
 商标分类
商标分类  商标转让
商标转让 
一种二次利用语音存在概率的语音降噪方法与流程
 2021-01-28 15:01:12|
2021-01-28 15:01:12| 282|
282| 起点商标网
起点商标网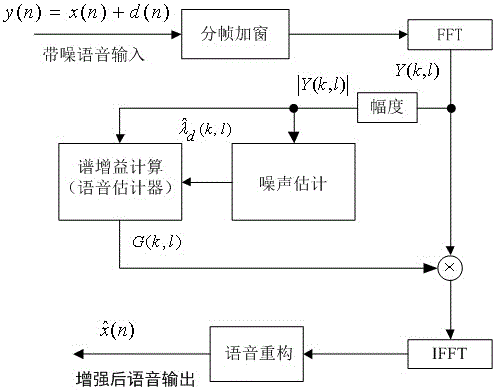
本发明属于人工智能技术领域,涉及语音识别,具体涉及一种二次利用语音存在概率的语音降噪方法。
背景技术:
语音降噪技术属于语音前端处理技术,它的目的是从带噪语音中滤除背景噪声,留下纯净语音。但是处理过后的语音信号要和原始语音完全一样是不可能的,即语音降噪或多或少会给语音带来一定失真,语音降噪是要找到一种算法能够有效地达到以下两个目的:一是抑制语音中的噪声,提高信噪比;二是围绕语音听感以及语音清晰度这两个方面做改进,尽量做到声音不失真。
技术实现要素:
为克服现有技术存在的缺陷,本发明公开了一种二次利用语音存在概率的语音降噪方法。
本发明所述二次利用语音存在概率的语音降噪方法,包括以下步骤:
s1对带噪语音进行逐帧读取,并将连续的多帧作为噪声估计的初始值;
s2以初始值为基础,通过递归的最小值统计法来进行每一帧的噪声估计;
s3使用估计出的噪声值,求得语音存在概率;
s4将语音存在概率和谱估计器进行结合;
s5使用结合后的谱估计器来求取最终降噪后的语音。
优选的:所述步骤s2中,对初始值的语音信号分帧并加窗处理,然后对每帧语音做快速傅里叶变换得到其频谱
优选的:所述步骤s3中,先根据噪声估计值求得后验信噪比,再利用直接平滑准则,得到先验信噪比;
并根据先验信噪比计算语音存在概率
优选的:所述步骤s4中结合的具体方式为:
g1为结合后的谱估计器,
进一步的:f函数为:
优选的:所述步骤s4中结合的具体方式为:
其中g1为结合后的谱估计器,gc为原
进一步的:通过下列函数确定
进一步的:对g1进行第二次结合语音存在概率,得到的最终谱估计器如以下形式:
本发明通过求得的语音存在概率,利用其动态调节不同的语音谱估计器的权重或参数,通过语音存在概率与语音谱估计器的结合,更好的抑制噪声并减小失真;并可以对求得的谱估计值二次利用语音存在概率来动态调整,以进一步抑制噪声。
附图说明
图1是本发明所述语音降噪方法的一个具体实施方式流程示意图;
图1中输入的x(n)表示目标人声,d(n)是环境噪声;
图2是本发明所述
图3是本发明所述语音存在概率映射到参数
图4为利用本发明进行带噪语音处理前后的一个具体实例的时域波形图,图4中纵坐标为归一化的语音信号幅度。
具体实施方式
下面对本发明的具体实施方式作进一步的详细说明。
本发明所述二次利用语音存在概率的语音降噪方法,包括如下步骤:
对带噪语音进行逐帧读取语音数据,并将连续多帧语音数据作为噪声估计的初始值;
以初始值为基础,可以通过递归的最小值统计法来进行每一帧的噪声估计,得到噪声估计值。
具体可以是:对语音信号分帧并加窗处理,然后对每帧语音做短时fft即快速傅里叶变换得到其频谱
使用噪声估计值,求得语音的先验信噪比和后验信噪比;
可以先求得后验信噪比,再利用直接平滑准则,得到先验信噪比;
根据先验信噪比和后验信噪比计算语音存在概率
将语音存在概率和谱估计器结合。
结合可以采用以下两种方式
第一种形式的结合方式可以如下式:
其中
f的下标1,2...表示不同的权重值,ga,gb表示两种在不同信噪比条件下各具优势的语音谱估计器.
第一种结合方式中,f函数的一个具体实施方式可以为:
第二种形式的结合方式可以如下式:
f(*)为符合
以下给出第二种形式结合的一个更具体的实施方式:
该具体实施方式中,通过语音存在概率
可以把
当
其中gc为原
这一类语音谱估计器中包含和信噪比相关且能够动态调整的参数
以下例子为通过语音存在概率来推算
对当前帧的语音存在概率求平均,并可以通过下列函数确定
语音存在概率映射到参数
为了进一步提升噪声抑制性能。将谱估计器
第二次结合语音存在概率后得到的最终谱估计器如以下形式:
利用结合后的最终谱估计器进行降噪,具体为:
使用该最终谱估计来求取最终降噪后的语音。
在通过语音存在概率计算谱估计器的基础上,并与谱估计器二次结合,进一步提高了降噪效果。
图4为利用本发明进行带噪语音处理前后的一个具体实例的时域波形图,上半部分为处理前,下半部分为处理后,从图4可以看出,处理后的波形噪声显著缩小。
本发明通过求得的语音存在概率,利用其动态调节不同的语音谱估计器的权重或参数,通过语音存在概率与语音谱估计器的结合,更好的抑制噪声并减小失真;并可以对求得的谱估计值二次利用语音存在概率来动态调整,以进一步抑制噪声。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



