
 商标分类
商标分类  商标转让
商标转让 
语音解析系统的制作方法
 2021-01-28 15:01:35|
2021-01-28 15:01:35| 260|
260| 起点商标网
起点商标网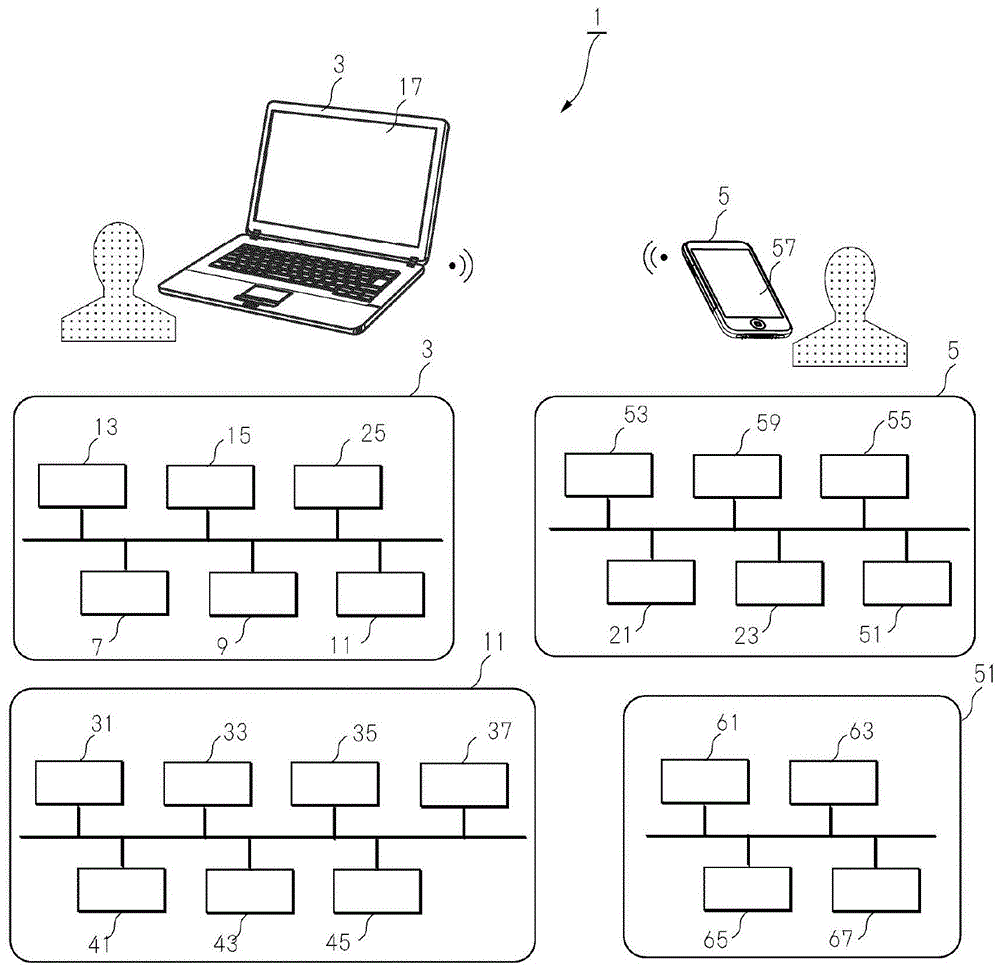
本发明涉及一种语音解析系统。若更详细地说明,涉及一种有效地利用可收录语音的多个终端而提高精确度的语音解析系统。
背景技术:
日本特开第2002-259635号公报中记载一种系统,其从讨论参加者在讨论过程做出的发言中,通过图形物件和文字的组合来显示关键词。
日本特开第2017-224052号公报中记载一种使用语音解析终端的演示评价装置。
然而,若利用1台语音解析终端将会话进行语音识别,则可将接近语音解析终端的使用者的会话较正确地进行语音解析,但有无法将远离语音解析终端的用户的会话正确地进行语音解析的问题。
现有技术文献
专利文献
专利文献1:日本特开第2002-259635号公报
专利文献2:日本特开第2017-224052号公报
技术实现要素:
发明所欲解决的课题
此说明书记载的一态样的发明,其目的在于提供一种可精确度更高地进行语音识别的语音解析系统。
解决课题的技术方案
一态样的发明,基本上基于下述知识:通过相互利用以多台语音解析装置所解析出的会话信息而进行语音识别,可精确度更高地进行语音识别。
此说明书所记载的一态样的发明,是涉及语音解析系统1。
此语音解析系统1是包含第1语音解析终端3和第2语音解析终端5的系统。此终端包含计算机,以下说明的各要素为通过计算机实现的要素。
第1语音解析终端3为包含第1用语解析部7、第1会话存储部9、解析部11、演示存储部13、相关语存储部15以及显示部17的终端。
第1用语解析部7为用于解析会话所包含的单词,获得第1会话信息的要素。
第1会话存储部9为用于存储第1用语解析部7所解析出的第1会话信息的要素。
解析部11为用于解析第1会话存储部9所存储的第1会话信息的要素。
演示存储部13为用于存储多个演示资料的要素。
相关语存储部15为用于存储与演示存储部13所存储的各演示资料相关的相关语的要素。
显示部17为可显示演示存储部13所存储的任一演示资料的要素。
第2语音解析终端5为包含第2用语解析部21和第2会话存储部23的终端。
第2用语解析部21为用于解析会话所包含的单词而获得第2会话信息的要素。第2会话存储部23为用于存储第2用语解析部21所解析出的第2会话信息的要素。
第1语音解析终端3进一步具有会话信息接收部25。
而且,会话信息接收部25为用于从第2语音解析终端5接收第2会话信息的要素。而且,第1会话存储部也存储会话信息接收部25所接收的第2会话信息。
解析部11包含:特定演示信息取得部31、会话区段取得部33、相关语提取部35以及会话区段选择部37。
特定演示信息取得部31为用于受理关于已选择特定演示资料的信息的要素,所述特定演示资料是多个演示资料中的某演示资料。
会话区段取得部33为用于分析第1会话信息中的会话区段而获得1或多个会话区段的要素。
相关语提取部35为用于提取第1会话信息及第2会话信息所包含的关于特定演示资料的相关语的要素。
会话区段选择部37为用于将会话区段取得部33所获得的各会话区段中的第1会话信息所包含的相关语的数量和第2会话信息所包含的相关语的数量进行比较,采用相关语的数量较多的一方的会话区段作为正确会话区段的要素。
语音解析系统1的优选态样为第1语音解析终端3进一步具有:时刻存储部41,其用于存储时刻时间。
此系统的第1会话信息包含:会话所包含的单词以及与各单词相关的时刻。会话区段取得部33是利用各单词的时刻信息而分析会话区段。
若会话中断,则得知讲者改变,故若单词之间空出时间则会得知会话区段改变。
语音解析系统1的优选态样为第1语音解析终端3进一步具有:频率解析部43,其解析会话所包含的语音的频率。
