
 商标分类
商标分类  商标转让
商标转让 
处理语音到文本的转换的制作方法
 2021-01-28 14:01:54|
2021-01-28 14:01:54| 309|
309| 起点商标网
起点商标网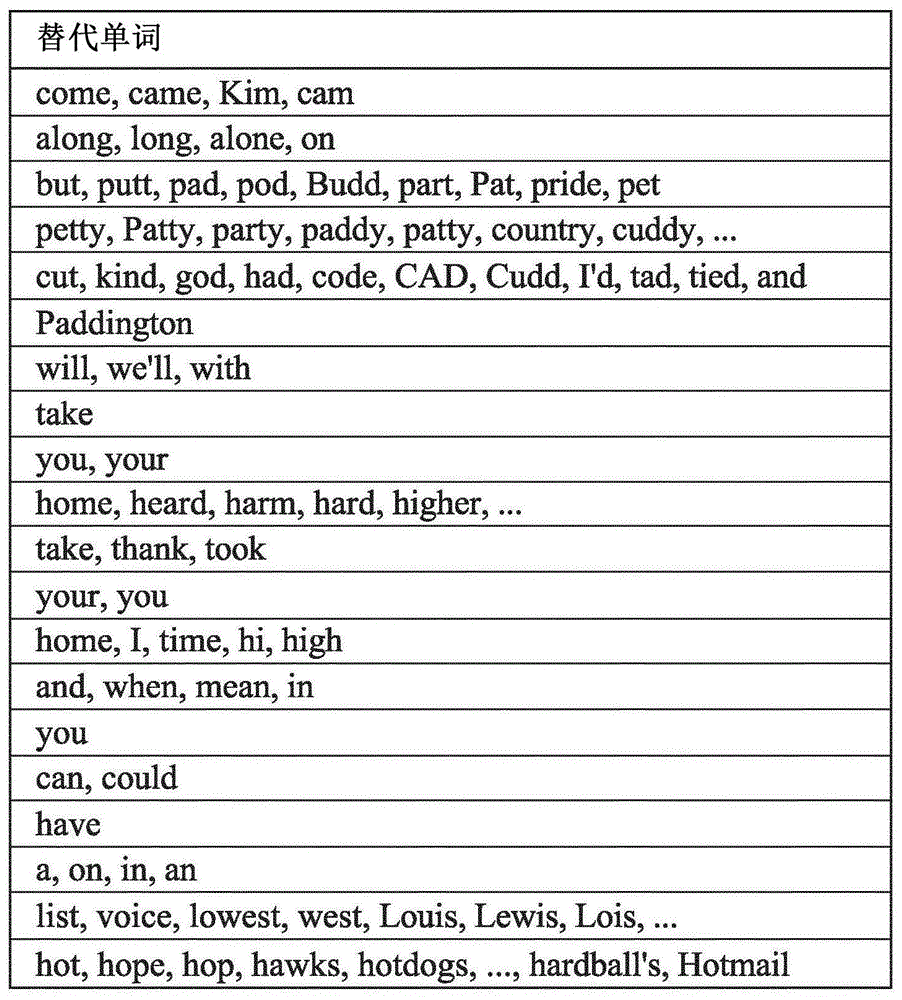
本发明涉及处理语音到文本(stt)的转换(transcription)。本发明包括方法、设备、计算机程序和非暂时性计算机可读存储介质,其可提供与处理语音到文本的转换相关的改进和/或优点。
背景技术:
:stt转换软件生成软件估计的一个人大声说出的文字的文本转换本(texttranscript)。当人们讲话时,stt软件通常可执行此操作。在某些情况下,转换本可例如输出到文字处理器,以便stt软件提供口述转换服务(dictation-transcriptionservice),允许用户通过大声朗读来撰写信件或其他文档。在其他情况下,可将文本转换本解析并解释为命令,例如来控制诸如手机、灯泡或气候控制系统之类的装置。所要求保护的发明旨在提供对语音到文本的转换的改进处理以及使用语音到文本的转换的附加功能。技术实现要素:在一个方面,本发明提供了一种分析语音的方法,包括:接收由语音到文本软件对参考文本的至少一部分的阅读者的口头阅读做出的估计,该估计包括多个估计字形,每个估计字形表示至少一个字素;将估计字形与表示至少部分参考文本的多个参考字形进行比较,每个参考字形表示至少一个字素;并基于估计字形与参考字形的比较来提供与阅读者语音相关的反馈。本发明的实施方式提供了一种分析来自参考文本的阅读的语音到文本转换的有效方式,从而可提供关于阅读者的流利度的反馈。具体地,通过比较表示字素或字素组合的字形,本发明的实施方式是独立于语言的。在一个实施方式中,每个参考字形表示参考文本中的至少一个单词,并且每个估计字形表示由语音到文本软件估计为阅读者/用户说出的单词的一组一个或多个替代单词或短语。该实施方式改善了同音词(例如“sail”和“sale”),近同音词(“are”和“our”)的处理,以及由于口吃或阅读者严重的口音而引起的转换本中的错误或不确定性。在一个实施方式中,将估计字形与参考字形进行比较包括:将每个估计字形链接到任何匹配的参考字形以产生多个链接;标识链接之间的冲突;并通过去除一些冲突的链接修剪链接以解决所有已标识的冲突。链接匹配的字形和修剪冲突的链接,可消除转换本中的诸如口吃的不流利、错误和重复单词。链接所有匹配的字形可确保为分析提供最大的链接集。仍然可分析去除的不流利,以直接或间接地根据缺失情况提供反馈——例如,剩余转换本中会有时间间隔,指示不流利发生的位置。在一个实施方式中,标识链接之间的冲突包括标识违反一组规则中的至少一个规则的链接,该组规则包括:(1)一个参考字形不得与一个以上的估计字形链接;没有一个参考字形可能具有两个链接(2)一个估计字形不得与一个以上参考字形链接;和(3)没有两个链接能够互相交叉。应用这三个规则会去除表示阅读中典型错误的链接,以准确了解阅读者的流利程度。在一个实施方式中,修剪所述链接包括:选择第一链接并标识与第一链接冲突的一组链接;确定将每个链接保持在所标识的一组冲突链接中的成本,该成本包括与该组中每个链接冲突的链接的数量;并去除所述冲突链接,但成本最低的冲突链接除外。反复选择链接,确定与保持该链接或冲突链接相关的成本,并且保持最低成本的链接有助于确保最终结果在转换本和参考文本之间提供最佳关联。在一个实施方式中,该方法包括从多个链接产生多个链接束,每个链接束包括一个或多个链接,这些链接形成与参考字形的连续序列匹配的估计字形的连续序列;并且其中,标识链接之间的冲突包括标识链接束之间的冲突。修剪链接包括去除一些冲突的链接束以解决所标识的冲突。创建链接束创建表示完全流利阅读的链接部分。这使得能够更好且更一致地处理包含阅读错误或类似“噪音”的转换。通过定义链接束以包括任何单个链接或任何连续的链接组,创建最大数量的链接束集,以进一步改善分析。在一个实施方式中,修剪链接还包括优先保持较大的链接束而不是较小的链接束,以解决所标识的冲突。大的链接束表示流利的读数,几乎没有“噪音”,因此使它们优先于单个链接或较小的链接束有助于确保保留最佳的阅读估计。在另一方面,本发明提供了一种分析用户语音的方法,包括:接收一个或多个估计字形,所述估计字形对应于由语音到文本软件对用户已大声说出的内容的估计;将一个或多个估计字形和用户尝试读出的一个或多个参考字形进行比较;并基于一个或多个估计字形与一个或多个参考字形的比较提供与用户语音相关的反馈。可选地,提供关于用户语音的反馈包括:产生多个链接,每个链接连接一个或多个估计字形中的一个字形和一个或多个参考字形中的一个字形;以及将修剪过程应用于多个链接以标识链接之间的冲突并解决所述冲突。可选地,修剪过程包括将至少一个规则应用于多个链接,该至少一个规则指定:一个或多个参考字形中的一个字形不得与一个或多个估计字形中的一个以上字形链接;一个或多个估计字形中的一个字形不得与一个或多个参考字形中的一个以上字形链接;或链接一个或多个估计字形和一个或多个参考字形中的字形的链接不得彼此交叉。可选地,修剪过程包括去除不符合至少一个规则的一个或多个链接。可选地,修剪过程包括确定保留链接的成本,并将保留所述链接的成本与保留不同链接的成本进行比较,以确定要去除两个链接中的哪一个。可选地,每个链接包括一对索引,所述一对索引标识一个或多个估计字形和一个或多个参考字形的每一个中的对应字形。可选地,该方法还包括产生多个链接束,每个链接束包括多个链接中的至少一个链接。可选地,基于由麦克风提供的输出信号,产生与由语音到文本软件对用户已经大声说出的内容的估计相对应的一个或多个估计字形。可选地,反馈包括以下一项或多项:指示用户语音的流利度的至少一个参数;以及在一个或多个参考字形中用户当前的阅读位置的至少一个表示。