
 商标分类
商标分类  商标转让
商标转让 
面向免验配助听器的语音质量自评估方法与流程
 2021-01-28 14:01:57|
2021-01-28 14:01:57| 389|
389| 起点商标网
起点商标网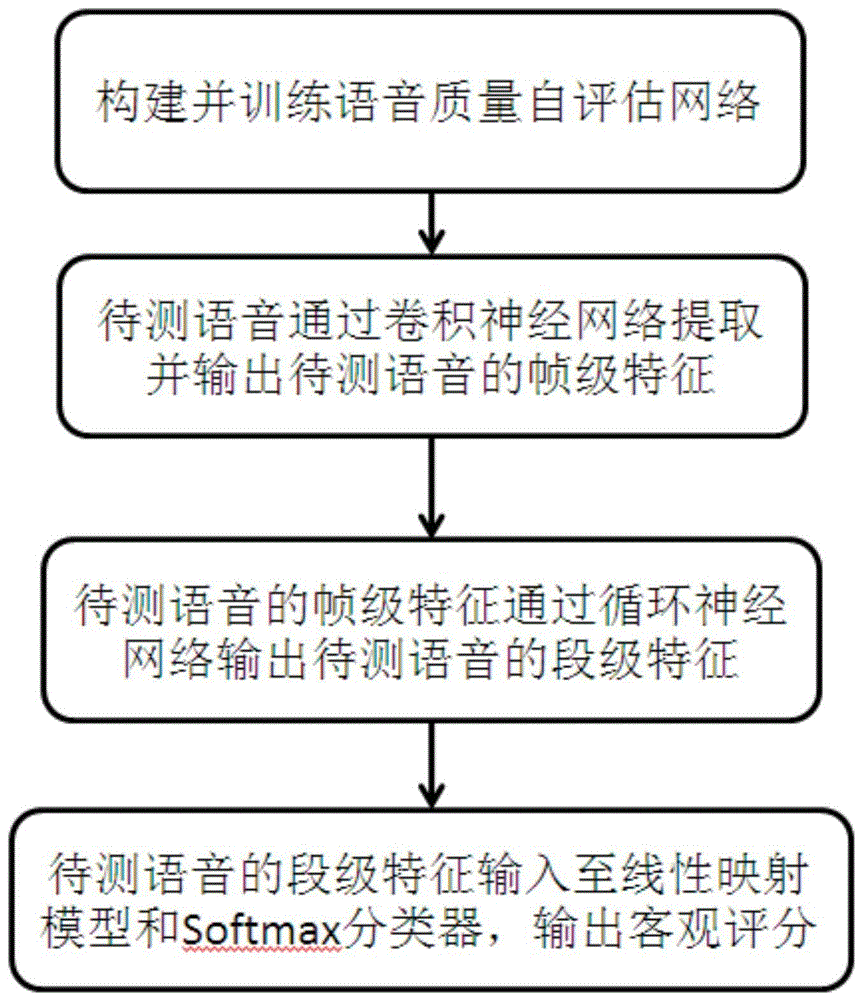
本发明涉及语音质量评价技术领域,尤其涉及一种面向免验配助听器的语音质量自评估方法。
背景技术:
传统助听器主要通过放大声信号来补偿患者缺失的声波能量和频率成分,并依靠听力专家的验配经验和专业技能来调配算法参数以尽可能达到最佳的工作状态。依靠听力专家来调配参数的本质是通过大量的知识学习和验配工作来使听力专家获得经验,使其达到一定的专业水准。很显然,这种完全依靠专家水平的验配方法低效且难以有效传承,具有很大的局限性。改善这一情况的策略之一是研究一种可以取代听力专家进行助听器调配的方法,比如助听器根据患者情况,自动评估语音质量,从而自动更新算法参数。
在语音质量评价方面,根据评价主体的不同,语音质量评价方法可分为主观评价方法和客观评价方法两大类。主观评价方法就是评测人员按照特定的规则对语音质量进行打分,常见的主观评价方法包括平均意见得分(mos)、诊断韵字测试(drt)、诊断满意度测量(dam)等。主观评价结果能够真实反映人对语音质量的主观感受,具有较高的准确度。但是这种方法需要耗费大量的时间和人力,并且需要严格地控制测试条件和主观因素,因此评测结果的重复性和稳定性差。客观评价方法则是通过算法自动评测语音质量,它具有省时省力、实时性高、结果可重复等优势,但是可靠性和准确度不及主观评价方法。在实时应用中,人们一般用客观评价方法来实现语音质量的自动评估。
根据是否需要原始参考信号,语音质量客观评价模型可分为单端模式和双端模式。双端模式的语音质量评价算法需要同时提供待测失真信号和原始参考信号,目前国际电信联盟(itu)标准化的双端客观评价算法有itu-tp.861(mnb)、itu-tp.862(pesq)、itu-tp.863(polqa)等,其他常用的客观评价算法还有短时客观可懂度(stoi)等。在这些客观评价算法中,一般都是计算失真信号和原始信号在感知域上的差异,从而得到评价结果。双端评价方法一般具有较高的准确性,但在某些应用场合中无法获取参考信号,这极大地限制了它的应用范围。单端评价方法不需要原始信号作为参考,它直接从失真信号中提取特征参数,并利用预先建立的先验知识将其映射成评价结果。被标准化的语音质量单端评价方法有itu-tp.563和itu-tg.107(e-model)等。近年来,由于深度学习的兴起,一些基于深度学习的单端语音质量评价方法也被提出,比如automos、qualitynet、nisqa、mosnet等。相比于双端评价方法,单端评价方法的灵活性更强,但由于缺乏参考,其准确度相对较低,有待进一步改进和提高。
技术实现要素:
发明目的:针对现有技术中无参考语音质量客观评价方法准确度不高的缺陷,本发明公开了一种面向免验配助听器的语音质量自评估方法,将卷积神经网络(cnns)、循环神经网络(rnns)和softmax分类器有机地结合成一个整体,利用了cnns的特征挖掘能力和rnns的时序建模能力,充分发挥了不同网络模型的优势,提高无参考语音质量客观评价方法准确度,不需要任何预处理和人工特征提取操作,大大简化了处理过程。
技术方案:为实现上述技术目的,本发明采用以下技术方案。
一种面向免验配助听器的语音质量自评估方法,包括以下步骤:
s1:构建并训练语音质量自评估网络:构建一个由卷积神经网络、循环神经网络和线性映射模型依次连接构成的混合网络作为语音质量自评估网络,利用主观测试数据进行训练,直至训练完成;
s2:待测语音输入至卷积神经网络:将待测语音输入语音质量自评估网络中的卷积神经网络,通过卷积神经网络提取并输出待测语音的帧级特征;
s3:待测语音的帧级特征输入至循环神经网络:将卷积神经网络输出的待测语音的帧级特征输入至循环神经网络,得到并输出待测语音的段级特征;
s4:待测语音的段级特征输入至线性映射模型和softmax分类器:将循环神经网络输出的待测语音的段级特征分别输入至softmax分类器和线性映射模型,对分类器的输出进行判决确定语音的失真类型,并结合线性映射模型的输出得到客观评分。
优选地,所述步骤s1中利用主观测试数据进行训练,直至训练完成的具体过程为:所述主观测试数据为语音时域数据,语音质量自评估网络输出主观mos评分,训练过程中计算语音质量自评估网络的损失函数,直至语音质量自评估网络的损失函数小于阈值,语音质量自评估网络训练完成;所述语音质量自评估网络的损失函数为:
其中,b表示批大小,moso,i表示预测的客观mos评分,moss,i表示主观mos评分。
优选地,所述语音质量自评估网络中,卷积神经网络包括依次连接的语音输入层、第一reshape层、二维卷积层、池化层、第二reshape层和帧级特征输出层;所述循环神经网络为结合注意力机制的基于lstm的循环神经网络,循环神经网络包括依次连接的帧级特征输入层、行注意力-lstm层、dense-relu层和段级特征输出层。
优选地,所述步骤s2具体过程为:
s21、待测语音进行分帧处理:对待测语音信号进行分帧,得到语音数据矩阵s∈rt×n,其中r表示实数集,t表示帧数,n表示帧长;
s21、提取待测语音的帧级特征:将语音数据矩阵s输入至卷积神经网络中的语音输入层,语音数据矩阵s经过语音输入层和第一reshape层转为三维矩阵s′∈rt×n×1,再输入至二维卷积层、池化层和第二reshape层,最终输出待测语音的帧级特征,所述帧级特征为二维矩阵f∈rt×m,其中m表示帧级特征维度;帧级特征f通过帧级特征输出层输出,并作为整个卷积神经网络的输出。
优选地,所述步骤s3具体过程为:
s31、将卷积神经网络输出的帧级特征f输入至循环神经网络中,先经过帧级特征输入层并输出;
s32、帧级特征输入层输出的帧级特征f在每个行注意力-lstm层中计算当前时间步t的输出:在时间步t,假设前t个时间步的隐藏输出为h=[h1,h2,...,ht],其中hi(i=1,2,...,t)为第i时间步的隐藏输出列向量,ht对于hi的权重定义为:
其中,w为权重矩阵,上标t表示矩阵转置;对各时间步的隐藏输出进行加权求和得到当前时间步t的输出为:
s33、所有行注意力-lstm层的输出结果输入至dense-relu层计算段级特征:所有行注意力-lstm层的输出结果输入至dense-relu层中,dense-relu层在最后一个时间步的输出为u∈rk,其中u∈rk是一个信息高度压缩的矢量,k表示dense-relu层的节点,将矢量u作为描述整段语音特性的段级特征。
优选地,所述步骤s4具体过程为:
s41:将段级特征u通过softmax分类器,得到输出矢量o;所述输出矢量o=(o1,o2,...,o6)为6种语音失真类型的预测概率分布;
s42、对输出矢量o进行判决,得到失真类型r,计算公式为:
其中,i∈{1,2,3,4,5,6},代表6种语音失真类型;
s43、将段级特征矢量u、softmax分类器输出的失真类型r和听障患者的11维听力图信息输入至线性映射模型,得到中间评分结果s;
s44、结合失真类型r和中间评分结果s得到最终的客观评分moso=sr;其中,sr是中间评分结果s的第r个分量。
优选地,所述6种语音失真类型为根据p.563得到的分类类型,具体为:强背景噪声、信号静音与间断、乘性噪声、话音机械化、不自然的男声和不自然的女声。
优选地,所述步骤s41中获取输出矢量o的具体过程为:
所述softmax分类器包括一个dense层和一个softmax层,dense层和softmax层的节点数设为6,对应6种设定的语音失真类型;假设softmax层的输入为z,其第i(i∈{1,2,3,4,5,6})个节点的输出为:
softmax层的输出矢量o=(o1,o2,...,o6)可以看作6种失真类型的概率分布,其中oi对应失真类型为第i种的预测概率。
优选地,所述步骤s43中获取中间评分结果s的具体过程为:
所述线性映射模型包括一个节点数为6的线性dense层,用于对段级特征矢量u的各分量结合听损信息进行线性组合,每种失真类型对应一组不同的线性系数,所述系数为dense层的权重wcoeff∈r32×6,wcoeff的第i(i∈{1,2,3,4,5,6})列即第i种失真类型的线性系数。
优选地,步骤s1中主观测试数据为itu-t规范的p系列语音数据库或听障患者验听后的汉语普通话言语测听材料。
有益效果:
1、本发明的面向免验配助听器的语音质量自评估方法,相比于其他无参考的语音质量评价方法,不需要任何预处理和人工特征提取操作,大大简化了处理过程,适用于听障患者进行语音质量评估;
2、本发明将卷积神经网络(cnns)、循环神经网络(rnns)和softmax分类器有机地结合成一个整体,利用了cnns的特征挖掘能力和rnns的时序建模能力,充分发挥了不同网络模型的优势,提高无参考语音质量客观评价方法准确度;
3、本发明在传统的lstm模型中融入行注意力机制,使循环单元能够从隐藏输出中筛选出丰富的有用信息;
4、本发明利用段级特征判断失真类型,再根据失真类型选择相应的线性系数将特征映射成客观评分;本发明中方法构思新颖,实时性和适用性强,具有良好的应用价值。
附图说明
图1是本发明面向免验配助听器的语音质量自评估方法的流程图;
图2是本发明实施例的结构图;
图3是本发明实施例中所使用的卷积神经网络结构示意图;
图4是本发明实施例中所使用的循环神经网络结构示意图;
图5是本发明与p.563在测试集上的预测结果散点图。
具体实施方式
以下结合附图和实施例对本发明做进一步的说明和解释。
实施例:
如附图1所示,本发明的一种面向免验配助听器的语音质量自评估方法,包括以下步骤:
步骤1:如附图2所示,构建一个由卷积神经网络、循环神经网络和线性映射模型构成的混合网络,利用主观测试数据进行训练。
主观测试数据来自itu-t规范的p系列的补充材料23被用作编码语音数据库。数据库中的源语音由两男两女录制而成,涵盖了英语、日语、法语和意大利语四种语言,以多种编解码条件对源语音进行处理。数据库中共包含1328个带有人工评分的编码语音样本,每个样本由24人打分,取其平均值作为样本的主观mos标签。从中随机选取250个样本用于测试,选取时确保测试样本和训练样本不会来自同一条源语音。由于每个样本包含两个独立的句子,我们使用vad将每个样本分成两个子样本,这些子样本与原始样本具有相同的mos标签。这样一共得到2156个训练样本和500个测试样本。
针对听障患者的主观测试集的原始测听数据来自于国内第一套标准化的汉语普通话言语测听材料——普通话单音节识别率测听cd。在验配过程中,验配专家会根据听障患者的听力状况和语音评价反馈调节助听器参数,同时播放修改后的语音给听力患者进行试听,听障患者对声音进行评价后,反馈给验配专家进行下一轮调配。除了实际验配过程中的测试数据,本发明还将普通话单音节识别率测听cd中的语音样本叠加15种noisex92库中的噪声,信噪比从-10db到20db,间隔5db,然后使用助听器语音质量指数(hasqi)获得语音评价指标。针对听障患者的主观测试数据一共有1500个训练样本和250个测试样本。
构建并训练一个由卷积神经网络、循环神经网络和线性映射模型构成的混合网络,其输入是语音时域数据,目标输出是主观mos评分;采用mmse准则对网络进行优化,损失函数具体如下:
其中,b表示批大小,即batchsize,moso,i表示预测的客观评分,moss,i表示主观评分,即主观测试数据中的主观mos标签。
其中,语音质量自评估网络中,卷积神经网络包括依次连接的语音输入层、第一reshape层、二维卷积层、池化层、第二reshape层和帧级特征输出层;所述循环神经网络为结合注意力机制的基于lstm的循环神经网络,循环神经网络包括依次连接的帧级特征输入层、行注意力-lstm层、dense-relu层和段级特征输出层。本发明将卷积神经网络(cnns)、循环神经网络(rnns)和softmax分类器有机地结合成一个整体,利用了cnns的特征挖掘能力和rnns的时序建模能力,充分发挥了不同网络模型的优势,提高无参考语音质量客观评价方法准确度。
步骤2:将待测语音输入卷积神经网络,提取待测语音的帧级特征:对待测语音信号进行分帧,得到语音数据矩阵s∈rt×n,其中r表示实数集,t表示帧数,n表示帧长;
首先对待测语音信号进行分帧,本实施例设置采样率为16khz,帧长为320点,帧移为帧长的一半,得到语音数据矩阵s∈rt×320,其中r表示实数集,t表示帧数;假设语音点数为l,则
步骤3:将卷积神经网络提取的帧级特征f经过一个结合行注意力机制的基于lstm的循环神经网络,得到语音的段级特征;
将上述帧级特征f作为输入,通过一个循环神经网络,本实施例中,该循环神经网络结构如附图4所示,循环神经网络包含4个行注意力-lstm层和一个dense-relu层,每个隐层即行注意力-lstm层的节点数为128;输出层即dense-relu的节点数为32,激活函数为relu函数;在时间步t,假设前t个时间步的隐藏输出为h=[h1,h2,...,ht],其中hi(i=1,2,...,t)为第i时间步的隐藏输出列向量,ht对于hi的权重定义为:
其中,score(ht,hi)按照乘性注意力定义为:
其中,w为权重矩阵,上标t表示矩阵转置;对各时间步的隐藏输出进行加权求和得到当前时间步的输出为:
输出层在最后一个时间步的输出u∈rk是一个信息高度压缩的低维矢量,可将其看作能够描述整段语音特性的段级特征,其中k表示dense-relu层的节点;本实施例中节点k为32,因此段级特征为u∈r32。
本发明在传统的lstm模型中融入行注意力机制,使循环单元能够从隐藏输出中筛选出丰富的有用信息。
步骤4:将循环神经网络输出的段级特征u作为输入,分别通过softmax分类器和线性映射模型,对分类器的输出进行判决确定语音的失真类型,并结合线性映射模型的输出得到客观评分;
步骤4包含以下分步骤:
步骤4.1,将段级特征u通过一个softmax分类器,得到输出矢量o;
该分类器由一个dense层和一个softmax层构成,鉴于p.563将失真类型分为6种,具体为:强背景噪声、信号静音与间断、乘性噪声、话音机械化、不自然的男声和不自然的女声。将dense层和softmax层的节点数也设为6;假设softmax层的输入为z,其第i(i∈{1,2,3,4,5,6})个节点的输出为:
softmax层的输出矢量o=(o1,o2,...,o6)可以看作6种失真类型的概率分布,其中oi对应失真类型为第i种的预测概率,由公式(5)可知
步骤4.2,对输出矢量o进行判决,得到失真类型r;
具体地,判决原理是取使概率最大的失真类型作为判决结果,即:
步骤4.3,将段级特征矢量u、softmax分类器输出的失真类型r和听障患者的11维听力图信息通过一个线性映射模型,得到中间评分结果s;
其中11维听力图信息包括听障患者在125hz,250hz,500hz,750hz,1khz,1.5khz,2khz,3khz,4khz,6khz,8khz的听阈,该11维听力图信息由听障患者通过听力测试得到。
线性映射模型是一个节点数为6的线性dense层,其作用就是对u的各分量和11维听力图信息进行线性组合,每种失真类型对应一组不同的线性系数,这些系数就是dense层的权重wcoeff∈r32×6,wcoeff的第i(i∈{1,2,3,4,5,6})列即第i种失真类型的线性系数;线性dense层输出中间评分结果s;
步骤4.4,结合失真类型和中间评分结果s得到最终的客观评分moso;具体地,moso=sr,其中,sr是s的第r个分量。
本发明利用段级特征判断失真类型,再根据失真类型选择相应的线性系数将特征映射成客观评分;本发明中方法构思新颖,实时性和适用性强,具有良好的应用价值。本发明的面向免验配助听器的语音质量自评估方法,相比于其他无参考的语音质量评价方法,不需要任何预处理和人工特征提取操作,大大简化了处理过程。
为验证本发明的语音质量自评估准确度,在同一测试集上,分别采用本发明中所述方法和p.563对结果进行预测,如附图5所示,其中横坐标为真实mos评分,纵坐标为预测mos评分,曲线为y=x线;从附图5中可以看出,本发明所述方法(seoesq)获取的各散点相较于p.563,集散密度更接近曲线,即本发明的语音质量自评估准确度更高。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



