
 商标分类
商标分类  商标转让
商标转让 
一种辅助语音识别控制方法和装置与流程
 2021-01-28 15:01:05|
2021-01-28 15:01:05| 287|
287| 起点商标网
起点商标网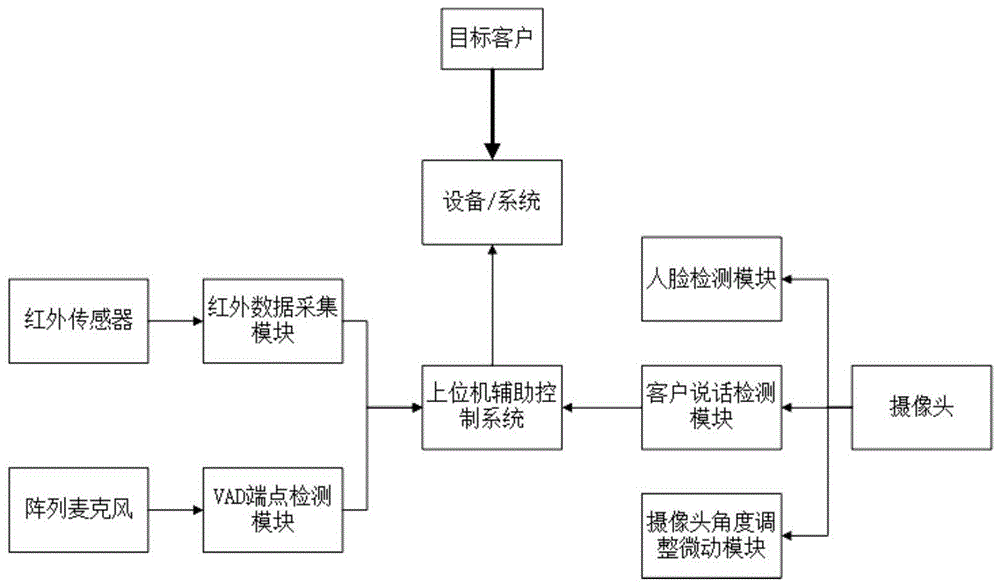
本发明属于语音识别技术领域,尤其涉及一种辅助语音识别控制方法和装置。
背景技术:
在语音识别系统中,正确有效的进行语音端点检测(voiceactivitydetection,vad)不仅可以减少计算量和缩短处理时间,而且能排除无声段的噪声干扰,提高语音识别的正确率。由于语音信号中不仅包含所需要的有用的语音端,同时也包含了无用的背景噪声段,语音端点检测可以从一段给定的语音信号中检测到语音的起始点和结束点,将语音信号分为语音端和无声段(背景噪声段)两类。现有技术中,通常使用语音能量的检测器进行语音端点检测,但是这种语音段在检测方法在嘈杂的环境下经常失效,从而造成干扰语音也作为目标语音送往语音识别引擎,造成语音识别系统抗干扰能力差,影响语音识别效果,最终影响客户交互体验。
中国专利cn110875060a公开了一种语音信号处理方法、装置、系统、设备和存储介质。该方法包括:使用图像采集设备获取实时图像,利用所述实时图像进行人脸识别,根据人脸识别结果检测目标人员发出语音的时间段(根据判断人嘴巴的张合来判断说话时机);对麦克风阵列接收的音频信号进行声源定位,确定所述音频信号中声源的方位信息;根据所述实时图像中目标人员发出语音的时间段和所述声源的方位信息,进行语音起止点分析,确定所述音频信号中的语音起止时间点。根据本发明实施例提供的语音信号处理方法,可以在多干扰源的嘈杂环境下对语音信号进行语音端点检测,提高系统的抗干扰能力。
中国专利cn111048066a提出了一种儿童机器人上利用图像辅助的语音端点检测系统,所述语音端点检测系统包括机器人唤醒模块、摄像头取景启动模块、拾音进程中动态检测模块和拾音开启前动态检测模块;其中,所述机器人唤醒模块,用于启动机器人准备进入拾音状态;所述摄像头取景启动模块,用于启动机器的摄像头针对用户头像进行取景拍摄;所述拾音进程中动态检测模块,用于检测用户在拾音进程中的实时的头部动态情况;所述拾音开启前动态检测模块,用于检测用户在拾音开启前的实时的头部动态情况。
上述专利均存在以下缺点:
1、因为摄像头是有一定获取图像的角度,而面对不同身高(例如:小孩和成年人,男人或女人)的客户,该方案里的图像采集设备将会无法获取高质量的人脸图像,即可能摄像头采集不到或者不全的人脸图像,所以就无法实施检测目标人员发出语音的时间段的目的。
2、一般普通摄像头(非广角)所采集区域也可能存在多人脸的情况(注:广角摄像头采集区域会更广),将会导致,无法判断目标客户(正在人机交互的客户)是谁,就更无法获取目标客户的有效辅助信息(例如:客户是否说话,客户是否盯着屏幕看等信息)或存在误导。
3、仅仅通过摄像头来判断是否客户到达,可能存在误判或失效情况。例如:客户站立的交互位置不佳或身高过高或过低,导致的不在摄像头采集范围等情况。
技术实现要素:
针对上述技术问题,本发明公开一种辅助语音识别控制方法和装置,提升语音识别系统抗干扰能力,增强语音识别效果。
为达到上述目的,本发明采用的技术方案如下。
本发明公开了一种辅助语音识别控制方法,主要流程如下:
当客户与设备进行人机交互活动时,红外传感器检测到信号,红外数据采集模块将红外触发数据传递给上位机辅助控制系统,判断客户到达动作。
当上位机辅助控制系统检测到红外传感器被触发后,启动人脸检测模块,并开启vad端点检测模块和语音识别开关。此时打开,能够防止客户不在人脸检测范围时,造成的交互体验差,若后续检测没人会再关闭。
当限定图像交互热区的人脸检测未检测到人脸,便启动摄像头微动方案,增加摄像头获取图像角度。
当摄像头通过微动方案调整后,仍未检测到人脸,则关闭语音识别开关和vad端点检测模块,防止噪音输入。
当摄像头检测到人脸,此时启动客户说话检测模块,判断客户是否说话,若客户未张嘴说话,则关闭语音识别开关和vad端点检测模块。若判断客户正在说话,vad端点检测模块控制语音音频拾音,将采集到的人声送到语音识别模块去识别文字。
进一步的,人脸检测模块中预设一图像交互热区,图像交互热区通过在视频帧里限定热区对角的坐标值来设定,若人脸识别模块识别到的人脸中心位置在交互区域内,则判断为客户在交互区域。优选的,热区的划定,只需要在视频帧里限定x1y1点(热区左下角)和x2y2(热区右上角)的值,然后就可以判断。例如鼻子中心点是x0y0,如果x1<x0<x2,y1<y0<y2即可判断鼻子中心在图像交互热区里。
进一步的,关于交互热区的限定判断,还结合线性阵列麦克风声源定位模块来判断。在人机交互过程中,通过线性阵列麦克风声源定位模块实时输出声源的立体方位,限定立体方位中的角度阈值为声源热区;当图像交互热区和声源热区同时满足时,才判定交互者处于可交互状态。
作为优选的,立体方位包括以下6个方位角度,第一角度(0,30),第二角度(30,60),第三角度(60,90),第四角度(90,120),第五角度(120,150),第六角度(150,180)。声源方向第三和第四角度设定为可交互的声源热区。上述判断,可防止声源非中心交互区域的误收音,例如客户在图像交互热区内且判定为说话状态,可能是说话状态模块的误判或者说话着声音小无法进行有效拾音,且其他方向有人在说话,即此时声源方向判定为非声源交互区域,则关闭拾音模块和vad端点检测模块。
进一步的,人脸检测模块1秒钟获取8-16帧图片,客户说话检测模块根据人脸检测模块产生的人脸特征位置,取上嘴唇和下嘴唇对应的特征点的张合距离,判断客户是否说话;若每秒钟超过4-8帧的嘴巴为张开状态,则判断此时客户为说话状态,反之,此时未说话状态。
进一步的,vad端点检测模块使用语音能量检测器进行语音端点检测,从一段给定的语音信号中检测到语音的起始点和结束点,将语音信号分为语音端和无声段两类。
本发明还公开了一种辅助语音识别控制装置,包括:上位机辅助控制系统,上位机辅助控制系统连接红外数据采集模块、vad端点检测模块、人脸检测模块、客户说话检测模块、摄像头角度调整微动模块等;
红外数据采集模块的红外传感器覆盖上位机的交互区域;上位机通过串口连接红外数据采集模块,实时获取红外触发数据。当有人交互时,可以第一时间通知上位机辅助控制系统。
vad端点检测模块:使用语音能量检测器进行语音端点检测,从一段给定的语音信号中检测到语音的起始点和结束点,将语音信号分为语音端和无声段两类。
由于摄像头有一定的广角,所以我们对摄像头范围进行预处理,在人脸检测模块中设定一个图像交互热区,图像交互热区有效减小多人交互时对系统进行的干扰。
客户说话检测模块:根据人脸检测模块产生的人脸特征位置,取上嘴唇和下嘴唇对应的特征点的张合距离,判断客户是否说话。
摄像头角度调整微动模块:上位机辅助控制系统对摄像头角度调整微动模块进行串口通信。
进一步的,图像交互热区的划定方法为:在视频帧里限定热区对角的坐标值。
进一步的,还包括线性阵列麦克风声源定位模块,声源定位模块实时输出声源的立体方位,限定立体方位中的角度阈值为声源热区;当图像交互热区和声源热区同时满足时,才判定交互者处于可交互状态。
作为优选的,立体方位包括以下6个方位角度,第一角度(0,30),第二角度(30,60),第三角度(60,90),第四角度(90,120),第五角度(120,150),第六角度(150,180);声源方向第三和第四角度设定为可交互的声源热区。
进一步的,上位机辅助控制系统通过串口通信,控制摄像头角度调整微动模块的微动结构件来调整摄像头上下仰角。
本发明具有以下有益效果:复杂环境下,多干扰源的嘈杂环境下对语音信号进行语音端点检测时,能够提高系统的抗干扰能力,辅助系统锁定人机交互中目标客户,提高系统的语音识别效果。
摄像头角度微动方案,是一种可调整摄像头传感器的上下仰角,增加摄像头广角范围,可满足于个子高或个子矮的人的场景,能够在面对不同身高的客户时,解决因图像采集设备将会无法获取高质量的人脸图像,即解决可能摄像头采集不到或采集不全人脸图像的问题。
通过对人脸检测原始范围内设置一个小的热区,只在人脸检测热区区域出现人脸才判断为有人交互,当所采集区域存在多人脸的情况下,也只判断热区内的交互者信息。
目标客户判断准确。
仅仅通过摄像头来判断客户是否到达方案下出现的特殊情况的问题。本发明的技术方案加入了红外数据采集模块,可以弥补这种误差,通过双重认证来增加交互准确率,增加交互体验效果。
附图说明
图1为本发明实施例的辅助语音识别控制装置示意图。
图2为本发明实施例的辅助语音识别控制方法流程图。
图3为本发明实施例的辅助语音识别控制方法交互热区示意图。
具体实施方式
为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明。
如图1所示,本实施例的辅助语音识别控制装置,包括:上位机辅助控制系统,上位机辅助控制系统连接红外数据采集模块、vad端点检测模块、人脸检测模块、客户说话检测模块、摄像头角度调整微动模块等。
红外数据采集模块:上位机通过串口连接红外传感器,实时获取红外触发数据。红外传感器需要覆盖整个交互区域。当有人交互时,可以第一时间通知上位机辅助控制系统。
vad端点检测模块:使用语音能量的检测器进行语音端点检测,语音端点检测模块,可以从一段给定的语音信号中检测到语音的起始点和结束点,将语音信号分为语音端和无声段(背景噪声段)两类。
人脸检测模块:由于摄像头有一定的广角,所以我们对摄像头范围进行预处理,画了一定图像交互热区,如图3所示,该热区可以有效减小多人交互时对系统进行的干扰。如下图所示,外框为摄像头采集区域,内色为我们画出的客户图像交互热区。若人脸的中心位置在图像交互热区的区域内,则判断为客户在交互区域。
客户说话检测模块:人脸检测之后会在人脸图像上产生68个特征位置。我们取点63上嘴唇和点67下嘴唇的张合距离来判断客户是否说话。我们人脸检测模块1秒钟获取10帧图片,若每秒钟超过4帧的嘴巴为张开状态,我们则判断此时客户为说话状态,反之,此时未说话状态(经过测试算法在人移动时会出现不稳定状态)。
摄像头角度调整微动模块:上位机辅助控制系统对摄像头角度调整微动模块进行串口通信。
关于交互热区的限定判断,不仅视频图像上的判断,还结合线性6麦或8麦阵列的声源定位方向来判断。线性麦克风阵列进行声源定位的方法主要有以下三种,基于最大输出功率的可控波束形成技术、基于高分辨率谱图估计技术和基于声音时间差的声源定位技术,我们通过实验选择最优的解决方案进行声源定位,并且可在人机交互过程中,通过线性阵列麦克风声源定位模块实时输出人的立体(0°~180°)方位,包含以下6个方位角度,第一角度(0,30),第二角度(30,60),第三角度(60,90),第四角度(90,120),第五角度(120,150),第六角度(150,180)。我们通过声源方向第三和第四角度设定为可交互的声源热区,结合上述图像热区的联合判断,故当图像中心热区和声源中心方向热区同时满足时,才判定交互者处于可交互状态。上述判断,可防止声源非中心交互区域的误收音,例如客户在视频热区内且判定为说话状态,可能是说话状态模块的误判或者说话着声音小无法进行有效拾音,且其他方向有人在说话,即此时声源方向判定为非声源交互区域,则关闭拾音模块和vad端点检测模块。
如图2,本实施例的辅助语音识别控制方法主要流程如下:
步骤一:当客户与设备进行人机交互活动时,红外传感器模块判断客户到达动作。
步骤二:当红外传感器检测到被触发后,启动人脸检测(限定热区)模块,热区的划定,只需要在视频帧里限定x1y1点(热区左下角)和x2y2(热区右上角)的值,然后就可以判断。例如鼻子中心点是x0y0,如果x1<x0<x2,y1<y0<y2即可判断鼻子中心在热区里。并开启vad端点检测模块和语音识别开关(此时打开,防止客户不在人脸检测范围时,造成的交互体验差,若后续检测没人会再关闭)。vad端点检测模块和语音识别开关是串行关系,vad端点检测模块是控制语音音频拾音的,即是检测人声的,如果有人声就送到语音识别模块去识别文字。
步骤三:当限定交互区域热区的人脸检测未检测到人脸,便启动摄像头微动方案,增加摄像头获取图像角度。上位机辅助控制系统通过串口通信,控制摄像头角度调整微动模块的微动结构件来调整摄像头上下仰角。
步骤四:当摄像头通过微动方案调整后,仍未检测到人脸,则关闭语音识别开关和vad端点检测模块,防止噪音输入。
步骤五:当摄像头检测到人脸,此时启动客户说话检测模块,判断客户是否说话,若客户未张嘴说话,则关闭语音识别开关和vad端点检测模块。若判断客户正在说话,则vad端点检测模块控制语音音频拾音,将采集到的人声送到语音识别模块去识别文字。
以上的实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



