
 商标分类
商标分类  商标转让
商标转让 
一种单通道语音分离方法和装置与流程
 2021-01-28 15:01:09|
2021-01-28 15:01:09| 252|
252| 起点商标网
起点商标网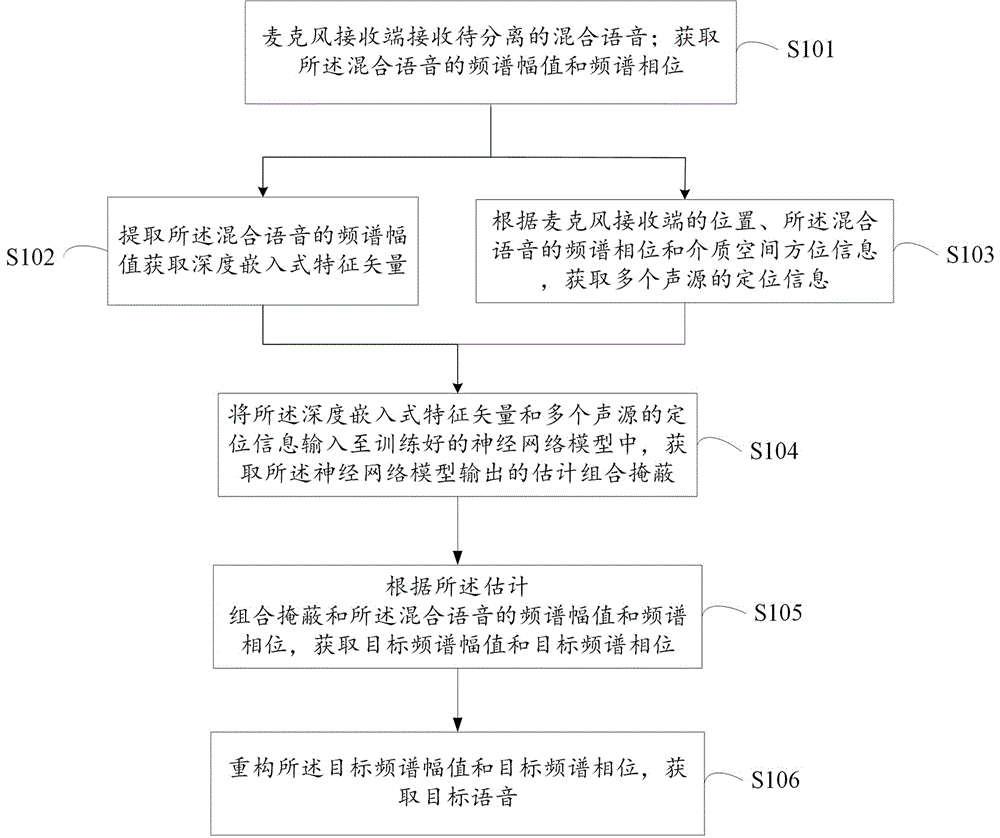
本发明涉及语音分离领域,具体为一种单通道语音分离方法和装置。
背景技术:
单通道语音分离技术在语音识别、助听器、会议记录等设备中得到广泛地应用。单通道语音分离技术是指单个麦克风接收语音信号后将其中的目标说话人与其他的说话人和背景噪音分离开的技术。随着语音分离和语音降噪技术的发展,环境噪音或其他与人声差异较大的噪音信号的分离已经取得较好的结果,但是其他目标说话人与非目标说话人的信号较为接近,因此分离的难度较高。混合语音信号分离的准确性对多种设备的应用效果至关重要,若不能提高分离的准确度,则会出现语音识别不准确、助听器传给用户错误语音信息等情况。
综上所述,针对目标说话人与非目标说话人的语音进行分离,如何进一步地提高单通道语音分离的准确度是确有必要解决的问题。
技术实现要素:
本发明的目的是提供一种单通道语音分离方法,提高混合语音中目标说话人与非目标说话人分离的准确度,提高获取目标说话人的精度。
为了实现上述目的,采用的技术方案为:一种单通道语音分离方法,包括:
s101:麦克风接收端接收待分离的混合语音;获取所述混合语音的频谱幅值和频谱相位。
s102:提取所述混合语音的频谱幅值获取深度嵌入式特征矢量。
s103:根据所述麦克风接收端的位置、所述混合语音的频谱相位和介质空间方位信息,获取多个声源的定位信息。
s104:将所述深度嵌入式特征矢量和多个声源的定位信息输入至训练好的神经网络模型中,获取所述神经网络模型输出的估计组合掩蔽。
s105:根据所述估计组合掩蔽和所述混合语音的频谱幅值和频谱相位,获取目标频谱幅值和目标频谱相位。
s106:重构所述目标频谱幅值和目标频谱相位,获取目标语音。
与现有技术相比,本发明的技术效果为:对于目标说话人语音与非目标说话人语音分离,本发明根据所述麦克风接收端的位置、所述混合语音的频谱相位和介质空间方位信息,获取混合语音中多个声源的定位信息,也就是能进一步对混合语音中的多个说话人做定位。
提取混合语音频谱幅值得到的深度嵌入式特征矢量与多个声源的定位信息结合后,本发明的关键点是额外增加了多个声源的定位信息,输入训练好的神经网络模型中得到输出的估计组合掩蔽,这样提高神经网络模型预测估计组合掩蔽的准确度,进而提高混合语音中目标说话人与非目标说话人分离的准确度。
附图说明
图1为本发明单通道语音分离方法的流程示意图。
图2为本发明单通道语音分离装置的结构示意图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述。
如图1所示,本发明一实施例为一种单通道语音分离方法,包括:
s101:麦克风接收端接收待分离的混合语音;获取所述混合语音的频谱幅值和频谱相位。
对所述混合语音时域信号加窗分帧和短时傅里叶变换得到混合语音的频谱幅值和频谱相位。