此系统的第1会话信息包含:会话所包含的单词以及与各单词相关的语音的频率。
会话区段取得部33是利用各单词的频率而分析会话区段。
若声音的音调改变,则得知讲者改变,故若分析各单词的语音的频率则会得知会话区段改变。
语音解析系统1的优选态样为相关语存储部15所存储的相关语包含:主讲人用相关语和听讲人用相关语。会话区段取得部33是利用会话信息所包含的主讲人用相关语和听讲人用相关语而分析会话区段。
演示方所使用的演示相关用语和听讲人方发言的用语不同,因此解析各自的用语,可区分会话区段。
语音解析系统1的优选态样为第1语音解析终端3进一步具有:错误转换用语存储部45,其存储了与多个演示资料的每一个相关的错误转换用语。
而且,解析部11在包含关于特定演示资料的错误转换用语的情况,会利用各会话区段中的未被采用作为正确会话区段的会话区段所包含的用语中与正确会话区段所包含的错误转换用语相对应的用语,修正正确会话区段所包含的用语。第1语音解析终端3及第2语音解析终端5彼此将信息互相对照,从而可获得高精确度的解析结果。
语音解析系统1的优选态样为第2语音解析终端5进一步具有:第2解析部51、第2演示存储部53、第2相关语存储部55、第2显示部57以及第2会话信息接收部59。第2会话存储部23也存储第2会话信息接收部59所接收的第1会话信息。而且,第2解析部51包含:第2特定演示信息取得部61、第2会话区段取得部63、第2相关语提取部65以及第2会话区段选择部67。
第2解析部51为用于解析第2会话存储部23所存储的第2会话信息的要素。
第2演示存储部53为用于存储作为第2语音解析终端5所存储的多个演示资料的第2演示的要素。
第2相关语存储部55为用于存储与第2演示资料的每一个相关的相关语的要素。
第2显示部57为用于显示第2演示存储部13所存储的任一演示资料的要素。
第2会话信息接收部59为用于从第1语音解析终端3接收第1会话信息的要素。
而且,第2会话存储部23也存储第2会话信息接收部59所接收的第1会话信息。
第2解析部51具有:第2特定演示信息取得部61、第2会话区段取得部63、第2相关语提取部65以及第2会话区段选择部67。
第2特定演示信息取得部61为用于受理关于已选择第2特定演示资料的信息的要素,所述第2特定演示资料是第2演示中的某演示资料。
第2会话区段取得部63为用于分析第2会话信息中的会话区段而获得1或多个会话区段的要素。
第2相关语提取部65为用于提取第1会话信息及第2会话信息所包含的关于第2特定演示资料的相关语的要素。
第2会话区段选择部67为用于将第2会话区段取得部63所获得的各会话区段中的第1会话信息所包含的相关语的数量和第2会话信息所包含的相关语的数量进行比较,采用相关语的数量较多的一方的会话区段作为正确会话区段的要素。
发明效果
此说明书可提供一种可精确度更高地进行语音识别的语音解析系统。
附图说明
图1是表示语音解析系统的构成例的方框图。
图2是表示语音解析系统的处理例的流程图。
图3是表示语音解析系统的处理例的概念图。
图4是表示语音解析系统的第2处理例的概念图。
图5是表示语音解析系统的第3处理例的概念图。
具体实施方式
以下,使用附图说明用于实施本发明的方式。本发明不受限于以下说明的方式,也包含在技艺人士可清楚得知的范围内由以下方式进行适当修正的方式。
此说明书所记载的一态样的发明是涉及语音解析系统1。语音解析系统为用于将会话等语音信息受理作为输入信息,解析所受理的语音信息,而获得会话句子的系统。语音解析系统是通过计算机实现。此外,将语音信息置换为文字信息的系统为公知系统,本发明可适当利用此种公知系统的构成。此系统可通过便携终端(便携电话等计算机终端)实现,也可通过计算机或服务器实现。
图1是表示语音解析系统的构成例的方框图。此语音解析系统1为包含第1语音解析终端3和第2语音解析终端5的系统。此终端包含计算机,以下说明的各要素为通过计算机实现的要素。
