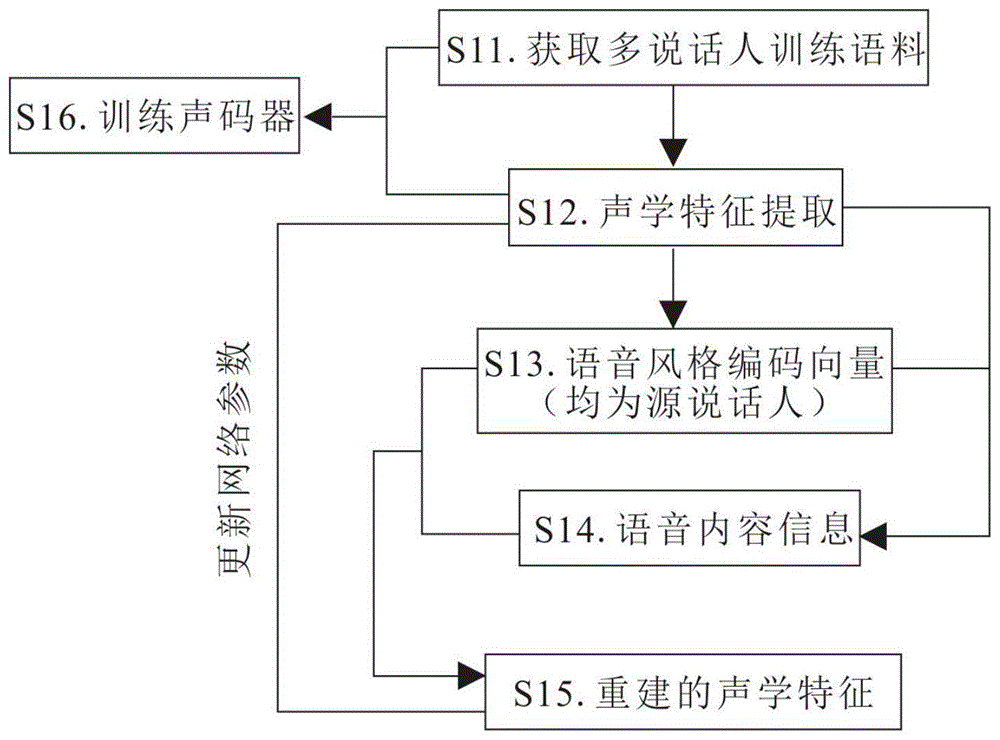
本发明涉及语音处理技术领域,具体的说,是一种带情感和韵律的语音转换方法及装置。
背景技术:
语音转换(voiceconversion)是一种保留源说话人语音的内容信息,并转换为目标说话人的声音的语音技术。该技术有着广泛的应用场景,如用户可以把自己的声音转换为自己喜欢的明星的声音,再如动漫迷们津津乐道的“变声蝴蝶结”,此外,语音转换技术的发展对与个性化语音合成、声纹识别、声纹安全等领域具有重要意义。
现有的语音转换方法从并行训练数据发展到非并行训练数据、一对多变换发展到多对多变换,有几种实现途径:一种是采用一定方法将非平行语料进行语音特征和参数对齐,然后训练模型,得到语音转换函数,该方法的语料对齐工作较为繁杂,语音转换效果较为有限;一种是对待转换语音数据进行语音识别得到识别文本,再利用目标说话人的语音合成模型进行语音合成,该种方法需要依赖语音识别以及个性化语音合成的发展;还有一种是直接对语音进行转换,从源说话人和目标说话人的训练语音信号中分别提取基频特征、说话人特征和内容特征,构建转换函数,但该种方法特征提取工程较为繁杂,并且合成的语音自然度较低。
技术实现要素:
本发明提供了一种带情感和韵律的语音转换方法及装置,用于解决上述问题。
本发明采用的技术方案是:提供一种带情感和韵律的语音转换方法,其特征在于,包括训练阶段和转换阶段,所述训练阶段包括以下步骤:
s11:获取多名说话人的训练语料,包含源说话人以及目标说话人;
s12:将获取的训练语料进行声学特征提取;
s13:确定风格编码层的token数量及维度,将步骤s12提取的声学特征输入到使用了注意力机制的风格编码层,得到风格编码向量;
s14:将步骤s12提取的声学特征、步骤s13得到的风格编码向量共同输入到内容编码器,以过滤语音的说话者信息,输出语音内容编码信息;
s15:将步骤s14输出的语音内容编码信息、步骤s13得到的风格编码向量共同输入到解码器,得到重建后的源说话人的声学特征,以训练网络参数;
s16:将步骤s12提取的声学特征输入到声码器网络,训练声码器模型;
在所述训练阶段,提取的语音内容编码信息、风格编码向量为同一说话人的语音内容编码信息与风格编码向量;
将训练阶段训练后的网络参数用于语音转换阶段,所述转换阶段包括以下步骤:
s21:将待转换的源说话人、目标说话人语料进行声学特征提取;
s22:将待转换的源说话人、目标说话人语料的声学特征输入到风格编码层网络,得到源说话人、目标说话人的风格编码向量;
s23:将步骤s22得到的源说话人风格编码向量、步骤s21提取的待转换源说话人语料的声学特征输入到内容编码器、以过滤语音的说话者信息,输出语音内容编码信息;
s24:将步骤s23输出的语音内容编码信息、步骤s22得到的风格编码向量共同输入到解码器,得到目标说话人的声学特征;
s25:将步骤s24得到的经转换后的声学特征输入到经过s16训练后的声码器模型中,经声码器模型转换为音频;
在所述转换阶段,提取的语音内容编码信息、风格编码向量为不同说话人的语音内容编码信息与风格编码向量。
优选地,步骤s13中的token还包括:
每个token是由正态分布随机生成,token的数量以及每一个token的维度根据训练数据设定。
优选地,步骤s13中风格编码层网络结构包括:
参照编码层,用于对输入的声学特征生成参照编码向量;
风格标记层,利用注意力机制将不同的token与参照编码向量进行计算得到风格编码向量。
优选地,步骤s13中生成风格编码向量的过程包括:
将token以及参照编码向量一同输入到多头注意力网络,计算token与参照编码向量的相似度,利用计算所得的相似度得分再对token进行加权求和,最后计算得到风格编码向量;
所述注意力机制为dot-productattention、local-basedattention或混合注意力机制。
