
 商标分类
商标分类  商标转让
商标转让 
一种语音模型的训练方法、装置、服务器和存储介质与流程
 2021-01-28 15:01:01|
2021-01-28 15:01:01| 306|
306| 起点商标网
起点商标网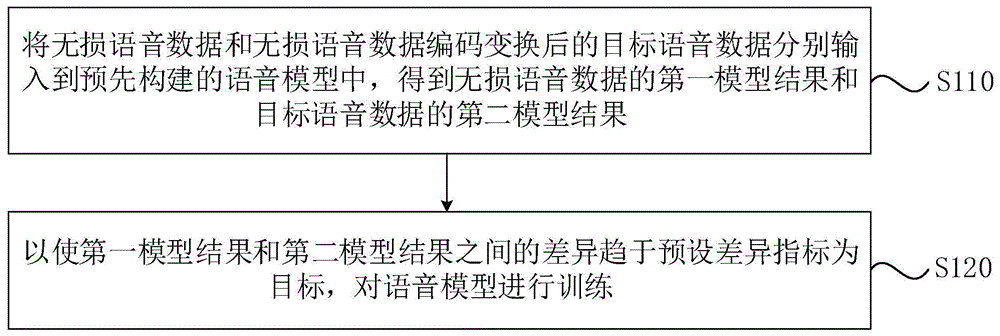
本发明实施例涉及音频处理技术领域,尤其涉及一种语音模型的训练方法、装置、服务器和存储介质。
背景技术:
随着互联网技术的快速发展,出现大量对语音数据进行识别处理的任务,例如语音识别、语音类场景识别或者声音事件检测等,此时通常会针对各个语音类任务,分别训练出相应的语音模型来预测该语音类任务的输出结果。
目前,通过会对大量语音采样数据进行相应的音频编码,作为语音模型的训练样本,然后采用交叉熵的损失函数对该语音模型进行训练,以使每一语音训练样本的输出结果在训练过程中不断接近该语音训练样本的样本标签;然而,同一音频数据源在不同编码方式或编码码率下进行编码压缩时,会丢失不同的音频内容,使得同一音频数据源在不同编码压缩后的音频数据之间会存在一定的差异,例如编码码率越低,编码压缩后的音频数据会丢失的越多,此类编码数据丢失对于语音模型的预测也会带来一定的影响,使得语音模型对于同一音频数据源在不同编码方式或编码码率下各编码音频的输出结果也存在一定的差异,影响到语音模型对各语音类任务的预测准确性。
技术实现要素:
本发明实施例提供了一种语音模型的训练方法、装置、服务器和存储介质,避免语音模型对相同语音源下不同语音数据输出的模型结果之间的差异,提高任一语音数据在语音模型下的预测准确性。
第一方面,本发明实施例提供了一种语音模型的训练方法,该方法包括:
将无损语音数据和所述无损语音数据编码变换后的目标语音数据分别输入到预先构建的语音模型中,得到所述无损语音数据的第一模型结果和所述目标语音数据的第二模型结果;
以使所述第一模型结果和所述第二模型结果之间的差异趋于预设差异指标为目标,对所述语音模型进行训练。
第二方面,本发明实施例提供了一种语音模型的训练装置,该装置包括:
语音数据输入模块,用于将无损语音数据和所述无损语音数据编码变换后的目标语音数据分别输入到预先构建的语音模型中,得到所述无损语音数据的第一模型结果和所述目标语音数据的第二模型结果;
语音模型训练模块,用于以使所述第一模型结果和所述第二模型结果之间的差异趋于预设差异指标为目标,对所述语音模型进行训练。
第三方面,本发明实施例提供了一种服务器,该服务器包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明任意实施例所述的语音模型的训练方法。
第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本发明任意实施例所述的语音模型的训练方法。
本发明实施例提供的一种语音模型的训练方法、装置、服务器和存储介质,将无损语音数据和该无损语音数据编码变换后的目标语音数据作为预先构建的语音模型的训练样本,此时无损语音数据和目标语音数据具有相同的语音源,在语音模型的训练过程中,不断将无损语音数据和目标语音数据分别输入到该语音模型中,以得到无损语音数据的第一模型结果和目标语音数据的第二模型结果,然后以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,对该语音模型进行训练,使得该语音模型能够对同一语音源下的无损语音数据和目标语音数据输出相近的模型结果,避免语音模型对同一语音源下不同语音数据输出的模型结果之间存在的过大差异,减少对同一语音源下不同语音数据的模型预测波动,提高任一语音数据在语音模型下的处理准确性。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1a为本发明实施例一提供的一种语音模型的训练方法的流程图;
图1b为本发明实施例一提供的语音模型的训练过程的原理示意图;
图2a为本发明实施例二提供的一种语音模型的训练方法的流程图;
