
 商标分类
商标分类  商标转让
商标转让 
一种融合骨振动传感器和双麦克风信号的深度学习降噪方法及系统与流程
 2021-01-28 15:01:33|
2021-01-28 15:01:33| 314|
314| 起点商标网
起点商标网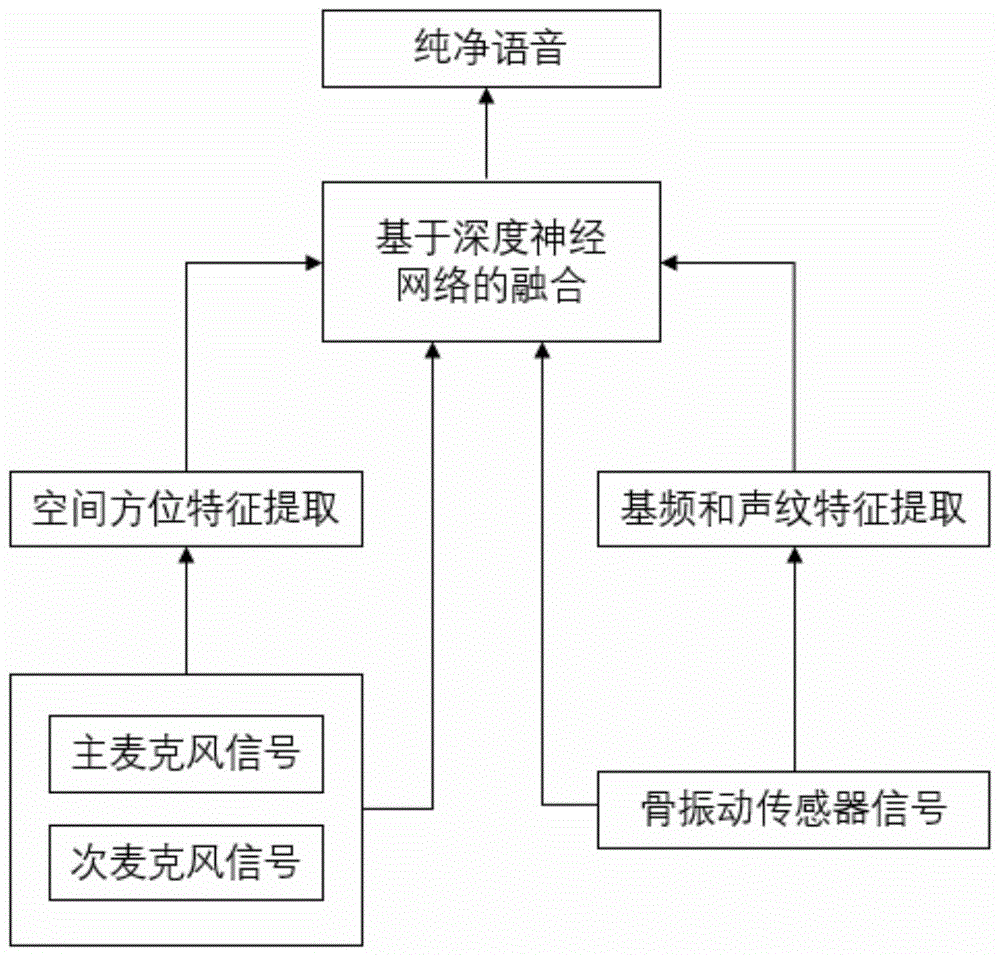
本发明涉及深度学习、语音信号处理、语音降噪技术领域,更具体地说,涉及一种融合骨振动传感器和双麦克风信号的深度学习降噪方法。
背景技术:
语音降噪技术是指从带噪语音信号中分离出语音信号,该技术拥有广泛的应用,通常有单麦克风降噪技术和多麦克风降噪技术,传统的单双麦降噪技术很难实现性能的突破,难以满足人们在地铁,马路,机场,咖啡厅等日常超级嘈杂环境中清晰的通话要求。
传统多麦克风降噪技术需要两个及以上麦克风,利用波束形成技术的降噪方案。传统多麦克风通话降噪技术存在以下缺陷:
1、传统多麦对麦克风的一致性要求高,一定程度上会限制产线的良品率;
2、多麦克降噪技术依靠方向信息进行降噪,无法抑制来自于目标人声方向的噪音。
本专利结合了骨振动传感器及双麦克风的信号,采用深度学习降噪技术,在各种噪声环境下,实现提取目标人声,降低干扰噪声。该技术可应用于耳机、手机等贴合耳部的通话场景。
相比于仅采用一个或多个麦克风降噪的技术,结合骨振动传感器可在信噪比极低的环境下,诸如:地铁、风噪等场景,依然可以保持良好的通话体验。
相比传统单麦克风降噪技术,本技术不对噪声做任何假设(传统单麦风降噪技术预先假设噪声为平稳噪声),利用深度神经网络强大的建模能力,有很好的人声还原度及极强的噪声抑制能力,可以解决复杂噪声场景下的人声提取问题。
不同于其他结合骨震动传感器及气导麦克风降噪方式仅利用骨震动传感器信号作为激活检测的标志,本技术利用骨振动传感器信号不受气导噪声干扰的特性,将骨传信号作为输入信号,与双麦克风信号一同送入深度神经网络进行整体降噪、融合。同时送入神经网络的还有从主麦克风和次麦克风提取出来的信号空间方位特征,和从骨振动传感器提取出来的说话者的基频,声纹特征。借助骨振动传感器,我们能够得到优质的低频信号,并以此为基础,极大地提高深度神经网络预测的准确性,使得降噪效果更佳。
相对传统单麦降噪技术,本专利采用双麦克风作为输入,极大提高了降噪的效果。因此具有鲁棒性强、成本可控、对产品结构设计要求低等特点,第三部分背景技术已有详细描述,在此不赘述;
相比本申请人之前提交的《一种融合骨振动传感器和麦克风信号的深度学习语音提取和降噪方法》(申请号:201910953534.9),本专利引入了主麦克风和次麦克风的双麦风阵列,并且将基频,声纹特征,信号空间方位特征,主麦克风信号,次麦克风信号,骨振动传感器信号同时融合到深度神经网络,从而得到性能更优的降噪效果,满足噪声极度恶劣的应用场合。
相比本申请人之前提交的《近距离交谈场景下双麦克风移动电话的实时语音降噪方法》(申请号:201910945319.4),本专利引入了骨振动传感器作为补充,利用骨振动传感器不受空气噪音干扰的特性,并且可以提取出更高精度的声音基频和声纹特征。将骨振动传感器信号与气导麦克风信号,声音基频,声纹特征,信号空间方位特征使用深度神经网络融合,达到了在极低信噪比下也能有理想的降噪效果。
与《一种通过人体振动识别用户语音以控制电子设备的系统》(申请号:201811199154.2)中将骨振动传感器信号作为语音活动检测的标志不同,我们将骨振动传感器信号与麦克风信号,基频,声纹特征,信号空间方位特征结合一起作为深度神经网络的输入,进行信号层的深度融合,从而达到优良的降噪效果。
技术实现要素:
本发明要解决的技术问题在于如何通过一种融合骨振动传感器和双麦克风信号的深度学习降噪系统,以解决现有技术下单双麦降噪在极低信噪比下噪声抑制差、人声清晰度不佳等问题。不同于其他结合骨震动传感器及气导麦克风降噪方式仅利用骨震动传感器信号作为激活检测的标志,本技术利用骨振动传感器信号不受气导噪声干扰的特性,将骨传信号作为低频输入信号,与双麦克风信号一同送入深度神经网络进行整体降噪、融合。同时送入神经网络的还有从主麦克风和次麦克风提取出来的信号空间方位特征,和从骨振动传感器提取出来的说话者的基频,声纹特征。借助骨振动传感器,我们能够得到优质的低频信号,并以此为基础,极大地提高深度神经网络预测的准确性,使得降噪效果更佳。
本发明解决其技术问题所采用的技术方案是:构造一种融合骨振动传感器和双麦克风信号的深度学习降噪系统,结合了骨振动传感器及双麦克风的信号,采用深度学习降噪技术,在各种噪声环境下,实现提取目标人声,降低干扰噪声。该技术可应用于耳机、手机等贴合耳部的通话场景。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪系统中,包括:
基频和声纹特征提取模块,用于从骨振动传感器信号中提取出用户声音的基频和声纹特征;
空间方位特征提取模块,用于从主麦克风信号和次麦克风信号中提取信号源的空间方位特征信息;
基于深度神经网络的融合模块,用于将所述骨振动传感器提取出的基频和声纹特征,从所述主麦克风信号和次麦克风信号提取出来的空间方位特征,和骨振动传感器信号以及主麦克风信号,次麦克风信号相融合,预测得到降噪后用户语音。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪系统中,所述基频和声纹特征提取模块可以提取部分声纹的特征,或者提取全部声纹的特征。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪系统中,所述空间方位特征包括用户声音的空间方位位置和干扰信号的空间方位信息。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪系统中,所述基于深度神经网络的融合模块中网络结构为卷积循环神经网络,或者长短期神经网络,或者深度全卷积网络结构。
本发明要解决的另一技术问题在于如何通过采用一种融合骨振动传感器和双麦克风信号的深度学习降噪方法,以解决现有技术中单双麦降噪在极低信噪比下降噪性能差、人声清晰度不佳等问题。不同于其他结合骨震动传感器及气导麦克风降噪方式仅利用骨震动传感器信号作为激活检测的标志,本技术利用骨振动传感器信号不受气导噪声干扰的特性,将骨传信号作为低频输入信号,与双麦克风信号一同送入深度神经网络进行整体降噪、融合。同时送入神经网络的还有从主麦克风和次麦克风提取出来的信号空间方位特征,和从骨振动传感器提取出来的说话者的基频,声纹特征。借助骨振动传感器,我们能够得到优质的低频信号,并以此为基础,极大地提高深度神经网络预测的准确性,使得降噪效果更佳。
本发明解决其另一技术问题所采用的技术方案是:构造一种融合骨振动传感器和双麦克风信号的深度学习降噪方法,结合了骨振动传感器及双麦克风的信号,采用深度学习降噪技术,在各种噪声环境下,实现提取目标人声,降低干扰噪声。该技术可应用于耳机、手机等贴合耳部的通话场景。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法中,包括如下步骤:
从骨振动传感器信号中提取出用户声音的基频和声纹特征信息;
利用主麦克风信号和次麦克风信号提取出声音源的空间方位特征;
将所述输出的特征与骨振动传感器信号和主麦克风的信号以及次麦克风信号融合送入深度神经网络模块;
