
 商标分类
商标分类  商标转让
商标转让 
声源方向估计装置、声源方向估计方法及程序与流程
 2021-01-28 15:01:19|
2021-01-28 15:01:19| 341|
341| 起点商标网
起点商标网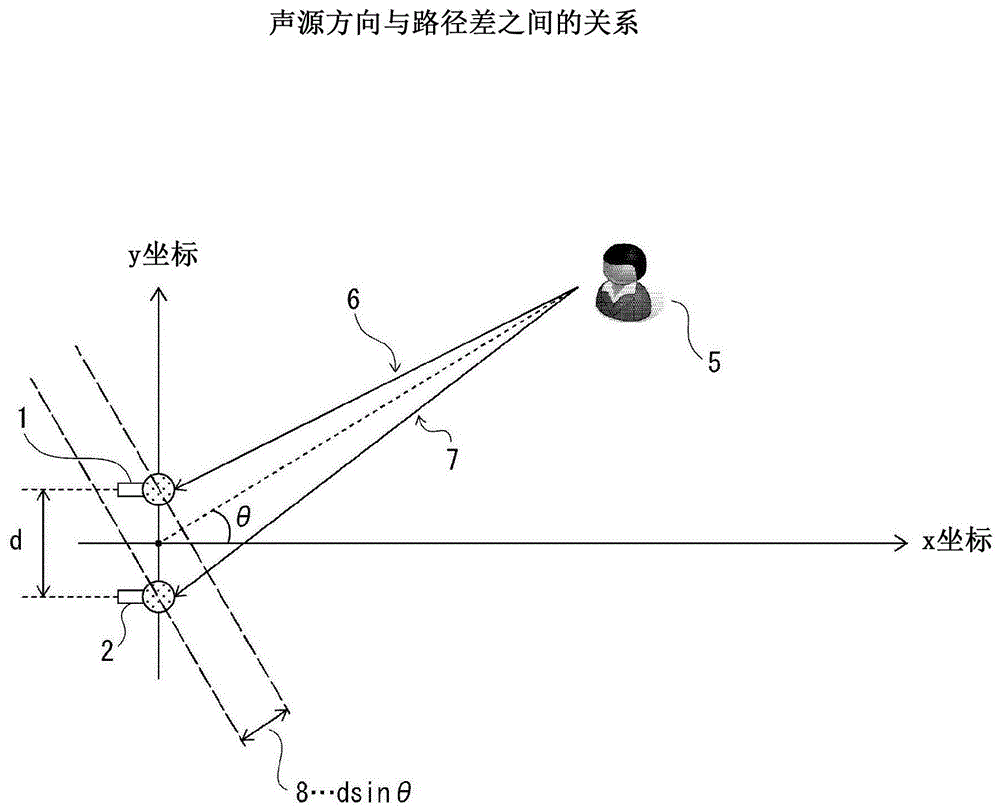
本技术涉及声源方向估计装置、声源方向估计方法及程序,具体地,涉及根据来自两个麦克风的输入估计声源的方向的技术。
背景技术:
下面的专利文献1和2是通过利用声源的稀疏性来估计用两个麦克风估计多个声源的方向的方法。
这些方法假设每频率段(frequencybin)的声源数量最多为一个。然后,针对每个频率段仅估计一个声源方向,并然后针对所有频率段执行声源方向的聚类,从而获得多个声源方向。
此外,作为使用两个麦克风支持多个声源的另一种方法,也存在另一种示例,在该示例中,在使用时频掩码执行声源分离之后,对每个分离结果执行声源方向估计,如下面的非专利文献1和2中所述。
以下的非专利文献3、4、5、以及6是引入机器学习(深度学习)的方向估计,并且使用了三个或更多个麦克风。
以下的非专利文献7描述了在声源方向估计中使用特征值的比率来选择频率段的示例。
以下的非专利文献8和9介绍了用于解决多标签问题的各种方法。
现有技术文献
专利文献
专利文献1:日本专利号4964259
专利文献1:日本专利申请公开号2007-198977
非专利文献
非专利文献1:m.i.mandelandr.j.weissandd.p.w.ellis“model-basedexpectation-maximizationsourceseparationandlocalization”,ieeetransactionsonaudio,speech,andlanguageprocessing,2010,vol.18,no.2,pp.382to394,https://www.ee.columbia.edu/toronw/pubs/taslp09-messl.pdf
非专利文献2:w.q.zhengandy.x.zouandc.ritz“spectralmaskestimationusingdeepneuralnetworksforinter-sensordataratiomodelbasedrobustdoaestimation”2015ieeeinternationalconferenceonacoustics,speechandsignalprocessing(icassp),2015,pp.325to329
非专利文献3:x.xiaoands.zhaoandx.zhongandd.l.jonesande.s.chngandh.li“alearning-basedapproachtodirectionofarrivalestimationinnoisyandreverberantenvironments”2015ieeeinternationalconferenceonacoustics,speechandsignalprocessing(icassp),2015,pp.2814to2818
非专利文献4:ryutakeda,kazunorikomatani:“soundsourcelocalizationbasedondeepneuralnetworkswithdirectionalactivatefunctionexploitingphaseinformation”icassp2016,pp.405to409,mar.23,2016。
非专利文献5:ryutakeda,kazunorikomatani“discriminativemultiplesoundsourcelocalizationbasedondeepneuralnetworksusingindependentlocationmodel”proceedingsofieeeworkshoponspokenlanguagetechnology(slt),pp.603to609,dec.16,2016。
非专利文献6:sharathadavanne,archontispolitis,tuomasvirtanen“directionofarrivalestimationformultiplesoundsourcesusingconvolutionalrecurrentneuralnetwork,”arxivpreprintarxiv:1710.10059,2017,https://arxiv.org/pdf/1710.10059.pdf
非专利文献7:mohans.,lockwoodm.e.,kramerm.l.,andjonesd.l.:“localizationofmultipleacousticsourceswithsmallarraysusingacoherencetest”j.acoust.soc.am.,123(4),2136to2147(2008),https://www.ncbi.nlm.nih.gov/pmc/articles/pmc2811542/
非专利文献8:g.tsoumakas,i.katakis,i.vlahavas“miningmulti-labeldata”dataminingandknowledgediscoveryhandbook,part6,o.maimon,l.rokach(ed.),springer,2ndedition,pp.667to685,2010.,http://lpis.csd.auth.gr/paper_details.asp?publicationid=290
非专利文献9:read,j.,perez-cruz,f.:“deeplearningformulti-labelclassification.”corrabs/1502.05988(2015),https://arxiv.org/abs/1502.05988
技术实现要素:
本发明要解决的问题
顺便提及,利用这些方法,在麦克风的数量被限制为两个的情况下,预计可以针对一个声源进行高精度的方向估计,但是针对两个或更多个混合声源进行高精度的方向估计较困难。
因此,本公开的目的是提供一种在所使用的麦克风的数量被限制为两个的状态下能够响应多个声源并且执行高精度的方向估计的技术。
问题的解决方案
根据本技术的声源方向估计装置包括:相位差计算单元,针对在一麦克风对中的每个频带计算麦克风间相位差,该麦克风对包括彼此间隔预定距离安装的两个麦克风;单声源掩码计算单元,针对麦克风对中的每个频带计算指示该频带的分量是否为单个声源的单声源掩码;以及多标签分类器,将由相位差计算单元计算出的麦克风间相位差和由单声源掩码计算单元计算的单声源掩码作为特征量输入,并且针对该特征量输出与声源方向相关联的方向标签。
即,不仅是针对麦克风对计算出的麦克风间相位差,而且针对该麦克风对计算出的单声源掩码都被输入到多标签分类器,并且输出零个以上声源方向。
可以设想到,根据上述本技术的声源方向估计装置还包括转换单元,该转换单元将由多标签分类器输出的方向标签转换为指示声源方向的声源方向信息。
即,由多标签分类器标记的方向信息被转换成声源方向信息,并且声源方向可以在输出目的地被解释。
在根据上述本技术的声源方向估计装置中,可以设想相位差计算单元和单声源掩码计算单元对来自一个麦克风对的输入执行计算。
该声源方向估计装置是通过彼此间隔预定距离安装的两个麦克风来执行与麦克风对相对应的声源方向估计的装置。
在根据上述本技术的声源方向估计装置中,可以设想,单声源掩码计算单元从来自麦克风对的预定时间长度的输入信号生成时频域中的协方差矩阵、获得协方差矩阵的特征值、并将一二值掩码作为单声源掩码,该二值掩码通过将关于最小特征值与最大特征值的比率是否低于预定阈值的二值用作掩码值来计算。
在仅存在一个声源的情况下,最小特征值取比最大特征值小得多的值,而在存在两个或更多个声源的情况下,最小特征值取接近最大特征值的值。此外,同样在没有声音的情况下,与在两个或更多声源的情况下一样,最小特征值取接近最大特征值的值。这用于生成单声源掩码。
在根据上述本技术的声源方向估计装置中,可以设想,单声源掩码计算单元从来自麦克风对的预定时间长度的输入信号计算时频域中的协方差矩阵、获得协方差矩阵的特征值、并将一软掩码作为单声源掩码,该软掩码通过将基于最小特征值与最大特征值的比率计算出的零以上且一以下的值用作掩码值来计算。
在这样计算的软掩码中,在仅存在一个声源的情况下计算接近1的掩码值,并且在存在两个或更多个声源的情况下或在没有声音的情况下计算接近零的掩码值。
在根据上述本技术的声源方向估计装置中,可以设想,多标签分类器包括与方向的分类数相同数量的二值分类器,每个二值分类器与每个方向相关联,并且当输入特征量时,与声源存在的方向相对应的零个以上的二值分类器输出真值,并且将与已输出真值的二值分类器相关联的方向标签作为声源方向。