图2b为本发明实施例二提供的语音模型的训练过程的原理示意图;
图3为本发明实施例三提供的一种语音模型的训练装置的结构示意图;
图4为本发明实施例四提供的一种服务器的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。此外,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
实施例一
图1a为本发明实施例一提供的一种语音模型的训练方法的流程图,本实施例可适用于对任一语音场景下的语音模型进行训练的情况中。本实施例提供的语音模型的训练方法可以由本发明实施例提供的语音模型的训练装置来执行,该装置可以通过软件和/或硬件的方式来实现,并集成在执行本方法的服务器中。
具体的,参考图1a,该方法可以包括如下步骤:
s110,将无损语音数据和无损语音数据编码变换后的目标语音数据分别输入到预先构建的语音模型中,得到无损语音数据的第一模型结果和目标语音数据的第二模型结果。
具体的,由于现有语音模型训练时,会将每一语音数据作为训练样本,直接根据每一训练样本的训练标签,采用交叉熵的损失函数对语音模型进行训练,此时由于同一语音源在不同编码下的各个语音编码数据之间存在不同的语音内容丢失,使得现有训练方式下的语音模型对同一语音源在不同编码下的各个语音编码数据的模型输出结果也存在一定的差异,影响到语音模型对语音数据的处理准确性;因此,为了解决上述问题,本实施例会提供一种新的语音模型训练方式,针对语音模型对于无损语音数据所输出的模型结果能够准确代表该无损语音数据所属的语音源的真实输出结果的特点,会将无损语音数据在语音模型中输出的第一模型结果作为语音模型对于该无损语音数据所属的语音源下其他语音数据进行处理的参考信息,以确保语音模型的训练全面性。
需要说明的是,本实施例中的无损语音数据可以为采用无损压缩下的编码方式对语音源数据进行编码后的语音数据,语音源数据为原始语音采样数据,进而使得该无损语音数据相比语音源数据来说,几乎不存在语音信息丢失,无损压缩下的编码方式可以为脉冲编码调制(pulsecodemodulation,简称为pcm)编码或者霍夫曼编码等;同时,由于在编码时选用的编码码率不同,会造成语音数据的信息丢失不同,而无损语音数据作为其他语音数据在语音模型中的处理参考,也会要求该无损语音数据所选用的编码码率可以适当为较高的码率档位,以便后续该无损语音数据能够成功变换到较低码率档位下,进而采用该无损语音数据和变换到较低码率档位下的语音数据来共同对语音模型进行训练。
此外,本实施例中预先构建的语音模型可以为面向任一类语音处理任务构建的网络模型,例如需要对各个语音信号的语音内容进行识别预测时所构建的语音识别模型,通过解析语音信号的内容来预测当前所处场景时所构建的场景识别模型,以及通过解析语音信号的内容来预测当前是否触发执行某一事件时所构建的事件检测模型等,本实施例中对于语音模型所属的具体预测类别不作限定,只要该语音模型是通过对各个语音信号进行分析来执行具体预测功能即可。
在本实施例中,为了保证预先构建的语音模型的训练准确性,本实施例首先会获取采用无损压缩下的编码方式对原始语音采样数据进行编码得到的无损语音数据,同时获取该无损语音数据采用多种其他编码方式进行编码变换后的各个目标语音数据,此时无损语音数据和每一目标语音数据均来自同一语音源,也就是具有相同的语音内容,然后为了避免同一语音源下不同语音数据在语音模型下的预测结果波动,直接将该无损语音数据和各个目标语音数据分别输入到预先构建的语音模型中,采用该语音模型中已训练的模型参数和模型结构分别对该无损语音数据和各个目标语音数据进行处理,进而可以预测得到该无损语音数据的第一模型结果和各个目标语音数据的第二模型结果,后续通过第一模型结果和各个第二模型结果之间的差异不断对该语音模型进行训练,以使该无损语音数据的第一模型结果和各个目标语音数据的第二模型结果之间能够保持一致,从而减少同一语音源下不同语音数据在语音模型下的预测结果波动。