s102:提取所述混合语音的频谱幅值获取深度嵌入式特征矢量。
也就是获得低维度的具有更高分辨率的嵌入矢量,通过训练目标函数
其中,v表示深度嵌入式特征,y表示理想幅值掩蔽,
s103:根据所述麦克风接收端的位置、所述混合语音的频谱相位和介质空间方位信息,获取多个声源的定位信息。
声源所在的介质为空气,介质空间方位信息是根据声源所在位置和麦克风接收端建立的空间坐标系。麦克风接收端表面任意一点(x0,y0,z0=0)以及介质中任意位置r(x,y,z)的坐标能够确定。
声源的定位信息为声源的坐标位置和所述混合语音的频谱相位融合得到。
具体地,根据所述麦克风接收端的位置、频谱相位和介质空间方位信息,通过高斯声束法获取声源空间的声压分布状态。具体通过下述公式计算。
其中,p(r,w)为声压分布状态;
根据所述声压分布状态,获取多个声源的定位信息。
s104:将所述深度嵌入式特征矢量和多个声源的定位信息输入至训练好的神经网络模型中,获取所述神经网络模型输出的估计组合掩蔽。
换言之,神经网络模型输出的预测值即为估计组合掩蔽。
s105:根据所述估计组合掩蔽和所述混合语音的频谱幅值和频谱相位,获取目标频谱幅值和目标频谱相位。
使用掩蔽的方法进行语音增强,在频谱幅值和频谱相位中既存在噪声信号又存在干净语音信号,因此,将混合语音中噪声信号掩蔽掉剩下的就是干净语音信号。
具体地,所述估计组合掩蔽包括估计幅值掩蔽和估计相位掩蔽;根据所述混合语音的频谱幅值和估计幅值掩蔽获取目标频谱幅值;根据所述混合语音的频谱相位和估计相位掩蔽获取目标频谱相位。
s106:重构所述目标频谱幅值和目标频谱相位,获取目标语音。
将所述目标频谱幅值和目标频谱相位结合,通过短时傅里叶逆变换和帧重叠恢复得到目标语音。
对于目标说话人语音与非目标说话人语音分离,本发明根据所述麦克风接收端的位置、所述混合语音的频谱相位和介质空间方位信息,获取混合语音中多个声源的定位信息,也就是能进一步对混合语音中的多个说话人做定位。
提取混合语音频谱幅值得到的深度嵌入式特征矢量与多个声源的定位信息结合后,额外增加了多个声源的定位信息,输入训练好的神经网络模型中得到输出的估计组合掩蔽,这样提高神经网络模型预测估计组合掩蔽的准确度,进而提高混合语音中目标说话人与非目标说话人分离的准确度。
本发明中所述神经网络模型通过步骤s201至s206训练。
s201:获取训练语音样本集,所述训练语音样本集中的一条训练语音样本包括混合语音样本和干净语音样本;
s202:用16khz对训练语音样本的时域信号采样,分别获取混合语音样本时域信号y(t)和干净语音样本时域信号xi(t),(i=1,2,…,n)。
s203:对所述混合语音样本时域信号加窗分帧和短时傅里叶变换得到混合语音的幅度谱及相位谱,对所述干净语音样本时域信号加窗分帧和短时傅里叶变换得到幅度谱及相位谱;
通过加窗分帧和短时傅里叶变换分别得到混合语音样本时域信号y(t)和干净语音样本时域信号xi(t),(i=1,2,…,n)的幅度谱y(t,f)和xi(t,f)(i=1,2,…,n)、相位谱及幅度最大值。
