
 商标分类
商标分类  商标转让
商标转让 
一种端到端的神经网络语音识别模型的训练方法与流程
 2021-01-28 15:01:15|
2021-01-28 15:01:15| 279|
279| 起点商标网
起点商标网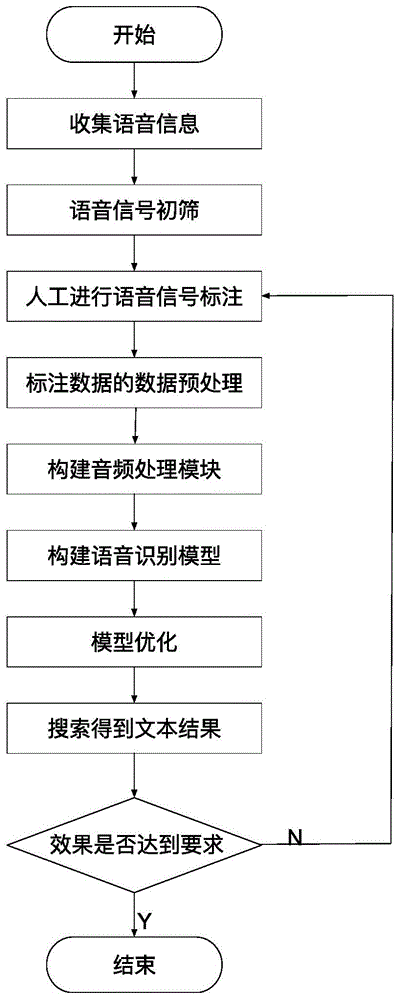
本发明涉及计算机信息处理技术领域,具体涉及一种端到端的神经网络语音识别模型的训练方法。
背景技术:
在信息技术快速发展的今天,越来越多的领域开始使用机器学习技术取代传统行业中繁杂重复且耗费人力物力的工作。例如,在线购物网站中,使用采用语音助手或者对话机器人解决客户可能遇到的常见问题,或者交通部门使用计算机视觉技术对汽车牌照进行识别工作。采用机器学习技术不仅能够有效降低生产成本,还能够保证较高的准确率。
在实际生产过程中,语音信息的转录识别是各类语音分析产品的基础工作。对音频信号的分析基础就是语音信息的转写功能。例如,语音输入法,即为直接使用语音转写模型的软件,此外,工业生产中进行的电话精准营销,大部分也需要将电话信号转化为文本信息再进行分析。
大部分传统的语音转录文字产品会基于两阶段的识别方法进行。这种方法会将语音识别任务转化为两阶段的任务,分别为语音识别任务和语言模型建模任务,在这两阶段任务中分别构建模型进行学习。在第一阶段,进行语音识别任务的时候会仅根据语音构建最可能对应的字,而在第二阶段则继续训练一个语言模型完成对语音信号直接处理之后文本的修正工作。两阶段模型在很长一段时间内都统治着语音识别引擎的世界。例如使用隐马尔可夫模型、高斯混合模型等都可以完成阶段性的任务。两阶段模型每个阶段有特定的任务目标,但是不同任务目标的优化方法并不一样。这种差异性导致其模型效果并不能保证达到最佳。而随着近些年深度模型的快速发展,另一类端到端的语音识别模型开始展现其有效性。端到端的语音识别模型主要目的是为了能够得到一个直接的从输入语音信号到输出文本信息之间的非线性变换关系。因此,将带有语音和文本的监督信息输入到模型中,可以直接地将语音信息和文本信息进行一一对应,便于在数据上直接进行迭代。而且近年来,端到端的语音识别模型由于其出色的性能,在公开数据集上得到最佳识别结果的均为端到端识别引擎,可见端到端的语音识别是非常有前景的领域。
技术实现要素:
本发明的目的在于解决传统语音转文本模型效果不佳的问题,提出了一个端到端的语音识别模型,目的在于显著提升识别效果。
为了达到上述目的,本发明提供如下技术方案:一种端到端的神经网络语音识别模型的训练方法,包括如下步骤:
步骤1、收集语音信息,并保存成音频文件;
步骤2、对音频文件进行初筛,使音量大小一致;
步骤3、通过人工对音频文件的内容进行标注,并生成数据文件;
步骤4、对标注完毕的数据进行预处理,进行特征分布;
步骤5、构建音频预处理模块,对所述音频文件进行变速、增加噪音、频域信号的扰动增强;
步骤6、使用端到端的深度学习模型构建语音识别模型;
步骤7、优化语音识别模型;
步骤8、输入的音频信号得到解码出的文本信息。
优选的,步骤4中,还包括通过随机选择标注完毕的音频文件进行抽取音频谱特征,所述音频谱特征包括但不限于使用梅尔频谱图(melbankfeatures)和短时傅立叶变换stft(shorttermfouriertransform)音频信号表示算法。
优选的,步骤6中所述的语音识别模型由transformer模型进行构建,并且在计算语音信号的同时,采用相对位置编码技术作为语音信号的补充。
优选的,所述步骤6中,对与所述transformer模型,采用n层transformer模型作为编码器,并采用m层transformer模型作为解码器来构建所述构建语音识别模型的识别引擎。
优选的,步骤6中的所述的语音识别模型分为encoder和decoder两个部分,并且学习目标为最大化的根据输入音频信号得到每一个文本的概率。
本发明有益效果:相比传统的语音识别引擎能够提升模型识别效率,对音频信号的转录结果能够达到较好的结果,高效率地将语音信号转化为文本信息,可以基本替代人工转录所需成本,更好的服务于音频内容的信息提取和数据挖掘工作。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明模型训练流程图。
具体实施方式
下面将结合本发明的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一:
根据图1所示,一种端到端的神经网络语音识别模型的训练方法包括如下步骤;
步骤1、收集语音信息,其语音输入信息可以来自各种形式,如对语音通话进行保存,既可作为语音信号信息,或者从开源数据网站上进行收集,或者对特定网站中的语音信号和字幕信息进行处理,从而得到足够进行语音识别模型训练的语音文件,然后使用wav或者mp3格式将模型文件进行保存。
步骤2、对语音信号的初筛,在语音信号收集之后,由于语音信号的差异性巨大,音量有大有小,我们将首先进行vad(语音活性检测)确定有效的语音部分,将通话中的有效录音段抽取出来作为待标注数据集。
步骤3、人工对进行标注工作;在完成语音信号的初筛工作之后,将音频进行归集,通过人工方式进行语音信号的标注工作。在进行标注之前,为了加快标注速度,将使用已有模型对给定音频进行预识别的工作。预识别将使用基础模型对待标注的数据进行识别,因此仅需人工修改识别结果即可。
在人工标注完成之后,将标注完成的数据进行归集工作,整理为一个文本文件,并分别记录标注音频文件以及标注的结果。
步骤4、对标注完毕的数据进行数据预处理工作,即对语音信号进行预提取,目的在于能够快速收集全部数据的特征分布工作。其中,将随机选择部分标注完毕的语音文件进行处理,抽取其音频谱特征。音频谱特征包括但不限于使用梅尔频谱图(melbankfeatures)和短时傅立叶变换stft(shorttermfouriertransform)等音频信号表示算法。
在得到音频频谱图之后,使用统计的方式获取全部音频文件对应频谱的分布。
例如,假设全部音频频谱信号的特征是满足高斯分布:
其中u为这些特征的平均值,而e为所有向量的协方差矩阵。在求得特征的平均值与协方差矩阵之后,我们可以预估所有音频的信号分布情况。此外,还要将所有标注使用的文本信息进行获取,通过对标注文本读取,获取全部字符作为模型的字符库。
步骤5、构建音频预处理模块,在将音频信号输入到识别模型的时,开始对音频信号进行处理,处理的方法将包括对音频进行传统的变速、增加噪音等数据增加方法以及进行频域信号的扰动增强。例如,这里我们使用了频域信号拉伸方法,将频域信号进行拉伸变换,公式为:
x′=tx
其中x代表原输入音频频域信号,t代表仿射变换,x′代表经过仿射变换之后的频域信号。通过这个仿射变换,能对音频在频域的信息添加一个微小的扰动,达到对音频数据进行增强的目的。
步骤6、构建语音识别模型,其采用端到端的深度学习模型进行构建。因此采用transformer模型进行构建。为了准确获取语音信息,在计算语音信号的同时,使用了相对位置编码技术作为语音信号的补充。对transformer模型,使用n层transformer模型作为编码器,以及m层transformer模型作为解码器构建端到端的识别引擎。
其中transformer模型的内部将包含两个结构(sub-layers),分别是多头注意力层(multiheadattention)以及全连接层(feedfrowardnetwork)。
其中多头注意力层主要由多个注意力网络构成,对第i层注意力层而言,其输入主要由q、k、v三个输入组成,其中q、k、v为与语音信号和相对位置编码信号相关的音频信息,其计算方式为:
其中hn-1为上一层的隐变量表示,在给定qi,ki,vi三个输入信号后,注意力机制计算方式为:
attention(qi,ki,vi)=softmax(qik+qiwri-j+ukj+vwri-j)
其中qi,ki,vi分别为第i层transformer的隐层表示向量,ri-j代表的是相对位置编码。多头注意力机制为使用若干个注意力机制,同时获取输入信号q、k、v的信息,进行融合,其计算方式为:
multihead(q,k,v)=concat(att1,att2,att3,...,attn)
其中atti=attentioni(q,k,v),concat代表的是将atti注意力机制得到的结果表示向量进行拼接。
transformer模型的解码器结构与编码器基本相同,但是解码器将由三个子网络其中包含两个多头注意力机制和全连接网络层,两个多头注意力将分别接受输入信号和编码器得到结果的表示向量,进而得到解码器的输出。
步骤7、语音识别模型的优化,上文提到本语音识别模型分为encoder和decoder两个部分,因为本模型使用sequence-to-sequence模型进行建模学习。因此,学习目标为最大化根据输入音频信号得到每一个文本的概率,即:
maxp(y|x′;⊙)
其中x′为上文提到的经过仿射变换的音频信号,y为文本信息。为了顺利学习的到模型的结果,本专利使用了teacherforcing技术进行学习,帮助模型快速学习得到目标文本。
步骤8、通过搜索得到文本结果
经过上文的语音识别模型的训练,可根据输入的音频信号得到解码出的文本信息。但由于模型的结构是编码器-解码器结构,因此需要选择使用集束搜索的方法进行文本序列的确定工作。这里将集束搜索的集束宽度设定为m,具体流程为:
1,输入信号x,以及起始符号<bos>,将两者同时输入编码器-解码器模型,得到第一个文字y1对应的前m个概率最大的字,将每个字按顺序放入集束中;
2、在每个集束中,根据已存在的字,于输入信号x,解码得到下一个字。具体方法为,假设模型已经处理了k个字,模型将会根据每个集束中的y1,y2,...yk以及输入信号x预测第k+1个字,yk+1。
3、当集束根据前k个字以及输入信号x预测出结束符号<eos>时,结束预测。
由于在模型训练和预测时,可使用批处理的方式进行推到。因此,在使用批处理方式进行集束搜索时,只有当批内部所有结果均出现<eos>时,才结束该批的预测工作。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