本发明的各方面可实施为例如设备、计算机程序或非暂时性计算机可读存储介质。附图说明现在将通过非限制性实施方式描述本发明的具体实施方式,其中:图1示出了stt转换软件的输出实例;图2示出了一种将待阅读文本中的单词与stt转换本中的单词相关的方法;图3示出了用于修剪待读文本和stt转换本中的单词之间的相关性的第一规则的实例;图4示出了用于修剪待读文本和stt转换本中的单词之间的相关性的第二规则的实例;图5示出了用于修剪待阅读的文本和stt转换本中的单词之间的相关性的第三规则的实例;图6示出了最大链接集的实例,该链接集将待阅读的文本中的单词和stt转换本中的单词相关联;图7示出了图6的实例,其中,从连续文本单词到连续转换本单词的一系列链接以粗体箭头和白框表示;图8示出了图6的实例最大链接集的变型;图9示出了应用图3至图5的第一、第二和第三修剪规则后图8的链接集;图10示出了图6的实例最大链接集的变型;图11示出了应用图3至图5的第一、第二和第三修剪规则后图10的链接集;图12示出了聚集到链接束b1和b2中的一组链接;图13示出了将图3的修剪规则应用于链接束之后图12的链接集;图14示出了聚集到链接束b1和b2中的一组链接;图15示出了聚集到链接束b1和b3中的一组链接;图16示出了聚集到链接束b1和b4中的一组链接;图17示出了聚集到链接束b1和b6中的一组链接;图18示意性地示出了用于确定一对链接束是否彼此重叠的方法;图19示出了应用于图1的实例输出的图2的方法;图20示出了部分通过链接修剪过程的图19的实例;图21示出了链接修剪过程完成后的图19的实例;和图22、图23和图24示出了应用于图1输出的链接束方法。具体实施方式本发明的实施方式表示了申请人目前将本发明付诸实践的最佳方法,但是它们并不是可实现本发明的唯一方法。仅举例说明它们,现在将对其进行描述。在某些情况下,可能需要将stt转换软件输出的文本转换本与另一个文本,例如用户正在阅读的文本,进行比较。例如,这可使得可在文本中建立用户的当前阅读位置。还可给出正在阅读文本的用户的语音准确性的指示。这可使希望提高其英语口语的用户大声阅读故事、报纸和其他文本,并接收有关数据点的反馈,诸如阅读准确性、阅读速度、流利度和发音。可向用户提供关于她或他对他或他已经大声说出的文本的清晰度的反馈。通过将stt转换本与正在阅读的文本进行比较,可确定阅读者的当前阅读位置。在理想条件下,这可能很直观——stt转换本可能与正在阅读的文本完全匹配,因此stt转换本和文本之间存在一一对应的关系。在这种情况下,可使用stt转换本中最近添加的单词来标识当前的阅读位置。但是,在实际情况下,有许多因素可能会使跟踪当前阅读位置变得困难。阅读者,特别是正在学习阅读的阅读者,可能不能流利地阅读文本。例如,他或她可能放慢或在句子中遇到陌生单词中途停下来,然后恢复以前的阅读速度。阅读者可使用填充词(例如“um”,“so”或“like”)。阅读者可能会认识到自己犯了一个错误,然后回到单词、行、句子或段落的开头,以尝试另一遍流利的阅读。阅读者可能会漏掉一个单词;无意间跳过了一行文本;重读单词、行或句子;读乱一小段文本;或迷失在文字中。此外,stt软件有时可能会错误地转换阅读者所说的话,特别是例如,如果阅读者具有stt软件无法正确解释的口音时。这些问题中的任何一个都可能导致转换错误,这使得比较用户正在阅读的文本和stt软件的输出变得困难并且容易出错。图1示出了当用户进行不流利阅读时stt软件的输出实例。在所示的实例中,用户尝试大声朗读文本迈克尔·邦德(michaelbond)的《请照顾这只熊》中的“comealong,paddington.we’lltakeyouhomeandyoucanhaveanicehotbath”。stt软件会转换用户的尝试,stt软件估计的说的各种备用单词示出在图1所示的表中,并以从左到右的置信度从高到低的顺序显示在备用行中。例如,stt软件已将用户在文本摘录开头的单词“come”的尝试解释为(以降低置信度的顺序)“come”、“came”、“kim”或“cam”。同样,stt软件将“along”解释为“along”、“long”,“alone”或“on”。用户的阅读从“comealong”流利地开始,然后在正确之前尝试几次结巴的“paddington”。接下来是“we’lltakeyouhome”,尽管阅读者实际上说的是“we’lltakeyouhome”,然后自我更正为“takeyouhome”。最后,我们得到“andyoucanhavea”,然后是“nice”、“hot”的错误转换。“bath”似乎已被遗漏,但在进一步检查stt输出最后一行中的替代单词时,出现“hardball’s”;经过一点解释,可将其视为“hotbath”。上述所有的不流利可能使得在任何给定时间都难以从stt转换本确定阅读者在阅读文本中的当前位置。因此,需要尝试标识并消除stt转换本中的不流利。为此,可先尝试将stt转换本中的单词与正在阅读的文本相关联。对于不经常出现的单词,相关性可能微不足道。例如,可将在阅读的文本中出现一次和在转换本中出现一次的单词置信度地相关。但是,通常不是这种情况。在上面的简短实例中,单词“you”出现了两次,如果用户进一步阅读了摘录所出自的书,那么其他单词也将出现多次,包括“paddington”等不太常见的单词。在阅读的文本和stt转换本之间建立相关性的一种方法可能是寻找犹豫。例如,人们可查看转换本中的犹豫词或短语,例如“erm”、“um”、“imean”等,并将其从相关性考虑中去除。但是,这种方法带来了几个问题。随着发现新的犹豫短语,犹豫单词和短语的列表可能会继续增长。不同的阅读者很可能会使用不同的“pet”犹豫短语,因此,一个阅读者可能使用“imean”,而另一个阅读者可能使用“er,sorry”,当作为软件实施时,这将导致频繁的软件更新,这可能难以保持。犹豫词也可能合法出现在正在阅读的文本中,因此不应简单地去除。另一种方法可能是寻找重复项。如图1的实例所示,阅读者有时会结巴并重复一个单词或短语,甚至开始在句子或段落的开头重新阅读。可寻找重复的单词或单词序列,将其识别为重复,并将它们从相关性考虑中排除。但是,这种方法也存在许多问题。重复的单词可能会合法地出现在正在阅读的文本中。例如,句子“ihadhadtoomanychocolatesandsodidn’tfeelverywell.”中的结构“hadhad”就是合法使用的重复单词。由于某些阅读者只会重复读错的单词,而有些阅读者可能会从行首、句子开头或段落开头重复,因此无法预测要寻找的重复单词序列的时间。另外,重复经常与犹豫短语混在一起,因此不一定很容易发现。例如,很难编撰如何从“todayiswednes,erimean,todayiswednesday”的单词中辨别出重复和犹豫单词。图2示出了根据本发明实施方式的将待阅读文本中的单词与stt转换中的单词相关联的通用方法。文字单词以以下顺序给出:文字单词意图应沿着图的顶部被阅读。给要阅读的文本中的每个单词一个索引(在所示实例中显示为“i”,其中i为1到5之间的数字),并且类似地,给由stt软件估计为已经被阅读的每个单词或单词组一个索引(在所示实例中显示为“j”,其中j为1到5之间的数字)。用链接对相关性进行建模,每个链接都将文本单词和转换本单词相关联。在这种情况下,“转换本单词”实际上可包括由stt软件提供的多个替代转换本单词。图2中索引为j=5的转换本单词示出了此概念——stt软件提供了多个选项,用于它估计示出的转换本中的最终发音的内容,由图2中的转换本单词行中索引为j=5处的级联正方形表示。如果索引j=5处的那些替代转换单词中的一个与文本单词匹配,则该文本单词和替代转换单词的集合将通过单个链接进行关联。为了表示的简单起见,附图中通常没有示出替代的转换本单词,但是图2或其他附图中的任何转换本单词也可具有多个替代转换本单词。在附图中,文本单词和转换本单词之间的相关性在象形上表示为连接文本单词和转换本单词的箭头。有时可能会以粗体显示链接以强调。然而,可以以其他方式来表示和/或存储相关性。例如,给定的链接l可表示为一对值(i,j),指示链接的起点和终点,即要阅读的文本中的单词和stt转换本中的单词或单词组通过链接连接。例如,图2中所示的链接可表示为(3,2),因为它连接了待阅读的文本中索引为i=3的单词和stt软件输出中索引为j=2的单词或单词组。最终,文本单词和转换本单词之间的一组链接应该建模为尽可能接近流利的文本阅读。流利的阅读可归类为以下一种阅读:以正确的顺序阅读单词,并且文本中的单词与转换本中的最多一个单词相关,反之,转换本中的单词与文字中的最多一个单词相关。这些约束可通过三个规则来捕获,如果一组链接表示流利的阅读,则将文本单词和转换本单词相关的任何链接都必须满足这三个规则。规则1:没有两个链接可将相同的文本单词链接到转换本单词。由于文本中的任何单词在有效阅读中仅应阅读一次,因此文本单词和转换本单词之间应有最多一个链接。作为规则1的结果,图3中所示的两个链接不能同时成为流利阅读的一部分,因为所示的两个链接将一个文本单词与两个转换本单词相关联。文本单词可能无法链接到任何转换本单词——例如,如果某个单词被阅读者跳过(即未阅读),或者该单词被stt软件错误地转换了。规则2:没有两个链接可将相同的转换本单词链接到一个文本单词。转换本中的一个单词应与文字中的最多一个单词对应。在一个完美的阅读中,每个文本单词都将链接到一个转换本单词。作为规则2的结果,图4中所示的链接不能同时成为流利阅读的一部分,因为这两个链接将两个文本单词与一个转换本单词相关联。由于多种原因中的任何一种,转换本单词可能不会链接到任何文本单词。阅读者从未说过的、错误转换的单词可能未链接到文本;犹豫词将不会链接到文本单词;例如,重新阅读的单词可能不会链接。规则3:没有两个链接可能交叉。交叉的链接表示单词被乱序阅读。作为规则3的结果,图5所示的链接不能全部都是流利阅读的一部分。违反规则1、规则2或规则3的链接被称为冲突。在以下段落中阐述了解决此类冲突的方法。要尝试获得一组表示流利阅读的链接,必须首先在文本单词和转换本单词之间创建最大的链接集。最大的链接集将在文本单词与转换本单词匹配的任何地方都包含一个链接(如上所述,一个转换本单词可能包括stt软件针对单个话语提出的几个替代转换本单词)。因此,最大的链接集不太可能为流利的阅读建模。在下面的段落中将更详细地讨论创建最大链接集的步骤,其中,文本中的每个文本单词te在文本te中都有一个索引,如图2中的以字母i所示。因此,可将文本视为文本单词的数组。类似地,转换本tr中的每个转换本单词tr都有一个索引,如图2中的以字母j所示。这些步骤可表示如下。1.设置l={}这将是一组候选链接。最初l为空,但随着标识候选链接而被填充。2.设置i=13.将tei设置为te中索引i处的文本单词。4.设置tri=match(tei,tr)tri是一组与tei匹配的转换本单词。match(te,tr)搜索tr中的每个转换本单词tr,如果te与转换本单词中的任何替代单词匹配,则返回tr。5.对于tri中的每个tr5.1.设置l=l∪{link(i,j)}——其中,j是转换本单词tr的索引。链接在索引i处的文本单词te和索引j处的转换本单词tr之间创建链接。请注意,这仅记录索引——而不是单词。6.设置i=i+17.如果i>telast——其中,telast是te中最后一个单词的索引。停止否则转到步骤4。如上所述,这创建了将尽可能多的文本单词和尽可能多的转换本单词相关联的最大的链接集。最大的链接集不太可能表示流利的文本阅读,因为在大多数情况下,单词在文本中的作用将不止一次,因此,假设此类单词至少被正确转换一次,规则2将被破坏。其他规则也可能被违反。一旦建立了最大链接集,便可对最大链接集应用修剪过程或方法(“修剪”),以标识破坏规则1、2和3中的一个或多个的链接,并去除链接直到规则都被遵守。修剪过程应最大化剩余链接的数量,因为这将导致文本和转换本单词的最佳相关性。首选的修剪过程通过评估保持冲突链接的成本来去除链接。保持链接的成本是为了满足这三个规则而需要去除的冲突链接的数量。给定一组链接,修剪过程将依次考虑每个链接及其冲突的链接,并保留成本最低的链接,因为这是导致去除最少的冲突链接的链接。链接的首选修剪过程的步骤可表示如下。1.设置lremaining={},lremoved={}。这些集合可跟踪修剪(去除)的链接和剩余的链接。最初它们是空的,但随着修剪过程的进行而被填充。2.设置lunprocessed=l-{lremaining∪lremoved}3.如果lunprocessed={}停止4.在lunprocessed中选择一个链接l5.设置lconflicting=conflicts(l,lunprocessed)conflicts(l,l)返回l的子集,其中包含与l冲突的链接,即违反规则r1、r2或r3中的至少一个规则。6.设置cl=|lconflicting|这是集合lconflicting的大小,即与l冲突的链接数。7.设置cmin=min({cl’:cl’=|conflicts(l’,lunprocessed)|,l’∈lconflicting})换句话说,找到使lunprocess中的每个链接l’保持的成本cl’。找到成本最低的链接,并将其保存在cmin中。8.如果cl<=cmin8.1.lremoved=lremoved∪lconflicting8.2.lremaining=lremaining∪{l}否则8.3.lremoved=lremoved∪{l}决定时间。如果cl<=cmin,则保留链接l。因此,我们将l添加到lremaining并将所有冲突的链接添加到lremoved。如果cl>cmin,则去除l,因此将l添加到lremoved。9.转到步骤2请注意,在步骤8中,从l到lremaining或lremoved的链接被添加。因此,最终,lremaining∪lremoved=l并且lunprocessed将为{},因此该修剪过程最终在步骤3中终止。当终止时,lremaining中的所有链接都将满足规则r1、r2和r3。修剪过程起作用,使得链接,如前所述,可表示为索引对。虽然索引指的是文本和转换本中的单词,但修剪过程完全不使用单词。修剪过程也不假定要考虑的链接的任何顺序(例如,从左到右或从右到左)。因此,尽管所描述和示出的实例出于说明目的使用英语单词,但修剪过程与语言无关,并且应该对其他语言同样有效。除适用于单词外,修剪过程还可应用于任何字素(grapheme)或字素组合,诸如字母、数字、标点、音节、徽标、象形图、表意字、速记符号或口语或话语的其他表示形式。在本文档中,“字形”一词旨在包括口语或话语的任何此类表示形式。在本文档中,一个或多个字形可构成“文本”(例如在所描述和示出的实施方式中所指的“参考文本”)。图6展示了一组要修剪的链接。假设修剪过程首先考虑链接14。l4与链接l3冲突(因为l3和l4违反了规则1导致同一个文本单词与两个转换本单词相关联)并与链接l5冲突(因为l4和l5违反了规则2导致两个文本单词与同一个转换本单词相关联)。下表中的各行给出了保持l4及其冲突链接,与相应链接冲突的链接以及因相应冲突而中断的规则的成本。链接成本冲突链接l33l1(r3),l2(r3),l4(r1),l42l3(r1),l5(r2)l51l4(r2)在此实例中,l5的保留成本最低(cmin=c5=1vsc4=2),我们将去除l4。假设修剪过程接下来考虑链接l1。只有l3与l1冲突。保留l1的成本为c1=1,而保留l3的成本为c3=2,因为在l4被去除后l3与l1和l2冲突(均基于规则3)。因此,l3被去除,其余的链接(l1,l2和l5)互不冲突,因此修剪过程结束。如前所述,修剪过程假定没有顺序考虑要修剪的链接。在实践中,按顺序阅读确实很重要。以不同的顺序关联同一转换本中的链接可能会导致微妙不同的相关性,其中一些具有比其他更多的链接——修剪过程的目的是最大化转换本中相关单词的数量。相关链接数量的这种变化往往会出现在许多不流利的阅读中,尤其是在一段文本包含相同单词序列的情况下。就是说,即使是不流利的阅读也通常会出现流利的片段。这些片段可标识为从连续文本单词到连续转换本单词的链接序列,如图7所示。流利的阅读由粗体箭头和白色框表示。在图7的实例中,考虑对链接进行修剪的顺序会影响哪些链接在修剪后存在下来,现在将参考图8、9、10和11进行描述。在每个实例中,链接均按以下顺序编号:考虑对其进行修剪(即首先考虑链接l1,然后考虑链接l2,依此类推)。在图8的实例中,修剪过程首先考虑链接l1。保持l1的成本为1(需要去除l4才能保持l1)。l4是与l1冲突的唯一链接。保持l4的成本为3(需要去除l1,l2和l3),因此将l4去除。没有与l2冲突的链接。有一个链接l5与l3冲突。保持l3的成本为1(l4已被去除,因此唯一的其他冲突链接为l5)。保持l5的成本也是1(它唯一的冲突链接是l3)。此时,修剪过程将做出任意决定保留l3并去除l5。当保持每个链接的成本相同时,以有利于冲突的链接来保留考虑的链接。在这种情况下,修剪过程可利用链接的权重(即在找到匹配项之前必须搜索的替代单词向下离列表多远)来区分冲突的链接,但是即使这样也会导致“平局”,因此仍然需要对保留哪个链接和去除哪个链接做出任意决定。以上修剪过程导致链接l1,l2和l3保留,如图9所示。从这些链接表示由图7中白框和粗体箭头表示的“流利”读数的意义上来说,这是一个很好的结果。图10示出了相同的实例,但按不同顺序考虑了链接。在图10的情况下,保持l1的成本为2(l1的冲突链接为l4和l5)。保持l4的成本为3(l4与l1,l2和l3冲突)。保持l5的成本为1(l5与l1冲突),因此l1被去除了!保持l2的成本为1(l2的冲突链接为l4)。保持l4的成本为2(l4的冲突链接为l2和l3),因此将l4去除。没有与l3和l5冲突的链接。修剪过程导致链接l2,l3和l5剩余,这是次优的——去除了l1,整个单词集中的流利阅读的一部分。因此,可能有这样的情况,其中考虑链接的顺序会导致不同的总体结果,特别是在最大链接集特别“嘈杂”的情况下,即包含大量错误链接的情况。因此,希望降低以去除“好的”链接为代价而修剪后保留了噪声链接的可能性。即使是不流利的阅读,也通常会具有流利的阅读片段,这些片段可被识别为将连续文本单词与连续转换本单词相关联的一系列链接。以良好链接为代价降低保留嘈杂链接的可能性的一种方法是将这些良好的链接序列组合在一起成为链接束,目的是在链接束上运行上述修剪过程。为此,必须稍微重新定义规则1、2和3,以考虑链接束而不是单个链接的行为,这将在以下段落中讨论。规则1的原始定义要求没有两个链接可共享相同的文本单词。在链接束的上下文中,这意味着一个链接束中的任何链接都不能与另一个文本束中的链接共享相同的文本单词。结果,图12中所示的链接束b1和b2违反规则1。具体地,以粗体显示的冲突链接违反规则1。如果对束b1和b2应用修剪过程,则将去除整个链接束,以便将去除非粗体链接(以及已去除的束中的冲突链接)。如果首先考虑束b1,则修剪过程将决定去除束b2。实际上,最好的结果是去除b2中的两个粗体链接,而幸存的链接形成一个新束,如图13中的bn所示。更笼统地说,束bn最好包含b2中所有未违反规则1的链接。违反规则1的束可如下所示。如果b是链接束,则bfrom,表示链接束b中包含的文本中第一个单词的索引的整数,bto,表示转换本中匹配单词的索引的整数,bsize,表示束中链接的数目,则在以下情况下链接束b和b’违反r1:max(bfrom+bsize,b’from+b’size)-min(bfrom,b’from)<bsize+b’size图18示意性地示出了此表达式为何标识违反规则1的链接束。在图18的上半部分显示了上述表达式的左侧。第一个链接束b显示为包含一系列正方形的矩形,每个正方形表示链接束b中链接(或者换句话说,每个正方形表示文本中一个单词,链接束b中的链接从该单词延伸)。链接束b从图的左侧开始(表示索引bfrom),并向右延伸一段距离(平方数),该距离表示链接束b中的链接数(bsize)(即表示由束b中的由链接链接的文本中连续单词的数量)。因此,链接束b以bfrom+bsize结尾。第二个链接束b’(也显示为矩形)从b’from开始,并向右延伸一段距离,该距离表示链接束b’中的链接数(b’size)。因此,链接束b’以b’from+b’size结尾。因此,通过两个链接束实现的文本的最大跨度是从bfrom和b’from的最小值(图18中最左侧)到bfrom+bsize和b’from+b’size的最大值(图18中最右侧)。该表达式的右侧如图18的下半部分所示。如果两个链接束b和b’不重叠(即,如果没有文本单词被链接束b中的链接和链接束b’中的链接链接),则它们所获得的文本的最小跨度将为bsize+b’size(由表示两个首尾相连的两个链接束的两个矩形表示)。因此,如果两个链接束之间存在重叠(即规则1被两个链接束违反),则表达式的左侧(由图18的上半部分表示)将小于表达式的右侧(由图18的下半部分表示)。如果两个链接束之间没有重叠(即规则1没有被两个链接束违反),则表达式的左侧至少与表达式的右侧一样大。可用类似的方式修改规则2,以标识违反规则2的束。在以下情况下链接束b和b’违反规则2:max(bto+bsize,b’to+bsize)min(bto,b’to)<bsize+b’size规则3也可扩展到链接束的上下文。在以下情况下链接束b和b’违反规则3:sgn(bfrom-b’from)+sgn(bto+bsize-(b’to+b’size))=0其中,sgn是符号或符号函数,对于i>0,其定义为sgn(i)=+1,对于i=0,其定义为0,对于i<0,其定义为-1。上述情况检测违反规则3的链接束,以及链接束违反规则1或2的某些情况。由于修剪过程对链接集有效,因此对修剪过程的工作没有影响,因为将链接添加到集合一次以上,例如如果检测到某个链接违反规则3和规则1,则不会导致该集合中出现同一链接的多个实例。图14中显示了交叉的链接束实例。在该实例中,这些束简单地交叉,并且修剪过程将去除b1或b2中的一个。像链接一样,创建候选链接束的最大集合是有利的。从表面上看,这似乎很直观:只需收集l(最大的候选链接集)中的链接,将连续的文本单词和连续的转换单词关联到一个链接束中。但是,这不会提供最大的链接束集。给定一个包含比如3个连续链接l1,l2和l3的链接束b,还将创建包含l1和l2,l2和l3,l1,l2和l3的链接束。这给出了一组最大的候选链接束集,每个束仅包含连续的链接,并解决了在上述链接束的背景下讨论规则1时突出显示的问题。图12中的实例显示了违反规则1的两个束b1和b2。修剪过程将去除b2,因此规则1不再被违法。图12中的实例未显示(为清楚起见)的是要考虑其他候选链接束,例如图15和图16中所示的链接束。创建的最大链接束集将包括束b3和b4。这些也与b1冲突(根据规则1),因此将被修剪过程去除。但是,由于创建了最大的候选链接束集,因此还会有另一个候选链接束b6(如图17所示,对应于图13的束bn),与b1不冲突。因此,r1中突出显示的问题无需任何特殊处理即可解决。链接束的首选修剪过程的步骤可表示如下。从一组候选链接l开始,修剪过程的步骤为:1.设置b=createlinkbundles(l)createlinkbundles实现上面概述的步骤,以创建最大的候选链接束集2.设置bremaining={},bremoved={}这些集合可跟踪被修剪(去除)的链接束和剩余的链接束。最初它们是空的,但随着修剪过程的进行它们会被填充。3.设置i=max({bsize:b∈b-bremoved})找到最大的束的大小,以便可从最大的束开始运行原始的修剪过程,然后再运行下一个最大的束,依此类推……4.设置bi={b:bsize==i,b∈{b-bremoved}}5.设置bremaining_i=修剪(bi)这是上面描述的原始修剪过程,适用于链接束,使用了如上所述的针对链接束扩展的规则1、2和3。6.设置bremaining=bremaining∪bremaining_i,并且bremoved=bremoved∪(bi-bremaining_i)bremaining_i是在修剪后幸存下来的一组链接束;这些需要添加到bremaining中。bi-bremaining_i是被修剪的链接束的集合;这些需要添加到bremoved。7.对于bremaining中的每个链接束b7.1.设置bconflicting=conflicts(b,{b’:b’∈b∧b’size<i})conflicts(b,b)返回包含与b冲突的链接束的b的子集——违反了规则1、2或3中至少一个,针对链接束进行了修改。7.2.设置bremoved=bremoved∪bconflicting任何与b冲突且大小<i的束b’∈b也应去除。链接束的主要目的是除去嘈杂的链接,因此,较大的链接束将优先于与之冲突的任何较小的链接束保持。8.如果i==0停止否则转到步骤3。如果i==0,则修剪过程结束。没有大小为0的链接束。否则,可能还有没有考虑修剪的链接束。图19示出了应用于图1的上下文中说明和描述的不流利阅读实例的图2的方法。阅读者尝试大声朗读文本迈克尔·邦德(michaelbond)的《请照顾这只熊》中的“comealong,paddington.we’lltakeyouhomeandyoucanhaveanicehotbath”。在该图的左栏中提供了一个索引,该索引可与要阅读的文本(其中的单词在中间列)和stt转换软件的输出(其中的单词,包括stt软件为每种话语建议的各种替代单词,在该图的右栏中)结合使用。已创建了一组初始链接,该链接将文本中的单词和转换本中的单词连接起来。每个链接将文本中的单词与转换本中的一个单词或一组替代单词相连,图中使用箭头表示。链接集是最大的链接集,因为只要文本中的单词与stt软件输出中的替代单词之一匹配,就会创建一个链接。例如,要阅读的文本中索引1处的单词“come”通过链接连接到stt软件输出中索引1处的单词组“come”、“came”、“kim”和“cam”,而不是stt软件输出中的任何其他单词或单词组,因为单词“come”没有出现在stt软件输出的其他位置。然而,要读取的文本中索引8处的单词“take”通过链接连接到stt输出中索引8和索引11处的单词组,因为单词“take”出现在stt软件输出中的两个这样的位置。同样,要读取的文本中索引12处的单词“you”通过链接连接到stt输出中索引9、12和15处的单词组,因为这些单词组中的每一个都包含单词“you”。如上所述,尽管在图中用象形图表示为箭头,但实际上可以以其他方式表示和/或存储链接。例如,给定的链接l可表示为一对值(i,j),指示该链接的起点和终点,即要读取的文本中单词的索引以及通过链接连接的stt软件输出中的该单词或单词组的索引。例如,将要阅读的文本中的单词“hot”和单词组“hot”、“hope”、“hop”、“hawks”、“hotdogs”等连接起来的链接可表示为(20,20),因为它连接了要读取的文本中索引20处的单词和stt软件输出中索引20处的单词组。当已经创建最大链接集时,将修剪过程应用于最大链接集,以尝试将链接集减少为尽可能接近流利地阅读要阅读的文本。修剪过程涉及应用到上面讨论的规则1-3的最大链接集,以尝试识别和去除导致通读不流利的链接。在第一种情况下,集合lremaining和lremoved为空,并且集合lunprocessed包含图19中所示的所有19个链接(链接(1,1),(2,2),(6,6)等)。由于lunprocessed不为空,选择链接(1,1)作为要测试的第一个链接。没有链接与链接(1,1)冲突,因此集合lconflicting={}(即空集)。因此,设置cl=0和cmin=0(因为没有冲突的链接,因此保持这些链接的成本为0)。因为cl=cmin,所以集合lremoved={}并且lremaining=lremaining∪{(1,1)}。然后从lunprocessed中去除(1,1),其余18个链接仍待处理。因此,在将修剪过程应用于链接(1,1)之后,将其保留在lremaining中并从lunprocessed中去除。当对链接(2,2),(6,6)和(7,7)进行修剪时,它们同样适用。接下来,选择链接(8,8)(仍在lunprocessed中)。集合lconflicting={(8,11)},因为该链接根据规则1与链接(8,8)冲突。设置cl=1且cmin=4(因为(8,11)根据规则1与链接(8,8)冲突,根据规则3与链接(12,9),(13,10)和(15,9)冲突——共四个冲突)。在这种情况下,cl<cmin。因此集合lremoved=lremoved∪{(8,11)}和lremaining=lremaining∪{(8,8)}={(1,1),(2,2),(6,6),(7,7),(8,8)}。从lunprocessed中去除(8,8)。将(12,9)作为lunprocessed的下一个要考虑的元素。集合lconflicting={(12,12),(12,15)和(15,9)},因为(12,9)根据规则1与(12,12)和(12,15)冲突,根据规则2与(15,9)冲突。设置cl=3(因为(12,9)总共有三个冲突),而cmin=5(保持链接(12,12)的成本为5,因为它根据规则1与(12,9)和(12,15)冲突,而根据规则2与(15,12)冲突,并且根据规则3与(13,10)和(15,9)冲突;保留(12,15)的成本为9,因为它根据r1与(12,9)和(12,12)冲突,根据r2与(15,15)冲突并且根据r3与(13,10)、(13,13)、(14,14)、(15,9)和(15,12)冲突;保持(15,9)的成本为7,因为它根据r2与(12,9)冲突,并且根据r3与(13,10)、(12,12)、(13,13)、(14,14)、(15,12)和(15,15)冲突)。在这种情况下,cl<cmin。因此集合lremoved={(8,11)}∪{(12,12),(12,15),(15,9)}且lremaining={(1,1),(2,2),(6,6),(7,7),(8,8)}∪{(12,9)}。从lunprocessed中去除(12,9)。lunprocessed中仍然包含元素。……图20示出了过程中此刻保留在lremaining或lunprocessed中的链接。将(13,10)作为lunprocessed的下一个要考虑的元素。集合lconflicting={(13,13)},因为(13,10)根据规则1与(13,13)冲突。设置cl=1(因为(13,10)仅与(13,13)冲突)且cmin=2(保留(13,13)的成本为2,因为它根据规则1与(13,10)冲突并且根据规则与(15,12)冲突)。在这种情况下,cl<cmin。因此集合lremoved={(8,11),(12,12),(12,15),(15,9)}∪{(13,13)}且lremaining={(1,1),(2,2),(6,6),(7,7),(8,8),(12,9)}∪{(13,10)}。从lunprocessed中去除(13,10)。lunprocessed中仍然包含元素。将(14,14)作为lunprocessed的下一个要考虑的元素。集合lconflicting={(15,12)},因为(14,14)根据规则3与(15,12)冲突。设置cl=1(因为(14,14)仅与(15,12)冲突)且cmin=2(保留(15,12)的成本为2,因为它根据规则1与(15,15)冲突并且根据规则3与(14,14)冲突)。在这种情况下,cl<cmin。因此集合lremoved={(8,11),(12,12),(12,15),(15,9),(13,13)}∪{(15,12)}且lremaining={(1,1),(2,2),(6,6),(7,7),(8,8),(12,9),(13,10)}∪{(14,14)}。从lunprocessed中去除(14,14)。lunprocessed中仍然包含元素。其余未处理的链接没有冲突的链接,因此当处理lunprocessed中剩余的元素时,不会去除其他链接。在使用链接(20,20)的修剪过程的最后迭代之后,lremoved={(8,11),(12,12),(12,15),(15,9),(13,13),(15,12)}并且lremaining={(1,1),(2,2),(6,6),(7,7),(8,8),(12,9),(13,10),(14,14),(15,15),(16,16),(17,17),(18,18),(20,20)}。当lunprocessed=l-{lremaining∪lremoved}={}时,修剪过程终止。图21示出了那时即修剪过程完成时lremaining中的链接。图22示出了使用链接束输出的文本和stt转换本的相同实例。图22示出了最大的链接束集。包含多个链接的链接束以大虚线箭头表示。链接束中包含的链接显示为未填充的空心箭头。仅包含一个链接的链接束显示为简单的黑线箭头。图22中总共有9个链接束——4个显示为大箭头,5个显示为黑线箭头。为了清楚起见,图中未明确标记链接束。链接束将使用符号(j,k,m)进行标识,表示包含m个链接的链接束,其中第一个包含的链接从文本单词j到转换(stt输出)单词k。因此,图22顶部的链接束(包含链接(1,1)和(2,2)的链接束)被标识为(1,1,2),因为链接束中的第一个链接链接了索引1处的文本单词(“come”)和索引1处的转换本单词(“come”、“came”、“kim”、“cam”),并且链接束总共包含2个链接。将上述链节束修剪过程应用于图22所示实例的过程如下。集合b={b1,1,2,b6,6,3,b8,11,1,b12,9,2,b12,15,1,b1212,7,b15,9,1,b15,12,1,b20,20,1,……}。b将包括其他链接束,这些链接束构成此处列出的子束。例如,除了b1,1,2,还有b1,1,1和b2,2,1。但是,为简单起见,这些子束未在上面或下面的步骤中列出。首先,集合bremaining和bremoved为空。设置i=7(最大束的大小,在此实例中为b12,12,7)。bi是大小为i的链接束的集合。在所示的实例中,b12,12,7是满足i=7的链接束的唯一实例。因此,对于i=7,集合bi={b12,12,7}。bremaining_i是在bi上运行链接修剪过程的结果。由于bi仅包含一个束,因此不会由于链接修剪过程而修剪任何内容。