
 商标分类
商标分类  商标转让
商标转让 
一种说话人语音分离方法及相关设备与流程
 2021-01-28 15:01:51|
2021-01-28 15:01:51| 268|
268| 起点商标网
起点商标网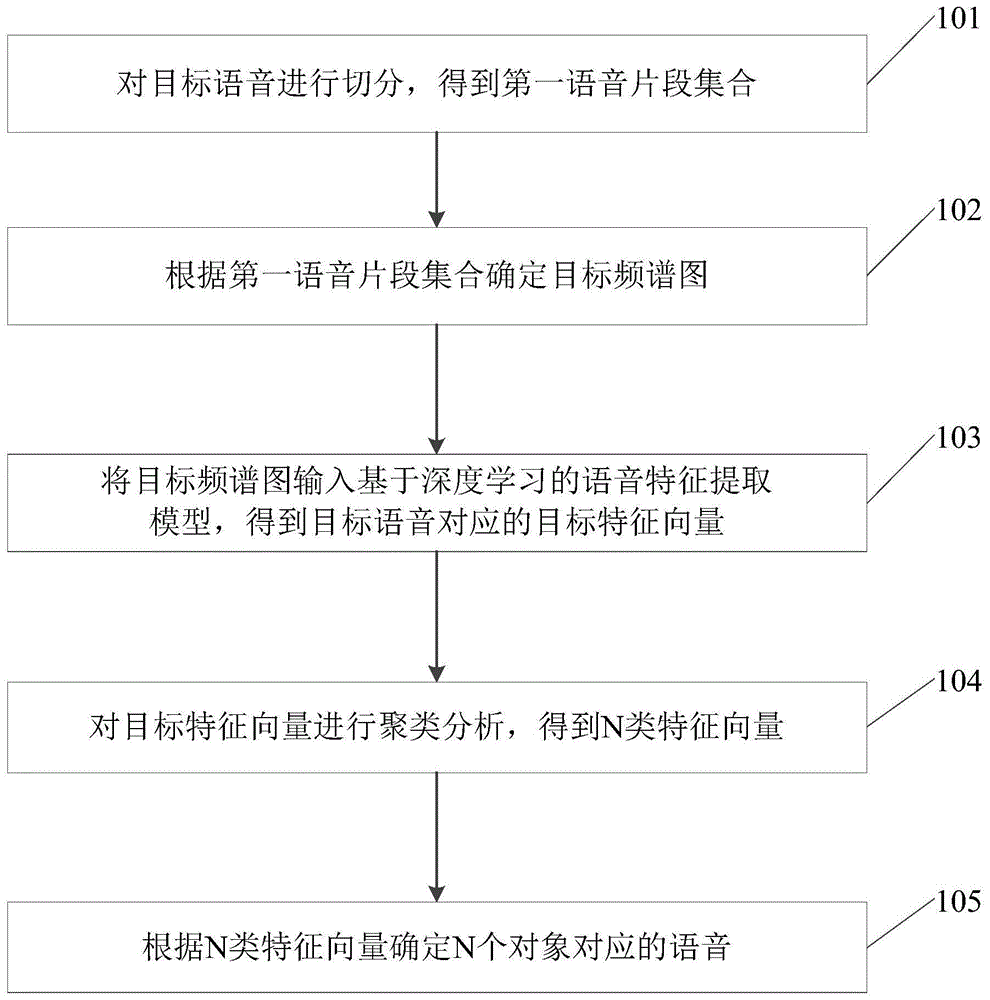
本申请涉及通信领域,尤其涉及一种说话人语音分离方法及相关设备。
背景技术:
在许多语音对话场景中,对话主角们往往都扮演着不同固定的角色。例如,在一次保险销售行业客户与客服交流中,客服主要是询问一些保险客户一些个人情况或者讲解一些保险知识等,而客户主要是询问理赔方案或者对保险理赔规则等的了解。
传统的方法需要耗费大量的人力物力去做来电客户的语音质检、分析客户情感或者买保险意向,费时费力,且准确度不高。
技术实现要素:
本申请提供了一种说话人语音分离方法及相关设备,可以快速准确的识别多人说话的单通道语音中的各个对象的声音,解决了现有技术中费时费力,且准确度不高的问题。
本申请第一方面提供了一种说话人语音分离方法,包括:
对目标语音进行切分,得到第一语音片段集合,所述目标语音为待识别的多对象的单通道语音;
根据所述第一语音片段集合确定目标频谱图;
将所述目标频谱图输入基于深度学习的语音特征提取模型,得到所述目标语音对应的目标特征向量;
对所述目标特征向量进行聚类分析,得到n类特征向量,其中,n为大于或等于1的正整数;
根据所述n类特征向量确定n个对象对应的语音。
可选地,所述根据所述第一语音片段集合确定目标频谱图包括:
对所述第一语音片段集合进行短时傅里叶变换,得到所述目标频谱图。
可选地,所述根据所述n类特征向量确定n个对象对应的语音包括:
确定所述n类特征向量对应的第二语音片段集合;
确定所述第二语音片段集合的每个语音片段的时间属性;
根据所述第二语音片段集合的每个语音片段的时间属性对所述第二语音片段集合中的语音片段进行拼接,得到所述n个对象对应的语音。
可选地,所述对所述目标特征向量进行聚类分析,得到n类特征向量包括:
对所述目标特征向量进行聚类,以计算所述目标特征向量中的向量之间的余弦距离;
根据所述目标特征向量中的向量之间的余弦距离确定所述n类特征向量。
可选地,所述方法还包括:
获取语音数据集,所述语音数据集中包含m个语音数据,m为大于1的正整数;
对所述语音数据集中的每个语音数据进行切分,得到m个语音片段集合;
通过短时傅里叶变换将所述m个语音片段集合转换为m个频谱图集合;
对所述m个频谱图集合进行模型训练,得到所述基于深度学习的语音特征提取模型。
本申请第二方面提供了一种说话人语音分离装置,包括:
切分单元,用于对目标语音进行切分,得到第一语音片段集合,所述目标语音为待识别的多对象的单通道语音;
第一确定单元,用于根据所述第一语音片段集合确定目标频谱图;
处理单元,用于将所述目标频谱图输入基于深度学习的语音特征提取模型,得到所述目标语音对应的目标特征向量;
分析单元,用于对所述目标特征向量进行聚类分析,得到n类特征向量,其中,n为大于或等于1的正整数;
第二确定单元,用于根据所述n类特征向量确定n个对象对应的语音。
可选地,所述第一确定单元具体用于:
对所述第一语音片段集合进行短时傅里叶变换,得到所述目标频谱图。
可选地,所述第二确定单元具体用于:
确定所述n类特征向量对应的第二语音片段集合;
确定所述第二语音片段集合的每个语音片段的时间属性;
根据所述第二语音片段集合的每个语音片段的时间属性对所述第二语音片段集合中的语音片段进行拼接,得到所述n个对象对应的语音。
可选地,所述分析单元具体用于:
对所述目标特征向量进行聚类,以计算所述目标特征向量中的向量之间的余弦距离;
根据所述目标特征向量中的向量之间的余弦距离确定所述n类特征向量。
可选地,所述装置还包括:
训练单元,所述训练单元用于:
获取语音数据集,所述语音数据集中包含m个语音数据,m为大于1的正整数;
对所述语音数据集中的每个语音数据进行切分,得到m个语音片段集合;
通过短时傅里叶变换将所述m个语音片段集合转换为m个频谱图集合;
对所述m个频谱图集合进行模型训练,得到所述基于深度学习的语音特征提取模型。
本申请第三方面提供了一种计算机装置,包括:至少一个连接的处理器、存储器和收发器;所述存储器用于存储程序代码,所述程序代码由所述处理器加载并执行以实现上述第一方面所述的说话人语音分离方法的步骤。
本申请第四方面提供了一种计算机可读存储介质,包括指令,当所述指令在计算机上运行时,使得计算机执行上述第一方面所述的说话人语音分离方法的步骤。
综上所述,可以看出,本申请提供的实施例中,通过对语音数据集中的每个语音数据进行切分,得到m个语音片段集合;通过短时傅里叶变换将m个语音片段集合转换为m个频谱图集合;对m个频谱图集合进行模型训练,得到基于深度学习的语音特征提取模型。由此,可以快速准确的识别多人说话的单通道语音中各个对象的声音,解决了现有的无法对多人说话的单通道语音进行进一步分析的困难。
附图说明
图1为本申请实施例提供的说话人语音分离方法的流程示意图;
图2为本申请实施例提供的基于深度学习的语音特征提取模型的训练流程示意图;
图3为本申请实施例提供的说话人语音分离装置的虚拟结构示意图;
图4为本申请实施例提供的服务器的硬件结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或模块的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或模块,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或模块,本申请中所出现的模块的划分,仅仅是一种逻辑上的划分,实际应用中实现时可以有另外的划分方式,例如多个模块可以结合成或集成在另一个系统中,或一些特征向量可以忽略,或不执行,另外,所显示的或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,模块之间的间接耦合或通信连接可以是电性或其他类似的形式,本申请中均不作限定。并且,作为分离部件说明的模块或子模块可以是也可以不是物理上的分离,可以是也可以不是物理模块,或者可以分布到多个电路模块中,可以根据实际的需要选择其中的部分或全部模块来实现本申请方案的目的。
下面从说话人语音分离装置的角度对本申请的方法说话人语音分离方法进行说明,该说话人语音分离装置可以终端,也可以是服务器,还可以是服务器中的服务单元,具体不做限定。
请参阅图1,图1为本申请实施例提供的说话人语音分离方法的流程示意图,包括:
101、对目标语音进行切分,得到第一语音片段集合。
本实施例中,说话人语音分离装置可以首先获取目标语音,此处具体不限定获取的方式,该目标语音为待识别的多对象单通道的语音也即多人说话的单通道语音,之后,说话人语音分离装置可以对目标语音进行切分,得到第一语音片段集合。例如说话人语音分离装置可以将目标语音切分为1秒时长的语音片段,得到第一语音片段集合,当然也还可以根据实际情况进行切分,例如2.5秒时长的语音片段,具体不做限定。
102、根据第一语音片段集合确定目标频谱图。
本实施例中,说话人语音分离装置在对目标语音进行切分,得到第一语音片段集合之后,可以根据第一语音片段集合确定目标频谱图,具体的说话人语音分离装置可以对第一语音片段集合进行短时傅里叶变换,得到目标频谱图,也就是说,说话人语音分离装置可以通过短时傅里叶变换的方式对第一语音片段集合中的音频进行转换生成对应目标频谱图。
103、将目标频谱图输入基于深度学习的语音特征提取模型,得到目标语音对应的目标特征向量。
本实施例中,说话人语音分离装置可以将目标频谱图输入说基于深度学习的语音特征提取模型,得到目标语音对应的目标特征向量,其中,该基于深度学习的语音特征提取模型为预先通过resnet34神经网络结构以及am-soft损失函数对大量音频数据进行训练得到的模型,该模型用于对声纹特征进行提取。具体的,可以将目标频谱图输入基于深度学习的语音特征提取模型,取基于深度学习的语音特征提取模型的网络结构倒数第二层的输出结果作为该目标语音对应的特征,获得其对应的目标特征向量。
104、对目标特征向量进行聚类分析,得到n类特征向量。
本实施例中,说话人语音分离装置在通过基于深度学习的语音特征提取模型确定目标特征向量之后,可以目标特征向量进行聚类分析,得到n类特征向量,n为大于或等于1的正整数,也即需要识别多少个对象的声音,即将目标特征通过聚类分类得到介个对象对应的特征向量。具体的,对目标特征向量进行聚类,以计算目标特征向量中的向量之间的余弦距离;根据目标特征向量中的向量之间的余弦距离确定n类特征向量。也就是说,说话人语音分离装置可以对所有的特征向量使用k-means进行聚类分析,其中计算向量之间的距离使用cos余弦距离,将不同对象的声音进行分离,最后获得不同对象对应的n类特征向量。
需要说明的是,通过k-means的方式进行分类具体如下:
1、随机选取n个点,作为聚类中心;
2、计算每个点分别到k个聚类中心的聚类,然后将该点分到最近的聚类中心,这样就行成了n个簇;
3、再重新计算每个簇的质心(均值);
4、重复以上2~4步,直到质心的位置不再发生变化或者达到设定的迭代次数,得到n类特征向量。
105、根据n类特征向量确定n个对象对应的语音。
本实施例中,说话人语音分离装置在得到n类特征向量之后,可以根据n类特征向量确定n个对象对应的语音。具体的,说话人语音分离装置可以首先确定n类特征向量对应的第二语音片段集合,之后确定第二语音片段集合的每个语音片段的时间属性(可以理解的是,此处的时间属性可以是每个语音片段的开始时刻以及结束时刻,也可以是按照每个语音片段的时间先后顺序的编号,例如目标语音对应的时间为2020年8月2日19:00:05至2020年8月2日19:00:28,以预设间隔例如1秒对目标语音进行切分,得到23个语音片段,切分时,可以直接在每个语音片段中加入开始以及结束的时刻,例如2020年8月2日19:00:05至2020年8月2日19:00:06的语音片段,也可以对语音片段按照时间顺序进行编号,例如2020年8月2日19:00:05至2020年8月2日19:00:06的语音片段编号为1,以此类推,得到所有语音片段的编号或开始结束时刻,假如得到2类特征向量,一类特征向量对应的语音片段为10个,另一类特征向量对应的语音片段为13个,此处可以确定该两类特征向量的时间属性);最后可以根据第二语音片段集合的每个语音片段的时间属性对第二语音片段集合中的语音片段进行拼接,得到n个对象对应的语音,由于上述已经得到每个语音片段的时间属性(开始时刻以及结束时刻,或,按照时间顺序的编号),之后既可以按照时间的先后顺序或者编号的先后顺序进行排序得到n个对象对应的语音。
综上所述,可以看出,本申请提供的实施例中,说话人语音分离装置对目标语音进行切分,得到第一语音片段集合,根据第一语音片段集合确定目标频谱图;将目标频谱图输入基于深度学习的语音特征提取模型,得到目标语音对应的目标特征向量;对目标特征向量进行聚类分析,得到n类特征向量;根据n类特征向量确定n个对象对应的语音。由此,可以快速准确的识别多人说话的单通道语音中各个对象的声音,解决了现有的无法对多人说话的单通道语音进行进一步分析的困难。
请参阅图2,图2为本申请实施例提供的基于深度学习的语音特征提取模型的训练流程示意图,包括:
201、获取语音数据集。
本实施例中,说话人语音分离装置可以获取语音数据集,该语音数据集中包含m个语音数据,m为大于1的正整数,也就是说,说话人语音分离装置搜集大量自然场景语音数据集,例如是保险行业的客户客服电话录音pcm编码wav格式、采样率为8000的音频数据,数据量为100w个平均时长为15s的数据(含1000说话者),之后将语音数据集进行脱敏处理之后,从1000个说话者中随意抽取100个说话者的数据作为测试数据集,剩余900(也即m=900)人的音频数据作为训练数据。
202、对语音数据集中的每个语音数据进行切分,得到m个语音片段集合。
本实施例中,说话人语音分离装置可以对语音数据集进行切分,得到m个语音片段集合,例如对900个语音数据进行切分,得到900个语音片段集合,每个语音数据切分后都会有一个语音片段集合,此处以时长为2.5s对语音数据集中的语音数据进行切分,得到m个语音片段集合,当然也还可以根据实际情况调整该切分时长,例如1s,具体不做限定。
203、通过短时傅里叶变换将m个语音片段集合转换为m个频谱图集合。
本实施例中,说话人语音分离装置可以将所有语音片段使用短时傅里叶变换转换为频谱图。
204、对m个频谱图集合进行模型训练,得到基于深度学习的语音特征提取模型。
本实施例中,说话人语音分离装置在得到m个频谱图集合之后,可以对m个频谱图集合进行模型训练,得到基于深度学习的语音特征提取模型。也就是说,可以将m个频谱图集合按照2:8的比例划分成验证集和训练集(当然也还可以是其他的比例,例如1:9,具体不做限定),之后使用验证集和训练集使用resnet34神经网络模型进行训练,获得最优模型并在测试集上进行测试,最终得到基于深度学习的语音特征提取模型。
综上所述,可以看出,本申请提供的实施例中,通过对语音数据集中的每个语音数据进行切分,得到m个语音片段集合;通过短时傅里叶变换将m个语音片段集合转换为m个频谱图集合;对m个频谱图集合进行模型训练,得到基于深度学习的语音特征提取模型。由此,在将该基于深度学习的语音特征提取模型应用至说话人语音分离场景中时,可以快速准确的识别多人说话的单通道语音中各个对象的声音,解决了现有的无法对多人说话的单通道语音进行进一步分析的困难。
上面从说话人语音分离方法的角度对本申请进行说明,下面从说话人语音分离装置的角度对本申请进行说明。
请参阅图3,图3为本申请实施例提供的说话人语音分离装置的虚拟结构示意图,包括:
切分单元301,用于对目标语音进行切分,得到第一语音片段集合,所述目标语音为待识别的多对象的单通道语音;
第一确定单元302,用于根据所述第一语音片段集合确定目标频谱图;
处理单元303,用于将所述目标频谱图输入基于深度学习的语音特征提取模型,得到所述目标语音对应的目标特征向量;
分析单元304,用于对所述目标特征向量进行聚类分析,得到n类特征向量,其中,n为大于或等于1的正整数;
第二确定单元305,用于根据所述n类特征向量确定n个对象对应的语音。
可选地,所述第一确定单元302具体用于:
对所述第一语音片段集合进行短时傅里叶变换,得到所述目标频谱图。
可选地,所述第二确定单元305具体用于:
确定所述n类特征向量对应的第二语音片段集合;
确定所述第二语音片段集合的每个语音片段的时间属性;
根据所述第二语音片段集合的每个语音片段的时间属性对所述第二语音片段集合中的语音片段进行拼接,得到所述n个对象对应的语音。
可选地,所述分析单元304具体用于:
对所述目标特征向量进行聚类,以计算所述目标特征向量中的向量之间的余弦距离;
根据所述目标特征向量中的向量之间的余弦距离确定所述n类特征向量。
可选地,所述装置还包括:
训练单元306,所述训练单元306用于:
获取语音数据集,所述语音数据集中包含m个语音数据,m为大于1的正整数;
对所述语音数据集中的每个语音数据进行切分,得到m个语音片段集合;
通过短时傅里叶变换将所述m个语音片段集合转换为m个频谱图集合;
对所述m个频谱图集合进行模型训练,得到所述基于深度学习的语音特征提取模型。
综上所述,可以看出,本申请提供的实施例中,通过对语音数据集中的每个语音数据进行切分,得到m个语音片段集合;通过短时傅里叶变换将m个语音片段集合转换为m个频谱图集合;对m个频谱图集合进行模型训练,得到基于深度学习的语音特征提取模型。由此,可以快速准确的识别多人说话的单通道语音中各个对象的声音,解决了现有的无法对多人说话的单通道语音进行进一步分析的困难。
图4是本申请实施例提供的一种服务器结构示意图,该服务器400可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(centralprocessingunits,cpu)422(例如,一个或一个以上处理器)和存储器432,一个或一个以上存储应用程序442或数据444的存储介质430(例如一个或一个以上海量存储设备)。其中,存储器432和存储介质430可以是短暂存储或持久存储。存储在存储介质430的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器422可以设置为与存储介质430通信,在服务器400上执行存储介质430中的一系列指令操作。
服务器400还可以包括一个或一个以上电源426,一个或一个以上有线或无线网络接口450,一个或一个以上输入输出接口458,和/或,一个或一个以上操作系统441,例如windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm等等。
上述实施例中由服务器所执行的步骤可以基于该图4所示的服务器结构。
本申请实施例还提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时实现上述所述说话人语音分离方法的步骤。
本申请实施例还提供了一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行上述所述说话人语音分离方法的步骤。
本申请实施例还提供了一种终端设备,设备包括处理器、存储器及存储在存储器上并可在处理器上运行的程序,所述程序代码由所述处理器加载并执行以实现上述所述说话人语音分离方法的步骤。
本申请还提供了一种计算机程序产品,当在数据处理设备上执行时,适于执行上述所述说话人语音分离方法的步骤。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flashram)。存储器是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



