
 商标分类
商标分类  商标转让
商标转让 
一种批量定位语音内容的方法及装置与流程
 2021-01-28 15:01:30|
2021-01-28 15:01:30| 259|
259| 起点商标网
起点商标网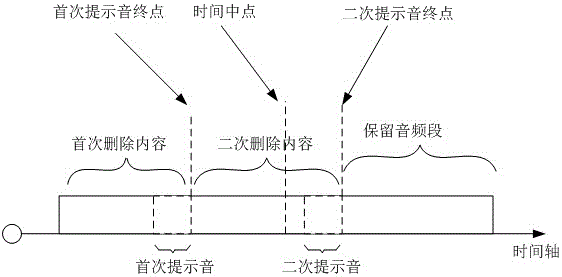
本发明属于语音智能识别技术领域,涉及语料识别技术,具体涉及一种批量定位语音内容的方法及装置。
背景技术:
在现有的人工智能领域中,语音识别日渐成熟,绝大部分的人工智能开发都是基于语音识别及处理之上。但由于对语音识别的研究和开发,需要建立在大量的语料基础之上,然而在正常的录音过程并不是全程都是有效内容,存在着大量的冗余信息。语料量大,冗余信息繁杂成为了语音识别研究和开发上的挡路石。
目前现有技术对语料冗余处理的方法存在以下缺点:
1、不同频率、不同声道的语料需要分开处理;
2、语料处理需要配置成相同的路径模板,对于目录下存储格式不同的音频无法处理;
3、音频处理速度慢;
4、音频定位容易受底噪影响,导致定位不准确;
5、缺少重复性检测。
技术实现要素:
为克服现有语料处理技术存在的缺陷,本发明公开了一种批量定位语音内容的方法及装置。
本发明所述批量定位语音内容的方法,包括如下步骤:
s1.录音开始之前进行提示音播放,提示音播放完成后再开始录制音频,录制并保存包括提示音的音频文件之后,将保存的音频文件的路径记录到路径记录文件中;
s2.对路径记录文件内纪录的全部路径进行遍历读取;对实际不存在的路径或该路径下找不到音频文件时则报错并记录在生成的错误日志中;
当遍历读取过程中,发现语料音频文件之后,对语料音频文件的特征进行读取处理为单声道音频文件;
s3.对音频文件前部分时间的内容进行提示音检测定位,所述前部分至少包括音频文件的前半部分,检测出提示音的文件,删除最后一个提示音之前的音频段;
若在音频文件的前部分内都没有检测到提示音,则认为该音频文件错误,将错误路径记录写入错误日志;
s4.再次筛选检测,具体包括:
s41.对已经检测出提示音并删除部分音频段的音频文件重新进行提示音检测,如果没有再次检测到提示音的音频文件,则对该文件保存;
s42.对检测到新的提示音的音频文件,进行重新定位并删除新提示音之前的音频段;
重复进行s41-s42,直至检测不出新的提示音;
s5.重复步骤s3-s4,处理完所有检测出的音频文件后结束。
优选的,所述提示音为周期性重复的音频信号。
优选的,对提示音的检测方式为:检测音频文件,发现与提示音音频幅值特征匹配的音频段时,记录该音频段起点;继续判断后续是否周期出现与提示音音频周期特征匹配的音频,周期次数相同则标记为提示音。
优选的,所述步骤s1-s5中的数据处理过程基于python算法编程实现。
优选的,所述步骤s2中处理为单声道音频文件的具体过程为:调用python库函数自动读取音频文件,获得当前音频文件的采样点数、采样频率、声道数;通过判断声道数为1还是2来确定当前音频是单声道音频还是双声道音频,对于双声道音频文件,分离其中一个声道的音频处理为单声道音频文件。
本发明还公开了一种批量定位语音内容的装置,包括依序连接的提示音播报模块、音频录制模块、路径记录模块、路径读取模块、音频文件遍历寻找模块和音频处理模块;所述音频处理模块包括依序连接的音频文件特征提取模块、单声道处理模块、提示音检测模块和音频段删除模块;所述音频文件特征提取模块与所述音频文件遍历寻找模块连接;
所述装置还包括与路径读取模块、音频文件遍历寻找模块和提示音检测模块连接的错误日志生成模块。
优选的,还包括与所述路径读取模块连接的窗口生成模块。
采用本发明所述批量定位语音内容的方法,与现有技术相比,具备如下优越性:
1.实现对不同格式下的音频做统一处理。系统可以自动识别当前wav音频的特征以及格式,对单双声道以及幅值大小做归一化处理,提高了适用性;
2.实现对不同文件目录下的音频处理。系统可以自己对给定的主目录进行遍历,对当前主目录的每一个角落进行wav文件的查找,当遍历到wav文件之后则送入处理模块,没有遍历到则自动跳过,解决了需要将目录进行统一的格式化处理的繁琐问题,提高了便利性;
3.对批量音频的处理相对缩短一半左右,系统可以对当前需要进行对齐处理的音频进行截选处理,仅对矩阵的前半部分进行判断,大幅度提高了运算速度;
本发明在底噪不大的情况下,提示音可以被精确定位,误差不超过0.05s;在提示音重复出现时,可以定位到最后出现的提示音的位置即语音开始正确录制的位置。
附图说明
图1为本发明对音频文件进行处理的一种具体实施方式示意图;
图2为本发明所述批量定位语音内容装置的一种具体实施方式示意图。
具体实施方式
下面对本发明的具体实施方式作进一步的详细说明。
本发明所述批量定位语音内容的方法,包括如下步骤:
s1.录音开始之前进行提示音播放,提示音播放完成后再开始录制音频,录制并保存包括提示音的音频文件之后,将保存的音频文件的路径记录到路径记录文件中;
s2.对路径记录文件内纪录的全部路径进行遍历读取;对实际不存在的路径或该路径下找不到音频文件时则报错并记录在生成的错误日志中;
当遍历读取过程中,发现语料音频文件之后,对语料音频文件的特征进行读取处理为单声道音频文件;
s3.对音频文件前部分时间的内容进行提示音检测定位,所述前部分至少包括音频文件的前半部分,检测出提示音的文件,删除最后一个提示音之前的音频段;
若在音频文件的前部分内都没有检测到提示音,则认为该音频文件错误,将错误路径记录写入错误日志;
s4.再次筛选检测,具体包括:
s41.对已经检测出提示音并删除部分音频段的音频文件重新进行提示音检测,如果没有再次检测到提示音的音频文件,则对该文件保存;
s42.对检测到新的提示音的音频文件,进行重新定位并删除新提示音之前的音频段;
重复进行s41-s42,直至检测不出新的提示音;
s5.重复步骤s3-s4,处理完所有检测出的音频文件后结束。
录音开始之前进行提示音播放,提示音播放完成后再开始录制音频,录音得到的语料音频文件保存之后,将保存的音频文件夹的路径记录到路径记录文件中,语料音频文件通常为扩展名为wav的文件,通常是将路径记录文件自身的路径复制到程序生成的窗口内以便读取该文件,从而读取音频文件,可以通过窗口生成模块实现复制路径功能。
程序开始对路径记录文件内的路径进行遍历读取,当某一路径不存在或该路径下找不到音频文件时则报错并记录在生成的错误日志中;
程序在读取到路径记录文件内的路径之后,会基于该路径对路径下的所有文件及文件夹进行遍历即寻找音频文件,通常是扩展名为wav的文件;当某一个路径不存在或者在某路径下找不到音频文件时会记录并生成一个日志文件,一般以log为后缀。
在遍历路径记录文件内所包含的全部路径时,系统自动区分每一路径下的文件和文件夹,对于文件夹,继续进入文件夹内寻找音频文件,路径下全部文件夹内均未发现音频文件则报错并生成错误日志记录该路径;
当遍历到发现扩展名为wav的语料音频文件之后,程序会自动对wav文件的特征进行读取,对单双声道的音频文件分别处理;
python的库函数中有自动读取音频功能的函数,可以直接获得当前音频的采样点数、采样频率、声道数等特征值,通过判断声道数为1还是2来确定当前音频是单声道音频还是双声道音频,并分别做不同的处理流程。双声道音频只用分离其中一个声道的音频做处理即可。
处理成单声道文件后,对音频文件前半部分时间的内容进行提示音检测定位,具体检测手段为:其根据是检测是否符合提示音的特征,例如发现某段音频信号幅值以及其周期均与提示音设置一致,对检测到的该段音频信号的时间起点记录位置,并通过判定提示音对应的幅值周期性出现的次数来确定是提示音还是其他声音。
若判定为提示音则返回时间起点的位置给主程序,然后加上提示音所固有的长度,获得新的点,对该新的点之前的所有内容进行删除。并对没有检测到提示音的音频文件进行记录报错;
提示音的波形是周期且规律的,且是特有的周期性,例如某一个音重复很多次,或者某一个音的波形幅值连续达到某一个值,因此选择该特性作为检测标志;音频在用程序读取之后是以点值的形式存在于内存当中,当检测到某一段音频符合提示音的特性之后,需要将该音频出现的第一个点记录下来;由于检测到的音频都是以幅值的形式存在,有可能出现幅值与提示音相同的点,但是提示音具有周期性的特点,可以通过判断幅值点周期性出现的次数是否与提示音本身的次数相同,如果相同则认为是提示音,如果不同则认为不是提示音。
若在音频的前半部分内都没有检测到提示音,则认为整条音频错误,将错误路径记录写入错误日志中。
随后对通过提示音检测的音频重新进行提示音检测,由于一开始就没有检测到提示音的音频已经被认为报错,所以该步骤内仅针对的是已经经过提示音处理的音频,
对提示音之前的音频段继续检测,如果没有再次检测到提示音的音频文件,则对该文件保存。对检测到新的提示音的音频进行重新定位,所谓定位,即步骤3所述,返回提示音时间起点的位置给主程序,然后加上提示音所固有的长度向后延伸,获得提示音终点,对该点之前的所有内容进行删除,以此流程处理完所有的wav音频后结束。
对检测到多次提示音的音频文件,通常是证明录音过程中出现了录制出错,或者中断,录音人重新开始了录音,由于录音时录音机是在每一个录音人录音过程中全程开启,所以会出现多次提示音的情况,则此时应该以最后一次提示音出现的位置为准,取最后一次提示音后的音频信息。
如图1所示,可以对音频文件的时间中点之前的音频段进行第一次提示音检测,检测出提示音后,将包括提示音在内的在前音频段删除;删除后的音频段继续进行第二次提示音检测,如果再检出提示音,则再次删除新的提示音之前的音频段,直至检测不出新的提示音,保存剩余的音频段。
本发明所述批量定位语音内容的方法可以基于这样一种批量定位语音内容的装置实现,基于python软件编程实现。如图2所示,包括依序连接的提示音播报模块、音频录制模块、路径读取模块、音频文件遍历寻找模块和音频处理模块;所述音频处理模块包括依序连接的音频文件特征提取模块、单声道处理模块、提示音检测模块和音频段删除模块;所述音频文件特征提取模块与所述音频文件遍历寻找模块连接;
所述装置还包括与路径读取模块、音频文件遍历寻找模块和提示音检测模块连接的错误日志生成模块。
通过错误日志生成模块生成的错误日志,用户可以方便的查找无效路径和无效音频文件,对录制过程进行及时纠错。
采用本发明所述批量定位语音内容的方法,与现有技术相比,具备如下优越性:
1.实现对不同格式下的音频做统一处理。系统可以自动识别当前wav音频的特征以及格式,对单双声道以及幅值大小做归一化处理,提高了适用性;
2.实现对不同文件目录下的音频处理。系统可以自己对给定的主目录进行遍历,对当前主目录的每一个角落进行wav文件的查找,当遍历到wav文件之后则送入处理模块,没有遍历到则自动跳过,解决了需要将目录进行统一的格式化处理的繁琐问题,提高了便利性;
3.对批量音频的处理相对缩短一半左右,系统可以对当前需要进行对齐处理的音频进行截选处理,仅对矩阵的前半部分进行判断,大幅度提高了运算速度;
本发明在底噪不大的情况下,提示音可以被精确定位,误差不超过0.05s;在提示音重复出现时,可以定位到最后出现的提示音的位置即语音开始正确录制的位置。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



