
 商标分类
商标分类  商标转让
商标转让 
基于深度特征与声学特征寻优融合的语音情感识别方法与流程
 2021-01-28 15:01:31|
2021-01-28 15:01:31| 380|
380| 起点商标网
起点商标网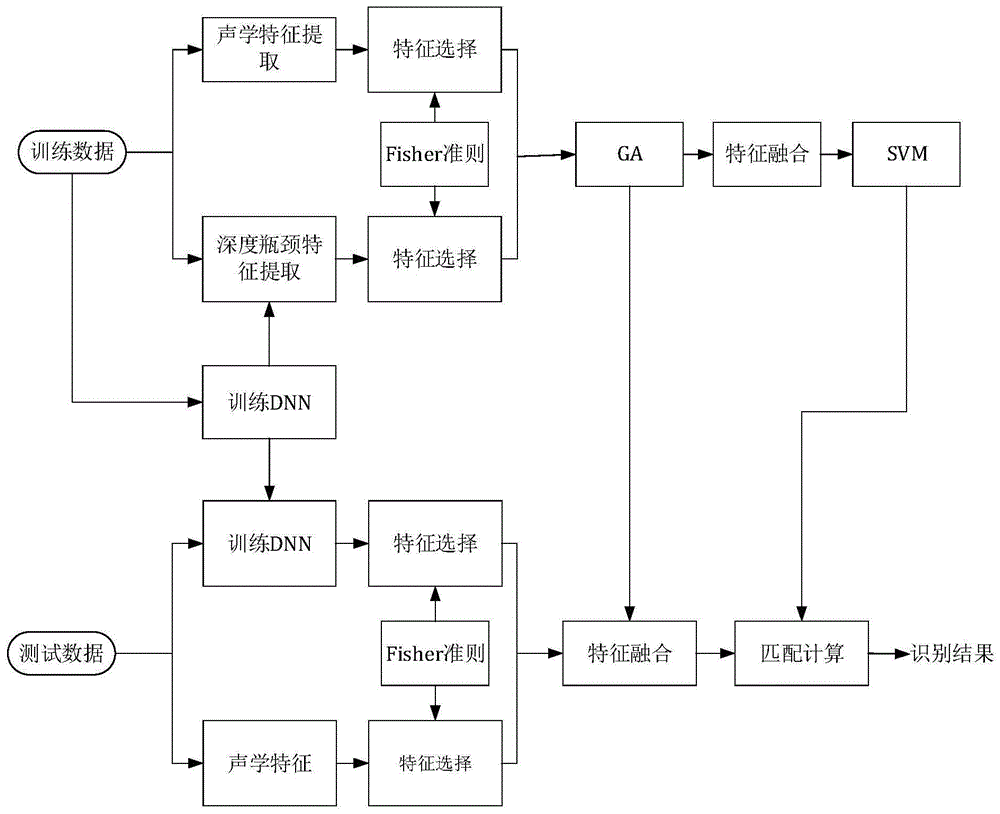
本发明属于语音识别技术领域,尤其涉及一种基于深度特征与声学特征寻优融合的语音情感识别方法。
背景技术:
随着人工智能技术的飞速发展,使机器具备和人一样的思维和情感成为网络时代的潮流和需求。实现机器与人的智能交互,其中不可或缺的一项就是让机器具备情感计算能力。语音作为人类最基本、最便捷的交流方式,承载着复杂的信息。语音信号不仅可以传递语义内容,还能反映说话人的内在情感。在具体的人机交互中,语音以其具有的自然、便捷和有效等特点成为诸多学者的重点研究内容,从而产生了语音情感识别技术。语音情感识别就是让计算机获取语音信号中的情感信息,从语音信号中提取包含情感信息的声学特征,找出这些声学特征与情感状态之间的映射关系,从而实现对说话人的情感状态分析。计算机的语音情感识别是计算机情感智能的重要组成部分,是实现智能人机交互的关键,对情感认知方向和信号处理以及信息获取等研究具有很大的研究价值和应用价值。
为建立一个高鲁棒性的语音情感识别模型,需要考虑三个问题:特征提取、模型训练和情感识别。其中,提取包含丰富语音情感信息的特征至关重要,会直接影响语音情感识别性能。因此,在本发明中重点研究了特征的提取、选择和融合。目前,用于语音情感识别的特征主要可分为声学特征和深度瓶颈特征。声学特征主要包含有mfcc、基音频率、过零率、能量幅度等。声学特征在已有的研究中被广泛使用,并能在一定的场景中达到不错的识别效果,但语音情感识别中的声学特征一般只考虑语音信号的物理层面信息,而丰富的情感信息尚未被充分提取。近年来,深度神经网络(deepneuralnetwork,dnn)成为了工业界和学术界的流行话题,由于其强大的特征提取能力和建模能力,dnn成功的将以往的识别率提升了一个档次。目前语音识别领域常用的网络包含:深度信念网络(deepbeliefnetwork,dbn)、卷积神经网络(convolutionalneuralnetwork,cnn)和循环神经网络(recurrentneuralnetwork,rnn)。在语音情感识别领域,利用深度信念网络进行情感识别可以分为两种情况:一是利用dbn进行特征提取,得到特征不同层次的表达,将特征与分类标签紧密联系在一起,挖掘语音信号深层次的情感信息从而获得区分度更高的情感特征;二是利用深度信念网络进行分类,将训练完成的深度信念网络最后的输出层改为一个分类器进行类别的直接分类,其中能实现较好效果的分类器有支持向量机(supportvectormachine,svm)。本发明即研究了dbn的这两种应用。
上述提取的声学特征和深度瓶颈特征虽然在某一场景下都能达到一定的识别效果,但是单一的特征很难完全表征语音中丰富的情感信息,在额外的场景下系统的识别率还有待提高。有鉴于此,有必要提供一种基于深度特征与声学特征寻优融合的语音情感识别方法,以期在多种语言场景下都能实现较高的识别率。
技术实现要素:
本发明为实现在多种语言场景下都能实现较高的识别率的目标,提出了一种基于深度特征与声学特征寻优融合的语音情感识别方法。与单一的传统声学特征以及深度瓶颈特征相比,本发明同时提取了深度瓶颈特征和传统声学特征,并利用遗传算法对这两种特征进行融合,在不同语言场景下都能取得较高的情感识别性能。
为实现以上目的,本发明提供了一种基于深度特征与声学特征寻优融合的语音情感识别方法,包括以下步骤:
步骤1、输入语料库中的语音信号,对语音信号进行预处理并提取语音信号的声学特征;
步骤2、提取语音信号的傅里叶系数特征,将其作为dnn输入,训练一个dnn用于提取语音信号的深度瓶颈特征;
步骤3、采用fisher准则对提取的声学特征以及深度瓶颈特征进行特征选择,降低特征冗余度,得到情感区分度高的优质特征;
步骤4、采用遗传算法实现声学特征与深度瓶颈特征的寻优融合,声学特征表征情感信息的物理层面信息,深度瓶颈特征表征与情感分类标签信息高度相关的信息,两者融合提升语音情感识别效果;
步骤5、根据寻优结果将测试数据进行组合,得到融合的测试特征集,将其作为支持向量机(supportvectormachine,svm)的输入,对svm进行训练,将训练得到的svm用于实现语音情感识别,并对所提出的基于寻优融合的语音情感识别方法进行性能评估。
本发明的进一步改进在于,所述步骤1包括:
步骤1-1:对每一句输入的时域连续语音信号进行采样,然后采用预加重、分帧加窗、端点检测技术对语音信号进行预处理,得到预处理后的信号;
步骤1-2:计算预处理后语音信号的声学特征,声学特征包括mfcc、基音频率、过零率、短时能量;
步骤1-3:计算每条语音的统计特征,即分别对每条语音的各帧信号进行统计,统计特征包含最大值、最小值、中值、方差、均值,最后得到的统计特征即是每条语音的声学特征。
本发明的进一步改进在于,所述步骤2包括:
步骤2-1:先计算预处理后语音信号的傅里叶系数特征,将得到的傅里叶系数特征作为dnn的输入;
步骤2-2:首先对dnn进行无监督的预训练,然后引入有监督的误差反向传播进行参数的微调,得到训练好的dnn模型;
步骤2-3:将所有训练语音信号重新输入到训练完成的dnn,获取dnn在第三层的输出,也即是瓶颈层的输出,此输出即是每一帧语音信号的深度瓶颈特征;
步骤2-4:计算每帧训练语音的深度瓶颈特征的统计特征,得到特征即是每条语音的深度瓶颈特征,统计特征包含最大值、最小值、均值、方差、中值。
本发明的进一步改进在于,所述步骤3包括:
步骤3-1:根据步骤1、步骤2中所得到的声学特征以及深度瓶颈特征,采用fisher准则分别计算声学特征和深度瓶颈特征中每一维特征的fisher值;
步骤3-2:将步骤3-1中由深度瓶颈特征以及声学特征得到fisher值分别进行排序,删除fisher值低于阈值p的深度瓶颈特征和声学特征,完成特征选择过程。
本发明的进一步改进在于,根据前述任一项所述的语音情感识别方法,所述步骤4包括:
步骤4-1:采用遗传算法对特征选择后的深度瓶颈特征和声学特征进行寻优融合,针对声学特征中的mfcc、短时能量、过零率、基音频率以及深度瓶颈特征分别标记为{x1,x2,x3,x4,x5},并针对每类特征赋予一个初始权值,设为{w1,w2,w3,w4,w5};
步骤4-2:将初始权值与特征的加权融合作为遗传算法输入,即输入为{w1*x1,w2*x2,w3*x3,w4*x4,w5*x5},初始化遗传算法,并设置遗传算法的目标函数为识别率,启动遗传算法对融合权值进行寻优;
步骤4-3:遗传算法输出权值寻优结果并保存,将其作为测试和训练svm数据的融合权值,声学特征和深度瓶颈特征以此权值进行加权融合。
本发明的进一步改进在于,所述步骤4-2包括:采用遗传算法对权值组合进行寻优,具体步骤如下:
a.初始化权重,对权重组合进行二进制编码,并生成初始种群;
b.解码得到权重组合,并以加权方式组合特征。将组合特征导入支持向量机进行训练,并将支持向量机获得的语音情感识别结果作为适应度函数。适应度高的个体被保留的可能性越大;
c.进行选择操作,根据适应度函数模拟适者生存规律,从群体中选取优秀个体作为父代,产生新的群体;
d.进行变异操作,从一个种群中随机选择一对个体,并交换他们的一些基因,形成新的个体;
e.对于群体中的每个个体,以一定的突变概率改变个体的基因,形成新个体加入到种群当中;
f.解码权重并计算适合度值。同时,比较子代和父代的语音情感识别率,以更新最佳个体;
g.检查迭代次数或适合度值是否满足终止条件:如果不满足,重复步骤c至f;如果满足条件,转到步骤h;
h.输出最优权重组合。
本发明的进一步改进在于,所述步骤5包括:
步骤5-1:根据步骤4中遗传算法寻优得到的权重组合,提取测试数据的声学特征和深度瓶颈特征,以此次权重组合进行加权融合;
步骤5-2:将融合得到的特征集用于svm训练,训练得到的svm实现语音情感识别。
本发明的进一步改进在于,根据步骤4中的寻优结果,将测试数据按照权值组合进行融合,可得到特征集如公式,将其输入到svm中进行训练;所述公式为:
t={w1'*x1,w2'*x2,w3'*x3,w4'*x4,w5'*x5}
训练求取svm最优超平面的目标函数为:
s.t.yi(wtxi+b)≥1-ξi,ξi≥0,i=1,2,...,n
其中,c代表惩罚系数,可以控制样本错误分类的惩罚,平衡模型的复杂性和损失误差。ξi代表松弛因子,n代表特征的维数,w代表支持向量,b为常数。
本发明的进一步改进在于,所述语音信号为wav格式。
本发明的进一步改进在于,根据公式分别计算每一维声学特征和深度瓶颈特征的fisher系数,并对fisher系数从低到高进行排序,针对声学特征只选取fisher系数大的前105维,针对深度瓶颈特征则选取fisher系数大的前100维;特征筛选后,声学特征包含105维,深度瓶颈特征包含100维;所述公式为:
其中,μ代表第d维特征的均值,σ代表第d维特征的标准差。
本发明的有益效果在于:
1、本发明提出的一种基于深度特征与声学特征寻优融合的语音情感识别方法具有一定的理论研究价值和实际应用价值。该方法通过提取语音信号的深度瓶颈特征和声学特征并进行融合的方式来弥补单一特征不能全面地表征语音情感信息的缺点,使系统性能得到了很大的提升,在不同语言情境下都能达到较高识别率。
2、本发明通过采用fisher准则对特征进行筛选,选取了对情感识别贡献度高特征,同时降低了特征的冗余度,降低了系统整体的计算复杂度。
3、本发明采用了遗传算法对特征进行寻优融合,相比于声学特征与深度瓶颈特征以1:1比例融合的方式,基于遗传算法的寻优融合可以实现更高的识别率,提升语音情感识别性能。
附图说明
图1是本发明整体的系统框图。
图2是提取深度瓶颈特征的dnn网络模型。
图3是遗传算法寻优过程图。
图4是使用emo-db时基于不同特征维度下的声学特征的平均语音情感识别率的示意图。
图5是深度瓶颈特征和傅里叶系数特征识别率对比图。
图6是不同特征融合方式下的性能对比图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
本发明主要涉及的是一种基于深度特征与声学特征寻优融合的语音情感识别方法,在实际应用中,一般提取语音信号的声学特征,将声学特征输入到分类器中进行训练,然后将训练得到的分类器模型进行情感识别。近几年,深度学习在数据挖掘,模式识别,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果,其强大的特征提取和建模能力使得模式识别的性能得到极大提升,因此,本发明将dnn应用于语音情感识别中,用于提取深度瓶颈特征,可实现更高性能的语音情感识别系统。
如图1所示,本发明利用dnn强大的特征提取能力,将傅里叶系数特征作为dnn输入,用于训练dnn,训练完成的dnn可具备提取深度瓶颈特征的能力。其主要思想是,首先将每条训练样本语音进行预处理操作,然后分别提取每帧语音信号的声学特征和深度瓶颈特征,并计算其统计特征,再采用fisher准则对这两大类特征分别进行特征选择。赋予特征选择过后的每类特征一个初始化权重,这个权重代表着每类特征对于分类识别的贡献度,并将经过加权组合的特征集输入到遗传算法进行权重组合的寻优,获取寻优后的权重组合,最后特征集以权重组合的方式输入到svm进行训练,输入处理后的相应测试数据得到最后的识别结果。经过交叉验证对比实验,基于寻优融合的语音情感识别方法相比于单独使用某类特征或采用直接融合特征的方法可以得到更佳的系统识别性能。
本发明的一种基于寻优融合的语音情感识别方法,在采用遗传算法寻优的方式融合了声学特征和深度特征后,实现了更高的语音情感识别性能,并适用于不同语音场景下的语音情感识别,进一步提升了语音情感识别系统的鲁棒性。以下是对本发明具体实施方式的详细论述:
步骤1:对输入语音信号进行预处理并提取语音信号的声学特征。
1.对语音信号进行预处理。
由于语音信号具有短时平稳特性,故在进行特征提取前需要对语音信号进行预处理,这样才能将语音信号的特征信息提取出来。预处理操作主要包含:预加重、分帧加窗、端点检测。
2.提取预处理后语音信号的声学特征,然后计算每条语音的统计特征。
提取的声学特征主要包含梅尔频率倒谱系数(melfrequencycepstrumcoefficients,mfcc)、基音频率、过零率、能量幅度这四大类,其中提取的mfcc参数提取的是其24维的系数及其一阶差分系数;然后计算每条语音的统计特征,统计特征包含最大值、最小值、均值、方差、中值等五类。提取后得到的特征维数为24*5*2,即每条语音提取的mfcc特征是240维。每条语音的基音频率、过零率、能量幅度的维数都为5维,因此,每条语音提取完声学特征后,总共包含255维特征。
步骤2:提取语音信号的傅里叶系数特征,将其作为dnn输入,用于训练dnn,训练得到的dnn可用于提取语音信号的深度瓶颈特征。
1.计算预处理后语音信号的傅里叶系数。
将预处理后的语音信号进行快速傅里叶变换得到谐波系数,计算每个谐波系数的模值得到傅里叶系数。
2.将傅里叶系数作为dnn输入,先对dnn进行无监督预训练,然后进行有监督的精细微调。
dnn每一层都是由受限玻尔兹曼机(restrictedboltzmannmachine,rbm)来实现的。本发明中,dnn训练阶段的冲量参数设置为0.9,学习速率设置为0.005,批量设置为2,迭代次数设置为50次。在训练过程中,首先将训练数据作为第一个rbm的输入,在第一层网络训练完成后,将其隐层的输出值作为下一个rbm的可见层的输入,从而训练得到第二层的rbm。以此类推,前一层的隐层输出作为下一层可见层的输入,从而实现所有rbm的预训练过程。当所有的rbm训练完成之后,将各个rbm按照层次关系叠加起来,从而得到训练好的多层网络结构。
