
 商标分类
商标分类  商标转让
商标转让 
联合模型的语音识别方法、装置和计算机设备与流程
 2021-01-28 15:01:42|
2021-01-28 15:01:42| 289|
289| 起点商标网
起点商标网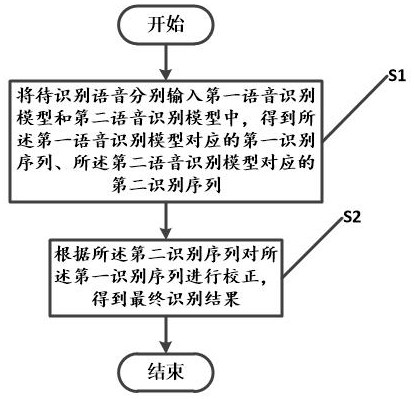
本申请涉及语音识别技术领域,特别涉及一种联合模型的语音识别方法、装置和计算机设备。
背景技术:
现有技术中,语音识别模型法是一种广泛应用的语音识别技术,语音识别模型法可分为基于人工神经网络的方法和基于隐马尔可夫模型的方法,但对于语音分割任务,这两种方法均存在一定的局限性(基于人工神经网络的方法无法有效分辨出空白标签对应的声学单元;而隐马尔可夫模型预测出来的声学单元严重依赖基于hmm(hiddenmarkovmodel)的语音识别模型的识别率,如果模型的预测结果与待分割语音的真实标签存在较大误差,那么分割出来的语音标签就存在错误标识),导致采用这两种语音识别方法进行语音分割的准确度较低。
技术实现要素:
本申请的主要目的为提供一种联合模型的语音识别方法、装置和计算机设备,旨在解决现有语音识别模型法的语音分割的准确度较低的弊端。
为实现上述目的,本申请提供了一种基于联合模型的语音识别方法,包括:
将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列,其中,所述第一语音识别模型为基于hmm的语音识别模型,所述第二语音识别模型为端到端语音识别模型;
根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果。
进一步的,所述第一识别序列为词格形式,所述根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果的步骤,包括:
以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度;
根据所述序列相似度对所述第一识别序列的最优路径进行权重更新;
从权重更新后的所述第一识别序列中,解码得到最优输出序列,并将所述最优输出序列作为所述最终识别结果。
进一步的,所述以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度的步骤,包括:
从所述第一识别序列中筛选出最优路径输出序列;
调用最少编辑距离算法,计算所述最优路径输出序列和所述第二识别序列之间的编辑距离;
将所述编辑距离代入第一公式中,计算得到所述序列相似度,其中,所述第一公式为:
进一步的,所述根据所述序列相似度对所述第一识别序列的最优路径进行权重更新的步骤,包括:
将所述序列相似度代入第二公式,计算出更新转移概率,其中,所述第二公式为:
使用所述pn替换所述最优路径输出序列对应的所述hn,实现对所述第一识别序列的最优路径进行权重更新。
进一步的,所述从权重更新后的所述第一识别序列中,解码得到最优输出序列的步骤,包括:
分别计算权重更新后的所述第一识别序列中各路径的累积转移概率;
从所述第一识别序列的各路径中,选择最大的累积转移概率对应的路径进行解码,得到所述最优输出序列。
进一步的,所述将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列的步骤之后,包括:
判断所述第一识别序列与所述第二识别序列是否为不等长序列;
若所述第一识别序列与所述第二识别序列为不等长序列,则判定所述第一语音识别模型不能有效分割所述待识别语音,并输出提示信息。
进一步的,所述将所述最优输出序列作为所述最终识别结果的步骤,包括:
采用词格工具提取所述待识别语音的对齐信息;
使用所述对齐信息对所述最优输出序列进行归类,得到所述最终识别结果。
本申请还提供了一种基于联合模型的语音识别装置,包括:
第一识别模块,用于将待识别语音输入第一语音识别模型中,得到第一识别序列,其中,所述第一语音识别模型为基于hmm的语音识别模型;
第二识别模块,用于将待识别语音输入第二语音识别模型中,得到第二识别序列,其中,所述第二语音识别模型为端到端语音识别模型;
校正模块,用于根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果。
进一步的,所述校正模块,包括:
计算单元,用于以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度;
更新单元,用于根据所述序列相似度对所述第一识别序列的最优路径进行权重更新;
解码单元,用于从权重更新后的所述第一识别序列中,解码得到最优输出序列,并将所述最优输出序列作为所述最终识别结果。
进一步的,所述计算单元,包括:
筛选子单元,用于从所述第一识别序列中筛选出最优路径输出序列;
第一计算子单元,用于调用最少编辑距离算法,计算所述最优路径输出序列和所述第二识别序列之间的编辑距离;
第二计算子单元,用于将所述编辑距离代入第一公式中,计算得到所述序列相似度,其中,所述第一公式为:
进一步的,所述更新单元,包括:
第三计算子单元,用于将所述序列相似度代入第二公式,计算出更新转移概率,其中,所述第二公式为:
更新子单元,用于使用所述pn替换所述最优路径输出序列对应的所述hn,实现对所述第一识别序列的最优路径进行权重更新。
进一步的,所述解码单元,包括:
第四计算子单元,用于分别计算权重更新后的所述第一识别序列中各路径的累积转移概率;
解码子单元,用于从所述第一识别序列的各路径中,选择最大的累积转移概率对应的路径进行解码,得到所述最优输出序列。
进一步的,所述语音识别装置,还包括:
判断模块,用于判断所述第一识别序列与所述第二识别序列是否为不等长序列;
提示模块,用于若所述第一识别序列与所述第二识别序列为不等长序列,则判定所述第一语音识别模型不能有效分割所述待识别语音,并输出提示信息。
进一步的,所述解码单元,还包括:
提取子单元,用于采用词格工具提取所述待识别语音的对齐信息;
归类子单元,用于使用所述对齐信息对所述最优输出序列进行归类,得到所述最终识别结果。
本申请还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
本申请还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的方法的步骤。
本申请中提供的一种联合模型的语音识别方法、装置和计算机设备,首先将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到第一语音识别模型对应的第一识别序列、第二语音识别模型对应的第二识别序列,其中,第一语音识别模型为基于hmm的语音识别模型,第二语音识别模型为端到端语音识别模型。系统根据第二识别序列对所述第一识别序列进行校正,得到最终识别结果。本申请通过将两种不同类型的语音识别模型的识别序列进行相互结合,通过第二识别序列对第一识别序列进行校正,从而有效提高对语音分割的准确度。
附图说明
图1是本申请一实施例中联合模型的语音识别方法步骤示意图;
图2是本申请一实施例中联合模型的语音识别装置整体结构框图;
图3是本申请一实施例的计算机设备的结构示意框图。
本申请目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
参照图1,本申请一实施例中提供了一种基于联合模型的语音识别方法,包括:
s1:将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列,其中,所述第一语音识别模型为基于hmm的语音识别模型,所述第二语音识别模型为端到端语音识别模型;
s2:根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果。
本实施例中,系统在接收到待识别语音后,将待识别语音分别输入第一语音识别模型和第二语音识别模型中,经过语音识别模型对待识别语音的相应处理后,第一语音识别模型输出第一识别序列,第二语音识别模型输出第二识别序列。第一语音识别模型为基于hmm的语音识别模型(比如hmm-gmm、hmm-dnn、hmm-lstm等关于hmm和人工神经网络的混合结构),第一语音识别模型训练时,按7:2:2的比例划分aishell1语料库,分别获得训练集、验证集和测试集,训练集和验证集用于基于hmm的语音识别模型训练,测试集则是用于测试基于hmm的语音识别模型训练后的准确率。基于hmm的语音识别模型的模型输入特征采用39维的mfcc特征,在傅里叶变换过程中,语音帧长为25ms,帧移为10ms。模型训练过程中,采用kaldi工具箱进行搭建hmm-gmm语音识别模型,该模型采用三音素作为hmm的隐含状态,其中采用决策树进行聚类后的有效三音素为6890个,模型训练过程中采用400个单高斯模型对语音特征进行分类。第二语音识别模型为端到端语音识别模型(比如lstm-ctc和基于注意力机制模型),第二语音识别模型训练时,同样按7:2:2的比例划分aishell1语料库,分别获得训练集、验证集和测试集,训练集、验证集用于端到端语音识别模型训练,测试集则是用于测试端到端语音识别模型训练后的准确率。端到端语音识别模型的模型输入特征采用161维的对数幅度谱特征,在傅里叶变换过程中,语音帧长为25ms,帧移为10ms。模型训练过程中,采用espnet平台搭建基于lstm-ctc的端到端语音识别模型,模型具体由3层cnn+2层blstm+2层dnn组成,模型输入维度设置为60*161,对应的输出维度为60*4096,其中核心单元blstm采用单向2048个神经元。系统采用第二识别序列对第一识别序列进行校正,从而提高第一识别序列的准确率,矫正后的第一识别序列即为最终识别结果。具体地,在本实施例中,第一识别序列为词格形式(词格形式包含多种解码途径)系统以第二识别序列为基准,首先计算出第一识别序列与第二识别序列之间的序列相似度。然后,根据序列相似度对第一识别序列的最优路径进行权重更新(权重更新后的第一识别序列的各个解码路径都会发生变更),系统从权重更新后的第一识别序列(此时依然是词格形式)中,通过维比特算法解码得到最优输出序列,并将最优输出序列作为最终识别结果,完成对待识别语音的语音识别。本实施例中,通过将两种不同类型的语音识别模型(基于hmm的语音识别模型和端到端语音识别模型)的识别结果进行结合,以第二识别序列为基础,对第一识别序列进行校验,从而有效提高对待识别语音的识别准确率。
进一步的,所述第一识别序列为词格形式,所述根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果的步骤,包括:
s201:以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度;
s202:根据所述序列相似度对所述第一识别序列的最优路径进行权重更新;
s203:从权重更新后的所述第一识别序列中,解码得到最优输出序列,并将所述最优输出序列作为所述最终识别结果。
本实施例中,系统以第二识别序列为基准,调用预设算法计算得到第一识别序列与第二识别序列之间的序列相似度。具体地,系统首先通过维比特算法从第一识别序列中筛选出最优路径输出序列,再调用最少编辑算法,计算最优路径输出序列与第二识别序列之间的编辑距离。系统将编辑距离代入第一公式中,计算得到序列相似度。其中,第一公式为:
进一步的,所述以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度的步骤,包括:
s2011:从所述第一识别序列中筛选出最优路径输出序列;
s2012:调用最少编辑距离算法,计算所述最优路径输出序列和所述第二识别序列之间的编辑距离;
s2013:将所述编辑距离代入第一公式中,计算得到所述序列相似度,其中,所述第一公式为:
本实施例中,词格形式的第一识别序列包含有多种解码路径,系统通过维比特算法从第一识别序列中筛选出最优路径输出序列(即累积转移概率最大的路径所形成的序列)。系统采用最少编辑距离算法(其中编辑动作包括删除、替换和插入三种),计算出最优路径输出序列和第二识别序列之间的编辑距离。系统调用第一公式,并将编辑距离代入第一公式中,计算得到最优路径输出序列和第二识别序列之间的编辑距离。其中,第一公式为:
进一步的,所述根据所述序列相似度对所述第一识别序列的最优路径进行权重更新的步骤,包括:
s2021:将所述序列相似度代入第二公式,计算出更新转移概率,其中,所述第二公式为:
s2022:使用所述pn替换所述最优路径输出序列对应的所述hn,实现对所述第一识别序列的最优路径进行权重更新。
本实施例中,系统调用第二公式,并将序列相似度代入第二公式中,从而计算出更新转移概率。其中,第二公式为:
进一步的,所述从权重更新后的所述第一识别序列中,解码得到最优输出序列的步骤,包括:
s2031:分别计算权重更新后的所述第一识别序列中各路径的累积转移概率;
s2032:从所述第一识别序列的各路径中,选择最大的累积转移概率对应的路径进行解码,得到所述最优输出序列。
本实施例中,系统分别计算权重更新后的第一识别序列中各解码路径的累积转移概率,其中累积转移概率为解码路径所对应的各个转移概率的乘积。系统从计算后的各个累积转移概率中筛选出最大的一个累积转移概率,最大的累积转移概率所对应的路径即为第一识别序列权重更新后的最优路径。系统对最大的累积转移概率对应的路径进行解码,从而得到最优输出序列。
进一步的,所述所述将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列的步骤之后,包括:
s3:判断所述第一识别序列与所述第二识别序列是否为不等长序列;
s4:若所述第一识别序列与所述第二识别序列为不等长序列,则判定所述第一语音识别模型不能有效分割所述待识别语音,并输出提示信息。
本实施例中,系统判断第一识别序列和第二识别序列是否为不等长序列,如果第一识别序列与第二识别序列为不等长序列,则判定第一语音识别模型在分割待识别语音时,无法有效分割其中的语音帧,并输出相应的提示信息。用户在接收到提示信息后,可以重新采集待识别语音。
进一步的,所述将所述最优输出序列作为所述最终识别结果的步骤,包括:
s401:采用词格工具提取所述待识别语音的对齐信息;
s402:使用所述对齐信息对所述最优输出序列进行归类,得到所述最终识别结果。
本实施例中,系统调用kaldi的词格工具提取待识别语音的对齐信息,其中,对齐信息包括字和词组的解码id、解码id对应的hmm状态。系统根据对齐信息对重新编码后的最优输出序列进行归类,实现待识别语音中语音帧与识别文字之间的对齐,对齐后得到最终识别结果并输出,完成待识别语音的整个识别流程。
本实施例提供的一种联合模型的语音识别方法、装置和计算机设备,首先将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到第一语音识别模型对应的第一识别序列、第二语音识别模型对应的第二识别序列,其中,第一语音识别模型为基于hmm的语音识别模型,第二语音识别模型为端到端语音识别模型。系统根据第二识别序列对所述第一识别序列进行校正,得到最终识别结果。本申请通过将两种不同类型的语音识别模型的识别序列进行相互结合,通过第二识别序列对第一识别序列进行校正,从而有效提高对语音分割的准确度。
参照图2,本申请一实施例中还提供了一种基于联合模型的语音识别装置,包括:
第一识别模块1,用于将待识别语音输入第一语音识别模型中,得到第一识别序列,其中,所述第一语音识别模型为基于hmm的语音识别模型;
第二识别模块2,用于将待识别语音输入第二语音识别模型中,得到第二识别序列,其中,所述第二语音识别模型为端到端语音识别模型;
校正模块3,用于根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果。
本实施例中,系统在接收到待识别语音后,将待识别语音分别输入第一语音识别模型和第二语音识别模型中,经过语音识别模型对待识别语音的相应处理后,第一语音识别模型输出第一识别序列,第二语音识别模型输出第二识别序列。第一语音识别模型为基于hmm的语音识别模型(比如hmm-gmm、hmm-dnn、hmm-lstm等关于hmm和人工神经网络的混合结构),第一语音识别模型训练时,按7:2:2的比例划分aishell1语料库,分别获得训练集、验证集和测试集,训练集和验证集用于基于hmm的语音识别模型训练,测试集则是用于测试基于hmm的语音识别模型训练后的准确率。基于hmm的语音识别模型的模型输入特征采用39维的mfcc特征,在傅里叶变换过程中,语音帧长为25ms,帧移为10ms。模型训练过程中,采用kaldi工具箱进行搭建hmm-gmm语音识别模型,该模型采用三音素作为hmm的隐含状态,其中采用决策树进行聚类后的有效三音素为6890个,模型训练过程中采用400个单高斯模型对语音特征进行分类。第二语音识别模型为端到端语音识别模型(比如lstm-ctc和基于注意力机制模型),第二语音识别模型训练时,同样按7:2:2的比例划分aishell1语料库,分别获得训练集、验证集和测试集,训练集、验证集用于端到端语音识别模型训练,测试集则是用于测试端到端语音识别模型训练后的准确率。端到端语音识别模型的模型输入特征采用161维的对数幅度谱特征,在傅里叶变换过程中,语音帧长为25ms,帧移为10ms。模型训练过程中,采用espnet平台搭建基于lstm-ctc的端到端语音识别模型,模型具体由3层cnn+2层blstm+2层dnn组成,模型输入维度设置为60*161,对应的输出维度为60*4096,其中核心单元blstm采用单向2048个神经元。系统采用第二识别序列对第一识别序列进行校正,从而提高第一识别序列的准确率,矫正后的第一识别序列即为最终识别结果。具体地,在本实施例中,第一识别序列为词格形式(词格形式包含多种解码途径)系统以第二识别序列为基准,首先计算出第一识别序列与第二识别序列之间的序列相似度。然后,根据序列相似度对第一识别序列的最优路径进行权重更新(权重更新后的第一识别序列的各个解码路径都会发生变更),系统从权重更新后的第一识别序列(此时依然是词格形式)中,通过维比特算法解码得到最优输出序列,并将最优输出序列作为最终识别结果,完成对待识别语音的语音识别。本实施例中,通过将两种不同类型的语音识别模型(基于hmm的语音识别模型和端到端语音识别模型)的识别结果进行结合,以第二识别序列为基础,对第一识别序列进行校验,从而有效提高对待识别语音的识别准确率。
进一步的,所述校正模块3,包括:
计算单元,用于以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度;
更新单元,用于根据所述序列相似度对所述第一识别序列的最优路径进行权重更新;
解码单元,用于从权重更新后的所述第一识别序列中,解码得到最优输出序列,并将所述最优输出序列作为所述最终识别结果。
本实施例中,系统以第二识别序列为基准,调用预设算法计算得到第一识别序列与第二识别序列之间的序列相似度。具体地,系统首先通过维比特算法从第一识别序列中筛选出最优路径输出序列,再调用最少编辑算法,计算最优路径输出序列与第二识别序列之间的编辑距离。系统将编辑距离代入第一公式中,计算得到序列相似度。其中,第一公式为:
进一步的,所述计算单元,包括:
筛选子单元,用于从所述第一识别序列中筛选出最优路径输出序列;
第一计算子单元,用于调用最少编辑距离算法,计算所述最优路径输出序列和所述第二识别序列之间的编辑距离;
第二计算子单元,用于将所述编辑距离代入第一公式中,计算得到所述序列相似度,其中,所述第一公式为:
本实施例中,词格形式的第一识别序列包含有多种解码路径,系统通过维比特算法从第一识别序列中筛选出最优路径输出序列(即累积转移概率最大的路径所形成的序列)。系统采用最少编辑距离算法(其中编辑动作包括删除、替换和插入三种),计算出最优路径输出序列和第二识别序列之间的编辑距离。系统调用第一公式,并将编辑距离代入第一公式中,计算得到最优路径输出序列和第二识别序列之间的编辑距离。其中,第一公式为:
进一步的,所述更新单元,包括:
第三计算子单元,用于将所述序列相似度代入第二公式,计算出更新转移概率,其中,所述第二公式为:
更新子单元,用于使用所述pn替换所述最优路径输出序列对应的所述hn,实现对所述第一识别序列的最优路径进行权重更新。
本实施例中,系统调用第二公式,并将序列相似度代入第二公式中,从而计算出更新转移概率。其中,第二公式为:
进一步的,所述解码单元,包括:
第四计算子单元,用于分别计算权重更新后的所述第一识别序列中各路径的累积转移概率;
解码子单元,用于从所述第一识别序列的各路径中,选择最大的累积转移概率对应的路径进行解码,得到所述最优输出序列。
本实施例中,系统分别计算权重更新后的第一识别序列中各解码路径的累积转移概率,其中累积转移概率为解码路径所对应的各个转移概率的乘积。系统从计算后的各个累积转移概率中筛选出最大的一个累积转移概率,最大的累积转移概率所对应的路径即为第一识别序列权重更新后的最优路径。系统对最大的累积转移概率对应的路径进行解码,从而得到最优输出序列。
进一步的,所述语音识别装置,还包括:
判断模块4,用于判断所述第一识别序列与所述第二识别序列是否为不等长序列;
提示模块5,用于若所述第一识别序列与所述第二识别序列为不等长序列,则判定所述第一语音识别模型不能有效分割所述待识别语音,并输出提示信息。
本实施例中,系统判断第一识别序列和第二识别序列是否为不等长序列,如果第一识别序列与第二识别序列为不等长序列,则判定第一语音识别模型在分割待识别语音时,无法有效分割其中的语音帧,并输出相应的提示信息。用户在接收到提示信息后,可以重新采集待识别语音。
进一步的,所述解码单元,还包括:
提取子单元,用于采用词格工具提取所述待识别语音的对齐信息;
归类子单元,用于使用所述对齐信息对所述最优输出序列进行归类,得到所述最终识别结果。
本实施例中,系统调用kaldi的词格工具提取待识别语音的对齐信息,其中,对齐信息包括字和词组的解码id、解码id对应的hmm状态。系统根据对齐信息对重新编码后的最优输出序列进行归类,实现待识别语音中语音帧与识别文字之间的对齐,对齐后得到最终识别结果并输出,完成待识别语音的整个识别流程。
本实施例提供的一种联合模型的语音识别装置,首先将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到第一语音识别模型对应的第一识别序列、第二语音识别模型对应的第二识别序列,其中,第一语音识别模型为基于hmm的语音识别模型,第二语音识别模型为端到端语音识别模型。系统根据第二识别序列对所述第一识别序列进行校正,得到最终识别结果。本申请通过将两种不同类型的语音识别模型的识别序列进行相互结合,通过第二识别序列对第一识别序列进行校正,从而有效提高对语音分割的准确度。
参照图3,本申请实施例中还提供一种计算机设备,该计算机设备可以是服务器,其内部结构可以如图3所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设计的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储第一公式等数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于联合模型的语音识别方法。
上述处理器执行上述基于联合模型的语音识别方法的步骤:
s1:将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列,其中,所述第一语音识别模型为基于hmm的语音识别模型,所述第二语音识别模型为端到端语音识别模型;
s2:根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果。
进一步的,所述第一识别序列为词格形式,所述根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果的步骤,包括:
s201:以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度;
s202:根据所述序列相似度对所述第一识别序列的最优路径进行权重更新;
s203:从权重更新后的所述第一识别序列中,解码得到最优输出序列,并将所述最优输出序列作为所述最终识别结果。
进一步的,所述以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度的步骤,包括:
s2011:从所述第一识别序列中筛选出最优路径输出序列;
s2012:调用最少编辑距离算法,计算所述最优路径输出序列和所述第二识别序列之间的编辑距离;
s2013:将所述编辑距离代入第一公式中,计算得到所述序列相似度,其中,所述第一公式为:
进一步的,所述根据所述序列相似度对所述第一识别序列的最优路径进行权重更新的步骤,包括:
s2021:将所述序列相似度代入第二公式,计算出更新转移概率,其中,所述第二公式为:
s2022:使用所述pn替换所述最优路径输出序列对应的所述hn,实现对所述第一识别序列的最优路径进行权重更新。
进一步的,所述从权重更新后的所述第一识别序列中,解码得到最优输出序列的步骤,包括:
s2031:分别计算权重更新后的所述第一识别序列中各路径的累积转移概率;
s2032:从所述第一识别序列的各路径中,选择最大的累积转移概率对应的路径进行解码,得到所述最优输出序列。
进一步的,所述所述将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列的步骤之后,包括:
s3:判断所述第一识别序列与所述第二识别序列是否为不等长序列;
s4:若所述第一识别序列与所述第二识别序列为不等长序列,则判定所述第一语音识别模型不能有效分割所述待识别语音,并输出提示信息。
进一步的,所述将所述最优输出序列作为所述最终识别结果的步骤,包括:
s401:采用词格工具提取所述待识别语音的对齐信息;
s402:使用所述对齐信息对所述最优输出序列进行归类,得到所述最终识别结果。
本申请一实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现一种基于联合模型的语音识别方法,所述语音识别方法包括具体为:
s1:将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列,其中,所述第一语音识别模型为基于hmm的语音识别模型,所述第二语音识别模型为端到端语音识别模型;
s2:根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果。
进一步的,所述第一识别序列为词格形式,所述根据所述第二识别序列对所述第一识别序列进行校正,得到最终识别结果的步骤,包括:
s201:以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度;
s202:根据所述序列相似度对所述第一识别序列的最优路径进行权重更新;
s203:从权重更新后的所述第一识别序列中,解码得到最优输出序列,并将所述最优输出序列作为所述最终识别结果。
进一步的,所述以所述第二识别序列为基准,调用预设算法计算得到所述第一识别序列与所述第二识别序列之间的序列相似度的步骤,包括:
s2011:从所述第一识别序列中筛选出最优路径输出序列;
s2012:调用最少编辑距离算法,计算所述最优路径输出序列和所述第二识别序列之间的编辑距离;
s2013:将所述编辑距离代入第一公式中,计算得到所述序列相似度,其中,所述第一公式为:
进一步的,所述根据所述序列相似度对所述第一识别序列的最优路径进行权重更新的步骤,包括:
s2021:将所述序列相似度代入第二公式,计算出更新转移概率,其中,所述第二公式为:
s2022:使用所述pn替换所述最优路径输出序列对应的所述hn,实现对所述第一识别序列的最优路径进行权重更新。
进一步的,所述从权重更新后的所述第一识别序列中,解码得到最优输出序列的步骤,包括:
s2031:分别计算权重更新后的所述第一识别序列中各路径的累积转移概率;
s2032:从所述第一识别序列的各路径中,选择最大的累积转移概率对应的路径进行解码,得到所述最优输出序列。
进一步的,所述所述将待识别语音分别输入第一语音识别模型和第二语音识别模型中,得到所述第一语音识别模型对应的第一识别序列、所述第二语音识别模型对应的第二识别序列的步骤之后,包括:
s3:判断所述第一识别序列与所述第二识别序列是否为不等长序列;
s4:若所述第一识别序列与所述第二识别序列为不等长序列,则判定所述第一语音识别模型不能有效分割所述待识别语音,并输出提示信息。
进一步的,所述将所述最优输出序列作为所述最终识别结果的步骤,包括:
s401:采用词格工具提取所述待识别语音的对齐信息;
s402:使用所述对齐信息对所述最优输出序列进行归类,得到所述最终识别结果。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储与一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的和实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可以包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram通过多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双速据率sdram(ssrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其它变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、装置、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其它要素,或者是还包括为这种过程、装置、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、装置、物品或者方法中还存在另外的相同要素。
以上所述仅为本申请的优选实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本申请的专利保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



