
 商标分类
商标分类  商标转让
商标转让 
一种车内声品质优化系统及优化方法与流程
 2021-01-28 14:01:19|
2021-01-28 14:01:19| 254|
254| 起点商标网
起点商标网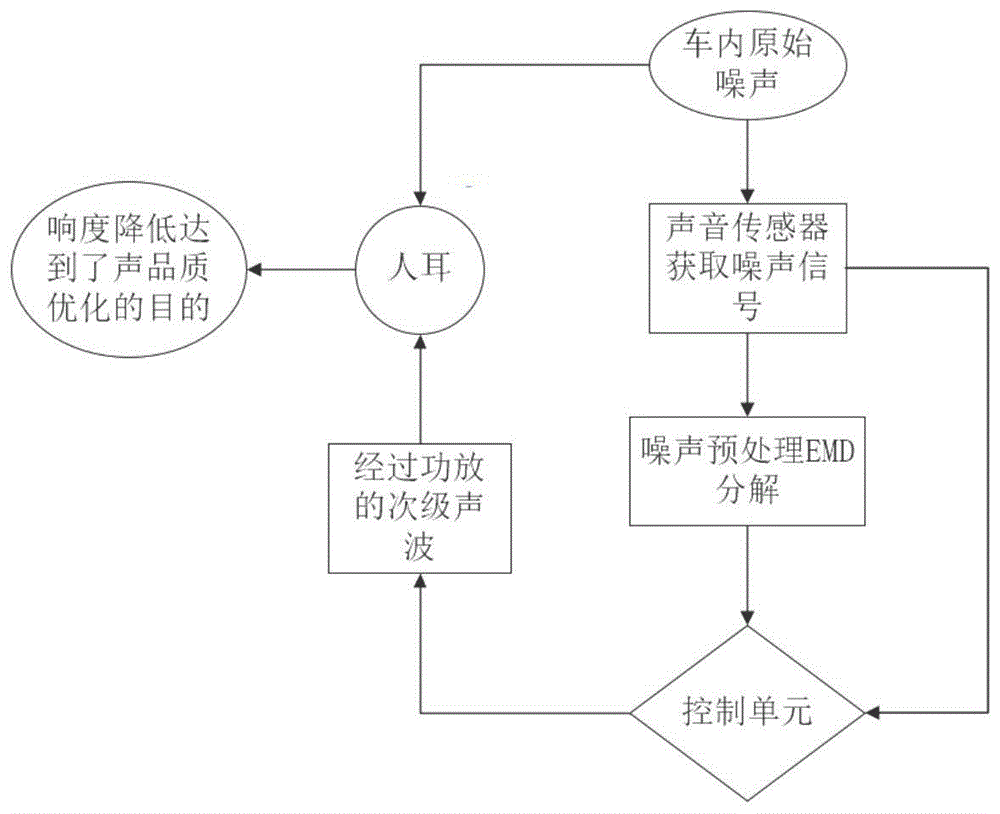
本发明涉及汽车振动与噪声领域,涉及一种利用主动降噪原理优化车内声品质的系统及方法。
背景技术:
研究表明:声压级(a、b、c计权)作为评价噪声的主要客观参数并不能准确反映人对噪声的主观感受,因此考虑人耳的听觉特性,结合人类心理学,研究人员提出了声品质的概念。
声品质是对声音性质的描述,反映的是人们对声音事件的主观感受:指人耳的听觉感知过程,然后人再根据自己的感知做出主观判断。该领域的科研人员也相继提出了影响声品质的客观参量,比如:响度、尖锐度、粗糙度、抖动度、音调度等。
主动噪声控制(anc),是在指定区域内人为地、有目的地产生一个次级声信号去控制初级声信号的方法,故次级信号的好坏影响了噪声控制效果的好坏,次级信号由自适应滤波器产生,而基于felms算法的控制单元中自适应滤波器的长度l及收敛因子μ是噪声主动控制系统重要参数,滤波器长度l影响滤波效果,收敛因子μ影响算法的收敛速度以及稳定性。理论上l越大控制效果越好,但是根据本段最后的公式可知,收敛因子μ可取范围受输入信号的均方和e[x2(k)]及滤波器长度l影响,在输入信号的均方和e[x2(k)]一定的情况下,滤波器长度l决定着收敛因子μ的最大值,μ越小稳定性越高,但收敛速度越慢。反之,μ越大稳定性就越差,但收敛速度快,当μ超过最大值时,算法就容易发散,出现不收敛的情况。用一个次级声信号去控制初级声信号的方法是根据两个声波相消干涉条件,如果利用人为附加的次级声源产生与初级声源声波幅值相等、相位相反的声波则两声波将在空间发生相干性叠加形成消声“静区”,从而达到降噪的目的。主动降噪方法使噪声控制更有针对性。本段最后的公式如下:
技术实现要素:
针对现有技术中存在不足,针对以上问题,利用已建立的基于felms算法的控制单元噪声主动控制系统simulink模型进行仿真,对比不同的l的仿真结果,得到最优的自适应滤波器的长度l;在已知的最优滤波器长度l情况下,分别取不同的收敛因子μ,利用已建立的噪声主动控制系统simulink模型进行仿真,对比不同的收敛因子μ的仿真结果,得到最优收敛因子μ,从而达到最好的滤波效果和算法收敛速度以及稳定性,得到最优的响度和粗糙度,从而得到一个更好的次级信号,从而达到声品质优化的目的。
本发明是通过以下技术手段实现上述技术目的的。
一种车内声品质优化系统,包括信号获取装置、信号处理装置和声音播放装置;所述信号获取装置用来车内信号进行采集,信号处理装置对采集到的信号进行处理,声音播放装置将信号处理装置处理后的数字信号转化为声信号;
所述信号获取装置包括声音采集装置,所述声音采集装置设置在车内用来采集需要声品质优化区域的原噪声信号x(k)和实现优化区域的误差信号e(k);
所述信号处理装置包括去噪单元、存储单元和基于felms算法的控制单元;
所述去噪单元将原信号x(k)进行处理,去除干扰成分,使去噪之后的噪声信号x′(k)符合稳态信号的特征;
所述存储单元将噪声信号x′(k)存储;
所述预处理单元将信号x′(k)分解为imf1、imf2、、……、imfn,n个分量信号,计算每个分量的声品质参数响度、粗糙度;
所述基于felms算法的控制单元利用felms自适应滤波器将存储单元里的x′(k)生成次级噪声信号s(k);
所述声音播放装置包括车载扬声器,
所述车载扬声器是将信号处理装置中生成单元的数字信号转化为声信号,在车厢内播放次级噪声信号,以抵消驾驶员人耳处噪声。
进一步的,所述声音采集装置分别和去噪单元、基于felms算法的控制单元相连接;所述去噪单元和存储单元相连接;所述存储单元分别和预处理单元、基于felms算法的控制单元相连接;所述基于felms算法的控制单元和车载扬声器相连接。
进一步的,所述声音采集装置为声音传感器。
基于车内声品质优化系统的优化方法,包括以下步骤:
s1:声音传感器获取车内原始噪声信号x(k)和误差信号e(k);
s2:对信号x(k)进行分解和重构,提取有效信号x′(k);
s3:信号x′(k)存储在储存单元中,作为预处理单元和基于felms算法的控制单元的输入;
s4:在预处理单元中,利用emd分解对x′(k)进行分解,分解为imf1、imf2、、……、imfn等n个分量信号;预处理单元再对imf分量进行fft分析,确定整个噪声信号需要选择性控制的频带,进一步确定felms算法中误差滤波器的截止频率,以及增益幅值;
s5:基于felms算法的控制单元运行控制算法,根据输入的信号x′(k)从而生成次级声波信号s(k),并根据误差信号e(k)实时调节felms算法中横向滤波器的权值,从而确保误差信号的均方根值最小。
进一步的,分为两个阶段进行:
第一阶段:声音传感器、去噪单元、储存单元和预处理单元工作,此阶段声音传感器采集信号x(k),信号长度5s,完成步骤s1,声音传感器停止工作,完成步骤s2至s4;
第二阶段:声音传感器、储存单元、基于felms算法的控制单元和车载扬声器工作,此阶段声音传感器持续采集误差信号e(k),完成步骤s5。
进一步的,在匀速下,车内噪声为稳态信号,将该稳态信号经过声音传感器拾取进行emd去噪得到x′(k)并储存,再将x′(k)循环输入至基于felms算法的控制单元中,代替传统主动降噪中的参考信号。
进一步的,步骤s4中,信号x′(k)分解为n个分量,每个分量对应的频带的带宽(fmax-fmin)相等。
进一步的,在匀速工况下,自适应滤波器长度取l=128,收敛因子为μ=0.03。
综合考虑收敛性、稳定性以及声品质控制效果,确定自适应滤波器长度l=128、收敛因子μ=0.03
本发明的有益效果:
(1)本发明在达到优化声品质的前提下,减小了控制系统的运算量;
(2)本发明对自适应滤波器的长度l(即滤波器的阶数)及收敛因子μ等影响声品质参数响度、粗糙的噪声主动控制系统重要参数进行研究,得到合适的l、μ取值,提高了控制系统的收敛性和稳定,并得到较好的声品质控制效果。
(3)本发明基于匀速巡航工况,具有实用性,并根据该工况下的稳态型号的特征,选择了更加接近车内噪声信号的参考信号,不仅避免了声反馈现象,同时也使响度和粗糙度的控制效果更好。
附图说明
图1为本发明实施例涉及到的声品质优化的原理图;
图2为本发明实施例涉及到的声品质优化装置的工作流程图;
图3为本发明实施例涉及到的emd-felms算法框架图。
图4为l=64时控制前后仿真结果时域图和频域图;
图5为l=128时控制前后仿真结果时域图和频域图;
图6为l=256时控制前后仿真结果时域图和频域图;
其中,颜色较深的中间部分为控制后时域图,颜色较浅的部分为控制前时域图;控制前后的频域图各个图所示,频域变化较大的为控制前,频域变化较小的为控制后。
图7为滤波器长度l=128时,μ=0.001时,控制前和控制后系统的收敛速度图;
图8为滤波器长度l=128时,μ=0.01时,控制前和控制后系统的收敛速度图;
图9为滤波器长度l=128时,μ=0.03时,控制前和控制后系统的收敛速度图;
图10为滤波器长度l=128时,μ=0.07时,控制前和控制后系统的收敛速度图。
其中,颜色较深的中间部分为控制后收敛速度图,颜色较浅的部分为控制前收敛速度图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
一种匀速下的车内声品质优化系统,包括信号获取单元、信号处理装置和声音播放装置;
所述信号获取单元包括声音采集装置,
声音采集装置设置在驾驶员座椅人耳处以采集需要声品质优化区域的原噪声信号x(k)和实现优化区域的误差信号e(k);
所述信号处理装置包括去噪单元、存储单元和基于felms算法的控制单元;
所述去噪单元将原信号x(k)进行处理,去除干扰成分,使去噪之后的噪声信号x′(k)符合稳态信号的特征;
所述存储单元将噪声信号x′(k)存储;
所述预处理单元将信号x′(k)分解为imf1、imf2、、……、imfn,n个分量信号,计算每个分量的声品质参数响度、粗糙度;
所述基于felms算法的控制单元利用felms自适应滤波器将存储单元里的x′(k)生成次级噪声信号s(k),以抵消驾驶员人耳处噪声;
所述声音播放装置包括车载扬声器,
所述车载扬声器是将信号处理装置中生成单元的数字信号转化为声信号,在车厢内播放次级噪声信号,以抵消驾驶员人耳处噪声;
所述声音采集装置分别和去噪单元、基于felms算法的控制单元相连接;所述去噪单元和存储单元相连接;所述存储单元分别和预处理单元、基于felms算法的控制单元相连接;所述基于felms算法的控制单元和车载扬声器相连接。
一种定速巡航工况下的车内声品质优化方法,包括以下步骤:
s1:声音传感器获取驾驶员人耳处原始噪声信号x(k);
s2:对信号x(k)进行分解和重构,提取有效信号x′(k);
s3:信号x′(k)存储在储存单元中,作为预处理单元和基于felms算法的控制单元的输入;
s4:在预处理单元中,利用emd分解对x′(k)进行分解,分解为imf1、imf2、、……、imfn等n个分量信号;
s5:对imf分量进行fft分析,确定整个噪声信号需要选择性控制的频带,进一步确定felms算法中误差滤波器的截止频率,以及增益幅值;
s6:根据步骤s1中的噪声信号,利用felms自适应滤波器得到次级噪声信号,并对自适应滤波器的长度l(即滤波器的阶数)及收敛因子μ等影响噪声控制系统稳定性、收敛性及声品质,得到合适的l、μ取值;felms算法的控制单元生产的次级声源信号经车载扬声器播放抵达降噪区域,实现选择性消声,同时声音传感器获取误差信号e(k)反馈至控制器中,自适应调整滤波器的权值,保证降噪区域误差信号均方根值最小。
下面首先结合附图具体描述根据本发明实施例的结合附图1本发明实施例涉及到的声品质优化的原理图。
首先,车内原始噪声被声音传感器获取,同时车内原始噪声传递到人耳;
其次,将车内信号进行去噪处理,去除干扰成分,使去噪之后的噪声信号符合稳态信号的特征;
然后,噪声预处理emd分解:将去噪处理后符合稳态信号特征的信号通过emd分解,分解为imf1、imf2、、……、imfn等n个分量信号,计算每个分量的声品质参数响度、粗糙度,允许对应的频段通过情况,进一步确定误差滤波器的参数,保证误差信号的均方根值最小;
再次,将经预处理emd分解噪声信号输入控制单元中,通过算法的自适应滤波器得到次级噪声信号;
最后,次级噪声信号经过功率放大器传递至车载扬声器,车载扬声器作为次级声源发射次级声波传播至降噪区域对原有噪声信号x(k)进行选择性抵消,以达到优化声品质的目的。
结合附图2,一种定速巡航工况下的车内声品质优化方法,包括两个阶段的工作。
第一阶段:声音传感器、去噪单元、储存单元、预处理单元依次顺序工作,其余单元不工作;
信号获取装置中的声音传感器获取车内噪声信号x(k),为保证噪声数据的真实性准确性,采样频率设置大于8192hz,要求汽车环境窗户关闭,空调关闭,采集时间5s,其中,s指秒,然后声音传感器关闭;
信号处理装置中的去噪单元对采集的信号x(k)进行去噪处理,处理方法为emd分解阈值法,得到去噪后的信号x′(k);
信号处理装置中的储存单元将去噪后的信号xn′(k)进行存储,作为预处理单元的一次输入和基于felms算法的控制单元的循环输入;
预处理单元将信号x′(k)分解为imf1、imf2、、……、imfn等n个分量信号,计算每个分量的声品质参数响度和粗糙度;
第一阶段结束。
第二阶段:声音传感器、储存单元、基于felms算法的控制单元、车载扬声器同时工作,其余单元不工作;
信号获取装置中的声音传感器持续采集降噪区域(人耳处)的误差信号e(k),并反馈至基于felms算法的控制单元中;
信号处理装置中的储存单元将所存储的去噪信号x′(k)循环输入到基于felms算法的控制单元中;
信号处理装置中的基于felms算法的控制单元运行控制算法,根据输入的信号x′(k)生成次级声波信号s(k),并根据误差信号e(k)实时调节felms算法中横向滤波器的权值,保证误差信号的均方根值最小;
声音播放装置中的扬声器根据控制单元发出的控制信号经过相移器、功率放大器传递至车载扬声器,车载扬声器作为次级声源发射次级声波传播至降噪区域对原有噪声信号x(k)进行选择性抵消,以达到优化声品质的目的。
结合附图3,进一步说明本发明方案,步骤如下:
①x(k)为车内驾驶员人耳处原噪声信号,通过声音传感器拾取;
②p(z)为felms算法的初级通道,在本方案中为1;
③原信号x(k)经过去噪处理得到信号x′(k);
④x′(k)经过emd分解处理确定误差滤波器h(z)的截止频率和增益幅值,该滤波器基于fir函数设计,可设计出任意响应曲线;
⑤x′(k)经过次级通道估计函数c′(z)后到达误差滤波器h(z),c′(z)是对c(z)的近似估计,目的是解决时延问题;
⑥h(z)为误差滤波器,允许最大的频带通过,抑制不是最大的频带通过,实现选择性抵消;
⑦w(z)是横向滤波器,其权值由lms算法进行调整;
⑧c(z)是扬声器到降噪区域即驾驶员人耳处的传递函数,可以由实验测得;
⑨原噪声信号x(k)和次级声源信号s(k)在降噪区域干涉抵消。
以汽车匀速工况下的怠速样本为例,暂取收敛因子μ=0.02,felms算法中的残差滤波器通带暂设置为20hz~15.5khz,覆盖了人耳的24个临界频带,利用上文已建立的噪声主动控制系统simulink模型进行仿真,l=64、128、256的仿真结果结合附图4、图5和图6所示。
对比图4和图5,当滤波器长度l=64时,系统在0.4s左右收敛至稳定状态。当l=128时,系统收敛速度加快,在0.30s左右就达到稳定状态,而且稳定状态下的残余信号也更小。对比图5和图6,当l=256时,滤波器长度对收敛速度影响变小,收敛时间与l=128时基本相同,但稳定状态下的残余信号稍优。为对比不同滤波器长度l对声品质控制效果的影响,计算控制后噪声的响度、粗糙度以及其他心理声学客观参量,利用ga-bp声品质预测模型得到客观烦躁度等级,结果如表1所示。可以看出,当l从64提高到128时,由于控制后的残余信号进一步降低,响度下降了0.67sone,粗糙度下降了0.048asper,噪声的烦躁度下降0.36个等级。当l从128提高到256时,响度、粗糙度以及烦躁度等级虽进一步下降,但下降幅值较小,而且滤波器长度的增加,会降低收敛因子的可取范围。在仿真过程中发现,l取值过大时系统会出现不收敛的情况,此外,在噪声主动控制系统硬件实现中,滤波器长度的增加会加大算法的计算量,从而提高对硬件的要求。所以,综合考虑收敛速度、声品质的控制效果以及硬件实现的难度等因素,选取滤波器长度l=128。
表1不同滤波器长度l噪声主动控制系统的声品质控制效果
同样以怠速工况下的样本为例,在滤波器长度l=128情况下,分别取不同的收敛因子进行仿真,结果如图7、图8、图9和图10所示。可以看出,当μ=0.001时,系统在1s左右才收敛至稳定状态,随着收敛因子μ的增大,系统的收敛速度也随之加快,当μ=0.07时,系统收敛速度最快。
表2显示了不同收敛因子μ下的声品质控制效果。
表2不同收敛因子μ噪声主动控制系统的声品质控制效果
可以看出,当μ=0.001时,响度、粗糙度及烦躁度等级的主动控制效果最好,但因收敛因子过小,算法的计算量较大,导致系统的收敛时间过长,实时性较差。由上文中felms算法的迭代公式可知,收敛因子不仅决定系统的收敛速度,而且还影响自适应滤波器权值的迭代,进而影响滤波效果。所以,随着μ的增加,虽然系统的收敛时间逐渐变小,但声品质的控制效果也逐渐变差。仿真中发现,当μ取值大于0.09时,系统会出现发散不收敛的情况,可以大概判定收敛因子的最大值在0.09左右。综合考虑系统的收敛速度、声品质控制效果以及系统的稳定性,选取收敛因子μ=0.03。
本发明实施例以汽车匀速工况下的怠速样本为例,暂取一个收敛因子μ,felms算法中的残差滤波器通带暂设置为20hz~15.5khz,覆盖了人耳的24个临界频带,利用已建立的基于felms算法的控制单元噪声主动控制系统simulink模型进行仿真,对比不同的l的仿真结果,得到最优的自适应滤波器的长度l;同样以怠速工况下的样本为例,在已知的最优滤波器长度l情况下,分别取不同的收敛因子μ,利用已建立的噪声主动控制系统simulink模型进行仿真,对比不同的收敛因子μ的仿真结果,得到最优收敛因子μ,从而达到最好的滤波效果和算法收敛速度以及稳定性,得到最优的响度和粗糙度,从而得到一个更好的次级信号,从而达到声品质优化的目的。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