示例性的,本实施例会将无损语音数据和该无损语音数据经过编码变换后的每一目标语音数据分别组成相应的语音对,然后将各个语音对作为该语音模型的训练样本,并将该无损语音数据的语音标注信息作为各训练样本的样本标签,然后将每一语音对不断输入预先构建的语音模型中,后续根据语音模型输出的模型结果对和对应的样本标签,对该语音模型进行训练。
s120,以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,对语音模型进行训练。
可选的,在得到无损语音数据的第一模型结果和目标语音数据的第二模型结果之后,为了确保语音模型对于同一语音源下不同语音数据所输出的各模型结果之间的一致性,本实施例会以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,来更新该语音模型中现有的模型结构和模型参数,此时该预设差异目标可以为最小化第一模型结果和第二模型结果之间的差异或者使第一模型结果和第二模型结果之间的差异满足预设差异区间,以确保同一语音源下不同语音数据在语音模型中所输出的各模型结果能够大致保持一致,而不存在过大的模型输出差异;后续采用更新后的语音模型继续对新的无损语音数据和该新的无损语音数据编码变换后的目标语音数据进行处理,依次循环,不断对该语音模型进行训练,直至第一模型结果和第二模型结果之间的差异趋向预设差异指标下的收敛,此时确定该语音模型训练完成,使得后续采用训练完成的语音模型对任一语音数据进行处理时,无论该语音数据为无损语音数据还是其他有损压缩的编码方式下的其他语音数据,均能够准确得到该语音数据在无损语音下的模型结果,提高语音模型的预测准确性。
此时,本实施例中以最小化第一模型结果和第二模型结果之间的差异为目标,或者以使第一模型结果和第二模型结果之间的差异满足预设差异区间为目标,均可以实现对语音模型的训练。
进一步的,为了保证语音模型的成功训练,本实施例在预先构建语音模型时,会直接以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,生成该语音模型的训练损失函数;在语音模型的训练过程中,不断将各个无损语音数据和该无损语音数据编码变换后的目标语音数据分别输入到预先构建的语音模型中,得到该无损语音数据的第一模型结果和目标语音数据的第二模型结果,然后采用该语音模型的训练损失函数,不断分析第一模型结果的具体值和第二模型结果的具体值之间的损失差异,并不断使该损失差异趋于预设差异指标的要求,进而对该语音模型进行训练。此时,通过本实施例中的训练损失函数对语音模型进行训练,能够使经过有损编码变换下的目标语音数据在该语音模型中输出的第二模型结果不断趋近于同一语音源下的无损语音数据在该语音模型中输出的第一模型结果,从而减少语音模型对同一语音源下不同语音数据输出的模型结果之间存在的差异,使得该语音模型训练完成后,对任一有损语音数据进行模型处理时,无需额外获取与该有损语音数据处于同一语音源下的无损语音数据,即可直接得到该有损语音数据下的无损模型结果,从而提高任一语音数据在语音模型下的处理准确性,减少对同一语音源下不同语音数据的模型预测波动。示例性的,在以最小化第一模型结果和第二模型结果之间的差异为目标,对语音模型进行训练时,本实施例中所生成的该语音模型的训练损失函数可以为:
本实施例提供的技术方案,将无损语音数据和该无损语音数据编码变换后的目标语音数据作为预先构建的语音模型的训练样本,此时无损语音数据和目标语音数据具有相同的语音源,在语音模型的训练过程中,不断将无损语音数据和目标语音数据分别输入到该语音模型中,以得到无损语音数据的第一模型结果和目标语音数据的第二模型结果,然后以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,对该语音模型进行训练,使得该语音模型能够对同一语音源下的无损语音数据和目标语音数据输出相近的模型结果,避免语音模型对同一语音源下不同语音数据输出的模型结果之间存在的过大差异,减少对同一语音源下不同语音数据的模型预测波动,提高任一语音数据在语音模型下的处理准确性。
