
 商标分类
商标分类  商标转让
商标转让 
一种基于语音和文字的情绪识别方法与流程
 2021-01-28 15:01:08|
2021-01-28 15:01:08| 448|
448| 起点商标网
起点商标网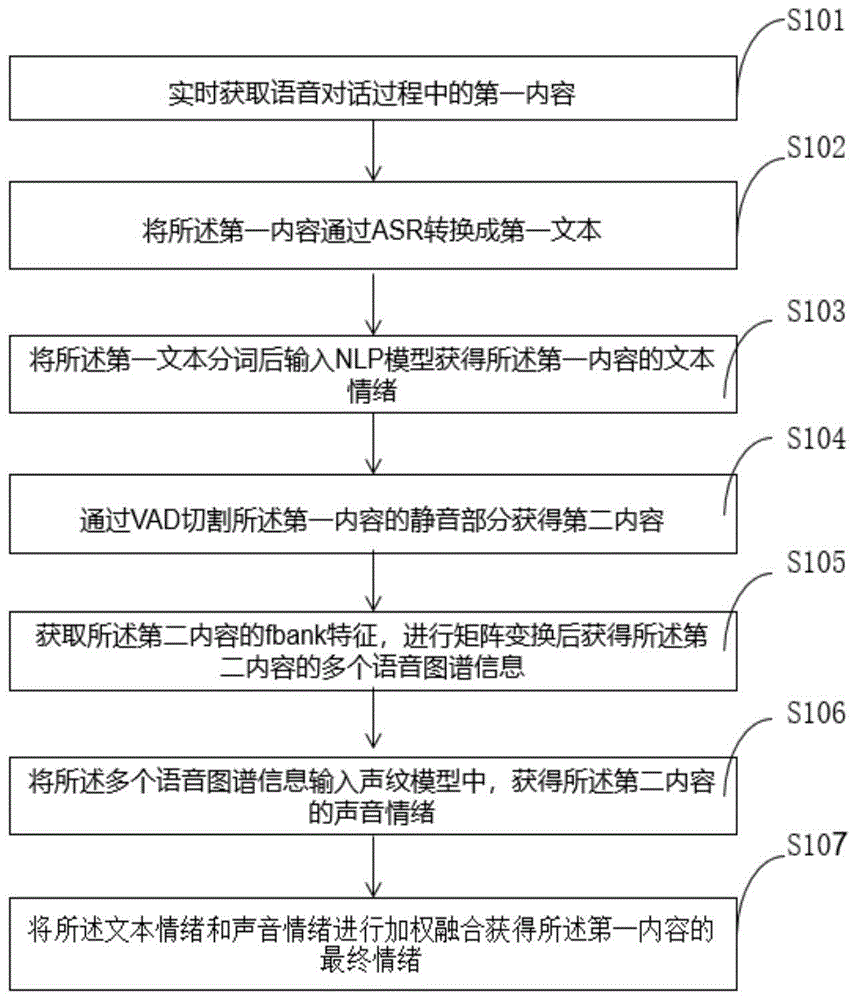
本发明涉及情绪识别,尤其涉及一种基于语音和文字的情绪识别方法。
背景技术:
随着人工智能技术的飞速发展,越来越多的智能产品运用到人们的生活中,智能外呼、智能接待、智能音响、来电助手等智能对话系统越来越成熟。而在智能语音对话中,语音ai从实时语音识别到能够理解交流对象的情绪从而作出相关的回应或安抚,或者及时通知人工介入也变得越来越重要。
现有技术中,语音ai和用户交流过程中的情绪识别大多数基于内容文本去识别情绪,通过标记正向(负向)词去计算最后的情绪,而通过文本的方式不能很准确的检测到用户实际的情绪。此外,收集正向(负向)词是一个长期费时的工作,需要不断的迭代积累,导致语音ai的成本过高。
技术实现要素:
本发明要解决的技术问题,在于提供一种基于语音和文字的情绪识别方法,结合语音和文本对用户的情绪进行识别,解决了现有技术中大多数基于内容文本去识别情绪,导致情绪识别准确率较低的技术问题。
为实现上述目的,本发明采用下述技术方案:
一种基于语音和文字的情绪识别方法,所述方法包括:
实时获取语音对话过程中的第一内容,所述第一内容为至少包含一个完整句子的wav格式的音频文件;
将所述第一内容通过asr转换成第一文本;
将所述第一文本分词后输入nlp模型获得所述第一内容的文本情绪;
通过vad切割所述第一内容的静音部分获得第二内容;
获取所述第二内容的fbank特征,进行矩阵变换后获得所述第二内容的多个语音图谱信息;
将所述多个语音图谱信息输入声纹模型中,获得所述第二内容的声音情绪;
将所述文本情绪和声音情绪进行加权融合获得所述第一内容的最终情绪。
作为优选,将所述文本情绪和声音情绪进行加权融合获得所述第一内容的最终情绪包括:
步骤s1:判断所述声音情绪的softmax分类阈值;
步骤s2:若存在所述声音情绪的softmax分类阈值≥80%的,将所述声音情绪作为所述第一内容的最终情绪,若否,执行步骤s3;
步骤s3:判断所述文本情绪的softmax分类阈值;
步骤s4:若存在所述文本情绪的softmax分类阈值≥80%的,将所述文本情绪作为所述第一内容的最终情绪,若否,执行步骤s5;
步骤s5:将无法识别作为所述第一内容的最终情绪。
作为优选,将所述文本情绪和声音情绪进行加权融合获得所述第一内容的最终情绪还包括:
若存在所述声音情绪的softmax分类阈值和所述文本情绪的softmax分类阈值均>50%,且对应的声音情绪的softmax分类和文本情绪的softmax分类不一致的,将无法识别作为所述第一内容的最终情绪。
本发明的有益效果是:本发明提供了一种基于语音和文字的情绪识别方法,综合考虑了用户的声音情绪和说话内容的文本情绪,提高了用户情绪识别的准确度。
附图说明
图1为本发明提供的一种基于语音和文字的情绪识别方法的流程示意图;
图2为本发明提供的一个示例中确定所述第一内容的最终情绪的流程示意图。
具体实施方式
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
目前语音ai和用户交流过程中的情绪识别大多数基于内容文本去识别情绪,通过标记正向(负向)词去计算最后的情绪,而通过文本的方式不能很准确的检测到用户实际的情绪。此外,收集正向(负向)词是一个长期费时的工作,需要不断的迭代积累,导致语音ai的成本过高。
为了能够解决现有技术中大多数基于内容文本去识别情绪,导致情绪识别准确率较低的技术问题,本发明实施例提供一种基于语音和文字的情绪识别方法。
以下结合附图,详细说明本发明中各实施例提供的技术方案。
一种基于语音和文字的情绪识别方法,如附图1所示,所述方法包括:
步骤s101,实时获取语音对话过程中的第一内容;
所述第一内容为至少包含一个完整句子的wav格式的音频文件。
步骤s102,将所述第一内容通过asr转换成第一文本;
步骤s103,将所述第一文本分词后输入nlp模型获得所述第一内容的文本情绪;
步骤s104,通过vad切割所述第一内容的静音部分获得第二内容;
可以理解,所述第二内容为切除静音部分后的第一内容。
步骤s105,获取所述第二内容的fbank特征,进行矩阵变换后获得所述第二内容的多个语音图谱信息;
步骤s106,将所述多个语音图谱信息输入声纹模型中,获得所述第二内容的声音情绪;
步骤s107,将所述文本情绪和声音情绪进行加权融合获得所述第一内容的最终情绪。
针对步骤s107,在一个示例中,如附图2所示,将所述文本情绪和声音情绪进行加权融合获得所述第一内容的最终情绪包括:
步骤s1:判断所述声音情绪的softmax分类阈值;
步骤s2:若存在所述声音情绪的softmax分类阈值≥80%的,将所述声音情绪作为所述第一内容的最终情绪,若否,执行步骤s3;
步骤s3:判断所述文本情绪的softmax分类阈值;
步骤s4:若存在所述文本情绪的softmax分类阈值≥80%的,将所述文本情绪作为所述第一内容的最终情绪,若否,执行步骤s5;
步骤s5:将无法识别作为所述第一内容的最终情绪。
可选地,将所述文本情绪和声音情绪进行加权融合获得所述第一内容的最终情绪还包括:
若存在所述声音情绪的softmax分类阈值和所述文本情绪的softmax分类阈值均>50%,且对应的声音情绪的softmax分类和文本情绪的softmax分类不一致的,将无法识别作为所述第一内容的最终情绪。
可以理解,当声音情绪和文本情绪均存在softmax分类的阈值>50%,且上述声音情绪和文本情绪的softmax分类不是同一情绪分类的,将无法识别作为第一内容的最终情绪。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,这些均属于本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



