
 商标分类
商标分类  商标转让
商标转让 
一种基于优化IMCRA的麦克风阵列语音增强方法与流程
 2021-01-28 14:01:29|
2021-01-28 14:01:29| 339|
339| 起点商标网
起点商标网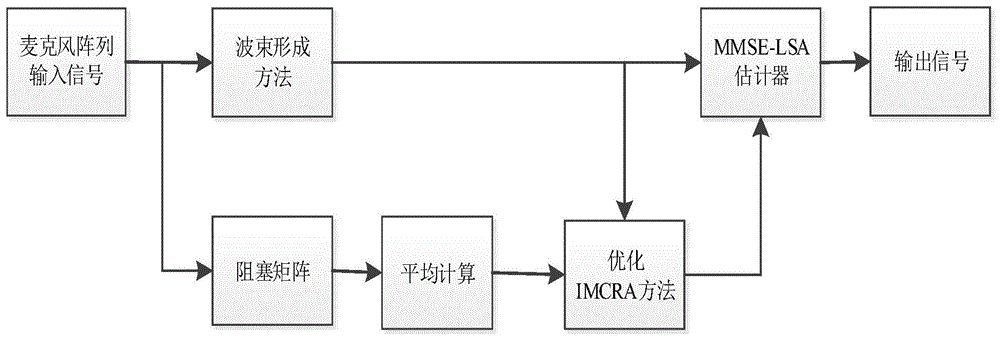
本发明涉及一种语音增强方法。特别是涉及一种基于优化imcra的麦克风阵列语音增强方法。
背景技术:
语音作为人类最基本的交流手段,是人与人之间最方便、最直接的信息交互工具。随着科学技术的飞速发展,语音也成为人与机器交流的主要工具。但在日常生活中,语音信号往往受到噪声的干扰。因此,如何降低噪声,或者说如何提高语音质量,特别是语音的可懂度,成为众多学者研究的热点。语音增强的目标是尽可能地抑制噪声。近年来,为了降低噪声,人们提出了许多语音增强方法。
根据麦克风的数量,可以分为单通道语音增强和麦克风阵列语音增强。其中,单通道语音增强算法是最早的一种。经典的单通道语音增强算法包括谱减法、维纳滤波和卡尔曼滤波等。然而,在处理过程中,谱减法会产生音乐噪声、维纳滤波法在非平稳环境下性能较差、卡尔曼滤波法会对语音造成损伤。
与传统的单通道语音增强方法相比,麦克风阵列语音增强方法具有更多的优点。它不仅利用了样本之间的时域信息,还利用了通道之间的空间信息,提高了语音增强性能。目前,已有许多成熟的麦克风阵列语音增强算法。如固定波束形成算法、自适应波束形成算法以及广义旁瓣相消法。固定波束形成算法容易实现,但需要更多的麦克风才能有效地增强语音。自适应波束形成算法是在固定波束形成的基础上发展起来的。与固定波束形成相比,其关键变化在于加权系数。自适应波束形成的加权系数不再是固定值,而是随着输入的变化而变化。该算法的灵活性得到了提高,可以应用到更多的声学环境中。广义旁瓣相消法它能消除强相关噪声,但对弱相干噪声和非相干噪声的抑制能力较差,计算更加方便灵活。
对噪声的功率谱密度进行估计是语音增强的一个重要步骤。噪声环境可分为平稳噪声环境和非平稳噪声环境。在平稳噪声环境中,噪声分布均匀且变化缓慢。它只利用含噪语音信号的噪声段来估计噪声谱,而噪声段通常由语音活动检测方法进行识别。在实际应用中,背景噪声往往是非平稳的,因此研究非平稳噪声环境下的噪声估计算法更具有实际意义。在非平稳噪声环境中,噪声是不断变化的。常用的估计方法有最小值统计法、最小控制递归平均法和改进最小控制递归平均法。
对于单通道语音增强算法,噪声功率谱估计器一般利用信号的时间谱特性。在非平稳噪声环境下,它的估计精度会下降。因为这些方法假设噪声仅在语音不存在时更新,而在语音存在时不更新。实际上,噪音总是存在的。这将导致在噪声变化很快时,非平稳噪声不能被准确地估计。
然而,麦克风阵列可以通过空间分离信号来克服单通道方法的局限性,这相对容易提取语音或噪声成分。因此,将麦克风阵列语音增强与噪声估计算法相结合,可以显著提高噪声估计的精度,同时减少了计算量。
技术实现要素:
本发明所要解决的技术问题是,提供一种能够提高噪声估计的精度和语音增强性能的基于优化imcra的麦克风阵列语音增强方法。
本发明所采用的技术方案是:一种基于优化imcra的麦克风阵列语音增强方法,包括如下步骤:
1)分别计算每个麦克风采集到的信号xn(t),构成麦克风阵列;
2)计算麦克风阵列的输出信号ya(t);
3)计算阻塞矩阵输出信号中的平均噪声信号bav(t);
4)使用优化的imcra方法估计的噪声功率谱密度
5)将麦克风阵列的输出信号y(t)和噪声功率谱密度
步骤1)包括:
设定空间中有j个信号sj(t),j∈1,2,3,...,j,n+1个麦克风,第n个麦克风在时间t接收到的信号为xn(t):
式中,hn,j是从第j个声源到第n个麦克风的声道脉冲响应,vn(t)表示加性噪声,
步骤2)包括:
对麦克风阵列在t时刻接收到的信号xn(t)使用波束形成的方法计算阵列的输出信号ya(t):
式中,阵列输入信号为xn(t),xn(t)=[x1(t),x2(t),...,xn(t)],波束形成的权重为wa(t),wa(t)=[wa,1(t),wa,2(t),...,wa,n(t)]。
步骤3)包括:
将基于麦克风阵列在t时刻接收到的信号xn(t)通过如下阻塞矩阵b,得到噪声信号:
再将所述的噪声信号采用如下公式进行平均处理得到平均噪声信号bav(t):
其中,n表示麦克风的总个数。
步骤4)是将麦克风阵列的输出信号ya(t)和平均噪声信号bav(t)经过傅立叶变换后得到对应的频域信号ya(k,l)和bav(k,l),再将所述的频域信号使用优化的imcra方法估计噪声的功率谱密度
所述的优化的imcra方法是在imcra方法中的噪声功率谱密度的更新公式加入平均噪声信号bav(t),具体公式如下:
其中,
所述的优化的imcra方法中,q(k,l)的判决阈值参数γ1=4.6,q(k,l)的判决阈值参数ζ1=1.67,第一次迭代中语音存在的判决阈值参数γ0=4.6,第一次迭代中语音存在的判决阈值参数ζ0=1.67。
本发明的一种基于优化imcra的麦克风阵列语音增强方法,将噪声估计算法与麦克风阵列语音增强相结合,不仅提高了噪声估计的精度,而且减少了语音增强的计算量。本发明的方法将麦克风阵列语音增强和单通道语音增强相结合,既利用了麦克风阵列语音增强的空域特性,也进一步去除了传统麦克风阵列语音增强的噪声残留。本发明首先使用波束形成的方法对麦克风阵列接收到的含噪信号进行处理,使含噪信号的信噪比得到提升。优化的imcra方法能估计出更加准确的噪声功率谱密度,从而使mmse-lsa估计器能输出质量更高的增强语音信号。
附图说明
图1是本发明的一种基于优化imcra的麦克风阵列语音增强方法的构成框图。
具体实施方式
下面结合实施例和附图对本发明的一种基于优化imcra的麦克风阵列语音增强方法做出详细说明。
如图1所示,本发明的一种基于优化imcra的麦克风阵列语音增强方法,包括如下步骤:
1)分别计算每个麦克风采集到的信号xn(t),构成麦克风阵列;包括:
设定空间中有j个信号sj(t),j∈1,2,3,...,j,n+1个麦克风,第n个麦克风在时间t接收到的信号为xn(t):
式中,hn,j是从第j个声源到第n个麦克风的声道脉冲响应,vn(t)表示加性噪声,
2)计算麦克风阵列的输出信号ya(t);包括:
对麦克风阵列在t时刻接收到的信号xn(t)使用波束形成的方法计算阵列的输出信号ya(t):
式中,阵列输入信号为xn(t),xn(t)=[x1(t),x2(t),...,xn(t)],波束形成的权重为wa(t),wa(t)=[wa,1(t),wa,2(t),...,wa,n(t)]。
3)计算阻塞矩阵输出信号中的平均噪声信号bav(t);包括:
将基于麦克风阵列在t时刻接收到的信号xn(t)通过如下阻塞矩阵b,得到噪声信号:
再将所述的噪声信号采用如下公式进行平均处理得到平均噪声信号bav(t):
其中,n表示麦克风的总个数。
4)使用优化的imcra方法估计的噪声功率谱密度
具体是将麦克风阵列的输出信号ya(t)和平均噪声信号bav(t)经过傅立叶变换后得到对应的频域信号ya(k,l)和bav(k,l),再将所述的频域信号使用优化的imcra方法估计噪声的功率谱密度
5)将麦克风阵列的输出信号ya(t)和噪声功率谱密度
本发明所述的优化的imcra方法是在imcra方法中的噪声功率谱密度的更新公式加入平均噪声信号bav(t),具体公式如下:
其中,
在所述的优化的imcra方法中,q(k,l)的判决阈值参数γ1=4.6,q(k,l)的判决阈值参数ζ1=1.67,第一次迭代中语音存在的判决阈值参数γ0=4.6,第一次迭代中语音存在的判决阈值参数ζ0=1.67。
下面通过在相同的仿真环境下与已有的方法进行对比,来说明本发明一种基于优化imcra的麦克风阵列语音增强方法的效果。
仿真环境是建立在开源工具mcroomsim上,它可以生成用户定义的矩形房间的混响室脉冲响应。房间属性设置为吸声系数为1的消声室,这意味着环境中没有混响或其他噪声。麦克风阵列为一个均匀的圆形麦克风阵列(uca),其间距为18厘米,n=7。uca的中心位于坐标系的原点(0,0,0),其中心轴为正x轴。目标信号置于中心轴15米处。仿真中建立了干扰源,位于(7.5,7.5,7.5)处。
从timit数据库20中随机选择一个男声和一个女声。从noisex-92数据库21中提取5种噪声信号,模拟不同的噪声环境,分别是粉红噪音、f16(飞机)噪音、白噪音、沃尔沃(汽车)噪音和m109噪音。所选的2个干净语音和5个噪声信号均在16khz下重新采样,并在-10db、-5db、0db、5db和10db下与snr混合生成目标信号。目标信号和干扰信号在仿真环境下传播到麦克风阵列。
分别使用本发明一种基于优化imcra的麦克风阵列语音增强方法、固定波束形成(ds)法以及mvdr方法的语音增强方法进行对比实验,实验结果采用分段信噪比(segsnr)和短时客观可懂度(stoi)来体现语音质量。实验结果如表1到5所示。仿真实验结果表明本发明一种基于优化imcra的麦克风阵列语音增强方法可以提高语音增强性能,在stoi和segsnr方面分别提高了12%和88%。
表1.原始信号和增强信号的平均stoi评分(女性)
表2.原始信号和增强信号的平均stoi评分(男性)
表3.原始信号和增强信号的segsnr评分(女性)
表4.原始信号和增强信号的segsnr评分(男性)
表5.m-oimcra的性别表现
从表1到表4可以看出,本发明一种基于优化imcra的麦克风阵列语音增强方法在各种噪声条件下,噪声语音的stoi和segsnr分数都能得到有效的改善。实验结果表明,本发明的方法在stoi和segsnr方面分别提高了12%和88%。
研究表明,男性嗓音中低频成分较多,女性嗓音中高频成分较多。从表5可以看出,本发明的方法对于不同类型的噪声,对于女性的降噪性能优于男性,女性的降噪效果比男性好20%。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