计算机具有输入输出部、控制部、运算部及存储部,各要素以可通过总线等进行信息的交换的方式连接。而且,例如,控制部读取存储在存储部的控制程序,利用存储在存储部的信息或从输入输出部输入的信息,使运算部进行各种运算。运算部所运算求出的信息,除了存储在存储部以外,也从输入输出部输出。通过这种方式,进行各种运算处理。以下说明的各要素也可与计算机的任一要素对应。
第1语音解析终端3为包含第1用语解析部7、第1会话存储部9、解析部11、演示存储部13、相关语存储部15、显示部17以及会话信息接收部25的终端。
第1用语解析部7为用于解析会话所包含的单词而获得第1会话信息的要素。例如,通过麦克风,将语音输入至第1语音解析终端3。这样一来,第1语音解析终端3将会话(语音)存储至存储部。第1用语解析部7解析会话所包含的单词而获得第1会话信息。第1会话信息是将语音调整为声音信息的信息。声音信息的例子为“jiēxiàláizhēnduìguānyútángniàobìngdexīnyàoàikèsīwàizàidejìnxíngshuōmíngtāhuìjiàngdīxuètángzhíma”。
第1会话存储部9为用于存储第1用语解析部7所解析出的第1会话信息的要素。例如,计算机的存储部发挥作为第1会话存储部9的功能。第1会话存储部9将上述声音信息存储在存储部。
解析部11为用于解析第1会话存储部9所存储的第1会话信息的要素。解析部11读取存储在存储部的声音信息,检索存储在存储部的用语,转换为适当用语。此时,具有可转换用语(同音异义词)的情况,也可选择与其他用语一同使用的频率高的用语,提高转换效率。例如,“tángniàobìng”转换为“糖尿病”。而“xīnyào”的转换候选,有“新药”或“新要”、“心钥”、“心药”。其中,选择与“糖尿病”一同出现的频率高的“新药”作为会话信息所包含的用语。这样一来,存储在存储部的声音信息被解析为“接下来针对关于糖尿病的新药xyz进行说明它会降低谑堂侄吗”的会话句子。而后,将解析出的会话句子存储在存储部。
解析部11也可利用与演示资料相关而读取的相关语,提高会话信息的解析精确度。例如,在具有“xīnyào”的会话信息的部分时,相关语有“新药”的情况下,只要解析此“xīnyào”并选择“新药”即可。若这样做,便可提高解析精确度。并且,在对于相关语先分配多种读音且在会话信息中包含其等的情况,也可选择相对应的相关语。例如,对于相关语“xyz”,读音的候选为“àikèsīwàizàide”、“àikèsīwàizéi”、“àikèsīwàizì”及“àikèsīwāizàide”。
演示存储部13为用于存储多个演示资料的要素。例如,计算机的存储部发挥作为演示存储部的功能。演示资料的例子为powerpoint(注册商标)的各页面。演示资料被存储在计算机,是可在显示部显示而对会话对象或听众进行演示的资料。
相关语存储部15为用于存储与演示存储部13所存储的各演示资料相关的相关语的要素。例如,计算机的存储部发挥作为相关语存储手段的功能。与演示资料相关的多个相关语的例子为在基于powerpoint的各页面进行说明时可能使用的用语。存储部是与powerpoint等演示资料的各页面相关,且存储多个相关语。存储部是与演示资料的信息(例如文件id或页码)相关,而存储与所述演示资料相关的多个相关语。相关语的例子为“糖尿病”、“新药”、“xyz”、“abc”(其他治疗剂的名称)、“血糖値”、“副作用”、“血糖”、“青光眼”、“视网膜病变”、“胰岛素”、“dc制药”、“附件文件”。此相关语特别优选为先列举同音异义词。在上述例子中,除了“新药”以外,优选为列举“血糖”(其他有“血塘”、“血溏”、“谑堂”、“谑螳”、“趐螳”、“狘镗”)作为相关语。通过先将同音异义词列举作为相关语,而可使解析精确度提升。
显示部17为可显示演示存储部13所存储的任一演示资料的要素。显示部17的例子为监控器或显示器。计算机会读取关于存储部所存储的演示资料的信息,在监控器或屏幕显示演示资料。以这种方式,可对会话对象或听众显示演示资料。
第2语音解析终端5为包含第2用语解析部21和第2会话存储部23的终端。例如,第1语音解析终端3为医药代表等说明人所持有的笔记本计算机等,存在于进行说明的人的附近,用于确实地收录说明人的语音。另一方面,第2语音解析终端5被设置成相较于说明人更接近听众,例如为相较于医药代表更接近医生处等,是用于更确实地收录倾听说明的人的语音。第2语音解析终端5的例子为麦克风或便携终端(如便携电话或智能手机)。第2语音解析终端5可与第1语音解析终端3进行信息的交换。信息的交换例如可以第1语音解析终端3和第2语音解析终端5直接进行的方式进行,也可以经由服务器进行信息的交换的方式进行。
第2用语解析部21为用于解析会话所包含的单词而获得第2会话信息的要素。第2会话信息的例子为“jiēxiàláizhēnduìguānyúdāngniàobìngdexīnyàoàikèsīwàizàidejìnxíngshuōmíngtāhuìjiàngdīxuètángzhíma”等。第2语音解析终端5会将从麦克风等输入的会话存储在存储部。而后,第2用语解析部21会从存储部读取会话,参考存储在存储部的用语,获得会话信息。第2会话信息的例子为“接下来针对观于当尿病的心药xyz进行说明它会降低血糖値吗?”。
第2会话存储部23为用于存储第2用语解析部21所解析出的第2会话信息的要素。存储部发挥作为第2会话存储部23的功能。亦即,第2会话信息被存储在第2语音解析终端5的存储部。第2语音解析终端5的存储部所存储的第2会话信息,例如经由第2语音解析终端5的天线等输出部而被发送往第1语音解析终端3。
这样一来,第1语音解析终端3会受理从第2语音解析终端5所发送的第2会话信息。第1语音解析终端3的会话信息接收部25为用于从第2语音解析终端5接收第2会话信息的要素。例如,第1语音解析终端3的天线发挥作为会话信息接收部25的功能。第2音会话信息会经由会话信息接收部25而被输入至第1语音解析终端3,并被存储在存储部。此时,例如,第1会话存储部只要也存储会话信息接收部25所接收到的第2会话信息即可。
解析部11包含:特定演示信息取得部31、会话区段取得部33、相关语提取部35以及会话区段选择部37。
特定演示信息取得部31为用于受理关于已选择特定演示资料的信息的要素,所述特定演示资料是多个演示资料中的某演示资料。例如,医药代表选择关于某糖尿病的新药xyz的powerpoint(注册商标)资料。这样一来,已选择此页面的信息会经由计算机的输入设备而被输入至计算机内。只要将此输入的信息设为关于已选择特定演示资料的信息即可。
会话区段取得部33为用于分析第1会话信息中的会话区段而获得1或多个会话区段的要素。会话区段取得部33也可亦分析第2会话信息中的会话区段而获得1或多个会话区段。会话区段一般为以句点(。)区隔的会话部分。会话区段也可为一句。但依据会话,有时不一定必须与书面文字相同。
例如,由“jiēxiàláizhēnduìguānyútángniàobìngdexīnyàoàikèsīwàizàidejìnxíngshuōmíngtāhuìjiàngdīxuètángzhíma”获得“jiēxiàláizhēnduìguānyútángniàobìngdexīnyàoàikèsīwàizàidejìnxíngshuōmíng”与“tāhuìjiàngdīxuètángzhíma”这2个会话区段。或,由“接下来针对关于糖尿病的新药xyz进行说明它会降低谑堂侄吗。”获得“接下来针对关于糖尿病的新药xyz进行说明。”“它会降低谑堂侄吗。”这2个会话区段。这种会话区段的取得方法是众所周知的。以下,说明会话区段的取得方法的例子(实施态样)。
语音解析系统1的优选态样为第1语音解析终端3进一步具有:时刻存储部41,其用于存储时刻或时间。此系统的第1会话信息包含:会话所包含的单词以及与各单词相关的时刻。会话区段取得部33利用各单词的时刻信息而分析会话区段。例如,在语音连续一定时间后,若无声状态持续一定时间以上,则可说是会话区段改变。若单词之间空出时间,则会得知会话区段改变。此一情况,例如,计算机的存储部会使第1会话存储部存储第1会话信息,并使时刻存储部41将关于第1会话信息的各信息的时刻建立对应而存储。这样一来,例如在解析部11解析第1会话信息时,可读取各会话信息的时刻,应求出其时间间隔。而后,读取存储在存储部的阈値,将读取的阈値和求出的时间间隔进行比较,在时间间隔较阈値更大的情况,可判断为会话区段。并且,第2语音解析终端5也优选为具有用于存储时刻或时间的第2时刻存储部。这样一来,通过将会话的时间加以对照,而可掌握第1会话信息的各区段和第2会话信息的各区段的对应关系。
语音解析系统1的优选态样为第1语音解析终端3进一步具有:频率解析部43,其解析会话所包含的语音的频率。此系统的第1会话信息包含:会话所包含的单词以及与各单词相关的语音的频率。会话区段取得部33是利用各单词的频率而分析会话区段。若声音的音调改变,则会得知讲者改变,因此若分析各单词的语音的频率则会得知会话区段改变。此一情况,也只要使其与会话信息所包含的各信息相关,并使语音的频率信息存储在存储部,解析部11读取存储在存储部的周波数信息而求出频率的变化,借此求出会话区段即可。并且,在存储部预先存储成为会话区段的用语且在会话信息中包含所述成为会话区段的用语的情况,也可判断其为会话区段。此种成为会话区段的用语的例子为“是…。”“不是吗。”“…吗。”“会成为…。”“是…吗。”“…是的。”“请让…。”“成为…。”“欸~”。
语音解析系统1的优选态样为相关语存储部15所存储的相关语包含:主讲人用相关语和听讲人用相关语。会话区段取得部33是利用会话信息所包含的主讲人用相关语和听讲人用相关语而分析会话区段。
演示的人所使用的演示相关用语和听讲人发言的用语不同,因此解析各自的用语,可区分会话区段。
相关语提取部35为用于提取第1会话信息及第2会话信息所包含的关于特定演示资料的相关语的要素。
例如,与某演示资料的资料名(存在位置)和其页数相关,并将“糖尿病”、“新药”、“xyz”、“abc”(其他治疗剂的名称)、“血糖値”、“副作用”、“血糖”、“青光眼”、“视网膜病变”、“胰岛素”、“dc制药”、“附件文件”存储在存储部,因此相关语提取部35会从存储部读取关于此等特定演示数据的相关语。而后,进行第1会话信息所包含的用语和相关语是否一致的运算处理。而后,将一致的相关语和会话信息及区段编号一同存储在存储部。
例如,第1会话信息是由2个会话区段组成,在最初的会话区段亦即“接下来针对关于糖尿病的新药xyz进行说明。”中,存在“糖尿病”“新药”及“xyz”这3个相关语。另一方面,在第1会话信息的第2个会话区段中,不存在相关语。第1语音解析终端3例如对于第1会话信息的第1个会话区段,存储“糖尿病”“新药”及“xyz”这些相关语,以及3这个数值。此外,也可对于此会话区段仅存储3这个数值,也可仅存储相关语。对于第2个会话区段或下一个第2会话信息也相同。
在第2会话信息的最初的会话区段亦即“接下来针对观于当尿病的心药xyz进行说明。”中,包含“xyz”这一个相关语。另一方面,在第2会话信息的第2个会话区段亦即“它会降低血糖値吗?”中,包含“血糖値”这1个相关语。
会话区段选择部37为用于将会话区段取得部33所获得的各会话区段中的第1会话信息所包含的相关语的数量和第2会话信息所包含的相关语的数量进行比较,采用相关语的数量较多的一方的会话区段作为正确会话区段的要素。
例如,会话区段选择部37对于第1会话信息的第1个会话区段,从存储部读取3这个数值,并对于第2会话信息的第1个会话区段,读取1这个数值。而后,进行将读取的数值进行比较的运算。结果得知相较于第2会话信息,第1会话信息中包含在第1个会话区段的相关语的数量更多。这样一来,会话区段选择部37会采用第1会话信息的第1个会话区段(例如“接下来针对关于糖尿病的新药xyz进行说明。”)作为正确会话区段。
同样地,会话区段选择部37会采用第2会话信息的第2个会话区段(“它会降低血糖値吗?”)作为正确会话区段。
语音解析系统1的优选态样为第1语音解析终端3进一步具有:错误转换用语存储部45,其存储了与多个演示资料的每一个相关的错误转换用语。
而后,解析部11在被采用作为正确会话区段的会话信息的各会话区段包含关于特定演示资料的错误转换用语的情况,会利用各会话区段中的未被采用作为正确会话区段的会话区段所包含的用语中与正确会话区段所包含的错误转换用语相对应的用语,修正正确会话区段所包含的用语。第1语音解析终端3及第2语音解析终端5彼此将信息互相对照,从而可获得高精确度的解析结果。
例如,具有“xyz”作为关于特定演示资料的相关语的情况,有“xyg”作为错误转换用语。第1会话信息的第1个会话区段为“接下来针对关于糖尿病的新药xyg进行说明。”的情况,“xyg”正确为“xyz”的可能性高。另一方面,在第2会话信息的第1个会话区段中,包含“xyz”。因此,解析部会使用第2会话区段所包含的“xyz”修正第1会话信息的第1个会话区段的错误转换用语亦即“xyg”。通过这种方式,可将“接下来针对关于糖尿病的新药xyg进行说明。”修正为“接下来针对关于糖尿病的新药xyz进行说明。”这个正确会话信息。此作业是解析部11会从存储部读取错误转换用语,并进行被判断为正确的会话区段所包含的用语和错误转换用语是否一致的运算处理。而后,在会话区段所包含的用语和错误转换用语一致的情况,读取各会话区段中的与未被采用作为正确会话区段的会话区段所包含的错误转换用语相对应的用语。而且,特别是在读取出的对应的用语为相关语的情况或为对于错误转换用语所存储的正确用语的情况,只要对此等用语进行置换处理,将已置换错误转换用语的会话区段存储在存储部,更新正确会话区段即可。
语音解析系统1的优选态样为第2语音解析终端5进一步具有:第2解析部51、第2演示存储部53、第2相关语存储部55、第2显示部57以及第2会话信息接收部59。第2会话存储部23也存储第2会话信息接收部59所接收的第1会话信息。而且,第2解析部51包含:第2特定演示信息取得部61、第2会话区段取得部63、第2相关语提取部65以及会话区段选择部67。此等各要素基本上与第1语音解析终端3对应的要素相同。
第2解析部51为用于解析第2会话存储部23所存储的第2会话信息的要素。
第2演示存储部53为用于存储作为第2语音解析终端所存储的多个演示资料的第2演示的要素。
第2相关语存储部55为用于存储与第2演示资料的每一个相关的相关语的要素。
第2显示部57为用于显示第2演示存储部13所存储的任一演示资料的要素。
第2会话信息接收部59为用于从第1语音解析终端3接收第1会话信息的要素。
而且,第2会话存储部23也存储第2会话信息接收部59所接收的第1会话信息。
第2解析部51具有:第2特定演示信息取得部61、第2会话区段取得部63、第2相关语提取部65以及会话区段选择部67。
第2特定演示信息取得部61为用于受理关于已选择第2特定演示资料的信息的要素,所述第2特定演示资料是第2演示中的某演示资料。
第2会话区段取得部63为用于分析第2会话信息中的会话区段而获得1或多个会话区段的要素。
第2相关语提取部65为用于提取第1会话信息及第2会话信息所包含的关于第2特定演示资料的相关语的要素。
会话区段选择部67为用于将第2会话区段取得部63所获得的各会话区段中的第1会话信息所包含的相关语的数量和第2会话信息所包含的相关语的数量进行比较,采用相关语的数量较多的一方的会话区段作为正确会话区段的要素。
此态样的系统的第2语音解析终端也与第1语音解析终端同样地可获得正确会话区段。因此,各要素的处理与上述态样相同。
此说明书所记载的态样是涉及一种程序。此程序为用于使计算机发挥作为第1用语解析部7、第1会话存储部9、解析部11、演示存储部13、相关语存储部15、显示部17以及会话信息接收部25的功能的程序。此程序可成为用于实现上述各态样的系统的程序。此程序也可采用安装在便携终端的应用程序的态样。
此说明书所记载的态样是涉及一种计算机可读取的信息记录介质,其存储有上述程序。信息记录介质的例子为cd-rom、dvd、软盘、存储卡及记忆棒。
图2是表示语音解析系统的处理例的流程图。图3是表示语音解析系统的处理例的概念图。在2台便携终端中安装上述程序。其中一台终端例如为医药代表的笔记本计算机,剩下的便携终端为智能手机,以容易收取对方的语音的方式放置在对方亦即医生的附近。实现上述程序的应用程序被安装在笔记本计算机或智能手机。
演示资料的选择工序(s101)
医药代表开启存储在笔记本计算机或从服务器读取的某powerpoint(注册商标)。这样一来,将关于已选择所述powerpoint(注册商标)的信息输入至计算机。
演示资料的显示工序(s102)
在笔记本计算机的显示部显示所述powerpoint(注册商标)的页面。另一方面,在智能手机的显示部也显示powerpoint(注册商标)的页面。
演示资料的相关语读取工序(s103)
另一方面,与powerpoint(注册商标)的页面相关,从存储部读取与所述页面亦即演示资料相关的相关语。读取到的相关语的例子为“糖尿病”、“新药”、“xyz”、“abc”(其他治疗剂的名称)、“血糖値”、“副作用”、“血糖”、“青光眼”、“视网膜病变”、“胰岛素”、“dc制药”、“附件文件”。
基于演示资料的会话(s104)
在医药代表与医生之间产生关于显示的资料的会话。会话可为演示,也可为说明。会话的例子为“接下来针对关于糖尿病的新药xyz进行说明。”“它会降低血糖値吗?”(图3)。
第1会话信息取得工序(s105)
笔记本计算机会收录会话并输入至计算机内。而后,解析会话所包含的单词,获得第1会话信息。解析前的第1会话信息的例子为“jiēxiàláizhēnduìguānyútángniàobìngdexīnyàoàikèsīwàizàidejìnxíngshuōmíngtāhuìjiàngdīxuètángzhíma”。笔记本计算机设置于医药代表侧,良好地收取医药代表的语音。会话信息被存储在存储部。
第1会话解析工序(s106)
例如,解析后的第1会话信息为“接下来针对关于糖尿病的新药xyz进行说明它会降低谑堂侄吗”这样的会话句子。而后,将解析出的会话句子存储在存储部。此外,也可分析此第1会话信息的会话区段。此一情况,会话区段的例子为“接下来针对关于糖尿病的新药xyz进行说明。”“它会降低谑堂侄吗。”。会话区段也可在之后的工序中分析。
第2会话信息取得工序(s107)
会话也被输入并存储至智能手机。而后,智能手机也通过启动的应用程序而解析会话。第2会话信息的例子为“jiēxiàláizhēnduìguānyúdāngniàobìngdexīnyàoàikèsīwàizàidejìnxíngshuōmíngtāhuìjiàngdīxuètángzhíma”。笔记本计算机和智能手机,在设置的位置、收音的方向等有所不同。因此,即便解析相同会话,仍会在笔记本计算机(第1语音解析终端)和智能手机(第2语音解析终端)所解析的会话中发现不同。此工序通常会与第1会话信息取得工序(s105)同时进行。
第2会话解析工序(s108)
在智能手机侧也会解析第2会话信息。第2会话信息的例子为“接下来针对观于当尿病的心药xyz进行说明它会降低血糖値吗?”。此时,也可解析会话区段。已解析会话区段的第2会话成为“接下来针对观于当尿病的心药xyz进行说明。“它会降低血糖値吗?”。第2会话信息也被适当存储在存储部。
第2会话信息发送工序(s109)
第2会话信息例如被从智能手机发送往笔记本计算机。这样一来,笔记本计算机(第1语音解析终端3)会受理从智能手机(第2语音解析终端5)发送的第2会话信息。
会话区段取得工序(s110)
也可分析第1会话信息及第2会话信息中的会话区段而获得1或多个会话区段。也可于各终端中解析会话区段。另一方面,在笔记本计算机(第1语音解析终端),针对2个终端所收录的会话信息一起分析会话区段的态样,因可在第1会话信息和第2会话信息获得对应的会话区段,故为优选。此一情况,第1会话信息的各会话区段和第2会话信息的各会话区段,会话时间应几乎相同。因此,优选为利用计时手段,匹配各区段。通过这种方式,可将第1会话信息区分区段的同时也获得对应的第2会话区段的各会话区段。
会话区段取得部33也可亦分析第2会话信息中的会话区段而获得1或多个会话区段。
第1会话信息被解析为:
“接下来针对关于糖尿病的新药xyz进行说明。”
“它会降低谑堂侄吗。”这样的会话句子。
第2会话信息被解析为:
“接下来针对观于当尿病的心药xyz进行说明。”
“它会降低血糖値吗?”这样的会话句子。
会话区段选择工序(s110)
将各会话区段中的第1会话信息所包含的相关语的数量和第2会话信息所包含的相关语的数量进行比较,将相关语的数量较多的一方的会话区段采用作为正确会话区段。
在上述例子中,将第1会话信息的第1个会话区段(例如“接下来针对关于糖尿病的新药xyz进行说明。”)采用作为正确会话区段。
同样地,将第2会话信息的第2个会话区段(“它会降低血糖値吗?”)采用作为正确会话区段。
将通过这种方式所采用的连续的会话区段存储在存储部。
连续的会话区段为“接下来针对关于糖尿病的新药xyz进行说明。”“它会降低血糖値吗?”。
图4是表示语音解析系统的第2处理例的概念图。在此例中,在第2语音解析终端中,分析会话区段,将已分析会话区段的第2会话信息送至第1语音解析终端。在此例中,为了避免会话区段的不一致,也优选为对于各会话区段使时刻信息相关连而存储,并与时刻信息一起从第2语音解析终端发送往第1语音解析终端。这样一来,在第1语音解析终端中,可使第1会话信息所包含的会话区段和第2会话信息所包含的会话区段一致。
图5是表示语音解析系统的第3处理例的概念图。在此例中,第2语音解析终端进行收音,将经数字化的会话信息发送往第1语音解析终端,第1语音解析终端进行各种解析。此外,虽未特别图示,但不仅第1语音解析终端,在第2语音解析终端中也可解析正确会话区段。
产业上的可利用性
此系统可被利用作为语音解析装置。尤其,googlemicrophone(注册商标)等语音解析装置被认为将在日后会更为普及。并且,设想使智能手机或便携终端等在使用者身边的终端中也安装语音解析装置。例如,也设想语音解析装置会收录与用户声音不同的其他噪声而不易收录使用者的声音的情况。另一方面,即便为这种情况,存在于使用者身边的终端仍有可能可适当地收录使用者的声音。这样一来,通过使用者身边的终端收录语音信息,并与语音解析装置共享语音信息,从而可精确度更高地解析语音。
附图标记说明
1语音解析系统
3第1语音解析终端
5第2语音解析终端
7第1用语解析部
9第1会话存储部
11解析部
13演示存储部
15相关语存储部
17显示部
21第2用语解析部
23第2会话存储部
25会话信息接收部
31特定演示信息取得部
33会话区段取得部
35相关语提取部
37会话区段选择部
41时刻存储部
43频率解析部
45错误转换用语存储部
51第2解析部
53第2演示存储部
55第2相关语存储部
57第2显示部
59第2会话信息接收部
61第2特定演示信息取得部
63第2会话区段取得部
65第2相关语提取部
67第2会话区段选择部
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