通过所述深度神经网络模块预测得到降噪语音。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法中,所述基频是复杂声音中最低且通常情况下最强的频率,是声音的基础音调,当用户发出声音时,声音可以分解为许多单纯的正弦波,自然声音基本都是由许多频率不同的正弦波组成的,其中频率最低的正弦波即为基音。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法中,所述声纹特征是指携带语言信息的声波频谱的特性,所述声纹特征包括频谱、倒频谱、共振峰、鼻音、沙哑音、韵律、节奏、语调。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法中,所述空间方位特征可以作为分离用户语音和干扰声音,并且去除干扰声音,保留有用语音信号的重要特征依据。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法中,所述空间方位特征包括信号的波达空间方向,所述波达空间方向是指空间信号的到达方向,其包括方位角和俯仰角,是空间谱估计的重要参数,所述波达空间方向估计主要利用了主麦克风信号和次麦克风信号的相位差和幅度差信息。
在本发明所述的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法中,所述深度神经网络模块的一种实现方法是通过卷积循环神经网络实现,并通过预测得到降噪语音,具体包括如下步骤:
该模块训练的目标是纯净语音的幅度谱,首先将纯净语音经过短时傅里叶变换,再获得它的幅度谱作为训练的目标;
网络的输入是将基频和声纹特征,空间方位特征,骨振动传感器信号的幅度谱和主、次麦克风信号的幅度谱堆叠后的结果,因此需要先将两路信号分别经过短时傅里叶变换,再分别取得两路幅度谱,然后再和基频和声纹特征,空间方位特征进行堆叠;
将堆叠后的幅度谱数据经过深度神经网络,深度神经网络由三层卷积网络、三层长短期记忆网络、三层反卷积网络构成;
深度神经网络输出预测的幅度谱;
将预测的幅度谱与目标幅度谱做均方误差;
训练过程采用反向传播-梯度下降的方式更新网络参数,不断地送入网络训练数据、更新网络参数,直至网络收敛;
推理过程使用麦克风数据短时傅里叶变化后结果的相位和预测出来的幅度结合,恢复出预测后的纯净语音。
根据上述方案的本发明,其有益效果在于,本发明提供了一种融合骨振动传感器和双麦克风信号的深度学习降噪方法及系统,利用深度神经网络强大的建模能力,有很好的人声还原度及极强的噪声抑制能力,可以解决复杂噪声场景下的人声提取问题。本专利结合了骨振动传感器及双麦克风的信号,采用深度学习降噪技术,在各种噪声环境下,实现提取目标人声,降低干扰噪声。该技术可应用于耳机、手机等贴合耳部的通话场景。相比于仅采用一个或多个麦克风降噪的技术,结合骨振动传感器可在信噪比极低的环境下,诸如:地铁、风噪等场景,依然可以保持良好的通话体验。不同于其他结合骨震动传感器及气导麦克风降噪方式仅利用骨震动传感器信号作为激活检测的标志,本技术利用骨振动传感器信号不受气导噪声干扰的特性,将骨传信号作为低频输入信号,与双麦克风信号一同送入深度神经网络进行整体降噪、融合。同时送入神经网络的还有从主麦克风和次麦克风提取出来的信号空间方位特征,和从骨振动传感器提取出来的说话者的基频,声纹特征。借助骨振动传感器,我们能够得到优质的低频信号,并以此为基础,极大地提高深度神经网络预测的准确性,使得降噪效果更佳。本专利采用双麦克风作为输入,极大提高了降噪的效果。因此具有鲁棒性强、成本可控、对产品结构设计要求低。本专利引入了主麦克风和次麦克风的双麦风阵列,并且将基频,声纹特征,信号空间方位特征,主麦克风信号,次麦克风信号,骨振动传感器信号同时融合到深度神经网络,从而得到性能更优的降噪效果,满足噪声极度恶劣的应用场合。本专利引入了骨振动传感器作为补充,利用骨振动传感器不受空气噪音干扰的特性,并且可以提取出更高精度的声音基频和声纹特征。将骨振动传感器信号与气导麦克风信号,声音基频,声纹特征,信号空间方位特征使用深度神经网络融合,达到了在极低信噪比下也能有理想的降噪效果。本专利将骨振动传感器信号与麦克风信号,基频,声纹特征,信号空间方位特征结合一起作为深度神经网络的输入,进行信号层的深度融合,从而达到优良的降噪效果。
附图说明
下面将结合附图及实施例对本发明作进一步说明。附图中:
图1为本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法的流程框图;
图2为本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法的深度神经网络融合模块结构框图;
图3为本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法的骨振动传感器采集到的音频信号频谱示意图;
图4为本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法的主麦克风采集到的音频信号频谱示意图;
图5为本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法的次麦克风采集到的音频信号频谱示意图;
图6为本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法处理后的音频信号频谱示意图;
图7为本发明的一种融合骨振动传感器结合单麦克风信号的降噪方法和一种融合骨振动传感器结合双麦克风信号的降噪方法的降噪效果对比图;
图8为双麦克风加骨振动传感器降噪运用在无线耳机接收语音降噪的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法及系统,该系统包括:基频和声纹特征提取模块,用于从骨振动传感器信号中提取出用户声音的基频和声纹特征;空间方位特征提取模块,用于从主麦克风信号和次麦克风信号中提取信号源的空间方位特征信息;基于深度神经网络的融合模块,用于将骨振动传感器提取出的基频和声纹特征,从主麦克风信号和次麦克风信号提取出来的空间方位特征,和骨振动传感器信号以及主麦克风信号,次麦克风信号相融合,预测得到降噪后用户语音。
本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法,包括如下步骤:
从骨振动传感器信号中提取出用户声音的基频和声纹特征信息;
利用主麦克风信号和次麦克风信号提取出声音源的空间方位特征;
将输出的特征与骨振动传感器信号和主麦克风的信号以及次麦克风信号融合送入深度神经网络模块;
通过所述深度神经网络模块预测得到降噪语音。
具体地,基频和声纹特征提取模块可以提取部分声纹的特征,或者提取全部声纹的特征。在本实施例中,提取声纹和基频的方法可以选上述的任何一种方法,在此不受局限性。
具体地,基频是复杂声音中最低且通常情况下最强的频率,是声音的基础音调。当用户发出声音时,声音可以分解为许多单纯的正弦波,自然声音基本都是由许多频率不同的正弦波组成的,其中频率最低的正弦波即为基音。
进一步地,基频和声纹特征是区分不同人声音的重要特征依据。语音基频提取在语音信号处理领域有广泛运用,如语音分离,语音合成等。由于人体发声器官生理方面的差异,男性的基频范围为50~250hz;女性的基频为120~500hz;婴儿的基频范围大约为250~800hz。由于骨振动传感器主要接收低频信号(1000hz以下),并且不受环境噪声和高频语音成分的影响,从而可以提取出更准确的基频特征。基频估计的方法可以用自相关函数法,平均幅度差函数法,倒谱分析法,离散小波变换法等。声纹特性是指携带语言信息的声波频谱的特性。人的发声器官存在大小,形态,功能上的差异,这些器官微小的差异会导致发声气流的改变,引起音质,音色的差别。这些差别体现在声纹特性上具有特定性,稳定性的特定。声纹特征是区分不同说话人声音的重要依据。声纹特征中可以反应出常见的声学特征如频谱,倒频谱,共振峰,鼻音,沙哑音,韵律,节奏,语调等。常用的声纹特征提取方法有:线性预测分析,感知线性预测系数,基于滤波器组的fbank特征,线性预测倒谱系数,梅尔频率倒谱系数等。由于骨振动传感器主要接收低频信号,并且不受环境噪声的影响,而从可以提取出更准确的基频特征和声纹特征。
具体地,空间方位特征包括用户声音的空间方位位置和干扰信号的空间方位信息。在本实施例中,提取空间特性的方法可以选上述的任何一种方法,在此不受局限性。
进一步地,由于用户声音和干扰声音一般来源于不同的空间方位,因此空间方位信息可以作为分离用户语音和干扰声音,并且去除干扰声音,保留有用语音信号的重要特征依据。信号的波达空间方向是一个重要的空间方位特征。波达空间方向是指空间信号的到达方向,包括方位角和俯仰角,是空间谱估计的重要参数。精确估计信号的波达空间方向在复杂声场分离噪声有十分重要作用。例如传统的波束形成技术,就是利用不同的波达空间方向设计出指向不同方向的滤波器,实现空间滤波。波达空间方向估计主要利用了主麦克风信号和次麦克风信号的相位差和幅度差信息。声源空间方位估计的方位可以用:估计麦克风信号之间的时延差,广义互相关算法,空间谱搜索方法,多信号分类算法,旋转因子不变法,神经网络算法等。
早期采用的snr(signal-to-noiseratio,信噪比)加权的方式加强目标语音频率,得到更高的snr。例如使用基于语音活动检测的算法或是基于最小均方误差的方法等snr估计法。然而,这些算法通常假设噪声是静态的,而现实环境中的噪声通常是动态的,从而导致现实环境中进行声源空间方位估计时,方向估计的鲁棒性较差。基于时频掩蔽和深度神经网络的声源方向估计方法对于在强混响或漫放射噪声的环境中,具有很强的鲁棒性。基于时频掩蔽和深度神经网络的声源方向估计可以采用方法一,将掩蔽后的广义互相关函数沿频率和时间进行加和,选取加和互相关函数最大峰值的方向最为声源的方向。方法二,采用波束形成的滤波器系数和目标语音协方差矩阵计算不同频率上目标语音的能量,采用波束成形的滤波器系数和噪声协方差矩阵计算不同频率上噪声的能量。在不同频率上,计算目标语音和噪声的能量比,并沿频率维度加和,形成在某一候选方向上的总体信噪比,选择对应总体信噪比最大的候选方向作为声源方向。方法三,根据麦克风阵列拓扑结构计算候选方向在麦克风之间的到达时间差,计算到达时间差和候选方向的麦克风之间的到达时间差之间的余弦距离,选择对应最大余弦距离的获选方向作为声源方向。相对传统单麦降噪技术,本本实施例采用双麦克风作为输入,极大提高了降噪的效果。因此具有鲁棒性强、成本可控、对产品结构设计要求低等特点。
图2示出了本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法的深度神经网络融合模块结构框图,在本实施例中,基于深度神经网络的融合模块中网络结构以卷积循环神经网络作为示例,当然也可替换成长短期神经网络、深度全卷积网络等任一种结构。
基于深度学习的监督式降噪被广泛认为是最先进的方法,并且极大地提升了降噪性能,包括首次展示出在带噪环境中为听力受损和听力正常的听众带来语音可懂度的实质性改善。近年来,语音降噪已经使用监督学习方法,通过训练数据来学习语音或噪声信号中的判别模式。与基于对语音和噪声信号进行统计分析的传统语音增强不同,监督式语音降噪是数据驱动的,并根据详细的训练样本自动地学习模式,这很大程度得益于深度学习的使用。相比本申请人之前提交的《一种融合骨振动传感器和麦克风信号的深度学习语音提取和降噪方法》(申请号:201910953534.9),本实施例引入了主麦克风和次麦克风的双麦风阵列,并且将基频,声纹特征,信号空间方位特征,主麦克风信号,次麦克风信号,骨振动传感器信号同时融合到深度神经网络,从而得到性能更优的降噪效果,满足噪声极度恶劣的应用场合。