实施例二
图2a为本发明实施例二提供的一种语音模型的训练方法的流程图,图2b为本发明实施例二提供的语音模型的训练过程的原理示意图。本实施例是在上述实施例的基础上进行优化。具体的,如图2a所示,本实施例主要对于无损语音数据到目标语音数据之间的编码变换过程以及语音模型对于无损语音数据和目标语音数据的输入要求进行详细的解释说明。
可选的,如图2a所示,本实施例中可以包括如下步骤:
s210,获取无损语音数据。
可选的,在对语音模型进行训练时,首先需要获取大量的训练样本,本实施例为了避免同一语音源下不同语音数据在语音模型下的预测结果波动,会将采用无损压缩的编码方式对原始语音采样数据进行编码的无损语音数据,以及该无损语音数据采用其他编码方式下进行编码变换的目标语音数据组合成对应的语音对,作为语音模型的训练样本,因此本实施例首先会采用无损压缩的编码方式,对大量原始语音采样数据进行编码,从而获取到大量的无损语音数据,后续通过对每一无损语音数据进行编码变换,而得到对应的目标语音数据。
需要说明的是,由于如果语音编码所选用的编码码率不同,使得编码过程中的信息丢失不同,从而也会得到同一语音源下的不同语音数据,使得语音模型对同一语音源下的不同语音数据输出不同的模型结果,因此本实施例中的无损语音数据的编码码率会选用较高的码率档位,以便后续能够变换到较低的码率档位,而得到大量目标语音数据。
s220,基于预设编码方式和预设码率档位对无损语音数据进行编码变换,得到对应的目标语音数据。
可选的,在获取到无损语音数据之后,可以采用各个预设编码方式对该无损语音数据进行重新编码,此时该预设编码方式可以为有损压缩下的编码方式,以确保语音模型的训练样本中无损语音数据与目标语音数据之间的编码差别,然后为了保证语音模型对不同编码码率下的语音数据进行区分训练,还会预先设定不同的码率档位,在采用各个预设编码方式对无损语音数据进行编码之后,针对无损语音数据在每一预设编码方式下的编码结果,分别采用每一预设码率档位对该编码结果进行码率变换,从而得到不同预设码率档位下的目标语音数据,此时可以每一无损语音数据经过编码变换后,可以得到多个目标语音数据,而且为了保证码率变换的准确性,本实施例中的预设码率档位会小于无损语音数据的编码码率,实现高码率到低码率的码率变换。
示例性的,无损语音数据可以为采用pcm编码后码率为256kbps的语音数据,此时预设编码方式可以为mp3编码和高级音频编码(advancedaudiocoding,aac),预设码率档位可以为32kbps、64kbps和128kbps三个档位,因此无损语音数据基于预设编码方式和预设码率档位进行编码变换后,可以得到6种目标语音数据。
s230,分别提取无损语音数据和目标语音数据的时频图。
可选的,为了保证语音模型对于无损语音数据和目标语音数据提取语音特征的便捷性,本实施例首先会对无损语音数据和目标语音数据进行时频分析,以分别提取出无损语音数据和目标语音数据的时频图,如图2b所示,后续通过语音模型分析无损语音数据和目标语音数据的时频图中所包含的语音信息,从而准确提取无损语音数据和目标语音数据的语音特征,提高语音模型处理的准确性。
s240,将无损语音数据和目标语音数据的时频图输入到预先构建的语音模型中,得到无损语音数据的第一模型结果和目标语音数据的第二模型结果。
可选的,在提取出无损语音数据和目标语音数据的时频图之后,会直接将无损语音数据和目标语音数据的时频图分别输入语音模型中,通过语音模型中的卷积层分别提取无损语音数据和目标语音数据的语音特征,并采用全连接层对无损语音数据和目标语音数据的语音特征进行综合分析,从而得到无损语音数据的第一模型结果和目标语音数据的第二模型结果。
s250,以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,对语音模型进行训练。