因此,集合bremaining=bremaining∪bremaining_i={b12,12,7}并且bremoved={}。接下来,对于bremaining中的每个b(在本例中仅为b12,12,7),确定bconflicting:bconflicting={b12,9,2,b12,15,1,b15,9,1,b15,12,1}(因为b12,12,7根据规则2与b12,9,2和b15,9,1冲突并且根据规则1与b12,15,1和b15,12,1冲突)。集合bremoved=bremoved∪bconflicting={b12,9,2,b12,15,1,b15,9,1,b15,12,1}。图23示出了链接束修剪过程中此时剩余的链接束。接下来,设置i=3(b中剩余的第二大链接束大小——bremoved)。集合bi={b6,6,3},因为仅剩下一个大小为3的束。集合bremaining_i={b6,6,3}。对于b6,6,3,bconflicting为{b8,11,1}(因为b6,6,3根据规则2仅与b8,11,1冲突)。集合bremoved={b12,9,2,b12,15,1,b15,9,1,b15,12,1}∪{b8,11,1}={b8,11,1,b12,9,2,b12,15,1,b15,9,1,b15,12,1}。图24示出了此时剩余的链接束。由于没有剩余的冲突链接束要去除,因此链接束修剪过程的进一步迭代不会导致链接束的任何进一步更改。最终,在测试大小为2和1的链接束是否存在冲突(i=0)之后,链接束修剪过程将停止。在图21所示的链接情况和图24所示的链接束情况下,结果都是参考文本(例如用户正在阅读的文本)中的单词与stt软件转换本(例如,软件的输出,其已解释了来自检测阅读者产生的声音的麦克风或其他装置的输入信号)中的单词之间的一组相关性。上述修剪过程和方法使得可提供有关用户语音的各种反馈。例如,修剪过程和方法使得可基于stt转换来跟踪阅读者当前的阅读位置,并且这种方式可容忍大量不流利阅读。这可启用诸如在屏幕上突出显示阅读者当前位置的功能。例如,如果用户正在阅读显示器(例如计算机屏幕、手机屏幕、平板电脑屏幕或其他可控制其输出的显示器)上显示的文本,则当用户阅读时该显示器可能会突出显示、加下划线或以其他方式在视觉上指示用户在文本中的当前位置。例如,取决于用户喜好和特定情况,显示器能够突出显示当前的单词、行、句子或段落。这可帮助阅读者在阅读过程中始终如一,从而使他们不会迷失在文本中。这也可以有助于确保说话者准确地说出所有单词。例如,如果通过stt软件确定说话者没有准确地说出某个特定单词(例如,说话者的发音不正确或用户错过了该单词),则在确定用户正确说出了这个单词之前,突出显示可能不会超过该单词。这可以有助于提高说话者自信而准确地朗读文本的能力。修剪过程和方法还使得可以跟踪给定参考文本中的阅读者正确阅读了多少个单词,并标识未正确阅读的单词。例如,可使用修剪过程和方法来维护未链接或间断链接的单词的有序列表。该列表可按单词未链接的次数占单词在阅读中遇到的次数的比例来排序,从而给出一种错误率(无论是阅读者产生的还是软件产生的)。在一些实施方式中,列表可仅包含错误率高于阈值的单词。修剪过程和方法可以使阅读者错误和上面列表中的stt软件中的错误区别开来。例如,如果某个单词首次出现在列表中,并且已知阅读者之前已经多次正确阅读了该单词(例如,由于该单词已经出现在文本中,该阅读者已经阅读了很多次并且阅读得正确无误),则可能是stt软件出现错误。对于有时会被stt软件忽略的常见短词(例如“the”、“and”和“you”)尤其如此。出现在未链接词列表中并且阅读者之前从未遇到过的新单词,或者已经在列表中的未链接单词可能是阅读错误,将被放入阅读者的“practice”列表中。当阅读者练习了列表中的单词并正确发音后,该单词将在列表中向下移动。修剪过程和方法可使得产生诸如“正确单词/读取单词”(其中正确单词的数量基于修剪后剩余链接的数量和/或修剪的链接数量)的度量,以及“每分钟读取单词”,例如基于stt软件提供的转换本中的计时信息。这样的定时信息可用于发现沉默的犹豫,和/或标识标点符号被阅读者正确地解释了——从而在遇到诸如“,”、“。”、“:”之类的东西时在语音中引入适当的停顿。修剪过程和方法可在可在移动电话、平板电脑、笔记本电脑、台式机、其他个人计算装置或可接收表示用户产生的声音的信号或数据的任何设备和可处理所述信号或数据的处理器上执行的软件中实施。例如,处理器可接收语音到文本的转换软件输出的数据。所述数据可以已经由处理器本身基于麦克风或其他语音输入装置生成的信号生成。该设备优选地包括显示器,用户可使用该显示器来获得关于他或她对参考文本的阅读的基本瞬时的反馈。修剪过程和方法可替代地或附加地使用关于参考文本中的单词链接到转换本中给定话语的“替代单词”中的第一个的频率的信息来产生度量。修剪过程可利用加权值,诸如标识在哪里找到特定匹配项的替代单词阵列中的索引。在这种情况下,可设置权重值,使得权重越小,stt软件对匹配的置信度就越大。权重0例如可指示链接到替代单词中的第一个的参考单词。这会潜在地给说话者他或她发音的准确性的指示。本发明的实施方式可由包括处理器和存储器的设备来执行。在此上下文中,处理器可以是能够执行导致上述过程和方法执行的指令的任何装置或结构。术语“处理器”旨在包括任何合适类型的处理器体系结构。类似地,在这种情况下,存储器可以是能够——无论是临时还是永久——存储数据以使得上述过程和方法能够被实施。术语“存储器”旨在包括任何合适类型的存储器,包括易失性和非易失性类型的存储器。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除
相关标签: 文本分析

 热门咨询
热门咨询




tips