语音信号是一个准稳态的信号,若把它分成较短的帧,每帧中可将其看作稳态信号,可用处理稳态信号的方法来处理。为了使一帧与另一帧之间的参数能够平稳过渡,应在相邻两帧之间互相有部分重叠。一般情况下,帧长取10~30ms,所以每秒的帧数约为33~100帧。帧移与帧长的比值一般取0~1/2。
将语音信号分帧后,需要对每一帧信号进行分析处理。窗函数一般具有低通特性,加窗函数的目的是减少频域中的泄漏。在语音信号分析中常用的窗函数有矩形窗、汉明窗和汉宁窗,可根据不同的情况选择不同的窗函数。本发明选择汉宁窗进行计算。
s204:根据所述混合语音样本和所述干净语音样本的幅度谱和相位谱,计算获得理想组合掩蔽,将所述理想组合掩蔽作为训练目标;
具体地,对所述混合语音样本和所述干净语音样本的幅度谱归一化处理;只对所述混合语音和所述干净语音的幅度谱归一化处理,而所述混合语音和所述干净语音的相位谱无需进行归一化处理。
根据归一化处理后的混合语音样本和所述干净语音样本的幅度谱和相位谱,获取理想组合掩蔽。理想组合掩蔽包括理想幅值掩蔽和理想相位掩蔽。
s205:根据采集训练语音样本的麦克风接收端位置、干净语音的频谱相位和介质空间方位信息,估计每个所述干净语音相应的定位信息。
具体参见上述s103的说明,此处不再赘述。
s206:将所述混合语音的幅度谱、干净语音的定位信息和作为训练目标的理想组合掩蔽输入神经网络模型中进行当次有监督训练,完成当次有监督训练后继续进行下一次训练,直至所述神经网络模型收敛。
随机初始化神经网络模型的参数,对神经网络模型进行训练,所述神经网络模型的训练阶段包括前向传播阶段和反向传播阶段。
前向传播阶段包括初始化网络神经元节点之间的权重和偏置;神经网络进行前向传播。
反向传播阶段包括计算神经网络模型的代价函数;通过梯度下降法更新神经网络模型的参数;
神经网络模型的损失函数如下所示。
其中,|y|为混合语音的幅度谱,|x|i为说话人i的幅度谱,
如图2所示,本发明另一实施例提供一种单通道语音分离装置,包括:
接收模块302,其被配置为麦克风接收端接收待分离的混合语音;获取所述混合语音的频谱幅值和频谱相位;
深度嵌入式特征提取模块304,其被配置为提取所述混合语音的频谱幅值获取深度嵌入式特征矢量;
声源定位模块306,其被配置为根据所述麦克风接收端的位置、所述混合语音的频谱相位和介质空间方位信息,获取多个声源的定位信息;
语音分离模块308,其被配置为将所述深度嵌入式特征矢量和多个声源的定位信息输入至训练好的神经网络模型中,获取所述神经网络模型输出的估计组合掩蔽;
获取模块310,其被配置为根据所述估计组合掩蔽和所述混合语音的频谱幅值和频谱相位,获取目标频谱幅值和目标频谱相位;
重构模块312,其被配置为重构所述目标频谱幅值和目标频谱相位,获取目标语音。
本实施例的单通道语音分离装置与上述单通道语音分离方法为同一发明构思,具体参见上述单通道语音分离方法的具体说明,此处不再赘述。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



