
 商标分类
商标分类  商标转让
商标转让 
一种用于语音识别的语音数据自动化标注方法和系统与流程
 2021-01-28 15:01:33|
2021-01-28 15:01:33| 341|
341| 起点商标网
起点商标网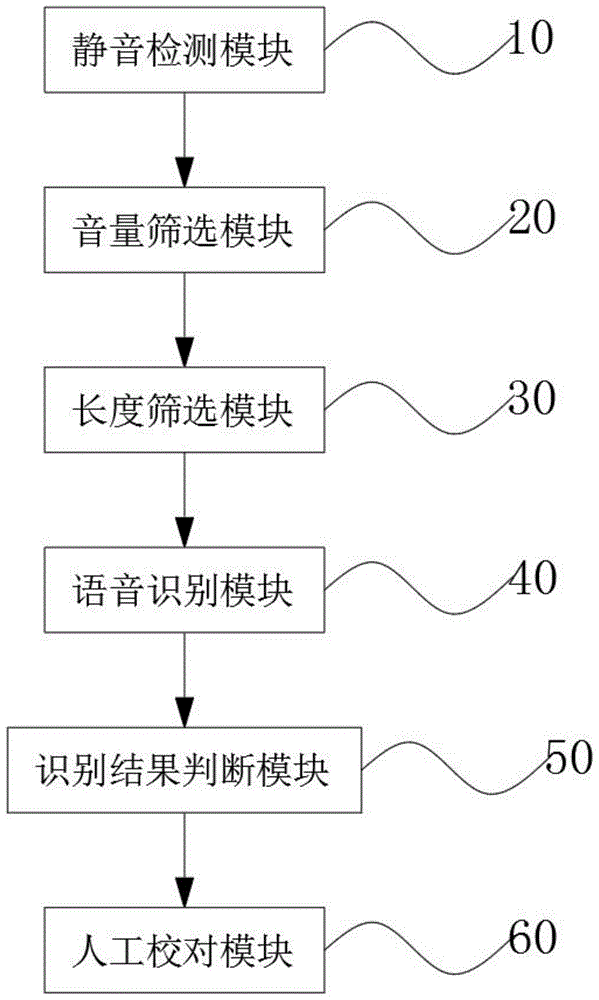
本发明涉及语音识别技术领域,更具体地说,本发明涉及一种用于语音识别的语音数据自动化标注方法和系统。
背景技术:
语音数据的标注,语音识别性能和鲁棒性很大程度上取决于识别模型建模过程中是否有精确标注的语料数据,传统的语音数据标注一般由人工来完成,这就消耗了大量的人力物力。vad(voiceactivitydetection),语音活性检测,是一项用于语音处理的技术,目的是检测语音信号是否存在,vad技术主要用于语音编码和语音识别。
随着各种智能终端的普及,以及人工智能技术的突破,语音作为人机交互的重要环节,广泛应用各种智能终端上,越来越多的用户习惯对着机器说话,根据应用需求使用语音输入信息,得到机器的响应,如用户发短信或使用聊天系统与其他人聊天时,使用语音输入需要发送的内容,利用语音识别技术将语音识别成文本,用户对识别文本进行确认后,发送出去;当然用户也可以使用语音完成其他应用需求,如语音搜索;用户在使用智能终端的过程中产生了海量语音数据。如何高效的对海量数据进行标注,得到语音数据的正确文本数据具有重要意见,利用标注后的语音数据及正确文本数据可以优化声学模型和语言模型,提升用户体验。
相关技术中,语音数据通过采用人工方式进行标注。但是,随着智能终端的广泛采用,获取到的语音数据越来越多,如果单纯依靠人工标注语音数据,远远不能满足海量语音数据标注的要求,并且人工标注的成本较高,标注周期较长,效率较低,显然不能满足应用的需求。
技术实现要素:
为了克服现有技术的上述缺陷,本发明的实施例提供一种用于语音识别的语音数据自动化标注方法和系统,本发明所要解决的技术问题是:语音数据人工标注周期长、成本高以及效率低的问题。
为实现上述目的,本发明提供如下技术方案:一种用于语音识别的语音数据自动化标注系统,包括静音检测模块、音量筛选模块、长度筛选模块、语音识别模块、识别结果判断模块和人工校对模块;
所述静音检测模块通过静音检测算法将每个语音拆分成多个语音片段;
所述音量筛选模块通过音量的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
所述长度筛选模块通过语音时长的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
所述语音识别模块通过语音识别引擎将语音识别为语音对应的文字,后期将加入新形成的语料库;
所述识别结果判断模块通过识别出文字的情况筛选符合要求的语音,将识别出文字不通畅,不准确的语音去除;
所述人工校对模块负责将符合要求的语音进行人工校对,并对符合要求的语音来进行标注,形成新的语料库。
在一个优选地实施方式中,所述语音识别模块运用百度和科大讯飞语料库,使用百度和讯飞的接口。
在一个优选地实施方式中,所述人工校对模块将语料库加入到语音识别模块中,与百度和科大讯飞语料库一起使用。
本发明还包括该用于语音识别的语音数据自动化标注系统的标注方法,具体标注步骤如下:
s1、语音预处理:
s1.1、静音检测:使用的算法为gmm(gaussianmixturemodel),由静音检测模块将待识别的语音通过静音检测算法将每个语音拆分成多个语音片段,估计数据由每个分模型生成的概率,将一定属于某一类改成了一个样本属于某类的概率;
s1.2、音量筛选:设定音量筛选模块的语音频率范围,音量筛选模块20通过音量的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
s1.3、长度筛选:设定语音片段的长度范围,由长度筛选模块通过语音时长的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
s2、语音识别:调用百度和科大讯飞语音识别的接口,由语音识别模块通过语音识别引擎将语音识别为语音对应的文字,运用百度和科大讯飞语料库,可后期将加入新形成的语料库,新形成的语料库采用sphinx4框架实现语音识别;
s3、结果判断:采用相似度算法来判断百度、讯飞等语音识别出的文字的相似度,识别结果判断模块将步骤s2中识别结果对应的文字通过识别出文字的情况筛选符合要求的语音,将识别出文字不通畅,不准确的语音去除,实现:python(语言)+mysql(数据库),符合要求的语音进入人工校对模块;
s4、人工校对:由人工校对模块将步骤s3中符合要求的语音进行人工校对,并对符合要求的语音采用xml方式存储来进行标注,形成新的语料库,并将语料库加入到语音识别模块中,与百度和科大讯飞语料库一起使用。
在一个优选地实施方式中,所述步骤s1.2中音量筛选模块的语音频率范围设置为300hz-3000hz,再由人工主观判断来度量。
在一个优选地实施方式中,所述步骤s1.3中长度筛选模块的语音片段的取帧长设置为10ms-30ms,再由人工主观判断来度量。
在一个优选地实施方式中,所述步骤s1中可按照先进行音量筛选和长度筛选,再进行静音检测。
在一个优选地实施方式中,所述步骤s3中相似度算法采用余弦相似度,取相似度大于0.5的进入人工校对模块。
本发明的技术效果和优点:
本发明通过一种多个模块的组合系统,通过语音预处理→语音识别,又采用公有云方式→识别结果判断人工校对→构建语音数据标注,经过上述过程多次迭代后,新的语料库不断训练,得到较高质量的语料数据,减少人工,提高语音数据标注质量,解决人工标注周期长、成本高以及效率低的问题。
附图说明
图1为本发明的整体模块结构示意图。
附图标记为:10静音检测模块、20音量筛选模块、30长度筛选模块、40语音识别模块、50识别结果判断模块、60人工校对模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1:
本发明提供了一种用于语音识别的语音数据自动化标注系统,包括静音检测模块10、音量筛选模块20、长度筛选模块30、语音识别模块40、识别结果判断模块50和人工校对模块60;
所述静音检测模块10通过静音检测算法将每个语音拆分成多个语音片段;
所述音量筛选模块20通过音量的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
所述长度筛选模块30通过语音时长的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
所述语音识别模块40通过语音识别引擎将语音识别为语音对应的文字,后期将加入新形成的语料库;
所述识别结果判断模块50通过识别出文字的情况筛选符合要求的语音,将识别出文字不通畅,不准确的语音去除;
所述人工校对模块60负责将符合要求的语音进行人工校对,并对符合要求的语音来进行标注,形成新的语料库。
所述语音识别模块40运用百度和科大讯飞语料库,使用百度和讯飞的接口,所述人工校对模块60将语料库加入到语音识别模块40中,与百度和科大讯飞语料库一起使用。
本发明还包括该用于语音识别的语音数据自动化标注系统的标注方法,具体标注步骤如下:
s1、语音预处理:
s1.1、静音检测:使用的算法为gmm(gaussianmixturemodel),由静音检测模块10将待识别的语音通过静音检测算法将每个语音拆分成多个语音片段,估计数据由每个分模型生成的概率,将一定属于某一类改成了一个样本属于某类的概率;
s1.2、音量筛选:设定音量筛选模块20的语音频率范围300hz-3000hz,再由人工主观判断来度量,音量筛选模块20通过音量的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
s1.3、长度筛选:设定语音片段的长度取帧长设置为10ms-30ms,再由人工主观判断来度量,由长度筛选模块30通过语音时长的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
s2、语音识别:调用百度和科大讯飞语音识别的接口,由语音识别模块40通过语音识别引擎将语音识别为语音对应的文字,运用百度和科大讯飞语料库,可后期将加入新形成的语料库,新形成的语料库采用sphinx4框架实现语音识别;
s3、结果判断:采用相似度算法来判断百度、讯飞等语音识别出的文字的相似度,采用余弦相似度,取相似度大于0.5的进入人工校对模块60,识别结果判断模块50将步骤s2中识别结果对应的文字通过识别出文字的情况筛选符合要求的语音,将识别出文字不通畅,不准确的语音去除,实现:python(语言)+mysql(数据库),符合要求的语音进入人工校对模块60;
s4、人工校对:由人工校对模块60将步骤s3中符合要求的语音进行人工校对,并对符合要求的语音采用xml方式存储来进行标注,形成新的语料库,并将语料库加入到语音识别模块40中,与百度和科大讯飞语料库一起使用。
实施例2:
本发明提供了一种用于语音识别的语音数据自动化标注系统,包括静音检测模块10、音量筛选模块20、长度筛选模块30、语音识别模块40、识别结果判断模块50和人工校对模块60;
所述静音检测模块10通过静音检测算法将每个语音拆分成多个语音片段;
所述音量筛选模块20通过音量的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
所述长度筛选模块30通过语音时长的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
所述语音识别模块40通过语音识别引擎将语音识别为语音对应的文字,后期将加入新形成的语料库;
所述识别结果判断模块50通过识别出文字的情况筛选符合要求的语音,将识别出文字不通畅,不准确的语音去除;
所述人工校对模块60负责将符合要求的语音进行人工校对,并对符合要求的语音来进行标注,形成新的语料库。
所述语音识别模块40运用百度和科大讯飞语料库,使用百度和讯飞的接口,所述人工校对模块60将语料库加入到语音识别模块40中,与百度和科大讯飞语料库一起使用。
本发明还包括该用于语音识别的语音数据自动化标注系统的标注方法,具体标注步骤如下:
s1、语音预处理:
s1.1、音量筛选:设定音量筛选模块20的语音频率范围300hz-3000hz,再由人工主观判断来度量,音量筛选模块20通过音量的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
s1.2、长度筛选:设定语音片段的长度取帧长设置为10ms-30ms,再由人工主观判断来度量,由长度筛选模块30通过语音时长的阈值将符合要求的语音筛选出来,将不符合要求的语音去除;
s1.1、静音检测:使用的算法为gmm(gaussianmixturemodel),由静音检测模块10将待识别的语音通过静音检测算法将每个语音拆分成多个语音片段,估计数据由每个分模型生成的概率,将一定属于某一类改成了一个样本属于某类的概率;
s2、语音识别:调用百度和科大讯飞语音识别的接口,由语音识别模块40通过语音识别引擎将语音识别为语音对应的文字,运用百度和科大讯飞语料库,可后期将加入新形成的语料库,新形成的语料库采用sphinx4框架实现语音识别;
s3、结果判断:采用相似度算法来判断百度、讯飞等语音识别出的文字的相似度,采用余弦相似度,取相似度大于0.5的进入人工校对模块60,识别结果判断模块50将步骤s2中识别结果对应的文字通过识别出文字的情况筛选符合要求的语音,将识别出文字不通畅,不准确的语音去除,实现:python(语言)+mysql(数据库),符合要求的语音进入人工校对模块60;
s4、人工校对:由人工校对模块60将步骤s3中符合要求的语音进行人工校对,并对符合要求的语音采用xml方式存储来进行标注,形成新的语料库,并将语料库加入到语音识别模块40中,与百度和科大讯飞语料库一起使用。
如图1所示的,实施方式具体为:在语音标注的过程中主要加入了音量筛选模块20、长度筛选模块30和识别结果判断模块50;又在语音识别模块40中,先采用百度和科大讯飞公有云方式来进行语音识别,对语音进行标注,形成新的语料库,再以后的迭代中在语音识别模块40中,不但采用了百度和科大讯飞公有云方式来进行语音识别,也加入新建的语料库进行语音的训练和识别,这样就提高了语音标准的质量了,减少人工。
最后应说明的几点是:首先,在本申请的描述中,需要说明的是,除非另有规定和限定,术语“安装”、“相连”、“连接”应做广义理解,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变,则相对位置关系可能发生改变;
其次:本发明公开实施例附图中,只涉及到与本公开实施例涉及到的结构,其他结构可参考通常设计,在不冲突情况下,本发明同一实施例及不同实施例可以相互组合;
最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



