
 商标分类
商标分类  商标转让
商标转让 
智能语音对话装置及其运行方法、智能语音对话机器人与流程
 2021-01-28 15:01:04|
2021-01-28 15:01:04| 304|
304| 起点商标网
起点商标网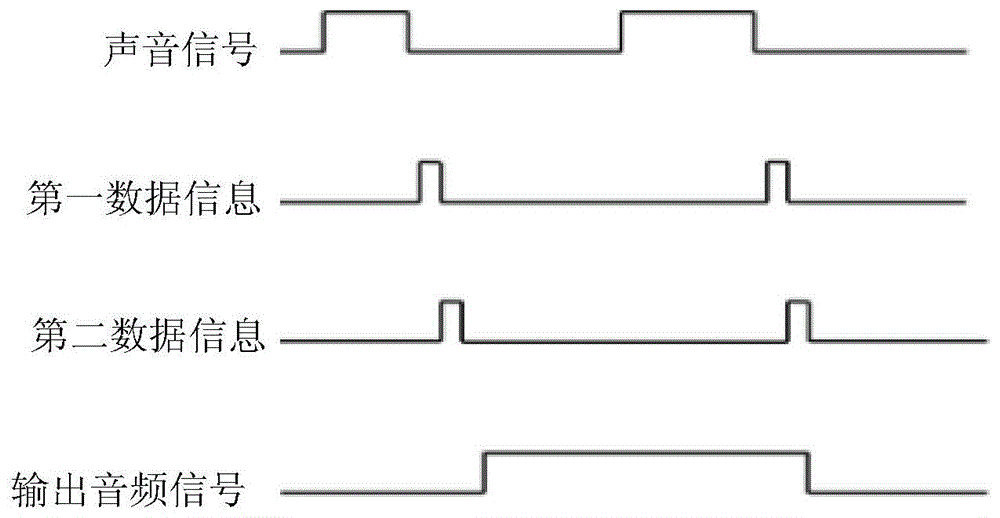
本发明属于智能语音对话机器人技术领域,具体涉及一种智能语音对话装置、一种智能语音对话装置的运行方法、一种智能语音对话机器人。
背景技术:
目前,关于人形机器人的智能对话功能已经成为一种商业热潮。例如nao机器人,nao是一个应用遍及全球教育市场的双足人形机器人,身高58公分的nao拥有与人类一样自然的肢体语言,能够听、能够看、能够说,也能够与人互动,或nao之间彼此进行互动。
nao机器人的语音识别功能在于实时监测是否存在关键词,若触发到关键词条,nao机器人就会根据数据库里的内容做出相应的回答。但是,nao机器人只能识别到关键词条,而且只能根据已经预先设定的答案进行回答,其本质上只是专家系统,不能实现真正的智能对话;而且nao机器人的语音识别硬件模块识别率低,用户体验不佳,经常出现误识别。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提供了一种智能语音对话装置、一种智能语音对话装置的运行方法、一种智能语音对话机器人。本发明要解决的技术问题通过以下技术方案实现:
本发明提供了一种智能语音对话装置,包括:
语音接收模块,用于接收声音信号,并将其发送至控制模块;
所述控制模块,用于对所述声音信号进行压缩,并将压缩文件传输至第一语音识别模块;
所述第一语音识别模块,用于对所述压缩文件进行识别,将识别后的内容转换为第一字符序列,并将所述第一字符序列传输至所述控制模块;
智能对话模块,用于对所述控制模块输出的所述第一字符序列进行运算得到回复信息,将所述回复信息转换为第二字符序列,并将所述第二字符序列传输至所述控制模块;
第二语音识别模块,用于将所述控制模块输出的所述第二字符序列转换为音频数字信号,并进行语音输出;
所述控制模块,还用于控制所述语音接收模块在语音输出时间内不接收所述声音信号。
在本发明的一个实施例中,所述语音接收模块为麦克风。
在本发明的一个实施例中,所述控制模块为树莓派。
在本发明的一个实施例中,所述第一语音识别模块为语音识别服务器。
在本发明的一个实施例中,所述智能对话模块为智能对话服务器。
在本发明的一个实施例中,所述第二语音识别模块为wegasun-m6模块。
在本发明的一个实施例中,所述控制模块包括语音输出时间计算单元,其中,
所述语音输出时间计算单元,用于根据所述第二字符序列,计算得到其对应语音输出时间y,计算公式如下,
y=5.606×10-7x3-8.492×10-5x2+0.2357x+0.5581,
其中,x表示第二字符序列的长度;
所述控制模块,用于根据所述语音输出时间y,控制所述语音接收模块在此时间内不接收所述声音信号。
本发明还提供了一种智能语音对话装置的运行方法,适用于上述实施例所述的任一种智能语音对话装置,包括:
接收声音信号;
对所述声音信号进行压缩,形成压缩文件;
对所述压缩文件进行识别,将识别后的内容转换为第一字符序列;
对所述第一字符序列进行运算得到回复信息,将所述回复信息转换为第二字符序列;
将所述第二字符序列转换为音频数字信号,并进行语音输出,且在语音输出时间内不接收所述声音信号。
本发明又提供了一种智能语音对话机器人,所述智能语音对话机器人包括上述实施例所述的任一种智能语音对话装置。
与现有技术相比,本发明的有益效果在于:
1、本发明的智能语音对话装置,在语音输出时间内控制语音接收模块不接收声音信号,可以克服回复信息播放时,被语音接收模块收录,形成噪声干扰的问题,也可以避免在第一组回复信息播放时,发送第二组回复信息,导致智能语音对话装置停止工作的现象发生。
2、本发明的智能语音对话装置,采用wegasun-m6模块作为第二语音识别模块,提高了智能语音对话装置的在复杂环境和高噪声环境中的适应性。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1是本发明实施例提供的一种传统的智能语音对话装置的时序图;
图2是本发明实施例提供的一种智能语音对话装置的结构框图;
图3是本发明实施例提供的另一种智能语音对话装置的结构框图;
图4是本发明实施例提供的一种智能语音对话装置的的时序图。
附图标记说明
1-语音接收模块;2-控制模块;201-语音输出时间计算单元;3-第一语音识别模块;4-智能对话模块;5-第二语音识别模块。
具体实施方式
为了进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及具体实施方式,对依据本发明提出的一种智能语音对话装置、一种智能语音对话装置的运行方法、一种智能语音对话机器人进行详细说明。
有关本发明的前述及其他技术内容、特点及功效,在以下配合附图的具体实施方式详细说明中即可清楚地呈现。通过具体实施方式的说明,可对本发明为达成预定目的所采取的技术手段及功效进行更加深入且具体地了解,然而所附附图仅是提供参考与说明之用,并非用来对本发明的技术方案加以限制。
请参见图1,图1是本发明实施例提供的一种传统的智能语音对话装置的时序图,如图所示,传统的智能语音对话装置,在捕获到第一组声音信号的之后,对其进行识别得到第一数据信息、然后再对第一数据信息进行运算处理得到第二数据信息,最后第二数据信息作为回复信息转化为音频信号被播放。但是,如果此时有用户输入第二组声音信号,会产生两个问题:
1、第一组声音信号的回复信息播放时会被收录,形成无用的噪声干扰;
2、由于对声音信号的识别和运算处理的速度很快,所以会发生在第一组回复信息未播放完时,第二组声音信号的回复信息已经产生的现象,此现象会导致智能语音对话装置发生故障,不仅不会继续播放第一组回复信息,第二组回复信息也会消失。
实施例一
为了解决上述问题,本实施例提供了一种智能语音对话装置,包括,语音接收模块1、控制模块2、第一语音识别模块3、智能对话模块4和第二语音识别模块5。其中,语音接收模块1、第一语音识别模块3、智能对话模块4和第二语音识别模块5均与控制模块2连接。语音接收模块1用于接收声音信号,并将其发送至控制模块2;控制模块2用于对声音信号进行压缩,并将压缩文件传输至第一语音识别模块3;第一语音识别模块3用于对压缩文件进行识别,将识别后的内容转换为第一字符序列,并将第一字符序列传输至控制模块2;智能对话模块4用于对控制模块2输出的第一字符序列进行运算得到回复信息,将回复信息转换为第二字符序列,并将第二字符序列传输至控制模块2;第二语音识别模块5用于将控制模块2输出的第二字符序列转换为音频数字信号,并进行语音输出;控制模块2还用于控制语音接收模块1在语音输出时间内不接收声音信号。
本实施例的智能语音对话装置,在语音输出时间内控制语音接收模块不接收声音信号,可以克服回复信息播放时,被语音接收模块收录,形成噪声干扰的问题,也可以避免在第一组回复信息播放时,发送第二组回复信息,从而导致第二语音识别模块停止工作的现象发生。
进一步地,对本实施的智能语音对话装置各模块进行具体说明。
本实施例的语音接收模块1为麦克风,用于收录声音信号,并通过usb接口将声音信号传递至控制模块2。
本实施例的控制模块2为树莓派,树莓派(raspberrypi,简称为rpi)它是一款微型电脑主板,其系统基于linux,具备所有pc(个人电脑,personalcomputer)的基本功能。在本实施例中,树莓派将声音信号进行压缩,转换为一个mp3文件,并将该mp3文件传输至第一语音识别模块3。
本实施例的第一语音识别模块3为语音识别服务器,通过语音识别技术识别出该mp3的文字内容,并将识别出的内容转换为第一字符序列,将所述第一字符序列通过http(超文本传输)协议传输至树莓派。语音识别技术,也被称为自动语音识别(automaticspeechrecognition,简称asr),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如二进制编码或者字符序列。在本实施例中,语音识别服务器将语音接收模块1收录的声音信号,通过预处理、特征提取后、输入到预先训练好的模型中,对该声音信号进行识别。
本实施例的智能对话模块4为智能对话服务器,用于对树莓派输出的第一字符序列进行运算得到回复信息,将所述回复信息转换为第二字符序列,并将所述第二字符序列通过http协议传输至树莓派。在本实施例中,智能对话服务器通过人工智能以及深度学习对第一字符序列进行运算得到回复信息。
本实施例的第二语音识别模块5为wegasun-m6模块,wegasun-m6模块是珠海时代电子科技有限公司推出的一款集语音识别、语音合成、语音(mp3)点播、rf(射频)功能、红外功能于一体的多功能模块。由于其优越的语音识别和语音合成性能,应用领域十分广泛。在本实施例中,wegasun-m6模块用于将树莓派输出的第二字符序列转换成音频二进制数据,音频二进制数据通过da转换器(da转换器是用于将数字信号转换为模拟信号的电路)转换成模拟信号,最后传输至喇叭播放。
进一步地,请参见图3,图3是本发明实施例提供的另一种智能语音对话装置的结构框图,如图所示,本实施例的控制模块2包括语音输出时间计算单元201,其中,语音输出时间计算单元201用于根据第二字符序列,计算得到其对应语音输出时间y,控制模块2还用于根据语音输出时间y,控制语音接收模块1在此时间内不接收声音信号。
计算公式如下,
y=5.606×10-7x3-8.492×10-5x2+0.2357x+0.5581(1),
其中,x表示第二字符序列的长度。
在本实施例中,通过测量wegasun-m6模块播放语音时,播放语音的时长,每个文字的播放时间,与对应第二字符序列的长度,选择3次多项式作为插值公式,然后用计算机拟合得到各项系数,最后得到公式(1)。
请参见图4,图4是本发明实施例提供的一种智能语音对话装置的的时序图,如图所示,在麦克风收录第一组声音信号之后,语音识别服务器对其进行识别得到第一字符序列;然后,智能对话服务器再对第一字符序列进行运算处理得到第二字符序列;最后,wegasun-m6模块将第二字符序列转换成音频二进制数据,再通过da转换器转换成模拟信号,最后传输至喇叭进行播放。同时,语音输出时间计算单元201根据公式(1)计算得到第二字符序列对应的语音输出时间y,树莓派根据所述语音输出时间y,在第一组声音信号的回复信息的音频未播放完毕之前,控制麦克风不接收任何声音信号,从而解决了传统的智能语音对话装置中存在的问题。从图3的时序图也可以看出,第二组声音信号被屏蔽,并不会传输至语音识别服务器进行识别。
本实施例的智能语音对话装置,在语音输出时间内控制语音接收模块不接收声音信号,可以克服回复信息播放时,被语音接收模块收录,形成噪声干扰的问题,也可以避免在第一组回复信息播放时,发送第二组回复信息,从而导致智能语音对话装置停止工作的现象发生。另外,本实施例的智能语音对话装置,采用wegasun-m6模块作为第二语音识别模块,提高了智能语音对话装置的在复杂环境和高噪声环境中的适应性。
另外,本实施例还提供了一种智能语音对话装置的运行方法,适用于上述实施例的智能语音对话装置,包括:
s1:接收声音信号;
具体地,麦克风收录人声信号,通过usb接口将人声信号传递给树莓派。
s2:对所述声音信号进行压缩,形成压缩文件;
具体地,树莓派将人声信号压缩转换成mp3文件,并通过http协议将mp3文件上传至语音识别服务器。
s3:对所述压缩文件进行识别,将识别后的内容转换第一字符序列;
具体地,语音识别服务器识别出该mp3的文字内容后,将其转换为第一字符序列,并通过http协议返回树莓派。
s4:对所述第一字符序列进行运算得到回复信息,将所述回复信息转换为第二字符序列;
具体地,树莓派通过http协议将第一字符序列上传至智能对话服务器,智能对话服务器经过运算得到回复信息,并将回复信息内容转换为第二字符序列,并通过http协议返回树莓派。
s5:将所述第二字符序列转换为音频数字信号,并进行语音输出,且在语音输出时间内不接收所述声音信号。
具体地,树莓派通过串口将第二字符序列传递至wegasun-m6模块,wegasun-m6将第二字符序列转换成音频二进制数据,然后再将音频二进制数据通过da转换器转换成模拟信号,最后传输至喇叭进行播放,从而实现智能对话。同时,树莓派根据第二字符序列对应的语音输出时间y,控制麦克风在此时间内不接收任何声音信号。
进一步地,本实施例还提供了一种智能语音对话机器人,所述智能语音对话机器人包括上述实施例所述的智能语音对话装置。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