结合图1、图2,本发明通过融合目标语音的基频和声纹特征,语音声源的空间方位信息,双麦克风的信号以及骨振动传感器信号作为深度神经网络的输入,极大丰富了神经网路的输入信息,而从得到很好的降噪效果。
具体地,卷积递归神经网络作为本实施例的深度神经网络模块的一个实现方式。该方法结合了卷积层和递归层,受益于卷积神经网络cnn的特征提取能力和回归神经网络rnn的时间建模能力。利用编码器-解码器架构,卷积递归网络crn将输入特征编码到更高维的潜在空间中,然后通过两个长短期记忆lstm层对潜在特征向量的序列进行建模。随后,解码器将长短期记忆lstm层的输出序列转换回原始输入尺寸。编码器包括三个卷积层,解码器包括三个去卷积层。为了改善整个网络中信息和梯度的流动,使用跳跃连接(skipconnection)来将每个编码器层的输出连接到相应编码器层的输入。在卷积递归网络crn中,所有卷积和去卷积都是因果的,因此在每个时间帧都不会将未来信息用于幅度谱估计。
图2示出了本发明的一种融合骨振动传感器和双麦克风信号的深度学习降噪方法的深度神经网络融合模块结构框图,给出了深度神经网络模块的卷积循环神经网络结构,这只是该模块的一种网络结构实现,不仅局限于此。具体包括如下步骤:
该模块训练的目标(trainingtarget)是纯净语音的幅度谱,首先将纯净语音(cleanspeech)经过短时傅里叶变换(stft),再获得它的幅度谱作为训练的目标;
进一步地,网络的输入是将基频和声纹特征,空间方位特征,骨振动传感器信号的幅度谱和主、次麦克风信号的幅度谱堆叠后的结果,因此需要先将两路信号分别经过短时傅里叶变换(stft),再分别取得两路幅度谱(magnitudespectrum),然后再和基频和声纹特征,空间方位特征进行堆叠(stacking);
进一步地,将堆叠后的幅度谱数据经过深度神经网络,深度神经网络由三层卷积网络、三层长短期记忆网络、三层反卷积网络构成;
进一步地,深度神经网络输出预测的幅度谱(estimatedmagnitudespectrum);
进一步地,将预测的幅度谱(estimatedmagnitudespectrum)与目标幅度谱(targetmagnitudespectrum)做均方误差(mean-squareerror,mse);
进一步地,训练过程(training)采用反向传播-梯度下降的方式更新网络参数,不断地送入网络训练数据、更新网络参数,直至网络收敛;
进一步地,推理过程使用麦克风数据短时傅里叶变化(stft)后结果的相位和预测出来的幅度结合,恢复出预测后的纯净语音(cleanspeech)。
相对传统单麦降噪技术,本实施例采用双麦克风作为输入,极大提高了降噪的效果。因此具有鲁棒性强、成本可控、对产品结构设计要求低等特点。本实施例不对噪声做任何假设(传统单麦风降噪技术预先假设噪声为平稳噪声),利用深度神经网络强大的建模能力,有很好的人声还原度及极强的噪声抑制能力,可以解决复杂噪声场景下的人声提取问题。传统的单双麦降噪技术很难实现性能的突破,难以满足人们在地铁,马路,机场,咖啡厅等日常超级嘈杂环境中清晰的通话要求。
公开的申请号为201811199154.2专利(名称为一种通过人体振动识别用户语音以控制电子设备的系统)包括人体振动传感器,用于感应用户的人体振动;处理电路,与所述人体振动传感器相耦合,用于当确定所述人体振动传感器的输出信号包括用户语音信号时,控制拾音设备开始拾音;通信模块,与处理电路和所述拾音设备相耦合,用于所述处理电路和所述拾音设备之间的通信。与《一种通过人体振动识别用户语音以控制电子设备的系统》(申请号:201811199154.2)中将骨振动传感器信号作为语音活动检测的标志不同,我们将骨振动传感器信号与麦克风信号,基频,声纹特征,信号空间方位特征结合一起作为深度神经网络的输入,进行信号层的深度融合,从而达到优良的降噪效果。
相比本申请人之前提交的《近距离交谈场景下双麦克风移动电话的实时语音降噪方法》(申请号:201910945319.4),本实施例引入了骨振动传感器作为补充,利用骨振动传感器不受空气噪音干扰的特性,并且可以提取出更高精度的声音基频和声纹特征。将骨振动传感器信号与气导麦克风信号,声音基频,声纹特征,信号空间方位特征使用深度神经网络融合,达到了在极低信噪比下也能有理想的降噪效果。
图3、图4、图5分别是骨振动传感器、主麦克风、次麦克风采集到的音频信号频谱,图6是经过该技术处理后的音频信号频谱示意图。
图8示出了双麦克风加骨振动传感器降噪运用在无线耳机接收语音降噪的结构示意图,图中下方的主麦克风10更靠近用户的嘴部,可以接收更高信噪比的用户声音信号,称为主麦克风信号。上方的次麦克风20相对远离用户嘴部,接收到用户声音信号更弱,同时受到噪声干扰更为严重,称为次麦克风信号。骨振动传感器30位于靠近耳机和人耳贴触部位,从而感知人说话时引起的振动信号。
如图7所示,示出了融合骨振动传感器结合单麦克风信号的降噪方法和一种融合骨振动传感器结合双麦克风信号的降噪方法的降噪效果对比图,具体地,我们对比了8种噪音场景下分别使用《一种融合骨振动传感器和麦克风信号的深度学习语音提取和降噪方法》(申请号:201910953534.9)中方法(sensor-1mic)与本技术所述方法(sensor-2mic)处理结果,得出了图7中的客观测试结果。八种噪声分别为:酒吧噪声、公路噪声、十字路口噪声、火车站噪声、130km/h速度行驶的汽车噪声、咖啡厅噪声、餐桌上的噪声以及办公室噪声。从表中我们可以看到,在各场景下,经本技术处理后主观语音质量评估(pesq)得分都有很大提升,八个场景平均提升在0.13。这表明本技术对语音还原度更高、噪声抑制能力更强。本方法结合了骨振动传感器及双麦克风的信号,采用深度学习降噪技术,在各种噪声环境下,实现提取目标人声,降低干扰噪声。该技术可应用于耳机、手机等贴合耳部的通话场景。结合骨振动传感器可在信噪比极低的环境下,诸如:地铁、风噪等场景,依然可以保持良好的通话体验。
更进一步地,相比传统单麦克风降噪技术,本技术不对噪声做任何假设(传统单麦风降噪技术预先假设噪声为平稳噪声),利用深度神经网络强大的建模能力,有很好的人声还原度及极强的噪声抑制能力,可以解决复杂噪声场景下的人声提取问题。传统的单双麦降噪技术很难实现性能的突破,难以满足人们在地铁,马路,机场,咖啡厅等日常超级嘈杂环境中清晰的通话要求。
在本实施例中,深度神经网络是一种效果最优秀的先进的方法,具体实施例中仅示例给出了一种深度神经网络的结构作为示例。实施例中基于深度神经网络的融合模块中网络结构以卷积循环神经网络作为示例,也可替换成长短期神经网络、深度全卷积网络等结构。
本发明提供一种融合骨振动传感器和双麦克风信号的深度学习降噪方法及系统,本发明利用骨振动传感器信号不受气导噪声干扰的特性,将骨传信号作为低频输入信号,与双麦克风信号一同送入深度神经网络进行整体降噪、融合。同时送入神经网络的还有从主麦克风和次麦克风提取出来的信号空间方位特征,和从骨振动传感器提取出来的说话者的基频,声纹特征。借助骨振动传感器,我们能够得到优质的低频信号,并以此为基础,极大地提高深度神经网络预测的准确性,使得降噪效果更佳。
尽管通过以上实施例对本发明进行了揭示,但本发明的保护范围并不局限于此,在不偏离本发明构思的条件下,对以上各构件所做的变形、替换等均将落入本发明的权利要求范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



