
 商标分类
商标分类  商标转让
商标转让 
一种基于音素滤波的说话人识别方法与流程
 2021-01-28 14:01:17|
2021-01-28 14:01:17| 340|
340| 起点商标网
起点商标网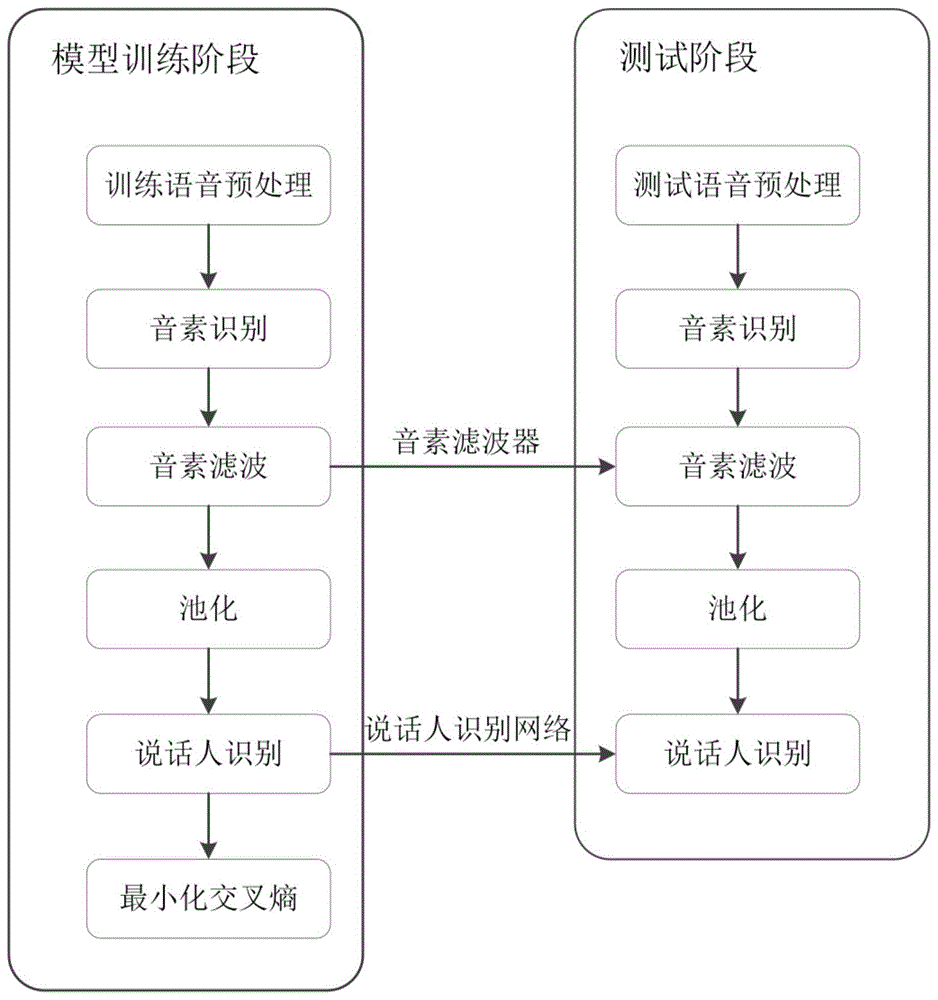
本发明属于声纹识别、模式识别与机器学习技术领域,特别地涉及一种基于音素滤波的说话人识别方法。
背景技术:
说话人识别是指根据包含在语音中的和说话人相关的信息来识别说话人身份,随着信息技术和通信技术的迅速发展,说话人识别技术越来越受到重视并在诸多领域得到广泛的应用。如身份鉴别,缉拿电话信道罪犯,法庭中根据电话录音做身份确认,电话语音跟踪,提供防盗门开启功能。互联网应用和通信领域,说话人识别技术可以应用于声音拨号、电话银行、电话购物、数据库访问、信息服务、语音e-mail、安全控制、计算机远程登录等领域。
2011年,kenny提出了基于高斯混合模型的i-vector说话人识别方法,取得当时最好的性能。随着深度神经网络的大规模应用,2014年,基于深度神经网络的d-vector说话人识别方法受到越来越多的关注,相比于传统高斯混合模型,深度神经网络的描述能力更强,能够更好地模拟非常复杂的数据分布。2017年,snyder考虑到语音的时序信息,提基于时延神经网络的x-vector的说话人识别方法。目前说话人识别方面state-of-the-art的方法就是x-vector。它首先对语音数据进行预处理,提取mfcc特征,进行活动语音检查,去掉静音部分。语音的每一帧mfcc特征都输入到一个时延神经网络中,得到每一帧的输出结果,再对一条语音的所有帧的输出结果进行池化,求取均值,根据该均值再进行该条语音的说话人识别。虽然这个方法取得了不错的效果,但是并没有直接针对说话人识别的难点进行分析和研究。说话人识别的难点在于说话人信息和语音中其他信息(比如噪声、信道、内容)纠缠在一起,并且我们不知道他们之间相互纠缠的原理。因此,我们分析说话人信息时,其他因素的不确定性,特别是语音内容信息的不确定性,会使系统性能下降。已有的说话人识别技术没有着重考虑语音内容不匹配对说话人因子识别的影响。
技术实现要素:
本发明的目的是为克服传统说话人识别技术,没有考虑语音内容信息的影响的问题,提出一种基于音素滤波的说话人识别方法。该方法为语音的每种音素建立一个音素滤波器,在进行说话人识别时,根据每一帧语音对应的音素,选择对应的音素滤波器对内容信息进行去除。从而减小内容信息对说话人识别的影响,有效地提高说话人识别的准确率。
本发明提出一种基于音素滤波的说话人识别方法,其特征在于,包括模型训练阶段和测试阶段。如附图1所示,其中模型训练包括语音预处理、音素识别、音素滤波、池化、说话人识别、最小化交叉熵阶段。说话人识别包括语音预处理、音素识别、音素滤波、池化、说话人识别步骤。具体包括以下步骤:
1)模型训练阶段;具体包括以下步骤:
1-1)语音预处理
训练语音数据集为(xi,zi)(i=1,…,i),xi为第i条训练语音,zi为第i条训练语音对应的说话人标签。对训练语音xi进行分帧并提取每一帧对应的梅尔倒谱特征
1-2)音素识别
根据步骤1)提取的梅尔倒谱特征
1-3)音素滤波
为音素n(n=1,…,n)构建它特有的音素滤波器fn。fn可以是一个深度神经网络,也可以是其他线性或非线性函数,参数为θn。音素滤波器输入为步骤1-1)提取的梅尔倒谱特征
1-4)池化
将训练语音的所有帧对应的滤除音素信息后的特征进行池化,得到该语音对应的滤除音素信息后的特征的均值。比如第i条训练语音对应的滤除音素信息后的特征的均值为:
1-5)说话人识别
构建一个说话人识别网络g,g可以是一个深度神经网络,也可以是其他线性或非线性函数,参数为φ,输入为语音滤除音素信息后的特征的均值yi,输出为该语音对应每个说话人的概率z′i=g(yi;φ)。
1-6)最小化交叉熵
目标函数为最小化通过模型预测得到训练语音对应的说话人的概率z′i和标签zi之间的交叉熵,即:
通过最小化该目标函数,训练得到每个音素对应的音素滤波器fn(n=1,…,n)的参数θn(n=1,…,n)和说话人识别网络g的参数φ。
模型训练阶段结束,得到每个音素对应的音素滤波器fn和说话人识别网络g。
2)测试阶段,具体包括以下步骤:
2-1)语音预处理
对测试语音x进行分帧并提取每一帧对应的梅尔倒谱特征xt(t=1,…,t),xt表示测试语音第t帧的特征,t表示测试语音的总帧数。
2-2)音素识别
根据步骤2-1)提取的梅尔倒谱特征xt,利用步骤1-2)所用的音素识别器,识别每一帧语音的音素。qt=1,2,…,n,其中qt为测试语音的第t帧对应的音素,n为音素总个数。
2-3)音素滤波
根据步骤2-2)得到的音素qt,若qt=n,则选择模型训练阶段训练好的音素滤波器fn作为xt的滤波器。测试语音的第t帧特征滤除音素信息后的特征为:yt=fn(xt;θn)。
2-4)池化
将测试语音的所有帧对应的滤除音素信息后的特征进行池化,得到测试语音对应的滤除音素信息后的特征的均值,即:
2-5)说话人识别
根据模型训练阶段训练好的深度神经网络g,对测试语音对应的说话人进行识别,得到语音属于各个说话人的概率z′=g(y;φ)。
完成测试语音对应的说话人识别。
本发明的特点及有益效果在于:
与现有的说话人识别技术相比,本发明着重减小语音内容信息对说话人识别的影响。由于语音承载的主要是内容信息,说话人信息作为弱信息,很容易淹没在内容信息之中,不容易识别。本发明为每个音素构建它对应的滤波器,在进行说话人识别之前,先滤除音素信息,从而使减小语音内容信息对说话人识别的影响。本发明方法提高说话人识别的准确率。
附图说明
图1是本发明方法的流程图。
具体实施方式
本发明提出一种基于音素滤波的说话人识别方法,包括模型训练阶段和说话人识别阶段。如附图1所示,其中模型训练包括语音预处理、音素识别、音素滤波、池化、说话人识别、最小化交叉熵等阶段。说话人识别包括语音预处理、音素识别、音素滤波、池化、说话人识别等步骤。具体实施例进一步详细说明如下。
1)模型训练阶段;具体包括以下步骤:
1-1)语音预处理
训练语音数据集为
1-2)音素识别
根据步骤1)提取的梅尔倒谱特征
1-3)音素滤波
为音素n(n=1,…,n)构建它特有的音素滤波器fn。fn可以是一个深度神经网络,也可以是其他线性或非线性函数,参数为θn。音素滤波器输入为步骤1-1)提取的梅尔倒谱特征
1-4)池化
将训练语音的所有帧对应的滤除音素信息后的特征进行池化,得到该语音对应的滤除音素信息后的特征的均值。比如第i条训练语音对应的滤除音素信息后的特征的均值为:
本实施例中,训练语音对应的滤除音素信息后的特征的均值为:
1-5)说话人识别
构建一个说话人识别网络g,g可以是一个深度神经网络,也可以是其他线性或非线性函数,参数为φ,输入为语音滤除音素信息后的特征的均值yi,输出为该语音对应每个说话人的概率z′i=g(yi;φ)。本实施例中,说话人识别网络采用一个8层的深度神经网络。
1-6)最小化交叉熵
本实施例中,目标函数为最小化通过模型预测得到训练语音对应的说话人的概率z′i和标签zi之间的交叉熵,即:
通过最小化该目标函数,训练得到每个音素对应的音素滤波器fn(n=1,…,39)的参数θn(n=1,…,39)和说话人识别网络g的参数φ。
模型训练阶段结束,得到每个音素对应的音素滤波器fn(n=1,…,39)和说话人识别网络g。
2)测试阶段;具体包括以下步骤:
2-1)语音预处理
对测试语音x进行分帧并提取每一帧对应的梅尔倒谱特征xt(t=1,…,t),xt表示测试语音第t帧的特征,t表示测试语音的总帧数。本实施例中,t=328。
2-2)音素识别
根据步骤2-1)提取的梅尔倒谱特征xt,利用1-2)步骤所用的音素识别器,识别每一帧语音的音素。qt=1,2,…,39,其中qt为测试语音的第t帧对应的音素,39为音素总个数。
2-3)音素滤波
根据步骤2-2)得到的音素qt,若qt=n,则选择模型训练阶段训练好的音素滤波器fn作为xt的滤波器。测试语音的第t帧特征滤除音素信息后的特征为:yt=fn(xt;θn)。
2-4)池化
将测试语音的所有帧对应的滤除音素信息后的特征进行池化,得到测试语音对应的滤除音素信息后的特征的均值,即:
2-5)说话人识别
根据模型训练阶段训练好的深度神经网络g,对测试语音对应的说话人进行识别,得到语音属于各个说话人的概率z′=g(y;φ)。
完成测试语音对应的说话人识别。
本发明所述方法,本领域普通技术人员可以理解为,上述说话人识别的方法可以通过程序来完成的,所述的程序可以存储于一种计算机可读存储介质中。
以上所述的仅为本发明的一个具体实施例而已,显然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



