
 商标分类
商标分类  商标转让
商标转让 
抗饱和失真的广义混合范数自适应回声消除方法与流程
 2021-01-28 15:01:19|
2021-01-28 15:01:19| 364|
364| 起点商标网
起点商标网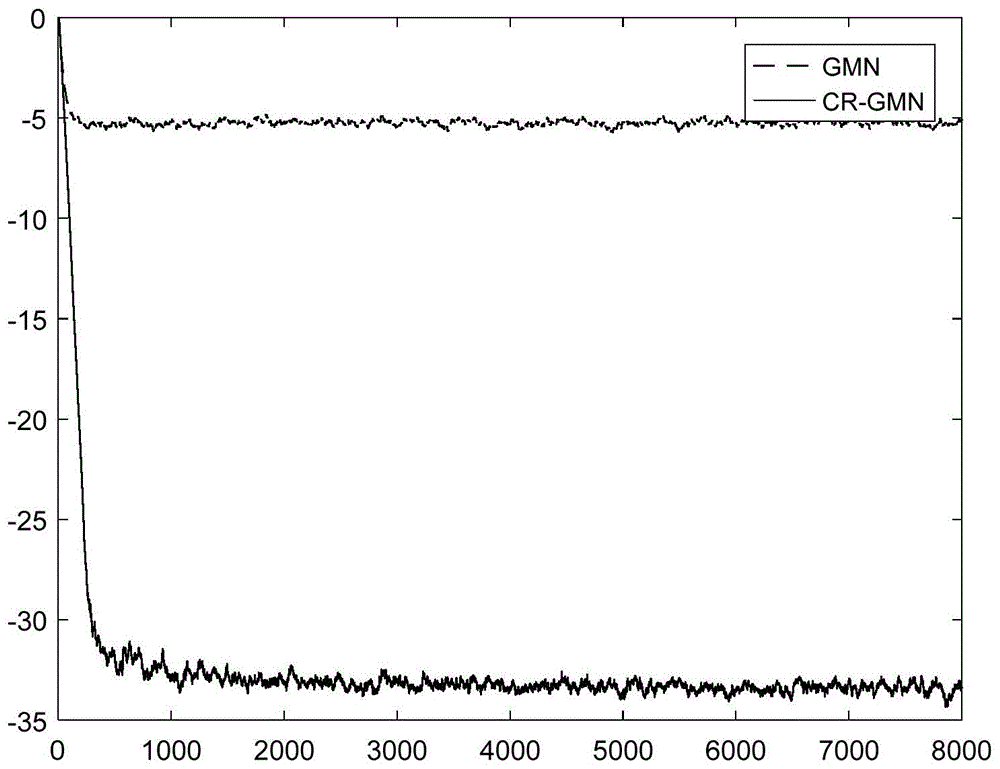
本发明涉及一种语音通信系统中的自适应回声消除方法。技术背景语音通信系统中的回声现象是指近端麦克风拾取的声音信号在传输过程中产生延时或形变又传回近端由听筒播放出来的现象(也即人们在通话过程中可以听到自己前一时刻的说话声音的现象)。回声会严重影响人们的通话质量,因此,对回声进行消除成为了人们关注的重点。通信回声可以通过系统辨识模型来进行自适应消除:所辨识系统为回声信道,系统辨识的输出为回声信号的估计;再将近端采样得到的,含回声信号的语音信号与回声信号的估计相减,然后由近端听筒播放出来,便可在近端实现回声的消除。自适应回声消除技术具有成本低,收敛速度快,回声残差小的优点,在通信领域被认为是最有前景的回声消除技术。最常用的自适应回声消除方法为最小均方误差方法,其对误差的运算为二次方,对误差不够敏感,其收敛速度较低。马文涛等人提出了误差的两个不同范数混合值最小的方法(广义混合范数方法)来代替传统的最小均方误差方法(文献1“kernelrecursivegeneralizedmixednormalgorithm.”w.ma,x.qiu,j.duan,y.li,andb.chenjournalofthefranklininstitute(2017):s0016003217301813)。这种广义混合范数方法,误差的运算幂指数更高,对误差更敏感,提高了收敛速度,还降低了非高斯噪声环境中的稳态误差。但是,现有的自适应回声消除方法,均是在麦克风拾取出的语音信号完整的假定下建立的。在近端语音信号强时,近端麦克风会产生饱和失真,使得拾取出的近端信号会产生饱和失真;导致基于语音信号完整的假定,而估计出的误差信号也会严重失真,进而导致算法精度低、稳态误差大,不能在强语音通信场景中使用。技术实现要素:本发明的目的是提供一种抗饱和失真的广义混合范数自适应回声消除方法,该方法抗饱和失真性能强、稳态误差小,收敛速度快,回声消除效果好,尤其适用于强语音通信场景。本发明实现其发明目的所采用的技术方案是,一种抗饱和失真的广义混合范数自适应回声消除方法,其步骤是:a、远端信号采集对远端传来的信号进行采样,获得当前时刻n的远端输入信号的离散值x(n),将当前时刻n和之前m-1个时刻的输入信号的离散值x(n)、x(n-1),...,x(n-m+1),组成自适应滤波器的当前时刻n的输入向量x(n),x(n)=[x(n),x(n-1),...,x(n-m+1)]t,其中t代表转置运算,m为自适应滤波器的抽头数、其取值为8、16、32;b、回声信号估计将当前时刻n的输入信号向量x(n)通过自适应滤波器,得到自适应滤波器的当前时刻n的输出值,即当前时刻n的回声信号估计值y(n)y(n)=xt(n)w(n)其中,w(n)为自适应滤波器的当前时刻n的抽头权向量,w(n)=[w1(n),w2(n),...,wm(n),...,wm(n)]t;wm(n)为自适应滤波器的当前时刻n的第m个抽头权系数,w(n)的初始值为零向量;c、回声消除对近端麦克风采样得到带回声的当前时刻n的近端信号d(n),将其减去回声信号的估计值y(n),得到当前时刻n的误差信号估计值e(n),再送回给远端,e(n)=d(n)-y(n);d、滤波器抽头权向量更新d1、回声信号的概率密度计算将当前时刻n及其前m-1个时刻的回声信号估计值y(n)、y(n-1),...,y(n-m+1),组成当前时刻n的回声信号估计值向量y(n),y(n)=[y(n),y(n-1),...,y(n-m+1)]t;估计出当前时刻n的回声信号估计值向量y(n)中的时刻i与时刻j间的回声信号的相对概率密度p(i,j),其中,i、j为当前时刻n及其前m-1个时刻中的任一时刻,i∈[n-m+1,n],j∈[n-m+1,n];σ2为当前时刻n的回声信号估计值向量y(n)中的回声信号估计值的均方差,其取值范围为σ>1.0;exp(·)表示自然指数运算;进而得到当前时刻n的回声信号估计值向量y(n)的回声信号概率密度累积值p(n),再估计出当前时刻n的回声信号的概率密度值p(n),及当前时刻n的回声信号负值的概率密度值p*(n),其中,y为当前时刻n的回声信号估计值向量的回声信号估计值的平均值d2、抽头权向量的预估更新先得到当前时刻n的近端信号符号值γ(n),再由下式算出下一时刻n+1的预估抽头权向量其中,的初始值即为全零向量,η是预估抽头权向量的更新步长,其取值范围为[0.001,0.002];d3、回声信号及误差的更新预估由当前时刻n的回声信号的概率密度值p(n)、回声信号概率密度累积值p(n)和下一时刻n+1的预估抽头权向量计算出下一时刻n+1的回声信号预估值进而得到下一时刻n+1的误差信号预估值d4、抽头权向量的更新由下式得出自适应滤波器的下一时刻n+1的抽头权向量其中,μ代表步长、其取值为0.0001-0.002,a为误差计算的范数指数一、b为误差计算的范数指数二、a,b的取值范围为[0,4],0<λ<1为范数指数一和范数指数二的混合参数,其取值范围为(0,1),sign(·)为符号函数运算;e、令n=n+1,重复上述步骤a、b、c、d的过程,直至通话结束。与现有的技术相比,本发明的有益效果是:一、在强语音通信场景,近端麦克风会产生饱和失真,使得拾取出的近端信号会产生饱和失真;现有的自适应回声消除方法,完全忽略近端语音信号的失真,估计出的误差信号严重失真,进而导致算法精度低、稳态误差大,不能在强语音通信场景中使用。本发明通过对滤波器输出的回声信号的概率分布密度值和概率密度累积值的估计,进而根据最大似然估计方法,估计出滤波器的权向量的最大似然预估值及回声信号和误差的最大似然预估值;再以误差的最大似然预估值的范数组合,替代已失真的误差的范数组合作为代价函数,迭代更新计算出滤波器校正后的权向量。从而最大限度的补偿了由于传感器的饱和特性造成的输出信号及误差信号的失真,能更好、更快的逼近真实的误差和回声,其抗饱和失真性能好,稳态误差小,收敛速度快,回声消除效果好。二、本发明以最大似然估计方法得到的误差的最大似然预估值的两个范数值的组合为代价函数,较之最小误差均方法以单一的误差均方(二阶范数)作为为代价函数;本发明的对误差的运算更全、幂指数更高,对误差更敏感;也提高了收敛速度,降低了非高斯噪声环境中的稳态误差。下面结合附图和具体实施方式对本发明做进一步的详细说明。附图说明图1是文献1和本发明方法的仿真实验得到的归一化稳态失调曲线图。图中标记为gmn的曲线为文献1方法的归一化稳态失调曲线,标记为cr-gmn的曲线为本发明方法的归一化稳态失调曲线。具体实施方式:实施例本发明的一种具体实施例是,一种抗饱和失真的广义混合范数自适应回声消除方法,其步骤是:a、远端信号采集对远端传来的信号进行采样,获得当前时刻n的远端输入信号的离散值x(n),将当前时刻n和之前m-1个时刻的输入信号的离散值x(n)、x(n-1),...,x(n-m+1),组成自适应滤波器的当前时刻n的输入向量x(n),x(n)=[x(n),x(n-1),...,x(n-m+1)]t,其中t代表转置运算,m为自适应滤波器的抽头数、其取值为8、16、32;b、回声信号估计将当前时刻n的输入信号向量x(n)通过自适应滤波器,得到自适应滤波器的当前时刻n的输出值,即当前时刻n的回声信号估计值y(n)y(n)=xt(n)w(n)其中,w(n)为自适应滤波器的当前时刻n的抽头权向量,w(n)=[w1(n),w2(n),...,wm(n),...,wm(n)]t;wm(n)为自适应滤波器的当前时刻n的第m个抽头权系数,w(n)的初始值为零向量;c、回声消除对近端麦克风采样得到带回声的当前时刻n的近端信号d(n),将其减去回声信号的估计值y(n),得到当前时刻n的误差信号估计值e(n),再送回给远端,e(n)=d(n)-y(n);d、滤波器抽头权向量更新d1、回声信号的概率密度计算将当前时刻n及其前m-1个时刻的回声信号估计值y(n)、y(n-1),...,y(n-m+1),组成当前时刻n的回声信号估计值向量y(n),y(n)=[y(n),y(n-1),...,y(n-m+1)]t;估计出当前时刻n的回声信号估计值向量y(n)中的时刻i与时刻j间的回声信号的相对概率密度p(i,j),其中,i、j为当前时刻n及其前m-1个时刻中的任一时刻,i∈[n-m+1,n],j∈[n-m+1,n];σ为当前时刻n的回声信号估计值向量y(n)中的回声信号估计值的均方差,其取值范围为σ>1.0;exp(·)表示自然指数运算;进而得到当前时刻n的回声信号估计值向量y(n)的回声信号概率密度累积值p(n),再估计出当前时刻n的回声信号的概率密度值p(n),及当前时刻n的回声信号负值的概率密度值p*(n),其中,为当前时刻n的回声信号估计值向量的回声信号估计值的平均值d2、抽头权向量的预估更新先得到当前时刻n的近端信号符号值γ(n),再由下式算出下一时刻n+1的预估抽头权向量其中,的初始值即为全零向量,η是预估抽头权向量的更新步长,其取值范围为[0.001,0.002];d3、回声信号及误差的更新预估由当前时刻n的回声信号的概率密度值p(n)、回声信号概率密度累积值p(n)和下一时刻n+1的预估抽头权向量计算出下一时刻n+1的回声信号预估值进而得到下一时刻n+1的误差信号预估值d4、抽头权向量的更新由下式得出自适应滤波器的下一时刻n+1的抽头权向量其中,μ代表步长、其取值为0.0001-0.002,a为误差计算的范数指数一、b为误差计算的范数指数二、a,b的取值范围为[0,4],0<λ<1为范数指数一和范数指数二的混合参数,其取值范围为(0,1),sign(·)为符号函数运算;e、令n=n+1,重复上述步骤a、b、c、d的过程,直至通话结束。仿真实验:为了验证本发明的有效性,进行了仿真实验,并将文献1的方法与本发明进行对比。仿真实验的条件为:远端信号x(n)为高斯信号,采样频率为8000hz,采样点数为5000;回声信道脉冲响应在宽3.75m,高2.5m,长6.25m,温度20℃,湿度50%的安静密闭房间内获得;脉冲响应长度即滤波器的抽头数m=8;使用具有饱和特性的取值范围为[-2,2]的麦克风对实际取值范围为[-3,3]的近端声音进行采集;实验的背景噪声为30db的高斯白噪声。仿真实验中本发明的方法与文献1的参数取值如下表。文献1μ=0.03,λ=0.3,a=2.5,b=1.6本发明η=0.1,μ=0.03,λ=0.3,a=2.5,b=1.6仿真实验通过独立运行100次得到仿真结果。图1是文献1的方法与本发明方法的归一化稳态失调曲线图,图中纵坐标为稳态误差,横坐标为采样时刻。图1中标记为gmn的曲线为文献1方法的归一化稳态失调曲线,标记为cr-gmn的曲线为本发明方法的归一化稳态失调曲线。从图1中可以看出,文献1(gmn)方法直接使用近端信号与回声估计值之差作为误差信号,进行权向量更新,造成了较高的稳态误差:在迭代大约400次后,其稳态误差稳定在-5db。而本发明方法(cr-gmn)采用通过最大似然估计方法校正后的误差预估值,进行权向量更新;从而有效消除了误差的失真,使算法获得了较低的稳态误差,在迭代大约300次后,稳态误差稳定在-34db。其稳态误差明显减低,说明本发明方法稳态误差低,回声消除效果好。该方法抗饱和失真性能强、稳态误差小,收敛速度快,回声消除效果好,尤其适用于强语音通信场景。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips