
 商标分类
商标分类  商标转让
商标转让 
借助语种识别辅助语音评测的方法及系统与流程
 2021-01-28 14:01:52|
2021-01-28 14:01:52| 359|
359| 起点商标网
起点商标网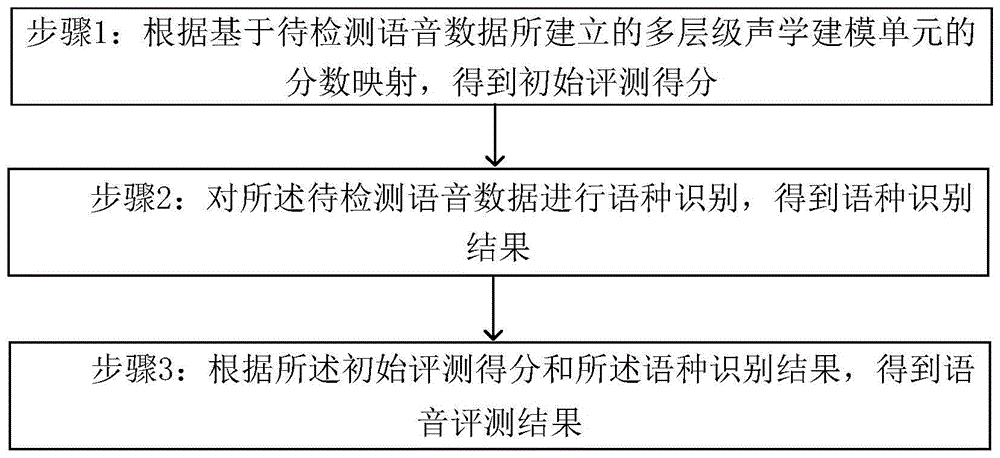
本发明涉及语音评测技术领域,特别涉及一种借助语种识别辅助语音评测的方法及系统。
背景技术:
目前的语音评测技术常针对特定语种搜集大量发音质量较高的语音数据来训练声学模型,然后通过参考文本、发音词典以及声学模型构建识别网络,最后通过gop(goodnessofpronunciation)算法给出后验概率作为衡量学习者对某个音素的发音好坏。若希望得到更多层级音段的分数,则需要组合多种特征按照至底向上的顺序,通过平均或加权平均依次得到音素、单词、句子、段落、篇章的分数。
这种方法的弊端在于,一方面,目前的语音评测技术通常要求学习者按照事先提供好的某一类语种的参考文本发音,由于识别网络只有一条路径,当学习者按照给定语种的参考文本发音时,评测系统通常能计算当前学习者的发音与模型的匹配程度,给出接近学习者发音水平的分数;而当学习者按照给定语种乱说(例如多读、乱读)时,评测系统常难以对齐当前语音与参考文本给出符合学习者真实发音水平的分数,例如给定文本为“中国人”,当学习者读“一块五毛钱”时,系统识别结果还是“中国人”;另一方面,由于解码路径仅有一条,当学习者不按照给定语种的文本发音时,即按照另外一个语种发音时,评测系统很难打零分。例如,参考文本为“你好”,学习者发成“hello”,识别结果还是“你好”,系统机器得分通常大于零分;再一方面,基于多语种融合的语音评测系统当前还没有实际落地场景。
技术实现要素:
本发明提供一种借助语种识别辅助语音评测的方法及系统,用以解决语音评测在学习者乱说情况下不能打零分的问题。
本发明提供了一种借助语种识别辅助语音评测的方法,所述方法执行以下步骤:
步骤1:根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分;
步骤2:对所述待检测语音数据进行语种识别,得到语种识别结果;
步骤3:根据所述初始评测得分和所述语种识别结果,得到语音评测结果。
进一步地,在所述步骤1中,所述多层级声学建模单元包括:音素层级建模单元、单词层级建模单元和句子层级建模单元。
进一步地,所述步骤1:根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分执行以下步骤:
步骤s11:提取所述待检测语音数据中的声学特征,经过语音识别网络计算,得到音素层级的gop后验概率和音素层级的置信分数;
步骤s12:根据所述音素层级的gop后验概率的平均值,得到单词层级的后验概率,根据所述音素层级的置信分数的平均值,得到单词层级的置信分数;
步骤s13:根据所述单词层级的置信分数和所述单词层级的后验概率的加权平均,得到句子层级的分数,并统计句子中单词后验概率打零分的比例;
步骤s14:根据所述句子层级的分数和所述句子中单词后验概率打零分的比例,得到句子的初始评测得分。
进一步地,在所述步骤s11中,根据以下公式确定所述音素层级的gop后验概率:
其中,gop(pi)表示第i个音素的gop后验概率,ts表示音素的起始时间,te表示音素的结束时间,p(oi|pi;ts,te)表示第i个观测矢量oi在模型pi下的似然分数,按照强制对齐从解码路径中获得,maxq∈qp(oi|q;ts,te)按照文本相关的音素循环网络近似获得,q表示参考文本中所有音素模型的集合;
在所述步骤s11中,基于语音识别网络,通过前后向算法获得所述音素层级的置信分数picm,picm表示第i个音素的置信分数;
在所述步骤s12中,根据以下公式确定所述单词层级的后验概率,
其中,wk表示第k个单词的后验概率,n表示单词所含音素个数;
在所述步骤s12中,根据以下公式确定所述单词层级的置信分数,
其中,wkcm表示第k个单词的置信分数;
在所述步骤s13中,根据以下公式确定所述句子层级的分数,
其中,sr表示第r个句子的置信分数;m表示句子中的单词个数,
在所述步骤s13中,根据以下公式统计句子中单词后验概率打零分的比例,
其中,zmatch表示句子中单词后验概率打零分的比例,integrityall=count(wmatch+wdel+wsub),integrityall表示依据dtw算法计算识别结果和参考文本中匹配的、删除的和替换的单词总个数;
在所述步骤s14中,根据以下公式确定句子的初始评测得分,
其中,t1表示zmatch阈值,t2表示sr阈值。
进一步地,所述步骤2:对所述待检测语音数据进行语种识别,得到语种识别结果执行以下步骤:
步骤s21:将待检测语音转化为语种向量,其中所述语种向量代表语种信息;
步骤s22:根据所述语种向量和与各语种模型对应的模型语种向量,得到语种识别结果。
进一步地,所述步骤s21:将待检测语音转化为语种向量执行以下步骤:
步骤s211:将所述待检测语音经过语音活动检测处理,以剔除所述待检测语音中的静音部分;
步骤s212:提取经过语音活动检测处理的所述待检测语音中的声学特征序列;
步骤s213:采用x-vector提取器,从所述声学特征序列中提取固定长度的向量,得到所述语种向量。
进一步地,所述步骤s22:根据所述语种向量和与各语种模型对应的模型语种向量,得到语种识别结果执行以下步骤:
步骤s221:分别对所述语种向量和所述模型语种向量进行降维处理和规整处理;
步骤s222:将经过降维处理和规整处理的所述语种向量和所述模型语种向量,经过训练好的概率线性判别分析模型进行打分处理,得到与各语种对应的得分;
步骤s223:选择得分最高并且大于语种阈值的语种,作为所述语种识别结果。
进一步地,所述步骤3:根据所述初始评测得分和所述语种识别结果,得到语音评测结果执行以下步骤:
步骤s31:对所述初始评测得分和评测总分阈值进行比较,若所述初始评测得分小于所述评测总分阈值,则执行步骤s32,若所述初始评测得分大于等于所述评测总分阈值,则执行步骤s34;
步骤s32:若所述语种识别结果和评测要求的语种不一致,则执行步骤s33,若所述语种识别结果和评测要求的语种一致,则执行步骤s34;
步骤s33:将所述初始评测得分重置为零分,作为所述语音评测结果;
步骤s34:将所述初始评测得分作为所述语音评测结果。
本发明实施例提供的一种借助语种识别辅助语音评测的方法,具有以下有益效果:基于多层级分数映射的方法,得到初始评测得分,更能精确地描述学习者实际发音水平;同时,基于语种识别和评测融合的方法,可以覆盖学习者说另一语种不能打零分的情况,而当学习者按照评测系统要求的语种发音时又不影响评测打分。
本发明还提供一种借助语种识别辅助语音评测的系统,包括:
初始评测得分计算模块,用于根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分;
语种识别模块,用于对所述待检测语音数据进行语种识别,得到语种识别结果;
语音评测模块,用于根据所述初始评测得分和所述语种识别结果,得到语音评测结果。
进一步地,所述多层级声学建模单元包括:音素层级建模单元、单词层级建模单元和句子层级建模单元。
对应地,所述初始评测得分计算模块包括:
音素层级计算单元,用于提取所述待检测语音数据中的声学特征,经过语音识别网络计算,得到音素层级的gop后验概率和音素层级的置信分数;
单词层级计算单元,用于根据所述音素层级的gop后验概率的平均值,得到单词层级的后验概率,根据所述音素层级的置信分数的平均值,得到单词层级的置信分数;
句子层级计算单元,用于根据所述单词层级的置信分数和所述单词层级的后验概率的加权平均,得到句子层级的分数,并统计句子中单词后验概率打零分的比例;
初始评测得分计算单元,用于根据所述句子层级的分数和所述句子中单词后验概率打零分的比例,得到句子的初始评测得分。
本发明实施例提供的一种借助语种识别辅助语音评测的系统,具有以下有益效果:初始评测得分计算模块基于多层级分数映射的方法,得到初始评测得分,更能精确地描述学习者实际发音水平;同时,语音评测模块基于语种识别和评测融合的方法,可以覆盖学习者说另一语种不能打零分的情况,而当学习者按照评测系统要求的语种发音时又不影响评测打分。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种借助语种识别辅助语音评测的方法的流程示意图;
图2为本发明实施例中一种借助语种识别辅助语音评测的方法的语种识别的流程示意图;
图3为本发明实施例中一种借助语种识别辅助语音评测的方法中进行语种识别所采用的x-vector提取器的结构图;
图4为本发明实施例中一种借助语种识别辅助语音评测的方法中根据初始评测得分和语种识别结果,得到语音评测结果的语种识别的流程示意图;
图5为本发明实施例中一种借助语种识别辅助语音评测的系统的框图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
本发明实施例提供了一种借助语种识别辅助语音评测的方法,如图1所示,所述方法执行以下步骤:
步骤1:根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分;
步骤2:对所述待检测语音数据进行语种识别,得到语种识别结果;
步骤3:根据所述初始评测得分和所述语种识别结果,得到语音评测结果。
上述技术方案的工作原理为:在所述步骤1中,所述多层级声学建模单元包括:音素层级建模单元、单词层级建模单元和句子层级建模单元。
具体地,本发明采用基于多层级分数映射的方法,首先根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分;然后对待检测语音数据进行语种识别,得到语种识别结果;最后根据初始评测得分和语种识别结果,得到语音评测结果。
上述技术方案的有益效果为:基于多层级分数映射的方法,得到初始评测得分,更能精确地描述学习者实际发音水平;同时,基于语种识别和评测融合的方法,可以覆盖学习者说另一语种不能打零分的情况,而当学习者按照评测系统要求的语种发音时又不影响评测打分。
在一个实施例中,所述步骤1:根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分执行以下步骤:
步骤s11:提取所述待检测语音数据中的声学特征,经过语音识别网络计算,得到音素层级的gop后验概率和音素层级的置信分数;
步骤s12:根据所述音素层级的gop后验概率的平均值,得到单词层级的后验概率,根据所述音素层级的置信分数的平均值,得到单词层级的置信分数;
步骤s13:根据所述单词层级的置信分数和所述单词层级的后验概率的加权平均,得到句子层级的分数,并统计句子中单词后验概率打零分的比例;
步骤s14:根据所述句子层级的分数和所述句子中单词后验概率打零分的比例,得到句子的初始评测得分。
上述技术方案的工作原理为:在所述步骤s11中,根据以下公式确定所述音素层级的gop后验概率:
其中,gop(pi)表示第i个音素的gop后验概率,ts表示音素的起始时间,te表示音素的结束时间,p(oi|pi;ts,te)表示第i个观测矢量oi在模型pi下的似然分数,按照强制对齐从解码路径中获得,maxq∈qp(oi|q;ts,te)按照文本相关的音素循环网络近似获得,q表示参考文本中所有音素模型的集合;
在所述步骤s11中,基于语音识别网络,通过前后向算法获得所述音素层级的置信分数picm,picm表示第i个音素的置信分数;
在所述步骤s12中,根据以下公式确定所述单词层级的后验概率,
其中,wk表示第k个单词的后验概率,n表示单词所含音素个数;
在所述步骤s12中,根据以下公式确定所述单词层级的置信分数,
其中,wkcm表示第k个单词的置信分数;
在所述步骤s13中,根据以下公式确定所述句子层级的分数,
其中,sr表示第r个句子的置信分数;m表示句子中的单词个数,
在所述步骤s13中,根据以下公式统计句子中单词后验概率打零分的比例,
其中,zmatch表示句子中单词后验概率打零分的比例,integrityall=count(wmatch+wdel+wsub),integrityall表示依据dtw算法计算识别结果和参考文本中匹配的、删除的和替换的单词总个数;
在所述步骤s14中,根据以下公式确定句子的初始评测得分,
其中,t1表示zmatch阈值,t2表示sr阈值。
上述技术方案的有益效果为:提供了根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分的具体步骤,基于多层级分数映射的方法,分别计算了后验概率和置信分数两个特征,通过加权和的方式更能精确的描述学习者实际发音水平;更进一步结合了打零分单词比例这一特征,一定程度上可以覆盖按照规定语种乱说的情况。
在一个实施例中,所述步骤2:对所述待检测语音数据进行语种识别,得到语种识别结果执行以下步骤:
步骤s21:将待检测语音转化为语种向量,其中所述语种向量代表语种信息;
步骤s22:根据所述语种向量和与各语种模型对应的模型语种向量,得到语种识别结果。
上述技术方案的工作原理为:其中,所述步骤s21:将待检测语音转化为语种向量执行以下步骤:
步骤s211:将所述待检测语音经过语音活动检测处理,以剔除所述待检测语音中的静音部分;
步骤s212:提取经过语音活动检测处理的所述待检测语音中的声学特征序列;
步骤s213:采用x-vector提取器,从所述声学特征序列中提取固定长度的向量,得到所述语种向量。
进一步地,所述步骤s22:根据所述语种向量和与各语种模型对应的模型语种向量,得到语种识别结果执行以下步骤:
步骤s221:分别对所述语种向量和所述模型语种向量进行降维处理和规整处理;
步骤s222:将经过降维处理和规整处理的所述语种向量和所述模型语种向量,经过训练好的概率线性判别分析模型进行打分处理,得到与各语种对应的得分;
步骤s223:选择得分最高并且大于语种阈值的语种,作为所述语种识别结果。
具体地,图2示出了语种识别的流程示意图,如上图2所示,语种识别分两个模块,前端模块和后端模块。前端模块主要将一段待检测语音转化为代表语种信息的特殊向量,这里表示为x-vector,具体地,首先一段待检测语音经vad(voiceactivitydetection,语音活动检测)处理后剔除静音部分,然后提取声学特征序列。提取的声学特征序列经x-vector提取器提取固定长度的向量即为x-vector。其中x-vector提取器的结构如图3所示,整个结构是一个前馈神经网络,由输入层、隐藏层、池化层和输出层组成,又可以按输入特征分为两个层级,在池化层之前是时延神经网络(timedelayneuralnetwork,tdnn)。tdnn每次取一段待检测语音的声学特征序列中的固定帧数逐层向上传递,池化层将tdnn的输出进行累计,计算均值和方差,池化层之后是两层全连接层,x-vector可以从这两层中任一层的输出提取,最后是softmax输出层,输出层节点个数为语种个数。后端为打分模块,前端模块得到的各语种模型的x-vector和一段待检测语音的x-vector,分别经过降维和规整,然后经过训练好的概率线性判别分析(probabilisticlineardiscriminantanalysis,plda)模型进行打分处理,选择得分最高并且大于阈值的语种作为最终识别语种。
上述技术方案的有益效果为:提供了对待检测语音数据进行语种识别,得到语种识别结果的具体步骤。
在一个实施例中,所述步骤3:根据所述初始评测得分和所述语种识别结果,得到语音评测结果执行以下步骤:
步骤s31:对所述初始评测得分和评测总分阈值进行比较,若所述初始评测得分小于所述评测总分阈值,则执行步骤s32,若所述初始评测得分大于等于所述评测总分阈值,则执行步骤s34;
步骤s32:若所述语种识别结果和评测要求的语种不一致,则执行步骤s33,若所述语种识别结果和评测要求的语种一致,则执行步骤s34;
步骤s33:将所述初始评测得分重置为零分,作为所述语音评测结果;
步骤s34:将所述初始评测得分作为所述语音评测结果。
上述技术方案的工作原理为:图4示出了根据初始评测得分和语种识别结果,得到语音评测结果的语种识别的流程示意图,若经过步骤1得到的初始评测得分小于评测总分阈值,则触发第二步语种识别,若语种识别结果不是当前语音评测所规定的语种,则将该句的初始评测得分重置为0分,作为语音评测结果,并且将该句中所有单词层级的置信分数和所有音素层级的置信分数都重置为0分;若语种识别结果为语音评测所要求语种则保持原来句子的初始评测得分;若第一步句子总分大于等于阈值则不触发语种识别,保持原来句子得分。
综上,可以通过以下公式确定语音评测结果,
其中,score表示语音评测总分,sthreshold表示评测总分阈值。
上述技术方案的有益效果为:提供了根据初始评测得分和语种识别结果,得到语音评测结果的具体步骤,基于语种识别和评测融合的方法,可以覆盖学习者说另一语种不能打零分的情况,而当学习者按照评测系统要求的语种发音时又不影响评测打分。
如图2所示,本发明实施例提供了一种借助语种识别辅助语音评测的系统,包括:
初始评测得分计算模块201,用于根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分;
语种识别模块202,用于对所述待检测语音数据进行语种识别,得到语种识别结果;
语音评测模块203,用于根据所述初始评测得分和所述语种识别结果,得到语音评测结果。
上述技术方案的工作原理为:所述多层级声学建模单元包括:音素层级建模单元、单词层级建模单元和句子层级建模单元。
具体地,本发明采用基于多层级分数映射的技术,利用初始评测得分计算模块201根据基于待检测语音数据所建立的多层级声学建模单元的分数映射,得到初始评测得分;利用语种识别模块202对待检测语音数据进行语种识别,得到语种识别结果;利用语音评测模块203根据初始评测得分和语种识别结果,得到语音评测结果。
上述技术方案的有益效果为:初始评测得分计算模块基于多层级分数映射的方法,得到初始评测得分,更能精确地描述学习者实际发音水平;同时,语音评测模块基于语种识别和评测融合的方法,可以覆盖学习者说另一语种不能打零分的情况,而当学习者按照评测系统要求的语种发音时又不影响评测打分。
在一个实施例中,所述初始评测得分计算模块201包括:
音素层级计算单元,用于提取所述待检测语音数据中的声学特征,经过语音识别网络计算,得到音素层级的gop后验概率和音素层级的置信分数;
单词层级计算单元,用于根据所述音素层级的gop后验概率的平均值,得到单词层级的后验概率,根据所述音素层级的置信分数的平均值,得到单词层级的置信分数;
句子层级计算单元,用于根据所述单词层级的置信分数和所述单词层级后验概率打零分的后验概率的加权平均,得到句子层级的分数,并统计句子中单词比例;
初始评测得分计算单元,用于根据所述句子层级的分数和所述句子中单词后验概率打零分的比例,得到句子的初始评测得分。
上述技术方案的工作原理为:音素层级计算单元根据以下公式确定所述音素层级的gop后验概率:
其中,gop(pi)表示第i个音素的gop后验概率,ts表示音素的起始时间,te表示音素的结束时间,p(oi|pi;ts,te)表示第i个观测矢量oi在模型pi下的似然分数,按照强制对齐从解码路径中获得,maxq∈qp(oi|q;ts,te)按照文本相关的音素循环网络近似获得,q表示参考文本中所有音素模型的集合;
音素层级计算单元基于语音识别网络,通过前后向算法获得所述音素层级的置信分数picm,picm表示第i个音素的置信分数;
单词层级计算单元根据以下公式确定所述单词层级的后验概率,
其中,wk表示第k个单词的后验概率,n表示单词所含音素个数;
单词层级计算单元根据以下公式确定所述单词层级的置信分数,
其中,wkcm表示第k个单词的置信分数;
句子层级计算单元根据以下公式确定所述句子层级的分数,
其中,sr表示第r个句子的置信分数;m表示句子中的单词个数,
句子层级计算单元根据以下公式统计句子中单词后验概率打零分的比例,
其中,zmatch表示句子中单词后验概率打零分的比例,integrityall=count(wmatch+wdel+wsub),integrityall表示依据dtw算法计算识别结果和参考文本中匹配的、删除的和替换的单词总个数;
初始评测得分计算单元根据以下公式确定句子的初始评测得分,
其中,t1表示zmatch阈值,t2表示sr阈值。
上述技术方案的有益效果为:借助于音素层级计算单元、单词层级计算单元、句子层级计算单元和初始评测得分计算单元,可以得到初始评测得分,基于多层级分数映射的方法,分别计算了后验概率和置信分数两个特征,通过加权和的方式更能精确的描述学习者实际发音水平;更进一步结合了打零分单词比例这一特征,一定程度上可以覆盖按照规定语种乱说的情况。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



