
 商标分类
商标分类  商标转让
商标转让 
基于Star-Transformer的口语理解方法、系统及设备与流程
 2021-01-28 14:01:48|
2021-01-28 14:01:48| 259|
259| 起点商标网
起点商标网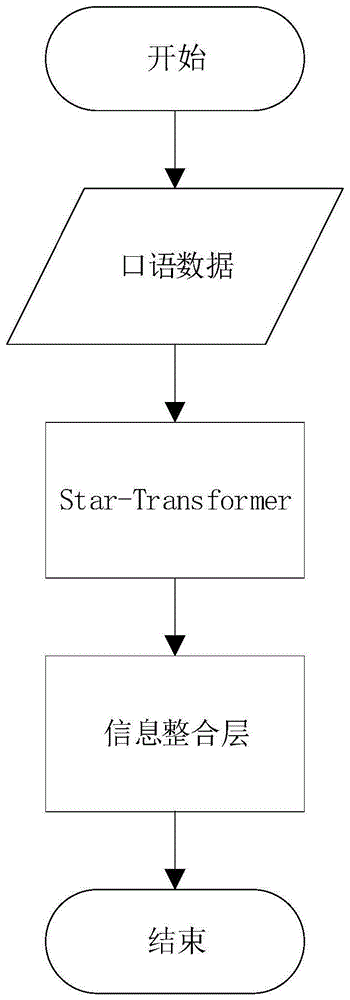
本发明涉及口语的理解方法和系统;属于语言处理技术领域。
背景技术:
随着人工智能的发展,基于深度神经网络的模型对语言识别能力越来越高,智能语音助手也相应产生;比如点播歌曲、上网购物,或是了解天气预报,它也可以对智能家居设备进行控制,比如打开窗帘、设置冰箱温度、提前让热水器升温等;语言识别技术在人工智能有着不可替代的作用;
随着深度学习技术的发展,利用神经网络对自然语言进行识别,已经能够取得较为不错的效果;但是由于自然语言具有一定的模糊性和歧义性,如何更准确的识别到人们想表达的意愿仍然是一个巨大的挑战;针对于自然语言的口语而言,口语表达相对简单且更加随意,有事甚至不符合常规的表达逻辑,而且可能具有更多的意思表达可能性,所以口语更加具有模糊性和歧义性,利用现有的神经网络对于口语的识别时,对应的准确度(准确的识别到人们想表达的意愿)和准确率较低,都有待于进一步提高。
技术实现要素:
本发明是为了解决利用现有的神经网络对口语进行识别存在的准确度较低的问题;现提供一种基于star-transformer的口语理解方法、系统及设备。
基于star-transformer的口语理解方法,首先利用star-transformer对口语语音信息对应文本序列的特征矩阵进行信息提取;然后使用双向门控循环单元对star-transformer提取的全局信息和局部信息进行整合,最后将插槽预测的概率最大的意图作为输出结果。
进一步地,所述方法还包括采集口语语音信息并将口语语音转换为文本序列,获得文本序列的特征矩阵的步骤。
进一步地,所述利用star-transformer对口语语音信息对应文本序列的特征矩阵进行信息提取的过程包括以下步骤:
口语语音信息对应文本序列的特征矩阵记为h=[h1,…,hn],其中hj表示第j个字的特征,n为文本长度;对于查询向量q∈r1×d,注意力公式如下:
其中,k=hwk,v=hwv,wk和wv为可学习参数;查询向量q为1×d的实数矩阵,表示查询向量q的列数;
由注意力公式得到多头注意力公式:
multihead(q,h)=concat(head1,…,headh)wo(2)
headi=attention(qwiq,hwik,hwiv),i∈[1,h](3)
其中,h为头的个数,wiq,wik,wiv,wo为可学习参数;concat(·)为concat函数;
对于第t∈[1,t]层,定义向量st表示中继结点,矩阵ht表示长度为n的所有卫星结点,矩阵e=[e1,…,en]表示序列长度为n的字嵌入,其中ek表示第k个字的嵌入;将卫星结点初始化为h0=e,中继结点初始化为st=average(e),average表示对矩阵取平均;t表示最后一层;
对于star-transformer更新第t层时,要分为两个阶段:(1)更新卫星结点h,(2)更新中继结点s;
在第一阶段,每一个卫星结点都将与它相邻的卫星结点、中继结点和它自己的嵌入进行拼接;随后使用多头注意力机制进行更新;最后进行归一化操作得到新的卫星结点;
其中,
在第二阶段,中继结点与已经更新过的所有卫星结点进行拼接:
st=layernorm(relu(multihead(st-1,[st-1;ht])));
star-transformer模型处理结束后完成信息提取。
进一步地,所述使用双向门控循环单元对star-transformer提取的全局信息和局部信息进行整合的过程包括以下步骤:
使用汇集了全局信息的最后一层的中继结点st作为双向门控循环单元初始隐藏结点,将最后一层中所有的卫星结点ht作为迭代信息被送到双向门控循环单元中;
其中,
最后,把st、
其中,intent和solt向量分别是意图和插槽预测的概率;
最终把预测概率最大的意图作为输出结果。
基于star-transformer的口语理解系统,所述系统包括star-transformer信息提取单元和信息整合单元;
所述star-transformer信息提取单元利用star-transformer对口语语音信息对应文本序列的特征矩阵进行信息提取;
所述信息整合单元使用双向门控循环单元对star-transformer提取的信息进行整合,最后将插槽预测的概率最大的意图作为输出结果。
进一步地,所述系统还包括文本序列的特征矩阵获取单元,所述文本序列的特征矩阵获取单元首先采集口语语音信息,并将口语语音转换为文本序列;然后根据文本序列获得文本序列的特征矩阵。
一种口语理解设备,所述设备用于存储和/或运行基于star-transformer的口语理解系统。
有益效果:
本发明通过star-transformer对自然语言分别进行局部信息和全局信息的提取,利用双向门控循环单元(bigru)对局部信息和全局信息进行整合,进而提高插槽填充和意图检测的性能,从而解决了利用现有的神经网络对口语进行识别存在的准确度较低的问题。
附图说明
图1为基于star-transformer的口语理解方法的流程示意图。
具体实施方式
具体实施方式一:参照图1具体说明本实施方式,
本实施方式为基于star-transformer的口语理解方法,包括以下步骤:
s1、搭建star-transformer信息提取层,提取全局信息和局部信息:
口语语音信息对应文本序列的特征矩阵记为h=[h1,…,hn],其中hj表示第j个字(中文就是字,英文就是单词)的特征,n为文本长度(中文就是字数,英文就是单词数);对于查询向量q∈r1×d,注意力公式如下:
其中,k=hwk,v=hwv,wk和wv为可学习参数;查询向量q为1×d的实数矩阵,表示查询向量q的列数;
由注意力公式得到多头注意力公式:
multihead(q,h)=concat(head1,…,headh)wo(2)
headi=attention(qwiq,hwik,hwiv),i∈[1,h](3)
其中,h为头的个数,wiq,wik,wiv,wo为可学习参数;concat(·)为concat函数;
对于第t∈[1,t]层,定义向量st表示中继结点,矩阵ht表示长度为n的所有卫星结点,矩阵e=[e1,…,en]表示序列长度为n的字嵌入,其中ek表示第k个字的嵌入;可以将卫星结点初始化为h0=e,中继结点初始化为st=average(e),average表示对矩阵取平均;t表示最后一层;
对于star-transformer更新第t层时,要分为两个阶段:(1)更新卫星结点h,(2)更新中继结点s;
在第一阶段,每一个卫星结点都将与它相邻的卫星结点、中继结点和它自己的嵌入进行拼接;随后使用多头注意力机制进行更新;最后进行归一化操作得到新的卫星结点;
其中,
在第二阶段,中继结点与已经更新过的所有卫星结点进行拼接,其余操作与第一阶段相同;
st=multihead(st-1,[st-1;ht])(7)
st=layernorm(relu(st))(8)
star-transformer模型处理结束后得到全局信息和局部信息;公式(8)和公式(7)也不是重复限定,而是先按照公式(7)得到
s2、搭建信息整合层,进行特征的整合:
使用双向门控循环单元对star-transformer提取的全局信息和局部信息进行整合;使用汇集了全局信息的最后一层的中继结点st作为双向门控循环单元(gru)初始隐藏结点,将最后一层中所有的卫星结点ht作为迭代信息被送到双向门控循环单元中;
其中,
最后,把st、
其中,intent和solt向量分别是意图和插槽预测的概率;
最终把预测概率最大的意图作为输出结果。
具体实施方式二:
本实施方式为基于star-transformer的口语理解方法,它包括以下步骤:
首先采集口语语音信息,并将口语语音转换为文本序列;
然后根据文本序列获得文本序列的特征矩阵h=[h1,…,hn]。
具体实施方式三:
本实施方式为基于star-transformer的口语理解系统,包括star-transformer信息提取单元和信息整合单元:
所述star-transformer信息提取单元利用star-transformer对口语语音信息对应文本序列的特征矩阵进行全局信息和局部信息的提取,具体过程如下:
口语语音信息对应文本序列的特征矩阵记为h=[h1,…,hn],其中hj表示第j个字(中文就是字,英文就是单词)的特征,n为文本长度(中文就是字数,英文就是单词数);对于查询向量q∈r1×d,注意力公式如下:
其中,k=hwk,v=hwv,wk和wv为可学习参数;查询向量q为1×d的实数矩阵,表示查询向量q的列数;
由注意力公式得到多头注意力公式:
multihead(q,h)=concat(head1,…,headh)wo(2)
headi=attention(qwiq,hwik,hwiv),i∈[1,h](3)
其中,h为头的个数,wiq,wik,wiv,wo为可学习参数;concat(·)为concat函数;
对于第t∈[1,t]层,定义向量st表示中继结点,矩阵ht表示长度为n的所有卫星结点,矩阵e=[e1,…,en]表示序列长度为n的字嵌入,其中ek表示第k个字的嵌入;那就可以将卫星结点初始化为h0=e,中继结点初始化为st=average(e),average表示对矩阵取平均;t表示最后一层;
对于star-transformer更新第t层时,要分为两个阶段:(1)更新卫星结点h,(2)更新中继结点s;
在第一阶段,每一个卫星结点都将与它相邻的卫星结点、中继结点和它自己的嵌入进行拼接;随后使用多头注意力机制进行更新;最后进行归一化操作得到新的卫星结点;
其中,
在第二阶段,中继结点与已经更新过的所有卫星结点进行拼接,其余操作与第一阶段相同;
st=multihead(st-1,[st-1;ht])(7)
st=layernorm(relu(st))(8)
star-transformer模型处理结束后得到全局信息和局部信息;公式(8)和公式(7)也不是重复限定,而是先按照公式(7)得到
所述的信息整合单元,对star-transformer提取的全局信息和局部信息进行整合,具体过程如下:
使用双向门控循环单元对star-transformer提取的全局信息和局部信息进行整合;使用汇集了全局信息的最后一层的中继结点st作为双向门控循环单元(gru)初始隐藏结点,将最后一层中所有的卫星结点ht作为迭代信息被送到双向门控循环单元中;
其中,
最后,把st、
其中,intent和solt向量分别是意图和插槽预测的概率;
最终把预测概率最大的意图作为输出结果。
具体实施方式四:
本实施方式为基于star-transformer的口语理解系统,所述系统还包括文本序列的特征矩阵获取单元,所述文本序列的特征矩阵获取单元首先采集口语语音信息,并将口语语音转换为文本序列;然后根据文本序列获得文本序列的特征矩阵h=[h1,…,hn]。
实施例
按照具体实施方式一进行实验。经过实验(在数据集上预测的结果),本发明提出的“基于star-transformer的口语理解方法”在snipsnaturallanguageunderstandingbenchmark测评数据集上的插槽填充任务、意图检测任务和总体评估任务与现有的方法对比效果见下表
表1基于star-transformer的口语理解方法的评测结果
由上表能够看出,本发明在snipsnaturallanguageunderstandingbenchmark测评数据集上的插槽填充任务、意图检测任务和总体评估任务与之前最好的相比分别提升了1.2,1.1,4.4。对于本领域来说,在三项指标达到一定准确度的情况下,再进行提高是很难的,而且本发明还能够保证三项指标都得到很好的效果,可见本发明的相比现有技术有着很大的优势。
需要注意的是,具体实施方式仅仅是对本发明技术方案的解释和说明,不能以此限定权利保护范围;凡根据本发明权利要求书和说明书所做的仅仅是局部改变的,仍应落入本发明的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