预训练完成之后,采用基于反向传播算法(backpropagation,bp)进行精细微调,将预训练之后的各层网络的参数作为dnn网络的初始化参数,然后加上一层softmax函数输出层构成完整的dnn网络。dnn的每个输出节点对应一个类别,从而起到监督训练的目的。在使用bp算法对参数进行调优的过程中,采用交叉熵(crossentropy,ce)函数作为调优函数,并通过计算最小代价函数来对模型参数进行估计,其目标函数如下:
其中
3.获取深度瓶颈特征。
将所有训练语音信号的傅里叶系数重新输入到训练完成的dnn,获取dnn在第三层的输出,也即是瓶颈层的输出,此输出即是每一帧语音信号的深度瓶颈特征,整体提取深度瓶颈特征的dnn模型如图2,网络结构为1280-1280-100-1280-7。
4.计算每帧训练语音的深度瓶颈特征的统计特征。
计算每条语音信号的深度瓶颈特征的统计值,统计变量包含5类:最大值、最小值、均值、方差和中值。
步骤3:采用fisher准则对提取的声学特征以及深度特征进行筛选。
根据公式(2)分别计算每一维声学特征和深度瓶颈特征的fisher系数,并对fisher系数从低到高进行排序。针对声学特征只选取fisher系数大的前105维,针对深度瓶颈特征则选取fisher系数大的前100维。因此,特征筛选过后,声学特征包含105维,深度瓶颈特征包含100维。
其中,μ代表第d维特征的均值,σ代表第d维特征的标准差。
步骤4:采用遗传算法实现声学特征与深度瓶颈特征的寻优融合,整体流程如图3。
1.符号设置
声学特征总共包含4种特征,即mfcc,过零率,能量幅度和基音频率,这4种特征组成声学特征,经过特征选择后特征维度为105维,针对声学特征中的mfcc,短时能量,过零率,基音频率以及深度瓶颈特征分别标记为{x1,x2,x3,x4,x5},并针对每类特征赋予一个初始权值,设为{w1,w2,w3,w4,w5}。
2.启动遗传算法进行寻优
将初始权值与特征的加权融合作为遗传算法输入,即输入为{w1*x1,w2*x2,w3*x3,w4*x4,w5*x5},初始化遗传算法,并设置遗传算法的目标函数为识别率,设置遗传算法迭代次数为500次,种群大小为50,变异率和交叉概率分别为20%和80%。启动遗传算法对融合权值进行寻优。具体步骤如下:
a.初始化权重,对权重组合进行二进制编码,并生成初始种群。
b.解码得到权重组合,并以加权方式组合特征。将组合特征导入支持向量机进行训练,并将支持向量机获得的语音情感识别结果作为适应度函数。适应度高的个体被保留的可能性越大。
c.进行选择操作,根据适应度函数模拟适者生存规律,从群体中选取优秀个体(一组权重代表一个个体)作为父代,产生新的群体。
d.进行变异操作,从一个种群中随机选择一对个体,并交换他们的一些基因,形成新的个体。
e.对于群体中的每个个体,以一定的突变概率改变个体的基因,形成新个体加入到种群当中。
f.解码权重并计算适合度值。同时,比较子代和父代的语音情感识别率,以更新最佳个体。
g.检查迭代次数或适合度值是否满足终止条件。如果不满足,重复步骤c至f。如果满足条件,转到步骤h。
h.输出最优权重组合。
3.获取遗传算法输出的权值寻优结果,并保存为{w1',w2',w3',w4',w5'}。
步骤5:将测试数据以根据寻优结果进行组合,得到融合的测试特征集,将其作为支持向量机(supportvectormachine,svm)的输入,对svm进行训练,训练完成的svm即可完成最终的语音情感识别。
1.输入融合特征集训练svm。
根据步骤4中的寻优结果,将测试数据按照权值组合进行融合,可得到特征集如公式(3),将其输入到svm中进行训练。
t={w1'*x1,w2'*x2,w3'*x3,w4'*x4,w5'*x5}(3)
训练求取svm最优超平面的目标函数为:
s.t.yi(wtxi+b)≥1-ξi,ξi≥0,i=1,2,...,n(4)
其中,c代表惩罚系数,可以控制样本错误分类的惩罚,平衡模型的复杂性和损失误差。ξi代表松弛因子,n代表特征的维数,w代表支持向量,b为常数。
2.利用训练完成的svm进行性能评估。
实验所采用的语料库为德语柏林语音情感库(emo-db),总共包含535条语音,由5位男演员和5位女演员以不同情感的朗读10个不同的德语文本内容,所包含的情感有生气,高兴,伤心,害怕,厌恶,中性,无聊7类。语音采样频率为16khz,16bit量化,分帧时将帧长设置为256,帧移设置为128。实验环境为windows7下的64位操作系统,4g内存。本实验将语料库所有语音随机平均划分为10份,其中8份用于训练,2份用于测试,实验重复进行5次,取5次实验的平均作为最终的识别结果。
首先,为了得出在对声学特征进行特征筛选时应该保留的特征维数,本发明对特征筛选后的不同特征维数进行了性能评估,评估指标为平均识别率,分类器为svm。如图4所示,声学特征在保留105维特征时可以达到最佳性能。同时,为了验证特征选择方法的有效性,本发明对比了声学特征在不采用fisher准则进行特征选择和采用fisher准则进行特征选择时的识别效果,如表1所示,在进行特征选择后,情感识别率提升了3.88%,以此证明采用fisher准则特征能够提升语音情感识别性能。
表1使用emo-db时的声学特征语音情感识别率(%)
为获取具有最佳性能的深度瓶颈特征,本发明对比了不同网络层下的输出,采用fisher准则对其进行特征筛选,最后输入到svm中进行训练,得到识别结果。采用的网络结构有1280-100-1280-1280-7,1280-1280-100-1280-7,1280-1280-1280-100-7从表2可以看出,当瓶颈层处于第三层时,语音情感识别性能可以达到最高,为72.22%,故在后续实验中,采用此网络结构。图5对比了输入到dnn中傅里叶系数特征,dnn瓶颈层特征和特征选择后的瓶颈层特征这三种特征的性能,有实验结果可以验证得出,经过特征选择后的瓶颈层特征可以达到最佳性能。
表2瓶颈层处于网络不同位置时的语音情感识别率(%)
最后为验证本发明提出的特征融合算法的有效性,本发明对比了采用遗传算法和使用普通融合算法的性能。结果如图6所示,使用普通融合算法时,平均的语音情感识别率为80.87%,当采用基于遗传算法的特征融合方法时,7类情感的平均语音情感识别率达到了84.22%,由此可以得出本发明提出的方法能够进一步提升语音情感识别率。
以上结果表明:本发明提出的一种基于深度特征与声学特征寻优融合的语音情感识别方法能够进一步提升语音情感识别性能,相较于普通的1:1方式特征融合以及只采用声学特征进行情感识别的语音情感识别方法,本发明的方法在识别率方面可以得到极大提升,可以克服普通方法对语音情感信息描述不全面的缺点,在实际应用中具有很好的借鉴意义。
以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