优选地,步骤s14中内容编码器网络结构包括:
瓶颈层,包括使用双向lstm或gru网络,其输出分别经过下采样、上采样,最后输出语音内容编码信息。
优选地,步骤s14中内容编码器采用内容损失函数,所述内容损失函数为:
其中,
优选地,步骤s15中解码器采用重建损失函数,所述重建损失函数为:
其中,x表示原始输入的声学特征,
优选地,步骤s16的声码器模型还包括:
声码器采用的网络结构为wavnet、wavrnn或melgan。
优选地,所述声学特征为梅尔频谱特征或线性频谱特征。
一种带情感和韵律的语音转换装置,其特征在于,包括:
声学特征提取模块,用于对输入语音提取声学特征;
风格编码生成模块,用于对输入的声学特征生成风格编码向量;
内容编码器模块,用于对输入的风格编码向量、语音声学特征输出语音内容编码信息;
解码器模块,用于对输入的风格编码向量、语音内容信息输出经转换后的声学特征;
声码器模块,用于将声学特征转换为音频。
本发明的有益效果是:本发明公开的带情感及韵律的语音转换方法及装置,使用带有注意力机制的风格编码层来计算说话人的风格编码向量,将风格编码向量与说话人语音声学特征一同输入带有bottleneck的自编码网络进行训练及转换,最后通过声码器将声学特征转换为音频。在传统语音转换方法的基础上,引入了说话人韵律、情感信息,使得转换的语音带有目标说话人语音的情感和韵律,该方法在多对多(manytomany)、集内对集内(seentoseen)、集内对集外(seentounseen)、集外对集外(unseentounseen)等说话人声音转换任务均有较高的相似度、较高的语音质量。
附图说明
图1为本发明实施例公开的带情感和韵律的语音转换方法的训练阶段流程示意图;
图2为本发明实施例公开的带情感和韵律的语音转换方法的转换阶段流程示意图;
图3为本发明实施例公开的参照编码层网络结构示意图;
图4为本发明实施例公开的风格标记层网络结构示意图;
图5为本发明实施例公开的内容信息编码网络结构示意图;
图6为本发明实施例公开的解码网络结构示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步详细描述,但本发明的实施方式不限于此。
实施例1:
为了便于理解,本实施例中,源说话人可以理解为自己,目标说话人可以理解为某个明星。本发明用于将自己的声音转化为某个明星的声音。
本实施例公开一种带情感和韵律的语音转换方法,包括训练阶段和转换阶段,如图1所示,在训练阶段包括以下步骤:
s11.获取多名说话人的训练语料,包含源说话人(sourcespeaker)以及目标说话人(targetspeaker);
可选的,现有一些质量较高的公共数据集可用来作为训练语料,如vctk、librispeech等,也可以采用自己录制的包含多说话人的语音数据。
s12.将获取的训练语料进行声学特征提取;
可选的,对训练语料提取梅尔频谱特征,具体的,参数选取如下:窗口大小为1024,步长为256,采样率为16000,梅尔维数80;并对频谱进行预加重、降噪、归一化、vad检测等系列处理,最后得到声学特征。
s13.确定风格编码层(styleencoderlayer)的token数量及维度,将步骤s12提取的声学特征输入到使用了注意力机制的风格编码层,得到风格编码向量(styleembedding)。
可选的,每个token是由正态分布随机生成,token的数量以及每一个token的维度根据训练数据设定。
可选的,风格编码层网络结构还包括:参照编码层,用于对输入的声学特征生成参照编码向量;风格标记层,利用注意力机制将不同的token与参照编码向量进行计算得到风格编码向量。
参照编码层网络结构结构如图2所示,由6层卷积核3×3、步长2×2的二维卷积堆叠而成,每层都使用了批归一化(batchnormalization)以及relu激活函数,最后通过256个单元的gru网络,得到256维参照编码向量;风格标记层网络结构如图3所示。
可选的,生成风格编码向量的过程包括:将token以及参照编码向量一同输入到多头注意力网络(multi-headattention),计算token与参照编码向量的相似度,利用计算所得的相似度对token进行加权求和,值得注意的是,所述注意力机制包括但不限于dot-productattention、local-basedattention或混合注意力机制。
具体的,以vctk训练数据为例,token数量选为128,每一个token的维度为256,将正态分布随机生成128个256维的token以及由参照编码层生成的参照编码向量一同输入到多头注意力网络,其中多头注意力网络的num_heads为8,计算token与参照编码向量的相似度得分,再用相似度得分对128个token进行加权求和得到256维的风格编码向量。
s14.将步骤s12提取的声学特征、步骤s13得到的风格编码向量共同输入到内容编码器(contentencoder),以过滤语音的说话者信息,输出语音内容编码信息;
所述说话者信息是指说话者的音色、音调,即情感和韵律。s14这一步的目的是为了将说话者语音的音色、音调和语音内容分离开,只保留语音内容进行编码。
可选的,内容编码器中的瓶颈层(bottlenecklayer),包括使用双向lstm或gru网络,其输出分别经过下采样、上采样,最后输出语音内容编码信息;
可选的,内容编码器采用的内容损失函数,所述内容损失函数为:
其中,
具体的,如图4所示,内容信息编码器的网络结构包括:3层5×1的一维卷积层,通道数为512,每层都使用批归一化(batchnormalization)与relu激活函数,卷积层的输出再通过两层的双向lstm,bottleneck为32,即lstm前向传播输出的维度等于后向传播输出的维度等于32,最后输出维度为64,最后再经过下采样与上采样得到语音内容编码信息。
s15.将步骤s14输出的语音内容信息、步骤s13得到的风格编码向量共同输入到解码器(decoder),得到重建后的源说话人的声学特征,以训练网络参数。
具体的,根据原始输入的源说话人的声学特征与重建后的源说话人的声学特征之间的拟合度训练网络参数。
可选的,解码器采用的重建损失函数,所述重建损失函数为:
其中,x表示原始输入的声学特征,
具体的,如图5所示,解码器网络结构为:3层5×1的一维卷积层,维度为512,3层lstm,隐层维度为1024,1×1的卷积层,维度为80,4层5×1的一维卷积层,维度为512,最后输入到5×1的卷积层,维度为80,得到梅尔频谱特征,其中卷积层间均使用批归一化以及relu激活函数。
s16.将步骤s12提取的声学特征输入到声码器网络,训练声码器模型。
可选的,声码器模型采用的网络结构为wavnet、wavrnn或melgan。
在训练阶段,提取的语音内容编码信息、风格编码向量为同一说话人(包括源说话人或目标说话人)的语音内容编码信息与风格编码向量。
步骤s16中的声码器模型用于将声学特征转化为音频,通过训练声码器模型,可将音频转化的更加自然。
将训练阶段训练后的网络参数用于语音转换阶段,在语音转换阶段包括以下步骤:
s21.将待转换的源说话人、目标说话人语料进行声学特征提取;
s22.将待转换的源说话人、目标说话人语料的声学特征输入到风格编码层网络,得到源说话人、目标说话人的风格编码向量;
s23.将步骤s22得到的源说话人的风格编码向量、步骤s21提取的源说话人语料的声学特征输入到内容编码器,以过滤语音的说话者信息,输出语音内容编码信息;
s24.将步骤s23输出的语音内容编码信息、步骤s22得到的目标说话人的风格编码向量共同输入到解码器(decoder),得到目标说话人的声学特征;
s25.将步骤s24得到的经转换后的声学特征输入到经过s16训练后的声码器模型中,经声码器模型转换为音频。
可理解的是,转换阶段方法与训练阶段类似,转换阶段的网络参数由训练阶段得到,并且保证网络结构一致,转换阶段的声学特征提取方法与训练阶段保持一致,其不同点在于转换阶段提取的内容编码信息、风格编码向量为不同说话人(内容编码向量为源说话人,风格编码向量为目标说话人)的内容编码信息与风格编码向量。
可理解的是,所述训练阶段以及转换阶段述声学特征为梅尔频谱特征或线性频谱特征。
通过本实施例1提供的带情感和韵律的语音转换方法,使用带有注意力机制的风格编码层来计算说话人的风格编码向量,将风格编码向量与说话人语音声学特征一同输入到带有瓶颈层的自编码网络进行训练及转换,最后通过声码器将声学特征转换为音频。在传统语音转换方法的基础上,引入了说话人韵律、情感信息,使得转换的语音带有目标说话人语音的情感和韵律。
实施例2
本发明实施例所述带情感和韵律的语音转换装置,包括:
声学特征提取模块,用于对输入语音提取声学特征。
可选的,所述声学特征为梅尔频谱特征或线性频谱特征。
风格编码生成模块,用于对输入的声学特征生成风格编码向量。
可选的,风格编码层的每个token是由正态分布随机生成,token的数量以及每一个token的维度根据训练数据设定。
可选的,风格编码层网络结构还包括:参照编码层,用于对输入的声学特征生成参照编码向量;风格标记层,利用注意力机制将不同的token与参照编码向量进行计算得到风格编码向量。
参照编码层网络结构结构如图2所示,由6层卷积核3×3、步长2×2的二维卷积堆叠而成,每层都使用了批归一化(batchnormalization)以及relu激活函数,最后通过256个单元的gru网络,得到256维参照编码向量;风格标记层网络结构如图3所示。
可选的,生成风格编码向量的过程包括:将token以及参照编码向量一同输入到多头注意力网络(multi-headattention),计算token与参照编码向量的相似度,利用计算所得的相似度对token进行加权求和,值得注意的是,所述注意力机制为dot-productattention、local-basedattention或混合注意力机制。
内容编码器模块,用于对输入的风格编码向量、语音声学特征输出语音内容编码信息。
可选的,内容编码器中的瓶颈层(bottlenecklayer),包括但不限于使用双向lstm或gru网络,其输出分别经过下采样、上采样,最后输出语音内容编码信息。
可选的,内容编码器采用的内容损失函数为:
其中,
内容信息编码器的网络结构如图4所示,包括:3层5×1的一维卷积层,通道数为512,每层都使用批归一化(batchnormalization)与relu激活函数,卷积层的输出再通过两层的双向lstm,bottleneck为32,即lstm前向传播输出的维度等于后向传播输出的维度等于32,最后输出维度为64,最后再经过下采样与上采样得到内容信息编码向量。
解码器模块,用于对输入的风格编码向量、语音内容信息输出经转换后的声学特征。
可选的,解码器采用的重建损失函数为:
其中,x表示原始输入的声学特征,
解码器网络结构如图5所示,包括:3层5×1的一维卷积层,维度为512,3层lstm,隐层维度为1024,1×1的卷积层,维度为80,4层5×1的一维卷积层,维度为512,最后输入到5×1的卷积层,维度为80,得到梅尔频谱特征,其中卷积层间均使用批归一化以及relu激活函数。
声码器模块,用于将声学特征转换为音频。
可选的,声码器采用的网络结构为wavnet、wavrnn或melgan。
通过本实施例2提供的带情感和韵律的语音转换装置,在多对多(manytomany)、集内对集内(seentoseen)、集内对集外(seentounseen)、集外对集外(unseentounseen)等说话人声音转换任务上均有较高的相似度、较高的语音质量。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