即,使用一个称作二值相关性的分类器作为多标签分类器。
在根据上述本技术的声源方向估计装置中,可以设想,多标签分类器是神经网络并且包括一个输入层、一个输出层、以及一个或多个中间层,输入层包括输入针对每个频带的麦克风间相位差的单元和输入针对每个频带的单声源掩码的单元,输出层包括与方向的分类数相同数量的单元,并且每个单元与不同的方向相关联,输入到输入层的数据被传播到输出层,并且仅当输出层的每个单元的值超过预定阈值时,该单元才被认为已经输出真值,并且将与已经输出真值的单元相关联的方向标签作为声源方向输出。
这样,就实现了被称作二值相关性的分类器。
在根据上述本技术的声源方向估计装置中,可以设想,多标签分类器包括与彼此不同的零以上且m以下个方向的组合的总数相同数量的分类类别,其中m是可以估计的声源的数量的上限,每个类别与零个以上声源方向相关联,当特征量被输入时,将特征量分类到类别中的一个类别中,并且与分类的类别相关联的零个以上方向标签被作为声源方向输出。
即,作为多标签分类器,使用被称作修剪集的分类器。
在根据上述本技术的声源方向估计装置中,可以设想,多标签分类器是神经网络并且包括一个输入层、一个输出层、以及一个或多个中间层,输入层包括输入每个频带的麦克风间相位差的单元和输入每个频带的单声源掩码的单元,输出层包括与彼此不同的零以上且m以下个方向的组合的总数相同数量的单元,每个类别与零个以上声源方向相关联,输入到输入层的数据传播到输出层,在输出层的单元当中选择具有最大值的单元,并且与所选的单元相关联的零个以上方向标签作为声源方向输出。
因此实现了被称作修剪集的分类器。
在根据上述本技术的声源方向估计装置中,可以设想,相位差计算单元和单声源掩码计算单元对来自多个麦克风对的输入执行计算。
该声源方向估计装置是执行与如由两个麦克风组成的麦克风对那样的多个麦克风对相对应的声源方向估计的装置,该两个麦克风彼此间隔预定距离安装。
在根据上述本技术的声源方向估计装置中,可以设想,多个麦克风对中的至少两个麦克风对共享每个麦克风对中的一个麦克风。
例如,这是三个麦克风中的一个麦克风被共享以形成两个麦克风对的状态。
在根据上述本技术的声源方向估计装置中,可以设想,相位差计算单元针对在由单声源掩码计算单元计算单声源掩码时生成的协方差矩阵的右上部或左下部元素,计算复数的辐角,并且取辐角的值作为麦克风间相位差。
即,也根据协方差矩阵计算麦克风间相位差。
本发明公开了一种声源方向估计方法,在信息处理装置中,针对包括彼此间隔预定距离安装的两个麦克风的麦克风对中的每个频带计算麦克风间相位差,针对麦克风对中的每个频带计算指示该频带的分量是否为单个声源的单声源掩码,并且将计算出的麦克风间相位差和计算出的单声源掩码作为特征量输入到多标签分类器,并且针对特征量,输出与声源方向相关联的方向标签。
根据本技术的实施例的程序是使信息处理装置执行如上所述的声源的声源方向估计方法的处理的程序。
因此,执行用于信息处理装置中的声源方向估计的处理。
本发明的效果
根据本技术,可以在使用两个麦克风的限制下执行与多个声源相对应的且高精度的方向估计。
注意,这里描述的效果不必受限制,并且可以是本公开中描述的任何效果。
附图说明
图1是根据本技术的实施例的声源方向与路径差之间的关系的说明图。
图2是实施例的输入特征量的说明图。
图3是实施例的输入层的说明图。
图4是实施例的多标签分类器的说明图。
图5是实施例的多标签分类器的说明图。
图6是实施例的学习数据的说明图。
图7是实施例的声源方向估计装置的结构的框图。
图8是实施例的麦克风对的说明图。
图9是实施例的声源方向估计装置的结构的框图。
图10是实施例的特征量提取单元的框图。
图11是实施例的类别-方向转换单元的说明图。
图12是实施例的类别-方向转换单元的说明图。
图13是实施例的声源方向估计处理的流程图。
图14是实施例的特征量提取处理的流程图。
图15是实施例的短时傅立叶变换的说明图。
图16是实施例的单声源掩码计算处理的流程图。
图17是比较例的ps-dnn的说明图。
图18是评估实验的设定的说明图。
图19是实验结果的示例的说明图。
图20是合计结果的说明图。
图21是信息处理装置的框图。
具体实施方式
下文中,将按照以下顺序描述实施例。
<1.实施例的构思>
[1-1概述及相关技术]
[1-2输入特征量]
[1-3多标签分类器]
[1-4学习数据de示例]
<2.装置配置及处理示例>
[2-1配置示例]
[2-2处理示例]
[2-3效果验证]
[2-4变形例]
<3.总结和变形例>
<1.实施例的构思>
[1-1概述及相关技术]
下文中,将描述根据实施例的声源方向估计装置。这里,在描述实施例的具体配置之前,将描述实施例的技术的概述和用于理解该技术的相关技术。
本实施例的声源方向估计方法是能够通过使用一个或多个麦克风对来估计多个声源方向的方法,并且即使用两个麦克风,也能够估计多个声源的方向。
作为输入特征量,除了针对每个频率计算麦克风间相位差之外,还使用单声源掩码,该单声源掩码通过二值或连续值来表示频率是否仅包含一个声源。此外,为了输出多个声源方向,使用了能够一次向输入特征量赋予多个方向标签的多标签分类器。多标签分类器通过使用两类输入特征量和相对应的声源方向标签来进行学习。
由于单声源掩码的操作,使得其中多个声源混合并且存在复杂的相位差的频率被忽略,因此,即使用相对少量的学习数据,也可以构造支持多个声源并且具有高精度的方向估计器。
如上所述的本公开的实施例的这种技术用于估计声源方向,并且是一种能够通过使用两个麦克风针对每一帧同时估计多个(零个以上)声源方向的方法。再者,另一个特征是将声源方向估计作为基于机器学习(深度学习)的分类问题来处理。
下面将从以下两个观点描述相关技术。
a)能够用两个麦克风估计多个声源方向的方法
b)使用基于机器学习的分类器的声源方向估计
首先,将描述“a)能够用两个麦克风估计多个声源方向的方法”。
除非另有说明,否则本文提到的声源指示方向性声源(到达方向明确的声源),并且排除了全向性声源(到达方向不明确的声源)。因此,多个声源意味着多个方向性声源同时存在,并且用麦克风观察它们的混合信号。另一方面,在单个声源中包括单个方向性声源与一个或多个全向性声源的混合。
多重信号分类(music)方法是已知能够估计多个声源方向的方法,但是多重信号分类方法需要n+1个麦克风来估计n个声源方向。
换言之,两个麦克风仅可以估计一个声源方向。因此,需要另一种方法来估计两个或更多个声源方向。
由于用两个麦克风估计多个声源,因此假设声源是稀疏的。即使声源好似不断地发出声音,也可能存在在精细划分的频率中存在无声部分的情况,并且在语音的情况下这种倾向尤为显著。因此,即使两个或更多个声源好似混合,但也很有可能存在精细划分的频带中仅有单个声源的部分。
当使用这种部分执行声源方向估计时,即使针对每个频带仅可以估计单个声源方向,但也可以在所有频带中估计多个方向。
下文中,“每个精细划分的频带”被称为“窄带”,并且“所有频带”被称为“宽带”。此外,由麦克风观察到的信号被称为观察信号。
在本公开中,使用声源的稀疏性的与多个声源相对应的方向估计被分类为以下两类并进行描述。
a-1)在窄带中执行单个声源的方向估计,并然后在宽带中对声源方向进行聚类(例如,专利文献1和2)
a-2)执行使用时频掩码的声源分离,并且针对每个分离结果执行单个声源的方向估计(例如,非专利文献1和2)
首先,将描述a-1)。
为了简单起见,假设存在两个声源,并且当从麦克风处查看时,它们位于不同的方向上。当它们被称作声源a和声源b时,每个频率的混合方式和声源方向可以被分类为表1中的(1)、(2)、(3)、以及(4)这四种类型。
[表1]
在两个声源的情况下针对每个频率的混合方式和声源方向
混合方式声源方向
如果两个声源足够稀疏,则在宽带内,表1中的(1)和(2)所占的比率会增加。因此,当在宽带中对声源方向进行聚类时,生成两个聚类并且获得声源a和声源b的方向作为每个聚类的代表方向。
接下来,将描述a-2)。
使用时频掩码的声源分离是相对于在时频域中的信号(谱图)的时间和频率,保留仅所需声源所存在的时间和频率而掩蔽其它时间和频率的处理。
在表1中的两个声源的示例中,分别生成用于保留声源a的掩码和用于保留声源b的掩码,前者在保留(1)的同时掩蔽(2)、(3)以及(4),而后者在保留(2)的同时掩蔽(1)、(3)以及(4)。省略了掩码生成方法的描述。
由于通过对时频域中的麦克风观察信号施加掩码而生成的分离结果仅包括单个声源,因此理想地,根据每个分离结果估计单个声源方向。
接下来,将描述“b)使用基于机器学习的分类器的声源方向估计”。
以下,还将参考使用三个或更多个麦克风的方法和仅能够估计单个声源的方法。