本实施例提供的技术方案,将无损语音数据和该无损语音数据编码变换后的目标语音数据作为预先构建的语音模型的训练样本,此时无损语音数据和目标语音数据具有相同的语音源,在语音模型的训练过程中,不断将无损语音数据和目标语音数据分别输入到该语音模型中,以得到无损语音数据的第一模型结果和目标语音数据的第二模型结果,然后以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,对该语音模型进行训练,使得该语音模型能够对同一语音源下的无损语音数据和目标语音数据输出相近的模型结果,避免语音模型对同一语音源下不同语音数据输出的模型结果之间存在的过大差异,减少对同一语音源下不同语音数据的模型预测波动,提高任一语音数据在语音模型下的处理准确性。
实施例三
图3为本发明实施例三提供的一种语音模型的训练装置的结构示意图,具体的,如图3所示,该装置可以包括:
语音数据输入模块310,用于将无损语音数据和所述无损语音数据编码变换后的目标语音数据分别输入到预先构建的语音模型中,得到所述无损语音数据的第一模型结果和所述目标语音数据的第二模型结果;
语音模型训练模块320,用于以使所述第一模型结果和所述第二模型结果之间的差异趋于预设差异指标为目标,对所述语音模型进行训练。
本实施例提供的技术方案,将无损语音数据和该无损语音数据编码变换后的目标语音数据作为预先构建的语音模型的训练样本,此时无损语音数据和目标语音数据具有相同的语音源,在语音模型的训练过程中,不断将无损语音数据和目标语音数据分别输入到该语音模型中,以得到无损语音数据的第一模型结果和目标语音数据的第二模型结果,然后以使第一模型结果和第二模型结果之间的差异趋于预设差异指标为目标,对该语音模型进行训练,使得该语音模型能够对同一语音源下的无损语音数据和目标语音数据输出相近的模型结果,避免语音模型对同一语音源下不同语音数据输出的模型结果之间存在的过大差异,减少对同一语音源下不同语音数据的模型预测波动,提高任一语音数据在语音模型下的处理准确性。
本实施例提供的语音模型的训练装置可适用于上述任意实施例提供的语音模型的训练方法,具备相应的功能和有益效果。
实施例四
图4为本发明实施例四提供的一种服务器的结构示意图,如图4所示,该服务器包括处理器40、存储装置41和通信装置42;服务器中处理器40的数量可以是一个或多个,图4中以一个处理器40为例;服务器中的处理器40、存储装置41和通信装置42可以通过总线或其他方式连接,图4中以通过总线连接为例。
本实施例提供的一种服务器可用于执行上述任意实施例提供的语音模型的训练方法,具备相应的功能和有益效果。
实施例五
本发明实施例五还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可实现上述任意实施例中的语音模型的训练方法。该方法具体可以包括:
将无损语音数据和所述无损语音数据编码变换后的目标语音数据分别输入到预先构建的语音模型中,得到所述无损语音数据的第一模型结果和所述目标语音数据的第二模型结果;
以使所述第一模型结果和所述第二模型结果之间的差异趋于预设差异指标为目标,对所述语音模型进行训练。
当然,本发明实施例所提供的一种包含计算机可执行指令的存储介质,其计算机可执行指令不限于如上所述的方法操作,还可以执行本发明任意实施例所提供的语音模型的训练方法中的相关操作。
通过以上关于实施方式的描述,所属领域的技术人员可以清楚地了解到,本发明可借助软件及必需的通用硬件来实现,当然也可以通过硬件实现,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如计算机的软盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、闪存(flash)、硬盘或光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
值得注意的是,上述语音模型的训练装置的实施例中,所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



