
 商标分类
商标分类  商标转让
商标转让 
一种无重叠子带划分快速独立向量分析语音盲分离方法及系统与流程
 2021-01-28 14:01:38|
2021-01-28 14:01:38| 352|
352| 起点商标网
起点商标网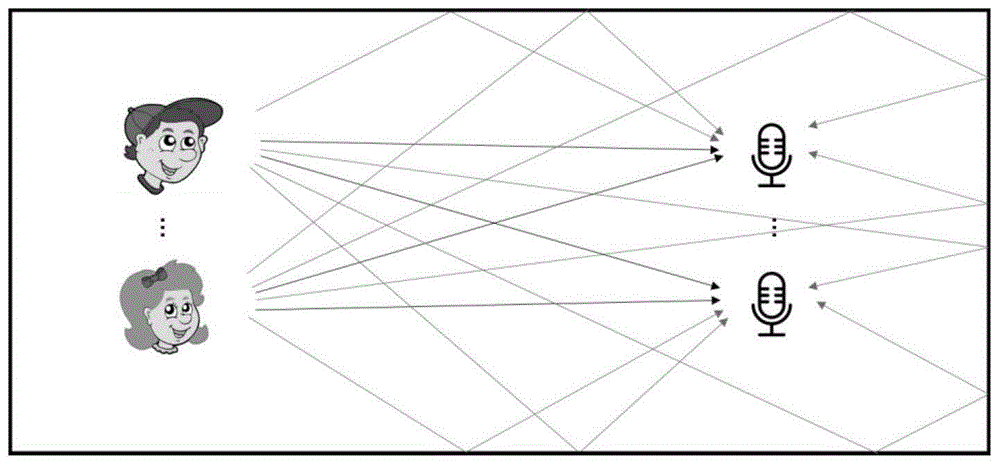
本发明属于频域语音盲分离中的子带划分方式和排序不确定性解决装置领域,具体而言,涉及一种无重叠子带划分快速独立向量分析语音盲分离方法。
背景技术:
房间中的传声器接收到的是来自多说话人的混合语音信号,各独立的语音信号之间相互干扰,给语音识别等技术带来困难。
盲源分离在只有混合信号的情况下,利用信号的统计特性等信息对源信号进行分离。盲源分离典型的应用是解决“鸡尾酒会问题”,即分离室内传声器接收到的来自多个声源的卷积混合语音信号,其在医学核磁共振信号分离和振动故障检测等方面也有重要应用。
混合信号可分为两类,无时延的直达声传输到传声器混合而成是瞬时混合信号,然而实际环境中不仅存在直达声,还有经过不同路径的时延和衰减的反射声传输到传声器,形成卷积混合信号,如图1所示。针对卷积混合的语音信号,时域算法计算量较大,通常将语音信号转换到时频域进行处理。
独立分量分析是一种应用广泛的盲源分离算法,主要基于信号的高阶统计特性,通常对瞬时混合的非高斯信号有较好的分离性能。在频域分离卷积混合信号时,独立分量分析算法假设每个频点信号满足独立性,在每个频点中单独进行信号分离。然而频域独立分量分析算法会因频点间的排序不确定性导致算法性能下降,因此需要在信号反变换回时域前解决排序不确定问题。
独立向量分析算法仍然在每个频点中单独更新分离矩阵,同时该算法在每个频点的更新中都利用了所有频点之间的高阶相关性,从原理上能有效解决频域盲源分离算法中的排序不确定问题。并且基于牛顿梯度的快速独立向量分析算法的收敛速度快于基于自然梯度的算法。
不同频点之间的高阶相关性的强弱并不相同,相邻频点之间的相关性较强,距离较远的频点之间的相关性较弱。重叠频带划分的快速独立向量分析利用频带之间的重叠部分来传递高阶相关性,但是这种方法不可靠,容易导致频带之间产生排序错乱。并且该类算法的声源假设基于多变量拉普拉斯分布,不能根据声源性质调整算法的相应参数,限制了算法的分离性能。
技术实现要素:
本发明的目的在于解决现有语音识别技术由于时域算法计算量大、频点间排序的不确定性以及算法性能下降和不可靠导致语音分离性能差的问题;
本发明提出的一种无重叠子带划分快速独立向量分析语音盲分离方法,特别涉及快速独立向量分析算法的子带划分以及解决子带之间排序不确定性问题,该方法在快速独立向量分析中利用无重叠子带划分来确保子带内部的排序一致性然后采用功率比相关法调整子带之间的排序,基于调整子带排序后的频域声源信号,根据幅值确定的分离矩阵,计算排序后的频域声源信号估计值,将排序后的频域声源信号变换回时域,得到最终估计的声源信号,实现语音盲分离。
本发明提出的一种无重叠子带划分快速独立向量分析语音盲分离方法,所述方法包括:
将时域内多通道卷积混合语音信号转换到频域;对频域内的混合语音信号进行中心化和白化预处理;
将预处理后的混合语音信号进行无重叠子带划分,根据采样率调整划分子带数和子带大小;
采用快速独立向量算法计算无重叠子带每个频点的分离矩阵;利用最小失真准则获得幅值确定的分离矩阵;然后再根据功率比相关调整分离矩阵的子带排序;
基于调整子带排序后的分离矩阵,计算排序后的频域声源信号估计值,将排序后的频域声源信号变换回时域,得到最终估计的声源信号,实现语音盲分离。
作为上述方法的一种改进,所述方法具体包括:
步骤1)将各通道卷积混合语音信号进行短时傅里叶变换转换到频域后得到时频域的混合语音信号
其中,j为第j个传声器的序号,j=1,2,...j,传声器总个数为j,m为第m个声源的序号,m=1,2,...m,声源总个数为m,k为第k频点索引的序号,k=1,2,...,k,k为总频点索引个数;l为第l帧缩引的序号,l=1,2,...,l,l为帧索引总数量;
步骤2)对频域第k频点的混合语音信号
其中,i为序列长度的序号,计算中心化处理后混合信号
ψ=λ-1/2et(3)
将白化矩阵ψ与第k频点的混合信号
步骤3)对白化预处理后的混合语音信号
步骤4)采用快速独立向量算法计算无重叠子带每个频点的分离矩阵w'(k);
步骤5)利用最小失真准则调整幅值,得到幅值确定的分离矩阵w(k):
w(k)=diag(w'(k))-1w'(k)(10)
步骤6)根据功率比相关调整分离矩阵的子带排序:
其中d1和d2分别表示要排序的两段子带,
步骤7)基于调整子带排序后的分离矩阵w(k),计算排序后的频域声源信号
其中,
作为上述方法的一种改进,所述步骤3)具体包括:当采样率为16khz时,采用均匀4段子带划分,具体子带划分范围为:0-2000hz,2000-4000hz,4000-6000hz,6000-8000hz。
作为上述方法的一种改进,所述步骤4)具体包括:
步骤401)采用单位矩阵初始化每个频点的分离矩阵w'(k),迭代次数ite初始值为1;
步骤402)计算当前迭代次数时频点(k,l)中的第m个声源的声源信号
其中,
步骤403)采用多变量广义高斯分布时,相应子带划分的声源分布为q(ym):
其中c=1,2,...,c,c为子带索引的个数,c为第c个子带索引的序号,bc和ec分别是第c个子带的第一个和最后一个频点索引,β为分布的形状参数;
令
g(z)=-logq(ym)(6)
根据公式(3)获得当前迭代次数下频点k的分离矩阵得到
其中g'(·)和g″(·)分别表示非线性函数g(·)的一阶导数和二阶导数,(·)*表示共轭;
步骤404)计算当前迭代次数下的代价函数jite:
计算当前迭代次数下的代价函数jite相对上一次迭代的变化值δj:
若δj<u,u为门限值,则判断算法已收敛,迭代过程结束,得到分离矩阵w'(k),
比较当前迭代次数ite是否达到最大迭代次数,若比较结果为“是”,则迭代过程结束,得到分离矩阵w'(k),
返回步骤402)将ite值加1继续迭代。
作为上述方法的一种改进,所述系统包括:信号时频域变换处理模块、无重叠子带划分模块、子带排序模块和声源语音分离模块;
所述信号时频域变换处理模块,用于将时域内多通道卷积混合语音信号转换到频域进行中心化和白化预处理;
所述无重叠子带划分模块,用于将预处理后的混合语音信号进行无重叠子带划分,根据采样率调整划分子带数和子带大小;
所述子带排序模块,用于采用快速独立向量算法计算无重叠子带每个频点的分离矩阵;利用最小失真准则获得幅值确定的分离矩阵;然后再根据功率比相关调整分离矩阵的子带排序;
所述声源语音分离模块,用于基于调整子带排序后的分离矩阵,计算排序后的频域声源信号估计值,将排序后的频域声源信号变换回时域,得到最终估计的声源信号,实现语音盲分离。
本发明还提出一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述的方法。
本发明还提出计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述任一项所述的方法。
与现有技术相比,本发明的有益效果在于:
1、本发明提出无重叠子带划分快速独立向量分析语音盲分离方法,该方法能更好地利用相邻频点之间的高阶相关性,以保证子带内部排序的一致性。
3、本发明可根据语音频谱的高低频特性进行非均匀无重叠子带划分,采用功率比相关后处理方式在上述无重叠子带划分的快速独立向量分析算法迭代结束后调整子带之间的排序,提高快速独立向量分析算法的语音分离性能。
4、本发明将多变量广义高斯分布用于上述无重叠子带划分快速独立向量分析算法中,进一步提高算法的分离性能。
附图说明
图1为语音信号的卷积混合模型示意图;
图2为本发明无重叠子带划分快速独立向量分析语音盲分离方法的无重叠子带划分快速独立向量分析算法框图;
图3为本发明无重叠子带划分快速独立向量分析语音盲分离方法的无重叠子带划分示意图;
图4(a)为纯净女声语音1;
图4(b)为纯净男声语音2;
图4(c)为混合语音1;
图4(d)为混合语音2;
图4(e)为传统iva算法分离语音1;
图4(f)为传统iva算法分离语音2;
图4(g)为本发明无重叠子带划分快速独立向量分析语音盲分离方法的分离语音1;
图4(h)为本发明无重叠子带划分快速独立向量分析语音盲分离方法的分离语音2。
具体实施方式
下面结合附图和具体实施例对本发明进行详细的说明。
如图2所示,本发明采用以下技术方案:
步骤1)将各通道卷积混合语音信号进行短时傅里叶变换转换到频域后得到时频域的混合语音信号
其中,j为第j个传声器的序号,j=1,2,...j,传声器总个数为j,m为第m个声源的序号,m=1,2,...m,声源总个数为m,k为第k频点索引的序号,k=1,2,...,k,k为总频点索引个数;l为第l帧缩引的序号,l=1,2,...,l,l为帧索引总数量;
步骤2)对频域第k频点的混合语音信号
其中,i为序列长度的序号,计算中心化处理后混合信号
ψ=λ-1/2et(3)
将白化矩阵ψ与第k频点的混合信号
步骤3)对白化预处理后的混合语音信号
对信号全频带进行无重叠子带划分,具体划分子带数和子带大小可根据采样率等参数进行调整,通常可采用均匀划分,4段均匀子带划分示意图如图3所示。
语音高频段的高阶相关性较强,采用较窄的子带如1khz就可以保证子带之间的排序一致性;而语音低频段的高阶相关性较弱,可采用较宽的子带如3khz来保证相关性强弱不一的频点之间的排序一致性。
步骤4)采用快速独立向量算法计算无重叠子带每个频点的分离矩阵w'(k);
其具体步骤如下:
步骤401)采用单位矩阵初始化每个频点的分离矩阵w'(k),迭代次数ite初始值为1;
步骤402)计算当前迭代次数时频点(k,l)中的第m个声源的声源信号
其中,
步骤403)采用多变量广义高斯分布时,相应子带划分的声源分布为q(ym):
其中c=1,2,...,c,c为子带索引的个数,c为第c个子带索引的序号,bc和ec分别是第c个子带的第一个和最后一个频点索引,β为分布的形状参数;
令
g(z)=-logq(ym)(6)
根据公式(3)获得当前迭代次数下频点k的分离矩阵得到
其中g'(·)和g″(·)分别表示非线性函数g(·)的一阶导数和二阶导数,(·)*表示共轭;
步骤404)计算当前迭代次数下的代价函数jite:
计算当前迭代次数下的代价函数jite相对上一次迭代的变化值δj:
若δj<u,u为门限值,则判断算法已收敛,迭代过程结束,得到分离矩阵w'(k),
比较当前迭代次数ite是否达到最大迭代次数,若比较结果为“是”,则迭代过程结束,得到分离矩阵w'(k),
返回步骤402)将ite值加1继续迭代。
步骤5)利用最小失真准则调整幅值,得到幅值确定的分离矩阵w(k):
w(k)=diag(w'(k))-1w'(k)(10)
步骤6)根据功率比相关调整分离矩阵的子带排序:
其中d1和d2分别表示要排序的两段子带,
步骤7)基于调整子带排序后的分离矩阵w(k),计算排序后的频域声源信号
其中,
采用本文发明对混响时间为0.3s的房间中录取到的两通道混合语音分离结果对比图如图4(a)-4(g)所示。语音长度10s,采样率16khz,具体子带划分为[0,2000]、[2000,4000]、[4000,6000]、[6000,8000]hz。两传声器相距0.0566m,声源与传声器相距2m,两声源分别在50°和130°方向。stft帧长和汉宁窗长2048点,帧移1024点。多变量广义高斯分布的形状参数β=1。结果表明本文发明有较高的分离性能。
本发明还提出一种无重叠子带划分快速独立向量分析语音盲分离系统,所述系统包括:信号时频域变换处理模块、无重叠子带划分模块、子带排序模块和声源语音分离模块;
所述信号时频域变换处理模块,用于将时域内多通道卷积混合语音信号转换到频域进行中心化和白化预处理;
所述无重叠子带划分模块,用于将预处理后的混合语音信号进行无重叠子带划分,根据采样率调整划分子带数和子带大小;
所述子带排序模块,用于采用快速独立向量算法计算无重叠子带每个频点的分离矩阵;利用最小失真准则获得幅值确定的分离矩阵;然后再根据功率比相关调整分离矩阵的子带排序;
所述声源语音分离模块,用于基于调整子带排序后的分离矩阵,计算排序后的频域声源信号估计值,将排序后的频域声源信号变换回时域,得到最终估计的声源信号,实现语音盲分离。
本发明还提出一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述的方法。
本发明还提出计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述任一项所述的方法。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