用分类器进行声源方向估计的基本思想是,如果是在离散方向上的估计,则声源方向估计可以作为分类问题来解决。例如,在半圆或180°的范围内以5°的粒度估计方向的问题可以解释为在-90°、-85°、……、+85°、以及+90°的37个类别将观察信号(或由此得到的特征量)进行分类的问题。
近年来,机器学习,特别是使用深度神经网络(dnn)的分类器已被积极研究,并且存在使用基于dnn的分类器来解决声源方向估计问题的案例示例。
在非专利文献3中,针对每对麦克风计算声音波形的互相关函数,并且通过将它们的全部进行连接而获得的向量作为输入特征量输入到基于dnn的分类器中,以执行分类。
在非专利文献4中,多重信号分类方法的部分处理被基于dnn的分类器代替。
在多重信号分类方法中,从计算窄带空间方向特性(多重信号分类谱)的处理到估计宽带声源方向的处理中存在变化,但是在非专利文献4中,通过预先学习将针对所有频率的窄带空间方向特性用作输入特征量的分类器,直接获得声源方向作为分类结果。
在非专利文献4中,仅可以估计单个声源,但是在非专利文献5中,该估计扩展到多个声源。因此,作为学习数据,使用从多个声源的混合声音中导出的输入特征量和与多个声源方向相关联的标签。
此外,在真实环境中,每个声源并不总不断地发声,并且即使存在最多m个声源,但也可能在某一时刻混合的声源数量小于m,或者没有发声的声源(零个声源,即没有声音)。为了处理这种情况,准备了从零个混合声源到m个混合声源的学习数据。
在非专利文献6中,使用了两个dnn,它们是以下的dnn1和dnn2。换言之,在非专利文献5中,仅用dnn基准代替多重信号分类方法的后半处理,但在非专利文献6中,与多重信号分类方法的前半处理相对应的多重信号分类谱的生成也用dnn基准代替。
dnn1:输入针对每个麦克风生成的幅度谱图和相位谱图,并且输出与多重信号分类谱类似的空间方向特性图案。
dnn2:当输入由dnn1生成的空间方向特性图案时,链接到声源存在的方向的输出单元点燃(输出真值)。
在声源方向估计中使用机器学习的优点在于,即使输入的特征量与声源方向之间的对应关系复杂,只要有足够的学习数据,就有可能学习到这种关系。具体地,可以列举以下几个优点。
-可以直接学习从窄带中的特征量到宽带中的声源方向的对应关系。因此,可以避免空间混叠的问题(在等于或高于特定频率的频带中存在与窄带中的特征量相对应的多个声源方向并且该多个声源方向不能被唯一地指定的问题)。
-关于诸如通常导致声源方向估计的精度降低的混响、反射、以及甚至全向噪声的因素,这些因素可以包括在学习数据中,以便覆盖精度降低。
-根据麦克风与声源之间的位置关系,存在输入特征量由于声源的移动而敏感地变化的位置和输入特征量不敏感地变化的位置,并且后一个位置通常难以执行高精度的方向估计。然而,在基于机器学习的方法中,可以通过增加与这种方向相对应的学习数据来提高精度。
使用基于机器学习的分类器,特别是基于dnn的分类器的声源方向估计具有这种优点。然而,由于下述原因,难以使用两个麦克风并且进一步将它们直接应用于可以估计多个声源的方法。
非专利文献3的方法使用根据波形计算出的互相关函数作为输入特征量,但是,如果存在与要估计方向的声源不同的声源(干扰声),则无论干扰声是方向性声源还是全向性声源,该特征量都具有使估计精度降低的问题。
另一方面,非专利文献4、5、以及6的方法使用与多重信号分类方法相同(或相似)的特征量,并因此适用于与多重信号分类方法相同的限制。多重信号分类方法利用在多重信号分类谱上在与声源方向相对应的位置处形成谷或峰的性质,该性质的前提是在所有声源方向上形成零波束(低灵敏度方向特性)。然而,n个麦克风所能形成的零波束的最大数量最多在n-1个方向上,因而,如果使用两个麦克风,除了声源的数量为一个时之外,则该两个麦克风将无法形成零波束。具体地,在任何方向上都不形成清晰的零波束,或者表现出在声源不存在的方向上形成假零波束的行为。因此,根据这种多重信号分类谱不能准确估计声源方向的可能性很大。
因此,在非专利文献3、4、5、以及6的任一种方法中,在麦克风的数量被限制为两个的情况下,即使针对一个声源可以进行高精度的方向估计,但是预计针对两个或更多个声源的混合将难以进行准确的方向估计。
因此,在本实施例中,执行以下操作,以便用两个麦克风对多个(零个以上)声源执行高精度的方向估计。
-不仅以下的a),而且以下的b)也用作输入特征量。
a)麦克风间相位差(耳间或声道间相位差:ipd)
b)量表示针对每个频率计算的声源的单一性的量(单声源掩码),
-分类器,被称作多标签分类器,用于同时估计(输出)多个声源方向。
下文中,将描述输入特征量和多标签分类器中的每个,并且进一步,也将描述在多标签分类器中使用的学习数据。
[1-2输入特征量]
这里,首先,将描述麦克风间相位差(ipd),然后将指出仅将其作为特征量的不足,并且还将描述单声源掩码在实施例中用作新特征量以解决该问题。
ipd取决于从声源到每个麦克风的路径差,并且路径差取决于声源方向。
将参考图1描述该关系。
图1示出两个麦克风1和2彼此间隔距离而安装的状态。麦克风1和2都位于y轴上,并且它们之间的中点是x-y坐标的原点。连接原点和声源5的线与x轴所形成的角度是声源方向θ。
在此图中,当声源方向θ=0时,声源位于x轴上的正部分,当θ=90°时,声源位于y轴上的正部分。
此外,位于x轴下方的声源由θ的负值表示。
在图1中,声音从声源5到相应麦克风1和2的传输路径分别示出为传输路径6和传输路径7。
当0<θ≤90°时,传输路径7比传输路径6长。传输路径6与传输路径7之间的路径差8取决于声源方向θ,但是当假设从麦克风1和2到声源5的距离与距离d相比足够大、并且传输路径在任一频率下都相同时,路径差8可以近似为dsinθ(下文中,它可以被称为“路径差dsinθ”)。
由于频率和ipd与固定路径差8成比例,所以如果ipd已知,则以可获得路径差8和声源方向θ。将使用(数学公式1)描述ipd计算方法。
[数学公式1]
通过对由麦克风1和2观察到的信号应用短时傅立叶变换(stft)而获得的信号分别是x1(f,t)和x2(f,t)。stft的细节将在后面描述。
符号f和t分别是由stft生成的频率段和帧编号(索引)。
ipd可以针对每个频率段和每个帧来计算,并且其计算公式如上面的公式[1.1]或公式[1.2]所示。然而,angle(x)是计算复数x的辐角的运算符,并且辐角由从-π到+π的弧度值表示。
ipd可以从多个帧来计算,其计算公式如公式[1.3]。
在该公式中,使用从第(t-t1+1)到第t的t1个帧来计算ipd。在公式[1.3]中,具有上划线的x2(f,t-τ)表示x2(f,t-τ)的共轭复数。
将参考图2描述以这种方式计算出的ipd与声源方向θ之间的关系。
图2的a是绘制在θ=0°时ipd与频率之间的关系的图。
在该图中,ipd在某一帧编号t处,纵轴表示频率段编号f,而横轴表示ipd。一个白色圆圈表示该频率段中的ipd。然而这张图是示意性的,并且实际数据的曲线与此不同。
在图1中的θ=0°的情况下,相位差原则上为零,因为从声源5到两个麦克风的距离相等,但在实际环境中,由于混响等,ipd在某种程度上以零为中心扩展。
图2的b是θ=30°时ipd与频率之间的关系图。在θ=30°的情况下,声源5相比麦克风2更接近于麦克风1,并因此由麦克风1观察到的信号在相位上预先于由麦克风2观察到的信号。即存在相位差。由于相位差与频率成比例(即也与频率段编号f成比例),所以表示ipd的白色圆圈位于具有预定斜率的直线上。
然而,同样在这种情况下,由于混响等的影响,ipd从直线开始呈一定程度的扩展分布。
图2的c是θ=90°时的ipd与频率之间的关系图。由于路径差dsinθ与图2的b中的路径差相比较大,所以直线的斜率变得更大(在该图中表示为进一步侧向下降的直线)。
此外,波长与频率成反比,且在特定频率或更高频率下,波长的一半小于路径差dsinθ,并因此在这种频带中会发生空间混叠。在该图中,ipd在频率fa之前和之后从π跳到-π,这意味着在比频率fa更高的频带中发生了空间混叠。
因此,ipd的曲线针对每个声源方向具有不同的趋势。因此,通过使用ipd作为输入特征并通过dnn等学习ipd与声源方向之间的对应关系,可以相对容易地实现仅包括一个声源的观察信号的声源方向估计。
然而,在仅使用ipd作为特征量的情况下,难以同时且准确地估计多个声源的方向。以下将对这一点进行描述。
即使为了简单起见将声源的数量限制为两个,但针对每个频率也有四种声源混合的方式,如表1所列。每种情况下的ipd如表2中的(1)、(2)、(3)、以及(4)所示。
注意,这两个声源将被称为“声源a”和“声源b”。
[表2]
在两个声源情况下的针对每个频率段的混合方式及麦克风间相位差(ipd)
图2的d示出与表2相对应的ipd的曲线的图像。在该图中,声源a和声源b的方向分别为0°和90°。存在于与声源方向θ=0°相对应的直线la上的白色圆圈是与表2的(1)相对应的频率段,而存在于与声源方向θ=90°相对应的直线lb上的白色圆圈是与表2的(2)相对应的频率段。
其它白色圆圈c属于表2中的(3)或(4)的频率段。
当推广到任意数量的声源时,针对每个频率段的混合方式与ipd之间的关系如下所示。
a)在频率段中仅存在一个声源的情况下,ipd位于与声源方向相对应的直线上。
b)在另一频率段中(即在没有声音或在两个或更多个声源混合的频率段中),ipd具有不定值。
由于上面的b)的频率段的ipd取的值与声源方向无关,因此其成为妨碍正确估计的因素。即,正确估计多个声源方向的关键在于寻找并排除与上面的b)相对应的频率段。
例如,通过用黑色掩蔽与上面的图2的d中的b)相对应的频率段,得到图2的e,在图2的e中,与未掩蔽的情况相比,可以容易地确定未被掩蔽的剩余白色圆圈位于两条直线上。
这种仅保留一个声源以外的频率段而排除其他频率段的掩码称为“单声源掩码”。如将在后面描述,除了真-假二值(二值掩码)之外,单声源掩码还可以是连续值(软掩码)或灰度值(灰度掩码)。
在根据其中仅存在一个声源的频率段的ipd来估计多个声源方向的情况下,问题被简化为以下两点(p1)和(p2)。
(p1)如何计算单声源掩码。
(p2)在使用基于dnn的分类器的情况下,由于dnn不能排除输入数据的部分,所以如何实现等效处理。
这里,将描述点(p1)。点(p2)将在后面与多标签分类器一起描述。
可以设想各种方法以用于确定声源的数量(正确地,其中声源到达的方向的数量)是否是单个。这里,将描述使用观察到的信号协方差矩阵的特征值的方法。
单声源掩码的计算方法如(数学公式2)所描述。
[数学公式2]
频率段f和帧t的观察信号向量x(f,t)由公式[2.1]定义。
当使用该向量时,在从第(t-t2+1)到第t的t2个帧中计算的协方差矩阵cov(f,t)由公式[2.2]表示。
在此公式中,上标“h”表示厄米特转置(转置向量或矩阵,并用共轭复数代替每个元素)。
对该协方差矩阵执行特征值分解。
公式[2.3]的右侧是特征值分解的结果,其中e1(f,t)和e2(f,t)分别表示最小特征值和最大特征值,并且v1(f,t)和v2(f,t)分别表示与该特征值相对应的特征向量。由于协方差矩阵cov(f,t)的性质,e1(f,t)和e2(f,t)始终是正值。
计算协方差矩阵时所使用的帧的范围和频率段中存在的声源数量与两个特征值之间有密切的关系。在仅存在一个声源的情况下,最小特征值e1(f,t)与最大特征值e2(f,t)相比取相当小的值(即,接近零)。
另一方面,在存在两个或更多个声源的情况下,e1(f,t)取接近于e2(f,t)的值。此外,在没有声音的情况下,如同在两个或更多个声源的情况下,e1(f,t)取接近于e2(f,t)的值。
因此,通过计算最小特征值和最大特征值之间的比率并确定其值是否小于阈值,可以找出声源是否是单个声源。公式[2.4]是用于进行该确定的公式,而阈值α是接近于零的正值。
公式[2.4]是用于计算具有包括真和假两个值(二值掩码)的掩码的公式,但是该掩码可以是包括零到一的连续值的软掩码。
作为用于计算软掩码的公式,例如使用公式[2.5]。由观察信号的协方差矩阵计算出的特征值始终是正值,且最大特征值大于最小特征值。因此,公式[2.5]可以取从0到1的值。
作为掩码值,除了连续值之外,还可以使用0、1/l、2/l、…、以及1的l+1个灰度的值。(灰度掩码)
注意,在上面的示例中,麦克风的数量被限制为两个(即麦克风1和2的一个麦克风对),但是也可以扩展为多个麦克风对。在这种情况下,针对每个麦克风对计算ipd和单声源掩码。然后,如后所述,通过将所有ipd和单声源掩码级联而生成的向量作为特征量输入到分类器。
[1-3多标签分类器]
本公开的声源方向估计装置根据当时存在的声源(方向性声源)的数量来改变要输出的声源方向的数量。例如,在不存在明确的方向性声源的情况下,不输出声源方向(或输出指示“不存在声源”的特殊值)。如果一个人在该环境中说话,则输出一个声源方向,而如果另一人在该话语期间说话,则输出两个声源方向。
为了用分类器实现这种输出,本公开使用多标签分类器。多标签分类器是能够将可变数量的标签一次性给予至输入特征量的分类器。实现它的各种方案参见非专利文献8和9。
尽管在本公开中可以使用任何类型的多标签分类器,但是下面将描述该分类器具体由dnn实现的情况。
在将基于dnn的分类器用作声源方向估计器的情况下唯一的变化的位置集中在输入层和输出层中。下面将按此顺序描述输入层和输出层。
首先,将描述输入层。
在图2中,已描述了生成表示某一频率段是否仅包括一个声源的掩码(单声源掩码),并且在方向估计或分类中仅反映掩码值为1的频率段的ipd。
然而,在dnn中,不能切换要被删除或未删除的任意维度的输入数据,并因此需要考虑在分类中反映掩码的另一种方法。
此外,与将掩码应用于谱图的情况(非专利文献2等)不同,直接将掩码应用于ipd(将ipd乘以掩码值)没有意义,并因此也不可能将在应用掩码之后的ipd用作dnn的输入特征量。
因此,在dnn的输入层中,除了用于输入ipd的单元组之外,还准备用于输入单声源掩码的单元组。换言之,可以通过级联ipd与单声源掩码而形成的向量被用作dnn的输入特征量,并且使输入层的维数与向量的维度相匹配。通过使用这两种类型的特征量作为dnn的学习中的输入,还学习了具有大掩码值的频率段的ipd在分类结果中强烈反映的倾向。
因此,如果单声源掩码也被视为输入特征量中的一个,则掩码值不必是二值,并且可以是连续值或灰度值。
将参考图3描述输入层。单元组31和32两者是dnn的输入层的单元组,单元组31用于ipd33的输入,而单元组32用于单声源掩码34的输入。
单元组31和32中的一个圆表示与特定维度相对应的单元。输入到输入层的每个单元的数据传播到中间层35(dnn的第二层和后续层)。
由于ipd33和单声源掩码34是针对每个频率段计算的值,所以单元组31和单元组32中的每个的单元数量与频率段的数量相同。可替代地,针对与最低频率(0hz)和最高频率(采样频率的一半)相对应的两个频率段,相位差始终是零,并因此省略它没有问题。在这种情况下,相应单元组31和32的数量仅比频率段的数量少两个。
在上面的描述中,假设存在一个麦克风对,但是该麦克风对可以扩展到多个麦克风对。由于ipd和单声源掩码两者是针对每个麦克风对而计算的特征量,所以针对每个麦克风对准备用于输入相应特征量的单元组。
在图3中,由另一个麦克风对计算出的ipd38和单声源掩码39分别输入到专用单元组36和37。然后,输入到输入层单元的值针对所有麦克风对传播到中间层35。
接下来,将描述dnn的输出层。
存在用于解决多标签分类问题的各种方法(参见非专利文献8),并且它们中的每一种方法都可以由dnn来实现(参见非专利文献9)。方法上的差异主要表现为输出层的形式上的差异。
以下,在各种方法当中,将关注并描述被称作二值相关性(br)和修剪集(prunedset)(ps)的这两种方法。
图4示出支持被称作二值相关性(br)的方法的dnn(br-dnn)。br的特性在于准备与作为分类目的地的每个类别相关联的二值分类器。即,在将声源方向分类为n种方式的情况下,准备n个二值分类器。
在br-dnn中,存在输出层40的n个单元,该n个单元中的每个在离散方向上相关联(在图中,示出了输出层40中的部分单元41、42、43、以及44)。通过单元的输出值是否大于预定阈值来确定输出层40的每个单元表示真还是假。
下文中,当单元的输出值超过阈值时,表示为“点燃”(即输出真值)。
当多个单元在输出层40中点燃时,意味着多个声源同时存在。例如,在图4中,当两个单元(即被厚框包围的单元42和43)一起点燃时,表示声源在0°和30°都存在。
此外,当输出层40中没有单元点燃时,指示没有声音(严格地,没有方向性声源存在)。
图5示出与被称为修剪集(ps)的系统兼容的dnn(ps-dnn)。由于ps是被称为标签幂集(lps)的系统的变体,因此将首先描述标签幂集(lps)。
如果有n个声源方向,则可以考虑从0到n的声源方向的数量,并且声源方向的组合有2n种。因此,原则上,如果准备了2n个类别,则所有声源方向的组合可以由单个分类器处理。准备2的幂的类别数被称为标签幂集。
从标签幂集中准备的类别中移除与不必要的组合和低频组合相对应的类别被称为修剪集(ps)。
例如,在声源方向估计中,可以通过将可估计的声源的数量上限限制为m(0<m<n)来减少类别的数量。
在ps-dnn中,输出层具有与减少后的类别数相同数量的单元,并且该数量可由下式[3.1]计算。
[数学公式3]
nc0+nc1+nc2...ncm......[3.1]
例如,在n=37的情况下(与以5°为单位进行估计180°的情况相对应),如果m=2,则输出单元的数量为704,如果m=3,则输出单元的数量为8474。
在图5中,示出与从0到2的声源数量相对应的输出单元50(在图中,示出了输出层50中的部分单元51、52、53、54、55、以及56)。
单元51是与零个声源相对应的单元,并且当方向性声源不存在时,分类为此类别。
从单元52到单元53的单元与一个声源相对应,并且如果存在n个声源方向,则存在与该一个声源相对应的n个单元。
从单元54到单元56的单元是与两个声源相对应的单元。由于两个声源的组合是n(n-1)/2,所以存在与组合一样多的对应于两个声源的单元。
为了用ps-dnn执行方向估计,在将输入层中的数据传播到输出层之后,在输出层中搜索具有最大输出值的单元,并且假设与该单元相关联的标签作为声源方向。
例如,在图5中,具有最大输出值的单元是具有粗体框的单元55。该单元是与两个声源相对应的单元中的一个,并且与“0°”和“30°”这两个标签相关联。因此,它输出了存在两个声源且方向分别为0°和30°的估计结果。
注意,在具有最大输出值的单元是单元51的情况下,不输出声源方向。可替代地,可以输出指示“零个声源”的特殊标签。
非专利文献9还引入了与其它类型的多标签分类器兼容的dnn,并且这些也可以用在本公开中。
[1-4学习数据的示例]
接下来,将参考图6描述在dnn的学习中使用的学习数据的示例。图6的a表示零个声源的学习数据、图6的b表示一个声源的学习数据、以及图6的c表示两个声源的学习数据。在图6的a、图6的b、以及图6的c中的每个图中,左列表示作为输入特征量的ipd和单声源掩码,而右列表示作为教师数据的标签。在本示例中,存在一个麦克风对。此外,单声源掩码是具有两个值的二值掩码,并且“0”和“1”分别由黑线和白线表示。
学习数据6-1和6-2是与零个声源(不存在明确的方向性声源的情况)相对应的学习数据。在零个声源的情况下,ipd取接近随机的值,而单声源掩码在大多数频率段中具有为“0”的值。
学习数据6-1是根据实际记录的声音数据生成的特征量,而学习数据6-2是通过模仿该特征量而在计算机上生成的特征量。关于标签,给出了表示零个声源的特殊标签,但在实际学习中,根据多标签分类器的类型,它在转换成适当的值之后使用。(类似于表中其他标签。)
学习数据6-3至6-6是与一个声源相对应的学习数据,学习数据6-3和6-4表示-90°的声源,而学习数据6-5和6-6表示0°的声源。
如上所述,在一个声源的情况下,由于ipd和频率段编号成比例,所以可以在ipd的曲线中看到位于直线上的点。
然而,学习数据还包括由混响等引起的分布的扩展、源自空间混叠的跳变等。
即使仅存在一个声源,但由于频率段,也可能几乎不存在声音。在这种频率段中,ipd具有随机值,并且单声源掩码的值为“0”。
学习数据段6-7至6-10是与两个声源相对应的学习数据。学习数据6-7和6-8表示声源存在于-75°和30°处,而学习数据6-9和6-10表示声源存在于-90°和0°。
如果建立了声源的稀疏性,则在以这种方式的ipd的曲线中可以看到两条直线。在两个声源一起存在的频率段中、或者在两个声源都是静音的频率段中,ipd具有随机值,并且单声源掩码的值为“0”。
在图6中,为同一标签(或标签组)列出了两段学习数据,但为实际学习准备了数量更大的学习数据段。
此外,准备学习数据,以便针对每个数量的声源覆盖声源方向的所有可能组合。
<2.装置配置和处理示例>
[2-1配置示例]
图7示出根据本实施例的声源方向估计装置的配置示例。
图7中的配置例如形成为在诸如微型计算机的信息处理装置中的硬件或软件的处理模块。
图7示出为每个麦克风对pr准备的两个模块组70。
麦克风对pr是图1所示的麦克风1和2的配对。
在图7的情况中,例如,麦克风对pr1由麦克风1-1和2-1形成,麦克风对pr2由麦克风1-2和2-2形成。
针对这些麦克风对pr中的每个形成模块组70。
在以这种方式设置多个麦克风对pr的情况下,麦克风1-1、1-2…统称为麦克风1,而麦克风2-1、2-2…统称为麦克风2。
每个模块组70设置有两个麦克风1和2、连接到麦克风1和2中的每个的ad转换单元72和73、以及特征量提取单元74。特征量提取单元74的细节将在后面描述。
在声源方向估计装置包括多个麦克风对pr的情况下,与每个麦克风对pr相对应地设置具有这种配置的模块组70。
例如,图8的a示出设置有八个麦克风(麦克风1(1-1、1-2、1-3、1-4)和麦克风2(2-1、2-2、2-3、2-4))从而形成麦克风对pr1、pr2、pr3、以及pr4的情况。
在这种情况下,形成四个模块组70以分别与麦克风对pr1、pr2、pr3、以及pr4相对应。
注意,如在图7和图8的a的示例中,整个装置所需的麦克风的数量基本上是麦克风对的数量的两倍,但是也可以在麦克风对pr之间共享麦克风。
例如,图8的b示出由三个麦克风1、2以及3形成三个麦克风对pr1、pr2、以及pr3的示例。
由此通过两个麦克风对共享一个麦克风,可以减少在整个装置中使用的麦克风的数量。
同样在图8的b的情况中,针对麦克风对pr1、pr2、以及pr3中的每个形成模块组70。
当然,在形成如图7所示的两个模块组70的情况下,可以使用图8的b中的麦克风对pr1和pr2。因此,在采用图7中的配置的情况下,至少存在三个麦克风就足够了。
图7中的分类单元76接收由相应的特征量提取单元74生成的两种类型的特征量(ipd和单声源掩码),并将它们分类到与声源方向相对应的类别。换言之,给出了指示声源方向的标签。
具体地,使用图4中描述的二值相关型多标签分类器、图5中描述的修剪集型多标签分类器等作为分类单元76。
类别-方向转换单元77将分类单元76的分类结果转换为声源方向信息。细节将在后面描述。
控制单元79控制作为特征量提取单元74、分类单元76、以及类别-方向转换单元77的模块。
注意,已针对具有多个麦克风对pr的情况进行了以上描述,但是如果作为本实施例的声源方向估计装置,提供至少一个麦克风对pr就足够了。
这种情况下的配置如图9所示,在该配置中设置有用于由麦克风1和2构成的麦克风对pr的模块组70,并且特征量提取单元74生成两种类型的特征量。然后,在该配置中,分类单元76将它们分类为与声源方向相对应的类别,并且类别-方向转换单元77根据分类结果获得声源方向信息。
接下来,将参考图10描述特征量提取单元74的细节。
特征量提取单元74的输入是从分别连接到两个麦克风1和2的ad转换单元72和73输出的信号(观察信号)。在特征量提取单元74中,这些观察到的信号被输入到短时傅立叶变换单元83和84。
短时傅立叶变换单元83和84分别对观察信号应用短时傅立叶变换,以便生成时频域中的观察信号(观察信号谱图)。
观察信号缓冲器单元85存储生成特征量所需的时间长度的观察信号。
在ipd中使用t1个帧的观察信号(参见(数学公式1))并且在单声源标志中使用t2个帧的观察信号(参见(数学公式2)),并因此存储具有较大帧数的观察信号。
麦克风间相位差计算单元86计算麦克风间相位差。
单声源掩码计算单元87计算单声源掩码。即,在麦克风对pr中,针对每个频率段计算声源的数量为1的程度,并且生成指示该麦克风对pr的频带的分量是否为单个声源的单声源掩码。
接下来,将参考图11和图12描述类别-方向转换单元77。
基本上,该模块是转换表,并且描述用于将从分类单元76输出的类别id转换为声源方向信息的对应关系。
由于类别id根据分类器76的类型而不同,所以转换表的内容取决于分类器76的类型。
图11是作为与图4中的br-dnn一起使用的集合的转换表。br-dnn具有与方向的分类数相同数量的输出单元,并且输出具有超过预定阈值的输出值的单元的编号作为类别id。
因此,图11中的转换表仅描述与每个类别id相关联的一个声源方向信息。
图12是作为与图5中的ps-dnn一起使用的集合的转换表。ps-dnn的输出单元的数量取决于可同时被估计的声源数m。ps-dnn输出具有最大输出值的输出单元的编号作为类别id。类别id本身是一个,但是与其相关联的声源方向是0至m。
因此,在图12中的转换表中,针对每个类别id描述了零个以上声源方向的信息。
注意,在此图中,第一类别id是与零个声源相对应的类别,并且描述了“零个声源”的特殊值,但它可以仅简单地为空。
[2-2流程示例]
将参考图13中的流程图描述具有上面的配置的声源方向估计装置中的声源方向估计处理。
该处理是基于控制单元79的控制由每个模块执行的处理。
步骤s101至s104是针对麦克风对pr的循环,并且针对麦克风对pr的数量执行步骤s102和s103。
在步骤s102的ad转换处理中,声源方向估计装置将输入到形成麦克风对pr的每个麦克风1和2的模拟声音信号转换成数字声音波形。
在步骤s103的特征量提取处理中,声源方向估计装置根据一帧或更多帧的观察信号生成两种类型的特征量(ipd和单声源掩码)。细节将在后面描述。
以这种方式为每个麦克风对pr生成的所有特征量被输入到dnn(分类单元76),并且在步骤s105中被分类。作为分类的结果,获得类别id。
接下来,在步骤s106中,声源方向估计装置将每个类别id转换成与其相关联的声源方向信息。
当要继续处理时,处理从步骤s107返回到s101,而当要结束处理时,处理在步骤s107结束。
将参考图14中的流程图描述步骤s103中的特征量提取的细节。
在步骤s201中,声源方向估计装置对麦克风1和2中的每个的观察信号波形执行短时傅立叶变换,以生成时频域中的观察信号(观察信号谱图)。细节将在后面描述。
接下来,在步骤s202中,声源方向估计装置将观察信号累积到用于后续的特征量生成所必需的量。
使用这样累积的观察信号,计算出两种类型的特征量。即,声源方向估计装置在步骤s203中计算单声源掩码,并且在步骤s204中计算麦克风间相位差(ipd)。
注意,可以首先执行步骤s203和s204的两个计算中的任一个,或者可以并行执行这两个计算。单声源掩码的计算将在后面描述。
将参考图15描述上面的步骤s201中的短时傅立叶变换的细节。
每个麦克风1和2的观察信号的波形在图15的最上部示出,该观察信号通过图13中的步骤s102中的ad转换处理获得。
在短时傅立叶变换中,从麦克风1和2中的每个的观察信号的波形切出固定长度,并且对它们应用诸如汉宁窗或汉明窗的窗函数。
该切出的单元叫做帧。在该图中,帧154被例示为切口范围。
通过对一帧的数据应用短时傅立叶变换,获得时频域中的xk(1,t)至xk(k,t)以作为观察信号157。这里,k是麦克风的编号,t是帧编号,k是频率段的总数。
切割的帧之间可以存在重叠。例如,设定诸如帧153至155的重叠切出范围。以这种方式,信号在时频域中的变化在连续帧之间变得平滑。
将时频域中的信号按时间方向和频率方向排列的一种数据结构称为谱图。在所示的频谱图中,横轴表示帧编号,而纵轴表示频率段编号,并且分别根据从153至155生成时频域中的观察信号156至158。
接下来,将使用图16中的流程图描述单声源掩码的计算(图14中的步骤s203)。
在步骤s301中,声源方向估计装置使用上面的公式[2.2]计算观察信号的协方差矩阵。
接下来,在步骤s302中,声源方向估计装置对观察信号的协方差矩阵应用特征值分解。特征值分解的如公式[2.3]所示,但由于特征向量未用在特征量的计算中,所以在公式[2.3]中仅需要计算两个特征值e1(f,t)和e2(f,t)。
最后,声源方向估计装置在步骤s303中计算掩码值。在使用具有两个值的掩码(二值掩码)的情况下,使用公式[2.4]计算掩码值。此外,在使用具有连续值的掩码(软掩码)的情况下,使用公式[2.5]进行计算。
如参考上面的图13、图14、以及图15所描述,在本实施例的声源方向估计装置中实现声源方向估计处理。
[2-3效果验证]
本实施例的特征在于输入特征量,并且除了麦克风间相位差(ipd)之外,还针对每个频率计算表示是否存在一个声源的单声源掩码,并且这两者都被输入到多标签分类器,从而执行多个声源的方向估计。
通过实验已经确认,单声源掩码针对多个声源的方向估计是有效的,并且该效果将被示出为实施例的效果。
实验中使用的多标签分类器是图5中的ps-dnn。所估计的方向为37个方向(以5°为单位对从-90°到90°进行划分)。
最大可同时估计的声源数为2个,并且输出层中的单元的数量为704个。输入层中的单元的数量为257×2=514,该公式源于512点的stft生成257个频率单元。
存在两个中间层,该两个中间层的单元的数量都是257,并且激活函数是整流线性单元(relu)。
单声源掩码为二值,并且使用为0.1的阈值(公式[2.4]中的α)。
学习数据的总数为234万个样本,并且按每个声源数细分如下表3所示。
[表3]
注意,在生成两个声源的学习数据时,在与相应声源方向相关联的类别彼此临近或彼此第二临近的情况下,将它们从学习数据中排除。例如,学习数据中包括90°与75°的组合,但学习数据中不包含90°与85°的组合以及90°与80°的组合。
在不排除时,两种声源的学习数据为1598400个样本,并且每个类别的样本数为2400个。
为了比较,如图17所示,准备仅具有ipd作为输入特征量的dnn。该dnn与图5之间的差异仅为输入特征量。即,仅存在用于输入ipd33的单元作为输入层的单元组31,并且不存在用于输入单声源掩码的单元。另一方面,中间层35和输出层50与图5所示的中间层35和输出层50相同。
可以说,该使用dnn作为比较例的声源方向估计是使用ipd作为输入特征量的方法(专利文献1和2)与使用基于dnn的多标签分类器的声源方向估计(非专利文献5、6、以及9)的组合。
接下来,将参考图18描述其中记录实验中所使用的测试数据的环境。在录音棚中,两个麦克风1和2相距6cm安装。扬声器(声源5-1)安装在距离麦克风对pr的中点150cm的点处,另一扬声器(声源5-2)安装在距离麦克风对pr的中点110cm的点处,并且从相应的扬声器再现不同的声音。
从麦克风对pr的中点看到的声源方向相对于声源5-1为0°,而相对于声源5-2约为36°。从声源5-1再现一个话语,并且从声源5-2再现60个话语(存在六个说话者,三个男性和三个女性,且每个说话者说10个话语)。
录音以16khz和16位进行。通过对每个声源录音并然后在计算机上混合它们而生成观察信号的波形。
声源5-1的话语比声源5-2的任一个话语都长,并因此观察信号具有仅存在声源5-1的部分和两个声源混合的部分。
针对这样录音的声音数据,特征量用以下设定生成。
-stft点数:512个样本(32ms)
-移位宽度:160个样本(10ms)
-频率段的数量:257
-ipd帧数(公式[1.3]中的t1):10、15、20、25、30
-协方差矩阵的帧数(公式[2.2]中的t2):与t1相同
-单声源掩码的阈值(公式[2.4]中的α):0.1
接下来,将参考图19描述实验结果的示例。
在图19的a中,叠加并绘制每个声源的录音信号的波形,且纵轴表示幅度,而横轴表示时间。由于使用了两个麦克风1和2进行录音,所以还存在另一对与与其几乎相同的波形。波形w1是声源5-1的波形,而波形w2是声源5-2的波形,并且它们被叠加并示出。
声源5-1在从时间轴的左端到右端的几乎所有时间都在发声,而声源5-2仅在时段192中发声。因此,在观察信号中,在时段192中存在该两个声源(即,两个声源),但是在时段191和193中仅存在声源5-1。
图19的b是使用图5中的ps-dnn的方向估计结果,并且与本实施例的方法相对应。
在该曲线中,纵轴表示估计方向(度),横轴表示帧编号(每帧0.01秒),并且用点表示在每帧中所估计的声源方向。在该图中,在大多数帧中,在0°附近的区段195中存在点,该0°是声源5-1的方向。另一方面,在时段192中,在36°附近的区段194中也存在点,该36°是声源5-2的方向。即,可以看出,在两个声源混合的时段192中,几乎正确地估计了两个声源方向。
注意,即使在时段193的一部分(靠近左端)中,在36°附近的区段194中也存在点,因为在该曲线中使用30帧的观察信号来计算特征量。即,即使声源5-2停止发声,但在高达30帧的时间内,影响仍然存在,并因此可以输出声源5-2的方向。
在其中仅存在声源5-1的时段191和时段193中,除了上述时段193的左端附近之外,大部分帧中仅存在一个点,并且其值在0°附近的区间195中。即,可以看出,也可以通过根据声源的数量改变估计方向的数量来实现。
另一方面,图19的c是使用图17中的作为比较例的ps-dnn的方向估计结果。
在该曲线中,虽然在时段192中存在两个声源,但在大多数帧中,仅估计出与声源5-2的方向相对应的36°附近的区段194中的点。换言之,在与声源5-1的方向相对应的0°附近的区段195中的点存在于时段191和193中,但几乎不存在于时段192中。即,可以看出两个声源的方向估计失败,并且仅估计出一个声源。
为了评估,声源5-1和声源5-2的方向上的正确解答率分别通过以下公式[4.1]和[4.2](数学公式4)计算。
[数学公式4]
这些公式中的“存在两个声源的帧数”与图19中的时段192中的帧数相对应。但是,正确解答率并不针对每个话语计算,而是使用所有60个话语的总帧数来计算。
在公式[4.1]中,以7.5度的余量确定输出方向是否与声源5-1(0°)相对应。由于输出以5°为步长,所以如果输出-5°、0°、以及5°中的任一个,则假设结果为正确答案。
同样针对声源5-2(36°),如果输出30°、35°、以及40°中的任一个,则类似地假设结果为正确答案。
图20示出总计所有60个话语的结果。
列201表示在ipd(公式[1.3]中的t1)的计算中所使用的帧数。
由于在此实验中t1=t2,所以单声源掩码的协方差矩阵也是用相同的帧数来计算。
列202和203与使用本实施例的ipd和单声源掩码两者作为输入特征量的方法相关,并且分别表示声源5-1和声源5-2的方向的正确解答率。
列204和205与仅使用比较例的ipd作为输入特征量的方法相关,并且分别表示声源5-1和声源5-2的方向的正确解答率。
比较本实施例与比较例,两者对于声源5-2的正确解答率为80%以上,并且比较例的精度更高。另一方面,相反地,针对声源5-1,正确解答率在本实施例中通常为50%或更高,但在比较例中,正确解答率在t1=10时最高,为16.8%。
即,确认了在两个声源同时发声的环境中,本实施例的方法在至少一半帧中成功地估计出两个声源的方向,而在比较例中仅估计出一个声源的方向。
如上所述,在本公开中,除了ipd之外,单声源掩码也被用作输入特征量,并且通过用多标签分类器对它们进行分类,即使难以进行多个声源的方向估计的情况下,也可以进行正确的估计。
[2-4变形例]
如果在进行两种类型的输入特征量的计算时使用相同的帧数,则可以简化配置。以下将对这一点进行描述。
关于两种类型的特征量,使用公式[1.3]根据t1个帧计算ipd,并且使用公式[2.2]等根据t2帧计算单声源掩码。相同的值可用于t1和t2。然后,公式[1.3]中的括号内与公式[2.2]中的协方差矩阵cov(f,t)的右上部的元素匹配。
因此,在这种情况下,计算两种类型的特征量的处理的部分可以共享。即,在通过公式[2.2]计算协方差矩阵之后,通过特征值分解等计算单声源掩码,并且还通过计算协方差矩阵的右上部元素的辐角来计算ipd。
可替代地,可以计算协方差矩阵的左下部元素的辐角,并然后可以颠倒符号。
此外,在配置图上,在图10中,麦克风间相位差计算单元86和单声源掩码计算单元87可以集成到一个模块,并且该模块可以输出ipd和单声源掩码两者。
<3.总结>
虽然上面描述了实施例,但是根据实施例的声源方向估计装置具有以下特征和效果。
根据本实施例的声源方向估计装置包括:麦克风间相位差计算单元86(相位差计算单元),针对麦克风对pr中的每个频带计算麦克风间相位差,该麦克风对pr包括彼此间隔预定距离安装的两个麦克风1和2;以及单声源掩码计算单元87,针对麦克风对pr中的每个频带计算指示该频带的分量是否为单个声源的单声源掩码。此外,声源方向估计装置包括分类单元76(多标签分类器),该单元输入麦克风间相位差和单声源掩码作为特征量,并针对该特征量输出与声源方向相关联的方向标签。
即,针对麦克风对计算的麦克风间相位差和单声源掩码输入到多标签分类器以确定零个以上声源方向。
因此,通过不仅使用麦克风间相位差而且还使用单声源掩码作为特征量,忽略其中没有声音或存在两个或更多个声源的时频率段的分量。因此,即使用少量的学习数据也容易学习输入特征量与声源方向之间的对应关系,并且可以估计多个高精度的声源方向。
本实施例的声源方向估计装置还包括类别-方向转换单元77(转换单元),该单元将由分类单元76输出的方向标签转换为指示声源方向的声源方向信息。
因此,作为多标签分类器的分类单元76的方向标签的信息被转换为声源方向信息,并且可以在输出目的地处解释声源方向。即,可以准确地输出所估计的声源方向信息。
在实施例中,如图9所示,已给出了其中特征量提取单元74(麦克风间相位差计算单元86和单声源掩码计算单元87)对来自一对麦克风1、2的输入执行计算的示例。
如上所述,根据实施例的声源方向估计装置可以实现为可以准确地确定与来自至少两个麦克风1和2的输入相对应的多个声源的声源方向的装置。
已描述了其中实施例的单声源掩码计算单元87根据来自麦克风对pr的预定时间长度的输入信号来生成时频域中的协方差矩阵、获得协方差矩阵的特征值、并且将二值掩码作为单声源掩码的示例,该二值掩码通过使用关于最小特征值与最大特征值的比率是否低于预定阈值的二值作为掩码值来计算。
在仅存在一个声源的情况下,最小特征值e1(f,t)与最大特征值e2(f,t)相比非常小,并且在存在两个或更多个声源的情况下,最小特征值e1(f,t)取接近最大特征值e2(f,t)的值。此外,同样,在没有声音的情况下,如同在两个或更多个声源的情况下一样,最小特征值e1(f,t)取接近于最大特征值e2(f,t)的值。这用于生成单声源掩码。
因此,如上式[2.4]中,关于最小特征值e1(f,t)与最大特征值e2(f,t)的比率是否低于预定阈值α的二值可以作为单声源掩码的值。
此外,在本实施例中,描述了其中单声源掩码计算单元87根据来自麦克风对pr的预定时间长度的输入信号计算时频域中的协方差矩阵、获得协方差矩阵的特征值、并且将软掩码作为单声源掩码的示例,该软掩码通过将基于最小特征值与最大特征值的比率计算出的零以上且一以下的值用作掩码值来计算。更具体地,将使用通过从预定常数减去最小特征值与最大特征值的比率而获得的值作为掩码值而计算出的软掩码作为单声源掩码。
即,通过从上式[2.5]中的预定常数(“1”)中减去最小特征值e1(f,t)与最大特征值e2(f,t)的比率而获得的值可以作为单声源掩码的值。
在本实施例中,已描述了这种示例,在该示例中分类单元76(多标签分类器)包括与方向的分类数相同数量的二值分类器,每个二值分类器与每个方向相关联,并且当输入特征量时,与声源存在的方向相对应的零个以上二值分类器输出真值,并且与输出真值的二值分类器相关联的方向标签作为声源方向。
即,使用被称作二值相关性分类器作为多标签分类器。
在这种情况下,如图4所示,声源存在的方向由已点燃的单元(该单元的输出值超过阈值)决定。即,可以输出与单元相关联的方向标签作为声源方向。
在这种情况下,分类单元76具有以下特征。
-它是一个神经网络并且包括一个输入层、一个输出层、以及一个或多个中间层。
-输入层包括输入针对每个频率的麦克风间相位差的单元和输入针对每个频率的单声源掩码的单元。
-输出层包括与方向的分类数相同数量的单元,并且每个单元与不同的方向相关联。
-输入到输入层的数据传播到输出层,并且仅当输出层中的每个单元的值超过预定阈值时,才认为该单元已被点燃。
-与已点燃的单元相关联的方向标签被作为声源方向输出。
利用该配置,可以具体地配置用于声源方向估计的二值相关性多标签分类器。
此外,在实施例中,已描述了这样的示例,在该示例中分类单元76(多标签分类器)包括与彼此不同的零以上且m以下个方向的组合的总数相同数量的分类类别,其中m是可以估计的声源的数量的上限,每个类别与零个以上声源方向相关联,当特征量被输入时,特征量被分类到这些类别中的一个类别中,并且与所分类的类别相关联的零个以上方向标签被作为声源方向输出。
即,使用称作修剪集的分类器作为多标签分类器。
在这种情况下,如图5所示,将输入层中的数据传播到输出层之后,搜索输出层中的具有最大输出值的单元,并且可以假设与该单元相关联的标签作为声源方向。
在这种情况下,分类单元76具有以下特征。
-它是一个神经网络并且包括一个输入层、一个输出层、以及一个或多个中间层。
-输入层包括输入针对每个频率的麦克风间相位差的单元和输入针对每个频率的单声源掩码的单元。
-输出层包括与零以上且m以下个不同方向的组合的总数相同数量的单元,并且每个单元与零个或更多声源方向相关联。
-输入到输入层的数据传播到输出层,并且在输出层的单元当中选择具有最大值的单元。
-零个以上方向标签与作为声源方向的所选单元相关联。
利用该配置,可以具体地配置用于声源方向估计的修剪集多标签分类器。
在本实施例中,描述了麦克风间相位差计算单元86和单声源掩码计算单元87对来自多个麦克风对的输入执行计算的示例。
即,如参考图7和图8所述,可以实现一种声源方向估计装置,该声源方向估计装置可以准确地确定与来自多个麦克风对pr的输入相对应的多个声源的声源方向。
此外,在这种情况下,如参考图8的b所述,多个麦克风对中的至少两个麦克风对可以共享每个麦克风对中的一个麦克风。
以这种方式,可以实现使用实施例的声源方向估计装置的声源方向估计,而不必需要两倍于麦克风对数pr的麦克风数。
作为实施例的变形例,已描述了麦克风间相位差计算单元86针对在由单声源掩码计算单元87计算单声源掩码时生成的协方差矩阵的右上部或左下部元素来计算复数的辐角,并将该辐角的值作为麦克风间相位差。
即,也根据协方差矩阵计算麦克风间相位差。因此,可以有效进行麦克风间相位差的计算处理。
本实施例的程序是使例如诸如中央处理单元(cpu)、数字信号处理器(dsp)等的信息处理装置或者包括它们的计算机装置执行图13、图14和图16所示的处理的程序。
换言之,本实施例的程序是:使信息处理装置针对麦克风对pr中的每个频带执行计算麦克风间相位差的处理,该麦克风对pr包括彼此间隔预定距离安装的两个麦克风1和2;针对麦克风对pr中的每个频带,计算指示该频带的分量是否为单个声源的单声源掩码的处理;以及将计算出的麦克风间相位差和计算出的单声源掩码输入到多标签分类器,并将与声源方向相关联的方向标签输出到该特征量的处理的程序。
利用这样的程序,可以实现执行上述声源方向估计的信息处理装置。
这种程序可以预先记录在硬盘驱动器(hdd)中作为内置在诸如计算机装置的装置中的记录介质、具有cpu的微型计算机中的只读存储器(rom)等。
可替代地,程序也可以临时(或永久)地存储(记录)在可移除记录介质(诸如软盘、压缩盘只读存储器(cd-rom)、磁光(mo)盘、数字多功能盘(dvd)、蓝光盘(注册商标)、磁盘、半导体存储器、存储卡等)中。这种可移除记录介质可以被提供作为所谓的包软件。
此外,这种程序可以从可移除记录介质安装到个人计算机等中,或者可以经由网络(诸如局域网(lan)或互联网)从下载站点下载。
此外,这种程序适合于提供用作根据实施例的声源方向估计装置的广泛范围的信息处理装置。例如,通过在个人计算机、便携式信息处理装置、移动电话、终端装置、游戏装置、视频装置、音频装置、成像装置、个人数字助理(pda)、对话接口装置、代理装置、机器人、语音检测装置、家用电器等中执行基于该程序的处理,可以使这些装置用作本公开的声源方向估计装置。
此外,图7和图9中的配置可以分布到多个信息处理装置,而不是作为单个信息处理装置。
作为所谓的云计算,终端装置中的麦克风对pr的输入可以被转换成数字数据,并然后传送到云服务器。在云服务器侧,还可以设想这样的配置,该配置包括作为具有麦克风间相位差计算单元86和单声源掩码计算单元87的特征量提取单元74、分类单元76、以及进一步的类别-方向转换单元77的部件,并且将获得的声源方向信息作为结果返回到终端装置。
然后,通过包括至少一个麦克风对pr的装置与云服务器的协作,可以通过本实施例的技术进行声源方向估计。
图21示出可用作本技术的声源方向估计装置的信息处理装置300的配置示例。
在图21中,信息处理装置300的cpu301根据存储在rom302中的程序或从存储单元308加载到随机存取存储器(ram)303的程序执行各种处理。ram303也适当地存储cpu301执行各种处理等所需的数据。
cpu301、rom302、以及ram303通过总线304彼此连接。输入输出接口305也连接到总线304。
包括麦克风、键盘、鼠标等的输入单元306、包括具有lcd或有机el面板等的显示器、扬声器等的输出单元307、包括硬盘等的存储单元308、以及包括调制解调器等的通信单元309连接到输入输出接口305。通信单元309经由包括互联网的网络执行通信处理。
驱动器310也根据需要连接到输入输出接口305,可移除介质311(诸如磁盘、光盘、磁光盘、或半导体存储器)适当地安装在其上,并且根据需要将从它们读取出的计算机程序安装在存储单元308中。
在通过软件执行上述声源方向估计处理的情况下,从网络或记录介质安装形成该软件的程序。
该记录介质包括为了向用户分发程序而分发的可移除介质311,并且该可移除介质311包括在其上记录有程序的磁盘、光盘、磁光盘、或半导体存储器等。可替代地,它也包括其中记录有程序的rom302、包括在存储单元308中的硬盘、或者在预先并入到装置主体中的状态下被分发给用户的记录介质。
如上所述的这种信息处理装置300例如包括作为输入单元306的麦克风对pr和用于输入其语音的ad转换单元72。然后,cpu301根据程序执行特征量提取单元74、分类单元76、类别-方向转换单元77、以及控制单元79的处理。以这种方式,可以使信息处理装置300用作声源方向估计装置。
注意,在本说明书中描述的效果仅仅是示例而不受限制,并且可以提供其它效果。
注意,本技术可以采用如下配置。
(1)
一种声源方向估计装置,包括:
相位差计算单元,针对一麦克风对中的每个频带计算麦克风间相位差,该麦克风对包括彼此间隔预定距离安装的两个麦克风;
单声源掩码计算单元,针对麦克风对中的每个频带,计算指示该频带的分量是否为单个声源的单声源掩码;以及
多标签分类器,将由相位差计算单元计算的麦克风间相位差和由单声源掩码计算单元计算的单声源掩码作为特征量输入,并针对这些特征量输出与声源方向相关联的方向标签。
(2)
根据上面(1)所述的声源方向估计装置,还包括:
转换单元,将由多标签分类器输出的方向标签转换为指示声源方向的声源方向信息。
(3)
根据上面(1)或(2)所述的声源方向估计装置,其中,
相位差计算单元和单声源掩码计算单元对来自一个麦克风对的输入执行计算。
(4)
根据上面(1)至(3)中任一项所述的声源方向估计装置,其中,
单声源掩码计算单元:
根据来自麦克风对的预定时间长度的输入信号生成时频域中的协方差矩阵、获得协方差矩阵的特征值、并将一二值掩码作为单声源掩码,该二值掩码通过将关于最小特征值与最大特征值的比率是否低于预定阈值的二值用作掩码值来计算。
(5)
根据上面(1)至(3)中任一项所述的声源方向估计装置,其中,
单声源掩码计算单元:
根据来自麦克风对的预定时间长度的输入信号计算时频域中的协方差矩阵、获得协方差矩阵的特征值、并且将一软掩码作为单声源掩码,该软掩码通过将基于最小特征值与最大特征值的比率计算出的零以上且一以下的值用作掩码值来计算。
(6)
根据上面(1)至(5)中任一项所述的声源方向估计装置,其中,
多标签分类器:
包括与方向的分类数相同数量的二值分类器,每个二值分类器与每个方向相关联,并且
当输入特征量时,与声源存在的方向相对应的零个以上二值分类器输出真值,并且
将与已输出真值的二值分类器相关联的方向标签作为声源方向输出。
(7)
根据上面(6)所述的声源方向估计装置,其中,
多标签分类器是神经网络并且包括一个输入层、一个输出层、以及一个或多个中间层,
输入层包括输入针对每个频带的麦克风间相位差的单元和输入针对每个频带的单声源掩码的单元,
输出层包括与方向的分类数量相同数量的单元,并且每个单元与不同方向相关联,
输入到输入层的数据被传播到输出层,并且仅当输出层的每个单元的值超过预定阈值时,才认为单元已输出真值,并且
将与已输出真值的单元相关联的方向标签作为声源方向输出。
(8)
根据上面(1)至(5)中任一项所述的声源方向估计装置,其中,多标签分类器
包括与彼此不同的零以上且m以下个方向的组合的总数相同数量的分类类别,其中m是能够估计的声源的数量的上限,每个类别与零个以上声源方向相关联,
当特征量被输入时,将特征量分类到一个类别中,并且
与分类的类别相关联的零个以上方向标签被作为声源方向输出。
(9)
根据上面(8)所述的声源方向估计装置,其中,
多标签分类器是神经网络,并且包括一个输入层、一个输出层、以及一个或多个中间层,
输入层包括输入针对每个频带的麦克风间相位差的单元和输入针对每个频带的单声源掩码的单元,
输出层包括输入与彼此不同的零以上且m以下个方向的组合的总数相同数量的单元,每个类别与零个以上声源方向相关联,
输入到输入层的数据传播到输出层,在输出层的单元当中选择具有最大值的单元,并且与所选单元相关联的零个以上方向标签被作为声源方向输出。
(10)
根据上面(1)至(9)中任一项所述的声源方向估计装置,其中,
相位差计算单元和单声源掩码计算单元对来自多个麦克风对的输入执行计算。
(11)
根据上面(10)所述的声源方向估计装置,其中,
多个麦克风对中的至少两个麦克风对共享每个麦克风对中的一个麦克风。
(12)
根据上面(4)或(5)所述的声源方向估计装置,其中,
相位差计算单元:
针对在由单声源掩码计算单元计算单声源掩码时生成的协方差矩阵的右上部或左下部元素,计算复数的辐角,并取该辐角的值作为麦克风间相位差。
(13)
一种声源方向估计方法,包括:在信息处理装置中,
针对一麦克风对中的每个频带计算麦克风间相位差,该麦克风对包括彼此间隔预定距离安装的两个麦克风;
针对麦克风对中的每个频带计算指示该频带的分量是否为单个声源的单声源掩码;并且
计算出的麦克风间相位差和计算出的单声源掩码作为特征量输入到多标签分类器,并且针对该特征量输出与声源方向相关联的方向标签。
(14)
一种程序,使信息处理装置执行:
针对一麦克风对中的每个频带计算麦克风间相位差的处理,该麦克风对包括彼此间隔预定距离安装的两个麦克风;
针对麦克风对中的每个频带计算指示该频带的分量是否为单个声源的单声源掩码;并且
将计算出的麦克风间相位差和计算出的单声源掩码作为特征量输入到多标签分类器,并且针对该特征量输出与声源方向相关联的方向标签。
参考符号列表
1、2、3麦克风
5声源
6、7传输路径
8路径差
74特征量提取单元
76分类单元
77类别-方向转换单元
79控制单元
83、84短时傅立叶变换单元
85观察信号缓冲单元
86麦克风间相位差计算单元
87单声源掩码计算单元。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



