
 商标分类
商标分类  商标转让
商标转让 
一种低资源下利用迁移学习进行情感语音合成的方法与流程
 2021-01-28 14:01:55|
2021-01-28 14:01:55| 324|
324| 起点商标网
起点商标网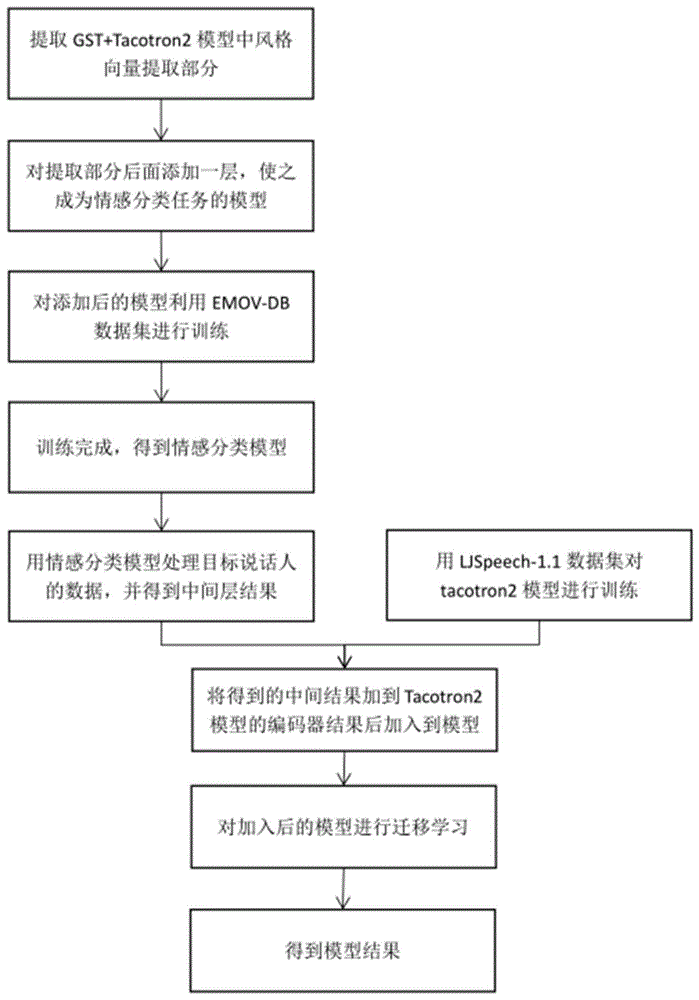
本发明涉及语音合成领域,具体是涉及一种在低资源下,利用现有数据进行迁移学习从而实现情感语音合成的方法。
背景技术:
:近年来,端到端语音合成领域发展迅速,在大数据集进行训练的前提下,语音合成的质量和清晰度有了很大的提升。对于在大数据量进行训练的前提下的情感语音合成目前已经达到了一个可以令人接受的水平,但在一些特殊情况下,可能没有条件获得进行训练的大数据量的数据集,或者获取代价比较高。技术实现要素:本发明的目的是为了克服现有技术中的不足,提供一种低资源下利用迁移学习进行情感语音合成的方法,该方法可以在少量用于训练的数据的前提下进行情感语音合成,采用迁移学习和模型预训练的方法,充分利用了单个说话人少量的含有情感的语音数据,在达到可以识别的情感的语音质量的前提下,利用较少的空间资源,实现情感语音合成的目的。本发明的目的是通过以下技术方案实现的:一种低资源下利用迁移学习进行情感语音合成的方法,包括以下步骤:步骤一,情感向量预训练:利用情感语音合成数据集对于一个语音情感识别模型进行训练获得中间结果,语音情感识别模型是由风格化端到端语音合成的基本方法中基于gst(globalstyletoken)机制通过风格向量提取进一步处理得到的;步骤二,语音合成模型预训练:对于基本的端到端语音合成模型,利用基本的单说话人语料的语音合成数据集进行预训练;具体是对步骤一获取的目标说话人的各种情感语音的中间结果,取出其中中性的结果,随机获取基本的单说话人语料语音合成数据集数据量次;用基本的单说话人语料语音合成数据集对上述的端到端语音合成模型进行基础的训练。步骤三,进行迁移学习训练:对于基本的端到端语音合成模型在编码器的结果中连接上步骤一中得到的中间结果,并进行迁移学习训练;最终生成具有情感的语音文件。进一步的,步骤一中具体如下:基本的端到端语音合成模型结构如下,xencoder=encoder(xtext)xattention=attention(xencoder)xdecoder=decoder(xattention)其中,xtext为文本中提取的特征信息;xencoder、xattention为相应的中间结果;xdecoder为最终的结果信息,为梅尔谱信息或频谱信息;最终的结果信息通过声码器转化为语音信息生成语音文件;在基本的端到端语音合成模型的基础上增加gst(globalstyletoken)结构,具体如下,xencoder=encoder(xtext)xstyle=styletoken(xref)xmiddle=concatenate(xencoder,xstyle)xattention=attention(xmiddle)xdecoder=decoder(xattention)其中,xtext、xencoder、xattention和xdecoder同基本的端到端语音合成模型中相同,xmiddle为最终结合后的输入到解码器的编码器结构的输出,xref为作为风格参考的语音提取的梅尔谱信息,经过gst(globalstyletoken)的结构的处理得到xstyle,xstyle带有风格相关的信息;利用gst(globalstyletoken)结构进行一个情感分类任务,具体如下,xstyle=styletoken(xref)xemotion=dense(xstyle)其中,gst(globalstyletoken)的结构不变,xemotion为相应的情感标签信息;dense为基本的深度学习全连接层,用于将中间结果转化为标签长度的维度的向量;对上述语音情感识别模型,经过情感语音合成数据集的数据进行训练,然后将目标说话人的相关数据在上述语音情感识别模型中进行处理,获取xstyle作为之后步骤的输入信息,xstyle即体现了目标说话人不同情感的信息,又体现了同一情感中不同句子的关于语音的风格上的差别。进一步的,步骤二中具体如下:对基本的端到端语音合成模型进行改造,改造后的结构如下:xencoder=encoder(xtext)xmiddle=concatenate(xencoder,xstyle)xattention=attention(xmiddle)xdecoder=decoder(xattention)其中xtext为文本中提取的特征信息;xencoder、xattention为相应的中间结果;xmiddle为最终结合后的输入到解码器的编码器结构的输出,xdecoder为最终的结果信息,xstyle为步骤一训练中获得的语音情感识别模型的中间结果;取出语音情感识别模型中的xstyle值的中性结果作为基本的端到端语音合成模型中xstyle输入值。进一步的,步骤三中训练完成后,在步骤一语音情感识别模型的中间结果中选取各个情感的xstyle结果作为基本的端到端语音合成模型中生成语音的xstyle值输入,从而生成有情感的语音文件。进一步的,步骤一所需的训练步数为50000步,初始学习率为1e-4,在5000步开始学习率下降,学习率最终下降为1e-6。进一步的,步骤二所需的训练步数为150000步,初始学习率为1e-3,在5000步开始学习率下降,学习率最终下降为1e-5进一步的,步骤三所需的训练步数为40000步,参数设置与步骤二相同。与现有技术相比,本发明的技术方案所带来的有益效果是:1.本发明采用预训练和迁移学习的方法,能够充分利用单个说话人少量的情感数据。通过迁移学习,语音情感识别模型能够生成具有良好聚类结构,并能表征一定语音信息的中间向量,通过这一中间向量,本方法在一个统一的情感语音合成模型的基础上,能合成出质量达到一定水平的、情感倾向明显的合成语音。2.对于之前的情感语音合成方法一般需要上万条数据的数据集进行训练(在单个情感训练过程中一般需要等同于ljspeech-1.1数据集(13000条)的数据量),但利用本方法实际使用的单一情感语音语料数据量只有大约500条,而情感语音数据的收集又是极其困难的。本方法基于迁移学习进行训练,能够在比较小的情感数据量的前提下得到质量和情感强度可以清晰识别的情感语音合成结果。3.对于一般的情感语音合成方法,一般需要对于单个情感训练一个语音合成模型,而一个语音合成模型是会消耗大约600m的存储空间的,而单独一个语音合成模型的训练过程往往需要15w步以上的训练过程,这在一台计算机上往往需要4到5天的时间。本方法最终对于各个情感整体训练了一个语音合成模型,所以在训练时长和存储消耗上会优于以往的方法。4.本发明方法可以更好的利用目标说话人有限的情感语音数据信息,利用一个基本的端到端语音合成模型和一个语音情感识别模型达到合成一定清晰度并具有明显情感倾向的语音信息的目的(具体数据对比可参看后文表2、表3)。附图说明图1是方法实施的整体步骤流程图;图2是利用emov-db(情感语音合成数据集)数据集进行语音情感识别模型图;图3是对于基本的tacotron2模型在编码器的结果上连接步骤一中间结果的端到端语音合成模型图。具体实施方式以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。本实施例提供一种低资源下利用迁移学习进行情感语音合成的方法,在本实施例的实际操作中使用了:emov-db和ljspeech-1.1两个数据集,其中emov-db数据集为低资源的情感语音合成数据集,数据集中文字是基于cmu北极数据库的。数据集包括四个演讲者的录音——两男两女。情绪类型包括中性、困倦、愤怒、厌恶和娱乐。ljspeech-1.1数据集是一个单人的中性情感的语音合成数据集,其包含来自单个演讲者的13,100个简短音频片段,这些片段来自7部非小说类书籍。为每个剪辑提供了转录。剪辑的长度从1到10秒不等,总长度约为24小时。对于emov-db数据集具体得说话人和情感情况如下:-珍妮(女性,英语:中性(417个文件),有趣(222个文件),愤怒(523个文件),困倦(466个文件),厌恶(189个文件)-贝亚(女性,英语:中性(373个文件),娱乐(309个文件),愤怒(317个文件),困倦(520个文件),厌恶(347个文件)-山姆(男性,英语:中性(493个文件),有趣(501个文件),愤怒(468个文件),困倦(495个文件),厌恶(497个文件)-乔希(男,英文:中性(302个文件),有趣(298个文件),困倦(263个文件)对于本实施例可以使用数据量类似的同样语音质量的数据集进行操作,可以达到同本实施例实验相同的效果。本方法主要是基于论文:[styletokens:unsupervisedstylemodeling,controlandtransferinend-to-endspeechsynthesis](https://arxiv.org/abs/1803.09017)进行的相关改进。原始论文主要针对大数据集下的风格迁移的语音合成任务,但对于小数据量的情感语音合成任务并不适用。所以在本方法中通过将论文中提到的方法进行改进(改进主要是对gst-tacotron2模型进行拆分,并引入新的任务目标以方便生成更能指导语音合成过程的中间结果)。通过本方法的改进gst-tacotron2模型能更好的获取参考语音当中的情感信息,从而在小数据量的情况下更好的指导情感语音合成任务。其具体步骤(如图1所示)如下:步骤一,情感向量预训练:如图2所示,主要是利用emov-db数据集(情感语音合成数据集)的全部数据对于一个语音情感识别模型进行训练。在本方法中,主要是利用styletoken的结构进行一个情感分类任务,其结构如下:xstyle=styletoken(xref)xemotion=dense(xstyle)其中,styletoken的结构分为referenceencoder和attention两个部分,其中referenceencoder为6层conv-2d(kernel22,33,outputchannel32,32,64,64,128,128)+1层gru(128),而attention为多头注意力机制,语音情感识别模型中,使用了4头注意力,其具体结构如下:xconv0=conv(xref)xbn0=batch_normalization(xconv0)xconv1=conv(xbn0)xbn1=batch_normalization(xconv1)xconv2=conv(xbn1)xbn2=batch_normalization(xconv2)xconv3=conv(xbn2)xbn3=batch_normalization(xconv3)xconv4=conv(xbn3)xbn4=batch_normalization(xconv4)xconv5=conv(xbn4)xbn5=batch_normalization(xconv5)xgru=gru(xbn5)xstyle=multihead_attention(xgru)对于styletoken结构后面的xemotion为相应的情感标签信息,其维度为512。dense为基本的深度学习全连接层,主要用于将中间结果转化为标签维度的向量。具体而言就是将512维转化为5维,之后进行softmax的处理。使用交叉熵作为损失函数,优化器选取adam优化器。语音情感识别模型中具体结构信息情况如下:表1语音情感识别模型结构信息情况网络层结构size卷积层六层卷积kernel22,33,outputchannel32,32,64,64,128,128gru层双向gru128注意力层4个头多头注意力机制(128,512)密集层全连接网络(512,5)对上述语音情感识别模型,经过emov-db(情感语音合成数据集)的数据进行训练,然后将目标说话人的相关数据在语音情感识别模型中进行处理,获取xstyle作为后面步骤的输入信息,认为这一向量即体现了目标说话人不同情感的信息,又体现了同一情感中不同句子的关于语音的风格上的差别。步骤二,端到端语音合成模型预训练:对于基本的tacotron2模型,利用ljspeech-1.1(基本的单说话人语料语音合成数据集)的数据集进行预训练,具体而言:如图3所示,对于基本的tacotron2模型进行改造,改造后的结构如下:xencoder=encoder(xtext)xmiddle=concatenate(xencoder,xstyle)xattention=attention(xmiddle)xdecoder=decoder(xattention)公式中xstyle为步骤一训练中获得的语音情感识别模型的中间结果。具体而言,就是对步骤一获取的目标说话人的各种情感语音的中间结果,取出其中中性的结果,随机获取ljspeech-1.1(基本的单说话人语料语音合成数据集)数据集数据量次。上述端到端语音合成模型中编码器模块包含一个字符嵌入层(characterembedding),一个3层卷积,一个双向lstm层。输入字符被编码成512维的字符向量;然后穿过一个三层卷积,每层卷积包含512个5x1的卷积核,即每个卷积核横跨5个字符,卷积层会对输入的字符序列进行大跨度上下文建模(类似于n-grams),这里使用卷积层获取上下文主要是由于实践中rnn很难捕获长时依赖;卷积层后接批归一化(batchnormalization),使用relu进行激活;最后一个卷积层的输出被传送到一个双向的lstm层用以生成编码特征,这个lstm包含512个单元(每个方向256个单元)。fe=relu(f3*relu(f2*relu(f1*e(x))))h=encoderrecurrency(fe)其中,f1、f2、f3为3个卷积核,relu为每一个卷积层上的非线性激活,e表示对字符序列x做embedding,encoderrecurrency表示双向lstm。注意力机制使用了基于位置敏感的注意力机制(attention-basedmodelsforspeechrecognition),是对之前注意力机制的扩展(neuralmachinetranslationbyjointlylearningtoalignandtranslate);这样处理可以使用之前解码处理的累积注意力权重作为一个额外的特征,因此使得端到端语音合成模型在沿着输入序列向前移动的时候保持前后一致,减少了解码过程中潜在的子序列重复或遗漏。位置特征用32个长度为31的1维卷积核卷积得出,然后把输入序列和为位置特征投影到128维隐层表征,计算出注意力权重。其中,va、w、v、u和b为待训练参数,si为当前解码器隐状态,hj是当前编码器隐状态,fi,j是之前的注意力权重αi-1经卷积而得的位置特征。解码器是一个自回归循环神经网络,它从编码的输入序列预测输出声谱图,一次预测一帧。上一步预测出的频谱首先被传入一个“pre-net”,每层由256个隐藏relu单元组成的双层全连接层,pre-net作为一个信息瓶颈层,对于学习注意力是必要的。pre-net的输出和注意力上下文向量拼接在一起,传给一个两层堆叠的由1024个单元组成的单向lstm。lstm的输出再次和注意力上下文向量拼接在一起,然后经过一个线性投影来预测目标频谱帧。最后,目标频谱帧经过一个5层卷积的“post-net”来预测一个残差叠加到卷积前的频谱帧上,用以改善频谱重构的整个过程。post-net每层由512个5x1卷积核组成,后接批归一化层,除了最后一层卷积,每层批归一化都用tanh激活。并行于频谱帧的预测,解码器lstm的输出与注意力上下文向量拼接在一起,投影成一个标量后传递给sigmoid激活函数,来预测输出序列是否已经完成的概率。用ljspeech-1.1(基本的单说话人语料语音合成数据集)数据集对上述端到端语音合成模型进行基础的训练,其中xstyle由随机获取的中性的结果作为输入值。步骤二所需的训练步数为150000步,初始学习率为1e-3,在5000步开始学习率下降,每1000步下降0.3,学习率最终下降为1e-5。步骤三,进行迁移学习训练:对于基本的tacotron2模型在编码器的结果上连接上步骤一中得到的中间结果,并进行迁移学习训练。具体而言:对于步骤二中提到的端到端语音合成模型,利用目标说话人的语音数据进行迁移学习训练,其中xstyle为步骤二训练中获得的端到端语音合成模型的对于目标说话人的中间结果。所需的训练步数为40000步,参数设置与步骤二相同。训练完成后,在步骤一语音情感识别模型的中间结果中选取各个情感的合适作为生成语音的xstyle值输入,之后便可以生成合适的具有情感的语音文件所需的梅尔谱预测信息。对于预测的梅尔谱信息可通过声码器进行转换,转换为相应的音频文件,在本发明中可以使用的声码器有g-l算法和wavenet等进一步地,在具体实践过程中对本发明同利用one-hot编码的tacotron2(一种常用的端到端语音合成模型)迁移学习情感语音合成结果进行了mcd和xab分数的比较,mcd结果见表2,xab结果见表3。以上结果说明本发明在情感语音效果上相比于之前的结果存在一定优势。表2mcd客观测评得分情况表3xab主观测评得分情况本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips