
 商标分类
商标分类  商标转让
商标转让 
语音识别系统及使用语音识别系统的方法与流程
 2021-01-28 14:01:25|
2021-01-28 14:01:25| 284|
284| 起点商标网
起点商标网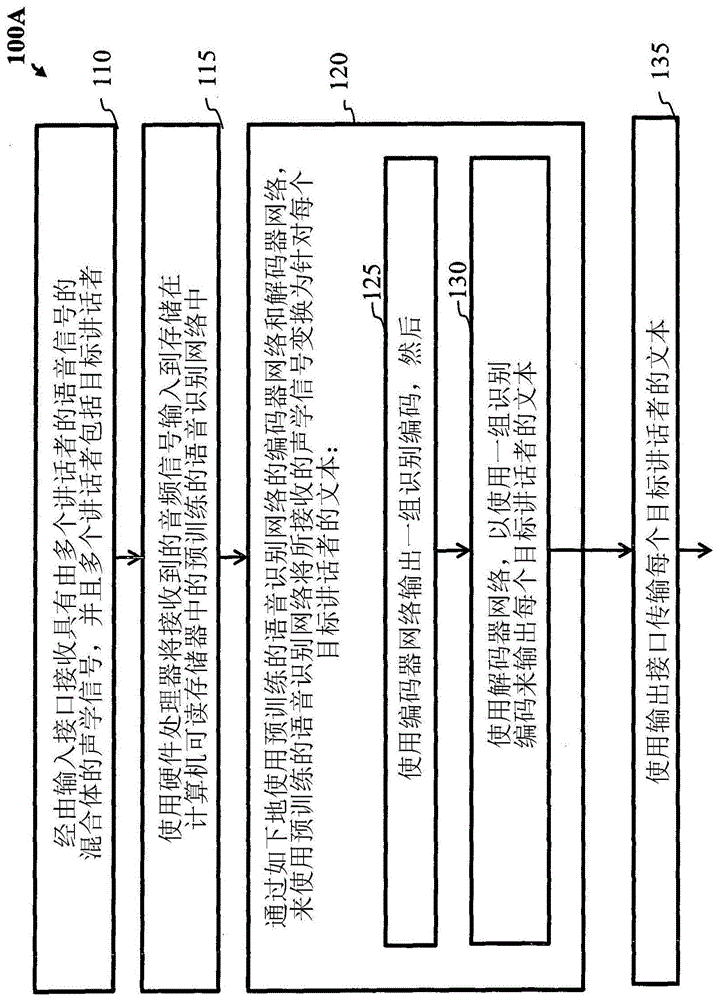
本公开总体上涉及音频信号,并且更具体地,涉及使用一个或更多个麦克风的语音分离和语音识别。
背景技术:
传统语音识别系统受到诸如来自环境的背景噪声以及目标源之外的语音源之类的干扰源的困扰。
例如,在存在许多人并且几个人同时讲话的情况下,来自不同人的语音被混合在所谓的鸡尾酒会效果的单一信号混合体中。人类能够将听觉注意力集中在特定刺激上,同时滤除一系列其它刺激。这通过参会人员能够在嘈杂房间内聚焦于单个会话的方式得到例证。然而,在这种情况下,机器很难转录一个或更多个目标讲话者的语音。
因此,需要对使用一个或更多个麦克风的语音识别进行改进。
技术实现要素:
本公开总体涉及音频信号,并且更具体地,涉及使用一个或更多个麦克风的语音分离和语音识别。
本公开的一些实施方式包括用于交叠语音信号的分离和识别的完全端到端的、联合训练的深度学习系统。联合训练框架能够协同地使分离和识别彼此适应。作为许多益处当中的附加益处是联合训练框架能够在仅包含混合信号及其转录的更真实的数据上进行训练,并且因此能够适于在现有转录数据上的大规模训练。
本公开的一些实施方式包括用于在没有基础语音信号的显式分离的情况下识别交叠语音信号的完全端到端的深度学习系统。与以上用于分离和识别的联合训练的深度学习系统类似,没有显式分离的系统具有许多益处当中的附加益处,该附加益处在于能够在仅包含混合信号及其转录的更真实数据上进行训练,并且因此能够适于在现有转录数据上的大规模培训。
例如,通过实验学习的是与编码器-解码器递归神经网络(rnn)一起使用,以将输入语音特征序列直接转换为输出标签序列,而无需语音/语言构造的任何显式中间表示的端到端自动语音识别(asr)系统。将整个识别系统实现为单片式神经网络能够消除对点对点(ad-hoc)语言资源的依赖。还发现识别系统能够极大地提高判别训练和与其它系统集成的便利性。本公开利用这些特性扩展asr以对多个交叠讲话者进行识别。在多个讲话者的嘈杂声当中识别语音是长期的挑战,被称为技术空间内的鸡尾酒会问题。解决此鸡尾酒会问题将为现实世界中的人机交互(hmi)等提供显著更好的技术。
在这个实验过程中,学习到的是深度聚类能够训练功能强大的深度神经网络,以将每个时频(t-f)单位投影到高维嵌入向量。这样,由同一讲话者主导的t-f单位对的嵌入彼此接近,而由不同讲话者主导的t-f单位对的嵌入相距远。因此,能够通过简单的聚类算法从嵌入推断出每个t-f单位的讲话者指配,以产生隔离每个单个讲话者的掩码。
尝试使用语音分离范例时最初面临的一些挑战是尝试孤立地训练语音分离和语音识别组件,然后在训练后将它们连接在一起。然而,后来获悉,这种方法对于本公开的普通现实世界信号而言并不理想。原因之一在于初始使用的语音分离训练范例依赖于各个来源的信号级真实值(groundtruth)基准。具体而言,在具有混响音响效果的自然录音中,这种信号级基准不可用,并且唯一的另选方案是模拟。因此,难以孤立地训练语音分离系统以在普通现实世界信号上获得最佳性能。另一方面,具有语音的自然声学和转录的数据很容易获得。由此,本公开的至少一个实现的动机是组合两个系统并联合训练它们以用于识别,或者作为另选方案,设计不执行显式分离的单个系统。现在,实施此实现已得到使用深度网络的多个讲话者识别语音的最佳实践。如以上所提及的,已经得到了用于识别交叠语音信号的、完整的端到端的、联合训练的深度学习系统。其中,在联合训练框架中,分离和识别能够协同地彼此适应,从而提高了性能。或者,在没有明确分离的系统中,能够直接优化识别,用于从具有多个交叠讲话者的声学信号中识别语音,从而提高性能。
根据本公开的实施方式,一种语音识别系统用于识别包括多个讲话者的交叠语音的语音。该系统包括硬件处理器。计算机储存存储器存储数据并且存储于其上的计算机可执行指令,该计算机可执行指令在由硬件处理器执行时将实现所存储的语音识别网络。输入接口接收声学信号,所接收的声学信号包括多个讲话者的语音信号的混合体,其中多个讲话者包括目标讲话者。所存储的语音识别网络的编码器网络和解码器网络被训练为将所接收的声学信号变换为每个目标讲话者的文本。使得编码器网络输出一组识别编码,并且解码器网络使用一组识别编码以输出每个目标讲话者的文本。输出接口传输每个目标讲话者的文本。
根据本公开的另一实施方式,一种语音识别系统用于识别包括多个讲话者的交叠语音的语音。该系统包括硬件处理器。计算机储存存储器存储数据并且具有存储于其上的计算机可执行指令,该计算机可执行指令在由处理器执行时将实现所存储的语音识别网络。输入接口接收声学信号,所接收的声学信号包括多个讲话者的语音信号的混合体,其中,多个讲话者包括目标讲话者。所存储的语音识别网络的编码器网络和解码器网络被训练为将所接收的声学信号变换为每个目标讲话者的文本。使得编码器网络输出一组识别编码,并且解码器网络使用一组识别编码,以输出每个目标讲话者的文本。其中,编码器网络还包括混合体编码器网络、一组讲话者差异化编码器网络和识别编码器网络。输出接口传输每个目标讲话者的文本。
根据本公开的另一实施方式,一种使用语音识别系统来识别具有多个讲话者的交叠语音的音频信号中的各个讲话者信号的方法。该方法包括:经由输入接口接收包括多个讲话者的语音信号的混合体的声学信号,其中多个讲话者包括目标讲话者。使用硬件处理器将所接收的音频信号输入到存储在计算机可读存储器中的预训练的语音识别网络中。其中,预训练的语音识别网络被配置为使用预训练的语音识别网络的编码器网络和解码器网络,通过使用编码器网络输出一组识别编码,并且解码器网络使用一组识别编码以输出每个目标讲话者的文本,来将所接收的声学信号变换为每个目标讲话者的文本。使用输出接口传输每个目标讲话者的文本。
附图说明
[图1a]
图1a是例示了根据本公开的实施方式的用于实现方法的一些方法步骤的流程图。
[图1b]
图1b是例示了根据本公开的实施方式的能够用于实现系统和方法的一些组件的框图。
[图1c]
图1c是例示了根据本公开的实施方式的同时讲话的多个讲话者的语音的端到端识别的框图。
[图1d]
图1d是例示了根据本公开的实施方式的包括被预先训练的语音识别网络(也称为编码器-解码器网络)的、同时讲话的多个讲话者的语音的端到端识别的框图,其中,编码器-解码器网络包括编码器网络和解码器网络,其中,编码器网络输出由解码器网络输出每个讲话者的文本的一组识别编码。
[图2]
图2是例示了根据本公开的实施方式的包括被预先训练的语音识别网络(也称为编码器-解码器网络)的、同时讲话的多个讲话者的语音的端到端识别的框图,其中,编码器-解码器网络包括编码器网络和解码器网络,其中,编码器网络输出针对每个讲话者的识别编码,并且解码器网络使用针对每个讲话者的识别编码以输出该讲话者的文本。
[图3]
图3是例示了根据本公开的实施方式的包括具有隐式分离的多讲话者asr网络的、同时讲话的多个讲话者的语音的端到端识别的流程图。
[图4]
图4是例示了根据本公开的实施方式的使用包括具有单个讲话者的语音的声学信号和相应的文本标签的数据集训练初始语音识别网络(即,编码器-解码器网络)的流程图,其中,该训练包括误差计算。
[图5]
图5是例示了根据本公开的实施方式的基于使用初始语音识别网络的讲话者差异化编码器网络对一组讲话者差异化编码器网络中的讲话者差异化编码器网络的初始化,来初始化具有使用初始语音识别网络的一组讲话者差异化编码器网络的语音识别网络(即,编码器-解码器网络)的流程图。
[图6]
图6是例示了根据本公开的实施方式的具有同时讲话的多个讲话者的语音的端到端识别的隐式分离的多讲话者asr网络的训练的流程图,其中训练包括误差计算。
[图7]
图7是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、用于同时讲话的多个讲话者的语音的端到端识别的另一方法的流程图。
[图8]
图8是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、用于同时讲话的多个讲话者的语音的端对端识别的另一方法的流程图,其中,多讲话者asr网络包括输出针对每个目标讲话者的分离编码的讲话者分离网络、从针对每个目标讲话者的分离编码输出该目标讲话者的识别编码的声学编码器网络、以及从一组识别编码输出针对每个目标讲话者的文本的解码器网络。
[图9a]
图9a是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、用于同时讲话的多个讲话者的语音的端对端识别的另一方法的流程图,其中,多讲话者asr网络包括输出针对每个目标讲话者的分离编码的讲话者分离网络、从针对每个目标讲话者的分离编码输出针对该目标讲话者的识别编码的声学编码器网络、以及从针对每个目标讲话者的识别编码输出针对该目标讲话者的文本的解码器网络。
[图9b]
图9b是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、同时讲话的多个讲话者的语音的端到端识别的流程图,其中显式分离涉及掩码推断。
[图10]
图10是例示了根据本公开的实施方式的同时讲话的多个讲话者的语音的端到端分离和识别的流程图。
[图11a]
图11a是例示了根据本公开的实施方式的单通道掩码推断网络架构的框图。
[图11b]
图11b是例示了根据本公开的实施方式的单通道深度聚类网络架构的框图。
[图11c]
图11c是例示了根据本公开的实施方式的单通道嵌合网络结构的框图。
[图12]
图12是例示了根据本公开的实施方式的用于同时讲话的多个讲话者的语音的端到端识别的、具有显式分离的多讲话者asr网络的训练的流程图,其中训练包括误差计算。
[图13]
图13是例示了根据本公开的实施方式的以多种语言同时讲话的多个讲话者的语音的端到端识别的示意图。
[图14]
图14是例示了根据本发明的实施方式的使用混合ctc/注意力端到端网络的语音识别模块的框图。
[图15]
图15是例示了根据本公开的实施方式的混合ctc/注意力语音识别模块中的神经网络的框图。
[图16]
图16是例示了根据本公开的实施方式的多语言语音识别模块中的神经网络的示意图。
[图17a]
图17a示出了根据本公开的一些实施方式的用于语音识别的替代语音识别系统的框图,具体而言,图17a包括语音识别网络,即,编码器-解码器网络。
[图17b]
图17b示出了根据本公开的一些实施方式的用于语音识别的替代语音识别系统的框图,具体而言,图17b包括语音分离网络以及基于混合ctc/注意力的语音识别asr网络。
[图18a]
图18a是例示了根据本公开的实施方式的能够用于实现方法和系统的一些技术的计算设备的示意图。
[图18b]
图18b是例示了根据本公开的实施方式的能够用于实现方法和系统的一些技术的移动计算设备的示意图。
具体实施方式
尽管以上面标识的附图阐述了当前公开的实施方式,但是如讨论中所指出的,其它实施方式也是可以预期的。本公开通过代表而非限制的方式呈现了示例性实施方式。本领域技术人员能够设计出落入当前公开的实施方式的原理的范围和精神内的许多其它修改和实施方式。
(总览)
本公开涉及使用一个或更多个麦克风的语音分离和语音识别。
本公开的一些实施方式包括用于分离和识别交叠的语音信号的完全端到端的联合训练的深度学习系统。联合训练框架能够协同地使分离和识别彼此适应。作为许多益处当中的附加益处,联合训练框架还能够在仅包含混合信号及其转录的更真实数据上进行训练,因此能够适合于在现有转录数据上进行大规模训练。
本公开的一些实施方式包括在没有显式分离的情况下用于识别交叠的语音信号的完全端到端深度学习系统。与用于分离和识别的以上联合训练的深度学习系统类似,没有显式分离的系统具有许多益处当中的附加益处,那就是它能够在仅包含混合信号及其转录的更真实数据上进行训练,因此能够适合于在现有转录数据上进行大规模训练。
例如,通过实验了解到的是:与编码器-解码器递归神经网络(rnn)一起使用以将输入语音特征序列直接转换为输出标签序列,而无需语音/语言构造的任何显式中间表示的端到端自动语音识别(asr)系统。将整个识别系统实现为单片式神经网络能够消除对点对点(ad-hoc)语言资源的依赖。还发现识别系统能够极大地提高判别训练和与其它系统集成的便利性。本公开利用这些特性来将asr扩展到对多个交叠讲话者的识别。在多个讲话者的嘈杂声当中识别语音是一个长期的挑战,被称为技术空间内的鸡尾酒会问题(cocktailpartyproblem)。解决此鸡尾酒会问题将为现实世界中的人机交互(hmi)等提供明显更好的技术。
图1a是例示了根据本公开的实施方式的用于实现方法的一些方法步骤的流程图。例如,使用语音识别系统来在具有多个讲话者的交叠语音的音频信号内识别单独的讲话者信号的方法100a。方法100a能够在客户端装置或一些其它装置上执行。
方法100a的步骤110能够包括接收具有多个讲话者的语音信号的混合体的声学信号。例如,声学信号能够包括在形成声学信号的单个麦克风处能够捕获的来自同时讲话的多个讲话者的语音。通过非限制性示例,与每个讲话者相关联的信号的一个方面能够是大致相同的音量水平,使得多个讲话者能够在距麦克风相同距离处以大约相同的音量讲话。
图1a的步骤115包括使用硬件处理器将接收到的音频信号输入到存储在计算机可读存储器中的预训练的语音识别网络中。其中,预训练的语音识别网络被配置为使用预训练的语音识别网络的编码器网络和解码器网络,将接收到的声学信号转换为每个目标讲话者的文本。想到的是能够依据特定应用来使用多个硬件处理器。如以上所提及的,一些实施方式能够包括用于分离和识别交叠的语音信号的完全端到端的联合训练的深度学习系统。联合训练框架能够协同地使分离和识别彼此适应。作为许多益处当中的附加益处,联合训练框架能够在仅包含混合信号及其转录的更真实的数据上进行训练,并因此能够适合于在现有转录数据上进行大规模训练。
图1a的步骤120包括硬件处理器使用预训练的语音识别网络,利用预训练的语音识别网络的编码器网络和解码器网络将接收到的声学信号转换为每个目标讲话者的文本。
图1a的步骤125包括使用编码器网络输出一组识别编码。
图1a的步骤130包括使用解码器网络输出每个目标讲话者的文本,该解码器网络使用一组识别编码。
图1a的步骤135包括使用输出接口传输每个目标讲话者的文本。
图1b是例示了根据本公开的实施方式的能够用于实现系统和方法的一些组件的框图。例如,方法100b可以包括与收集来自环境1的包括声学信号8的数据的、诸如声学传感器之类的传感器2或多个传感器通信的硬件处理器11。声学信号包括具有交叠的语音的多个讲话者。此外,传感器2能够将声学输入转换为声学信号。硬件处理器11与计算机储存存储器(即,存储器9)通信,使得存储器9包括能够由硬件处理器11实施的包括算法、指令和其它数据的存储数据。
可选地,硬件处理器11能够连接到与数据源3、计算机装置4、移动电话装置5和储存装置6通信的网络7。另外可选地,硬件处理器11能够连接到与客户端装置15连接的网络使能的服务器13。硬件处理器11能够可选地连接到外部存储器装置17、发送器19。此外,能够根据特定用户打算的用途21而输出每个目标讲话者的文本,例如,一些类型的用户用途能够包括在诸如监视器或屏幕之类的一个或更多个显示装置上显示文本,或将每个目标讲话者的文本输入计算机相关装置,以用于进一步分析等。
可以设想,硬件处理器11能够依据特定应用的要求而包括两个或更多个硬件处理器,其中处理器能够是内部的或外部的。当然,包括输出接口和收发器以及其它装置的其它组件可以与方法100b合并。
作为非限制性示例,网络7能够包括一个或更多个局域网(lan)和/或广域网(wan)也是可以的。其中,网络环境能够类似于企业范围的计算机网络、内联网和互联网。对于所提到的全部组件,设想到可以是任何数量的客户端装置、储存组件以及系统100b内所采用的数据源。每个可以包括单个装置或在分布式环境中协作的多个装置。此外,系统100b能够包括一个或更多个数据源3。数据源3包括用于训练语音识别网络的数据资源。由数据源3提供的数据可以包括带标签的数据和未带标签的数据,诸如转录数据和非转录数据。例如,在实施方式中,数据包括一个或更多个声音,并且还可以包括可用于初始化语音识别网络的相应转录信息或标签。训练数据能够包括多个讲话者同时讲话的声学信号。训练数据还能够包括单个讲话者单独讲话的声学信号,在嘈杂环境中讲话的单个或多个讲话者的声学信号以及嘈杂环境中的声学信号。
此外,数据源3中未带标签的数据能够由一个或更多个反馈环路提供。例如,来自在搜索引擎上执行的所讲的搜索查询的使用数据能够作为未转录数据而提供。数据源的其它示例可以包括例如但不限于各种口头语言的音频或图像源,其包括流声音或视频、网络查询、移动装置相机或音频信息、网络摄像头馈送(webcamfeeds)、智能眼镜和智能手表馈送、客户服务系统、安全摄像机馈送、网络文档、目录、用户馈送、sms日志、即时消息日志、所讲单词的转录、游戏系统用户交互(诸如语音命令或捕获的图像(例如,深度相机图像))、推文、聊天或视频通话记录或社交网络媒体。可以基于包括数据是否是某一类型的数据(例如,仅与特定类型的声音有关的数据,例如,包括机器系统、娱乐系统的数据)或性质上是通用的(非类型特定的)数据的应用,来确定所使用的特定数据源3。
系统100b能够包括第三方装置4、5,其能够包括任何类型的计算装置,使得可以对计算装置上具有自动语音识别(asr)系统感兴趣。例如,在此,包括诸如与图18a有关描述的类型的计算装置之类的计算机装置4的第三方装置、或者诸如与图18b有关描述的类型的移动计算装置之类的移动装置5。可以设想的是,用户装置可以体现为个人数据助理(pda)、移动装置、诸如智能电话、智能手表、智能眼镜(或其它可穿戴智能装置)、增强实现耳机、虚拟实现耳机。此外,用户装置可以是膝上型计算机,诸如平板电脑、遥控器、娱乐系统、车辆计算机系统、嵌入式系统控制器、电器、家用计算机系统、安全系统、消费电子装置或其它类似的电子装置。在一个实施方式中,客户端装置能够接收输入数据,诸如在装置上运行的本文所描述的asr系统可用的音频和图像信息。例如,第三方装置可以具有用于接收音频信息的麦克风或线路输入、用于接收视频或图像信息的相机、或用于从诸如互联网或数据源3之类的另一源接收这种信息的通信组件(例如,wi-fi功能)。
使用语音识别网络的asr模型能够处理所输入的数据,以确定计算机可用信息。例如,可以处理当房间中的多个人正在讲话时由用户向麦克风所说的查询,以确定该查询的内容,例如,是否提出了问题。示例性第三方装置4、5可选地包括在系统100b中,以例示可以部署深度神经网络模型的环境。此外,本公开的一些实施方式可以不包括第三方装置4、5。例如,深度神经网络模型能够在服务器上或在云网络、系统或类似布置中。
关于储存器6,储存器6能够存储包括在本文中描述的技术的实施方式中所使用的数据、计算机指令(例如,软件程序指令、例程或服务)和/或模型的信息。例如,储存器6能够存储来自一个或更多个数据源3的数据、一个或更多个深度神经网络模型、用于生成和训练深度神经网络模型的信息、以及由一个或更多个深度神经网络模型所输出的计算机可用信息。
图1c是例示了根据本公开的实施方式的同时讲话的多个讲话者的语音的端到端识别的框图。图1c例示了如权利要求1中所描述的一些特征。语音识别网络(即,编码器-解码器网络)143使用所存储的网络参数141处理使用传感器2从环境1所记录的声学信号8,以输出每个目标讲话者的文本,对于有c个目标讲话者的情况,输出文本1145至文本c147。
图1d是例示了根据本公开的实施方式的包括语音识别网络(即,编码器-解码器网络)的、同时讲话的多个讲话者的语音的端到端识别的框图,其中,编码器-解码器网络包括编码器网络和解码器网络,其中编码器网络输出由解码器网络使用的一组识别编码,以输出每个讲话者的文本。图1d例示了如权利要求1中所描述的一些特征。图1c的编码器-解码器网络143通过使用编码器网络146来处理声学信号8以输出一组识别编码148,该识别编码148进一步被解码器网络150处理以输出每个目标讲话者的文本,针对有c个目标讲话者的情况,输出文本1145至文本c147。在一些实施方式中,编码器146包括特征提取器(未示出),该特征提取器被配置为从声学信号8提取声学特征序列,以供编码器-解码器网络使用。特征提取器是可微函数,因此能够连接到单个编码器-解码器网络。可微函数的示例包括通道信号的幅度的mel(梅尔)函数和通道信号的幅度的bark函数。
图2是例示了根据本公开的实施方式的、包括语音识别网络(即,编码器-解码器网络)的、同时讲话的多个讲话者的语音的端到端识别的框图,其中,编码器-解码器网络包括编码器网络和解码器网络,其中编码器网络输出针对每个讲话者的识别编码,并且解码器网络使用针对每个讲话者的识别编码以输出该讲话者的文本。
仍然参照图2,图2例示了权利要求2中所描述的一些特征。语音识别网络(即,编码器-解码器网络)243通过使用编码器网络240来处理声学信号8,以输出针对每个讲话者的识别编码,对于有c个目标讲话者的情况,输出从针对讲话者1的识别编码248到针对讲话者c的识别编码259。由解码器网络250分别处理每个识别编码,以输出相应目标讲话者的文本。具体地,由解码器网络250处理针对讲话者1的识别编码248以输出文本1245,并且由解码器网络250处理针对讲话者c的识别编码249以输出文本c147。编码器网络240和解码器网络250使用所存储的网络参数241。
图3是例示了根据本公开的实施方式的包括具有隐式分离的多讲话者asr网络的、同时讲话的多个讲话者的语音的端到端识别的流程图。图3例示了如权利要求3所描述的一些特征。输入混合体308由混合体编码器310处理成混合体编码。该图使用两个目标讲话者的情况作为示例说明了概念。混合体编码进一步由讲话者差异化编码器1312和讲话者差异化编码器2322分别处理,得到讲话者差异化编码。每个讲话者差异化编码分别由识别编码器314进一步处理,各自得到识别编码。每个识别编码分别由解码器网络350的ctc模块316和注意力解码器318二者进一步处理。针对以讲话者差异化编码器1312开始的流水线的ctc模块316和注意力解码器318的输出被组合,以输出一组假设1320,并且针对以讲话者差异化编码器2322开始的流水线的ctc模块316和注意力解码器318的输出被组合,以输出一组假设2330。从一组假设1320输出文本1345。从一组假设2330输出文本2347。
图4是例示了根据本公开的实施方式的使用包括具有单个讲话者的语音的声学信号和相应文本标签的数据集训练初始语音识别网络(即,编码器-解码器网络)的流程图,其中,该训练包括误差计算。图4例示了权利要求4中所描述的一些特征。从数据集406采样具有单个讲话者语音的输入信号408和相应的基准标签432。混合体编码器410处理具有单个讲话者语音的输入信号408,输出混合体编码。然后由讲话者差异化编码器1412处理混合体编码,输出讲话者差异化编码。然后由识别编码器414处理讲话者差异化编码,输出识别编码。识别编码进一步由解码器网络450的ctc模块416和注意力解码器418处理。误差计算模块430使用ctc模块416的输出和基准标签432来计算ctc损失,并使用注意力解码器418的输出和基准标签432来计算注意力损失。ctc损失
图5是例示了根据本公开的实施方式的基于使用初始语音识别网络的讲话者差异化编码器网络对一组讲话者差异化编码器网络中的讲话者差异化编码器网络进行的初始化,来初始化包括使用初始语音识别网络的一组讲话者差异化编码器网络的语音识别网络(即,编码器-解码器网络)的流程图。语音识别网络511的讲话者差异化编码器2522的参数能够从图4的讲话者差异化编码器1412通过复制其参数(可选地例如使用随机扰动对参数进行扰动)来获得。能够使用图4的相应组件的参数来初始化语音识别网络511的全部其它参数。在这种初始化之后,然后可以如图3中那样处理输入混合体508。
图6是例示了根据本公开的实施方式的用于同时讲话的多个讲话者的语音的端到端识别的、具有隐式分离的多讲话者asr网络的训练的流程图,其中训练包括误差计算。从数据集606中采样输入混合体608和相应的基准标签632。混合体编码器610处理输入混合体608,输出混合体编码。混合体编码进一步由讲话者差异化编码器1612和讲话者差异化编码器2622分别处理,得到讲话者差异化编码。每个讲话者差异化编码进一步由识别编码器614分别处理,各自得到识别编码。每个识别编码分别由解码器网络650的ctc模块616和注意力解码器618二者进一步处理。误差计算模块630使用ctc模块616的输出和基准标签632二者来计算ctc损失
图7是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、用于同时讲话的多个讲话者的语音的端到端识别的另一种方法的流程图。编码器-解码器网络743通过使用编码器网络740处理声学信号8,以输出一组识别编码748,一组识别编码748进一步由解码器网络750处理,以输出每个目标讲话者的文本,对于有c个目标讲话者的情况,输出文本1745至文本c747。编码器网络740包括:讲话者分离网络742,其处理声学信号8以输出一组分离编码747;以及声学编码器网络746,其处理一组分离编码747以输出一组识别编码748。网络参数841指定讲话者分离网络742、声学编码器网络746和解码器网络750的参数。
图8是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、用于同时讲话的多个讲话者的语音的端对端识别的另一方法的流程图,其中,多讲话者asr网络包括输出针对每个目标讲话者的分离编码的讲话者分离网络、根据每个目标讲话者的分离编码输出针对该目标讲话者的识别编码的声学编码器网络、以及根据一组识别编码输出每个目标讲话者的文本的解码器网络。编码器网络840处理声学信号8以输出一组识别编码848,一组识别编码848进一步由解码器网络850处理以输出每个目标讲话者的文本,对于存在c个目标讲话者的情况,输出文本1845至文本c847。编码器网络840包括讲话者分离网络842和声学编码器网络746。讲话者分离网络842处理声学信号8以输出每个目标讲话者的分离编码,即,分离编码1843至分离编码c844。声学编码器网络846分别处理每个分离编码以输出相应识别编码,其中分离编码1843由声学编码器网络746处理以输出识别编码1853,而分离编码c844由声学编码器网络846处理以输出识别编码c854。一组识别编码848包括识别编码1853至识别编码c854。网络参数841指定讲话者分离网络842、声学编码器网络846和解码器网络850的参数。分离编码能够是例如但不限于在已经孤立地观察了语音的情况下,与相应目标讲话者的语音的估计相对应的特征向量序列的形式。
图9a是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、用于同时讲话的多个讲话者的语音的端对端识别的另一方法的流程图,其中,多讲话者asr网络包括输出针对每个目标讲话者的分离编码的讲话者分离网络、根据针对每个目标讲话者的分离编码输出针对该目标讲话者的识别编码的声学编码器网络、以及根据针对每个目标讲话者的识别编码输出该目标讲话者的文本的解码器网络。编码器网络940包括讲话者分离网络942和声学编码器网络946。讲话者分离网络942处理声学信号8,以输出针对每个目标讲话者的分离编码,对于有c目标讲话者的情况,输出分离编码1943至分离编码c944。声学编码器网络946分别处理每个分离编码以输出相应识别编码,其中分离编码1943由声学编码器网络946处理以输出识别编码1953,而分离编码c944由声学编码器网络946处理以输出识别编码c954。识别编码各自进一步由解码器网络950分别处理,以输出每个目标讲话者的文本,其中识别编码1953由解码器网络950处理以输出文本1945,而识别编码c954由解码器网络950进行处理以输出文本c947。网络参数941指定了讲话者分离网络942、声学编码器网络946和解码器网络950的参数。
图9b是例示了根据本公开的实施方式的包括具有显式分离的多讲话者asr网络的、同时讲话的多个讲话者的语音的端到端识别的流程图,其中显式分离涉及掩码推断。该图使用两个目标讲话者的情况作为示例说明了概念。输入混合体908由讲话者分离网络942处理,以输出针对每个目标讲话者的分离编码。
讲话者分离网络942包括混合体编码器910、掩码推断模块912和分离编码估计模块913。混合体编码器910处理输入混合体908以输出混合体编码。混合体编码进一步由掩码推断模块912处理,该掩码推断模块912估计一组掩码。一组掩码与输入混合体一起由分离编码估计模块913使用,以获得针对每个目标讲话者的分离编码。例如,掩码推断模块912能够输出针对每个目标讲话者的掩码,并且分离编码估计模块能够将针对目标讲话者的掩码应用于输入混合体的表示,以获得针对该目标讲话者的分离信号的估计的表示。该表示例如能够是输入混合体的诸如短时傅立叶变换之类的时频表示,在这种情况下,掩码被应用于输入混合体的短时傅立叶变换,以获得针对该目标讲话者的分离信号的短时傅立叶变换的估计,该估计是在该目标讲话者的孤立信号是孤立地观察到的情况下该目标讲话者已经具有的孤立信号的短时傅立叶变换的估计。每个分离编码由声学编码器946分别进一步处理,各自得到识别编码。
仍然参照图9b,每个识别编码分别由ctc模块916和注意力解码器918二者进一步处理。ctc模块916和注意力解码器918的输出被组合,以输出用于采用针对第一目标讲话者的分离编码1作为输入的流水线的一组假设1920,以及用于从针对第二目标讲话者的分离编码2作为输入而开始的流水线的一组假设2930。从一组假设1920输出文本1945。从一组假设2930输出文本2947。
图10是例示了根据本公开的实施方式的同时讲话的多个讲话者的语音的端到端分离和识别的流程图。编码器-解码器网络1043通过使用编码器网络1040处理声学信号8,以输出一组识别编码1048,一组识别编码1048进一步由解码器网络1050处理,以输出每个目标讲话者的文本,针对有c个目标讲话者的情况,输出文本11045至文本c1047。编码器网络1040包括处理声学信号8以输出一组分离编码1047的讲话者分离网络1042、以及处理一组分离编码1047以输出一组识别编码1048的声学编码器网络1046。网络参数1041指定讲话者分离网络1042、声学编码器网络1046和解码器网络1050的参数。一组分离编码1047能够与声学信号8一起由信号重构模块1051使用,以输出针对每个目标讲话者的分离信号的估计,即,信号11055至信号c1057。估计出的分离信号是在该讲话者的信号已经被孤立地观察的情况下该讲话者已经具有的那些信号的估计。例如,讲话者分离网络1042能够以针对每个目标讲话者在幅度短时傅立叶变换域中的估计的幅度谱图的形式输出一组分离编码1047。针对每个目标讲话者的幅度谱图能够与声学信号8的相位组合,以获得针对每个目标讲话者的估计的复数谱图,从该估计的复数谱图,能够通过短时傅立叶逆变换重构时域信号。
图11a是例示了根据本公开的实施方式的单通道掩码推断网络架构的框图。从输入混合体获得的特征向量序列(例如,输入混合体的短时傅立叶变换的对数幅度)用作混合体编码器1110的输入。例如,序列中输入向量的维数能够是f。混合体编码器1110由从第一双向长短期记忆(blstm)层1130到最后一个blstm层1135的多个blstm神经网络层组成。每个blstm层由前向长期短期记忆(lstm)层和后向lstm层组成,它们的输出被组合并用作下一层的输入。例如,第一blstm层1130中的每个lstm的输出的维度能够为n,并且包括最后一个blstm层1135的所有其它blstm层中的每个lstm的输入维度和输出维度二者能够为n。最后一个blstm层1135的输出用作包括线性神经网络层1140和非线性1145的掩码推断模块1112的输入。对于时频域(例如,短时傅立叶变换域)中的每个时间帧和每个频率,线性层1140使用最后一个blstm层1135的输出来输出c个数字,其中c是目标讲话者的数量。非线性1145被应用于针对每个时间帧和每个频率的该组c个数字,得到掩码值,该掩码值针对每个时间帧、每个频率和每个目标讲话者指示在该时间帧和该频率处在输入混合体中该目标讲话者的主导程度。来自掩码模块的分离编码估计1113将这些掩码与输入混合体在已经针对其估计了掩码的时频域(例如,幅度短时傅立叶变换域)中的表示一起使用,以输出针对每个目标讲话者的分离编码。例如,来自掩码模块的分离编码估计1113能够将针对目标讲话者的掩码与输入混合体的幅度短时傅立叶变换相乘,以获得在已经孤立地观察了讲话者的分离信号的情况下针对该目标讲话者的分离信号的幅度短时傅立叶变换的估计,其被用作该目标讲话者的分离编码。
图11b是例示了根据本公开的实施方式的单通道深度聚类网络架构的框图。从输入混合体获得的特征向量序列(例如,输入混合体的短时傅立叶变换的对数幅度)用作混合体编码器1120的输入。例如,序列中输入向量的维度能够是f。混合体编码器1120由从第一双向长短期记忆(blstm)层1101到最后一个blstm层1103的多个blstm神经网络层组成。每个blstm层由前向长短期记忆(lstm)层和后向lstm层组成,它们的输出被组合并用作下一层的输入。例如,第一blstm层1101中的每个lstm的输出维度能够为n,并且包括最后一个blstm层1103的所有其它blstm层中的每个lstm的输入维度和输出维度二者能够为n。最后一个blstm层1103用作嵌入计算模块1122的输入,该嵌入计算模块1122包括线性神经网络层1105和实现s形非线性并随后进行单位范数归一化的模块1107。对于时频域(例如,短时傅立叶变换域)中的每个时间帧和每个频率,线性层1105使用最后一个blstm层1103的输出来输出d维向量,其中d是嵌入维度。实现s形非线性并随后进行单位范数归一化的模块1107向d维向量的每个元素应用s形,并将其重新归一化,使其具有单位欧几里得范数,得到针对每个时间帧和频率的嵌入向量。来自嵌入的分离编码估计模块1123将这些嵌入向量与输入混合体在对其估计了嵌入的时频域(例如,幅度短时傅立叶变换域)中的表示一起使用,以输出针对每个目标讲话者的分离编码。例如,来自嵌入的分离编码估计模块1123能够使用诸如k-均值算法之类的聚类算法,以将嵌入向量聚类为c个组,其中c是目标讲话者的数量,并且每个组对应于由相同讲话者主导的时间和频率分量。能够针对每个讲话者获取二进制掩码,该二进行制掩码指示时间和频率分量是否由该讲话者主导。然后,来自嵌入的分离编码估计模块1123能够将目标讲话者的掩码与输入混合体的幅度短时傅里叶变换相乘,以获得在已经孤立地观察了该目标讲话者的分离信号的情况下针对该目标讲话者的分离信号的幅度短时傅里叶变换的估计,其被用作针对该目标讲话者的分离编码。还能够考虑更精细复杂的方案来使用来自嵌入的分离编码估计模块1123获得这种掩码,并且以上描述不应被视为以任何方式进行限制。
图11c是例示了根据本公开的实施方式的单通道嵌合网络结构的框图。从输入混合体获得的特征向量序列(例如,输入混合体的短时傅立叶变换的对数幅度)用作混合体编码器1150的输入。例如,序列中输入向量的维度能够是f。混合体编码器1150由从第一双向长短期记忆(blstm)层1171到最后一个blstm层1173的多个blstm神经网络层组成。每个blstm层由前向长短期记忆(lstm)层和后向lstm层组成,它们的输出被组合并用作下一层的输入。例如,第一blstm层1171中的每个lstm的输出维度能够为n,并且包括最后一个blstm层1103的所有其它blstm层中的每个lstm的输入维度和输出维度二者能够为n。
最后一个blstm层1173的输出用作包括线性神经网络层1175和非线性1177的掩码推断模块1152的输入。对于时频域(例如,短时傅立叶变换域)中的每个时间帧和每个频率,线性层1175使用最后一个blstm层1173的输出来输出c个数字,其中c是目标讲话者的数量。非线性1177被应用于针对每个时间帧和每个频率的这组c个数字,得到掩码值,该掩码值针对每个时间帧、每个频率和每个目标讲话者指示在该时间帧和该频率处输入混合体中该目标讲话者的主导程度。来自掩码的分离编码估计模块1153将这些掩码与输入混合体在对其估计了掩码的时频域(例如,幅度短时傅立叶变换域)中的表示一起使用,以输出针对每个掩码的分离编码。例如,来自掩码的分离编码估计模块1153能够将针对目标讲话者的掩码与输入混合体的幅度短时傅里叶变换相乘,以获得在已经孤立地观察了该目标讲话者的分离信号的情况下针对对该目标讲话者的分离信号的幅度短时傅里叶变换的估计,其被用作针对该目标讲话者的分离编码。
最后一个blstm层1173的输出还能够用作嵌入计算模块1162的输入,该嵌入计算模块1162包括线性神经网络层1185和实现s形非线性并随后进行单位范数归一化的模块1187。对于时频域(例如,短时傅立叶变换域)中的每个时间帧和每个频率,线性层1185使用最后一个blstm层1173的输出来输出d维向量,其中d是嵌入维度。实现s形非线性并随后进行单位范数归一化的模块1187向d维向量的每个元素应用s形,并将其重新归一化,使其具有单位欧几里得范数,得到针对每个时间帧和频率的嵌入向量。来自嵌入的分离编码估计模块1163将这些嵌入向量连同输入混合体在对其估计了嵌入的时频域(例如,幅度短时傅立叶变换域)中的表示一起使用,以输出针对每个目标讲话者的分离编码。例如,来自嵌入的分离编码估计模块1163能够使用诸如k-均值算法之类的聚类算法将嵌入向量聚类为c个组,其中c是目标讲话者的数量,并且每个组对应于由相同讲话者主导的时间和频率分量。针对每个讲话者能够获得二进制掩码,该二进制掩码指示时间和频率分量是否由那个讲话者主导。然后,来自嵌入的分离编码估计模块1163能够将目标讲话者的掩码与输入混合体的幅度短时傅里叶变换相乘,以获得在已经孤立地观察了目标讲话者的分离信号的情况下针对该目标讲话者的分离信号的幅度短时傅里叶变换的估计,其被用作针对该目标讲话者的分离编码。
在训练时,最后一个blstm层1173的输出既用作掩码推断模块1152的输入,又用作嵌入计算模块1162的输入。能够使用由嵌入计算模块1162输出的嵌入、由掩码推断模块1152输出的掩码、由来自嵌入的编码估计模块1163输出的分离编码、以及由来自掩码的编码估计模块1153输出的分离编码中的一个或更多个来计算训练误差,如图12所示。在测试时,也能够同时使用两个模块并组合从每个模块获得的分离编码,或者能够选择以仅使用一个模块进行并使用相应的分离编码。
图12是例示了根据本公开的实施方式的用于同时讲话的多个讲话者的语音的端到端识别的、具有显示分离的多讲话者asr网络的训练的流程图,其中训练包括误差计算。该图使用两个目标讲话者的情况作为示例来说明概念。具有显式分离的多讲话者语音识别网络1211包括编码器网络1240和解码器网络1250。编码器网络1240包括讲话者分离网络1242和声学编码器网络1246。从数据集1206采样输入混合体1208及相应的基准标签1232和基准源信号1234。基准源信号对应于输入混合体1208中的与孤立地观察的每个目标讲话者相对应的部分。输入混合体1208由讲话者分离网络1242处理以输出针对每个目标讲话者的分离编码。讲话者分离网络1242包括混合体编码器1210、掩码推断模块1212、来自掩码的分离编码估计模块1213、嵌入计算模块1222以及可选地来自嵌入的分离编码估计模块1223。
混合体编码器1210处理输入混合体1208以输出混合体编码。混合体编码进一步由估计一组掩码的掩码推断模块1212处理。这一组掩码与输入混合体一起被来自掩码的分离编码估计模块1213使用,以获得针对每个目标讲话者的分离编码。例如,掩码推断模块1212能够输出针对每个目标讲话者的掩码,并且来自掩码的分离编码估计模块能够将针对目标讲话者的掩码应用于输入混合体的表示,以获得针对该目标讲话者的分离信号的估计的表示,其被用作针对该目标讲话者的分离编码。该表示例如能够是输入混合体的诸如短时傅立叶变换之类的时频表示,在这种情况下,掩码应用于输入混合体的短时傅立叶变换,以获得针对该目标讲话者的分离信号的短时傅立叶变换的估计,该估计是在已经孤立地观察了该目标讲话者的孤立信号的情况下该目标讲话者已经具有的孤立信号的短时傅立叶变换的估计。
混合体编码还由估计一组嵌入的嵌入计算模块1222进一步处理。来自嵌入的分离编码估计模块1223能够将这些嵌入向量与输入混合体1208一起使用,以输出另一组分离编码。
这些来自嵌入的分离编码能够与来自掩码的分离编码组合,以获得组合的分离编码,或者能够代替来自掩码的分离编码而被使用,以用作对声学编码器网络1246和后续步骤的输入。每个分离编码分别由声学编码器1246进一步处理,各自得到识别编码。每个识别编码分别由ctc模块1216和注意力解码器1218二者进一步处理。误差计算模块1230使用ctc模块1216的输出和基准标签1232二者来计算ctc损失
图13是例示了根据本公开的实施方式的、同时以多种语言讲话的多个讲话者的语音的端到端识别的示意图。语音混合体1305包括多个讲话者(例如,两个讲话者)的语音,其中话语11306是讲话者1讲出的话语,具有日语的第一部分1307和英语的第二部分1308;话语21309是由讲话者2以汉语讲出的话语。语音混合体1305由两个编码器网络编码器11310和编码器21315处理,输出编码11311和编码21316。编码11311和编码21316由分别为解码器11320和解码器21325的解码器网络分开处理,得到讲话者1的文本(例如,日语然后英语)以及讲话者2的文本(例如,汉语)。由系统来确定解码器11320输出的文本是否对应于话语11306,以及解码器21325输出的文本是否对应于话语21309,反之亦然。
图14是例示了根据本公开的实施方式的使用混合ctc/注意力端到端网络的语音识别模块的框图。
端到端语音识别模块1400包括编码器网络模块1402、编码器网络参数1403、包括注意力解码器模块1404和ctc模块1408的解码器网络、注意力解码器网络参数1405、ctc网络参数1409、以及标签序列搜索模块1406。编码器网络参数1403、注意力解码器网络参数1405和ctc网络参数1409分别存储在储存装置中,以向相应模块1402、1404和1408提供参数。
编码器网络模块1402包括使用来自编码器网络参数1403的编码器网络读取参数将声学信号1401转换为隐藏向量序列的编码器网络。在一些实施方式中,编码器网络模块1402包括被配置为从声学信号中提取声学特征序列,以供编码器网络进一步处理的特征提取器(未示出)。特征提取器是可微函数并且因此能够连接到单个端到端神经网络。可微函数的示例包括通道信号的幅度的mel函数和通道信号的幅度的bark函数。
仍然参照图14,以下描述使用注意力解码器网络1404的注意力机制。注意力解码器网络模块1404包括注意力解码器网络。注意力解码器网络模块1404从编码器网络模块1402接收隐藏向量序列,并从标签序列搜索模块1406接收先前标签,然后使用来自注意力解码器网络参数1405的解码器网络读取参数,计算该先前标签的下一标签的第一后验概率分布。注意力解码器网络模块1404向标签序列搜索模块1406提供第一后验概率分布。ctc模块1408从编码器网络模块1402接收隐藏向量序列,并从标签序列搜索模块1406接收先前标签,并使用ctc网络参数1409和动态编程技术来计算下一标签序列的第二后验概率分布。在计算之后,ctc模块1408向标签序列搜索模块1406提供第二后验概率分布。
标签序列搜索模块1406使用从注意力解码器网络模块1404和ctc模块1408提供的第一后验概率分布和第二后验概率分布,来寻找具有最高序列概率的标签序列。由注意力解码器网络模块1404和ctc模块1408计算出的标签序列的第一后验概率和第二后验概率被组合为一个概率。在这种情况下,可以基于线性组合来执行计算出的后验概率的组合。利用端到端语音识别模块1400,可以考虑ctc概率以寻找对于输入的声学特征序列的更好地对准的假设。
(用于独立于语言的端到端语音识别的神经网络架构)
端到端语音识别通常被定义为寻找给定输入声学特征序列x的最可能的标签序列的问题,即:
其中,
在本公开的实施方式中,独立于语言的神经网络可以是诸如前馈神经网络(ffnn)、卷积神经网络(cnn)和递归神经网络(rnn)之类的不同网络的组合。
仍然参照图14,例如,混合注意力/ctc架构可以用于神经网络。图14是例示了使用具有混合注意力/ctc架构的端到端网络的语音识别模块1400的框图,其中,如下计算标签序列概率。
编码器模块1402包括用于将声学特征序列x=x1,…,xt如下地转换为隐藏向量序列h=h1,…,ht的编码器网络:
h=encoder(x),(2),
其中,函数encoder(x)可以由层迭的一个或更多个递归神经网络(rnn)组成。rnn可以实现为在每个隐藏单元中具有输入门、忘记门、输出门和存储单元的长短期记忆(lstm)。另一个rnn可以是双向rnn(brnn)或双向lstm(blstm)。blstm是一对lstmrnn,其中一个是前向lstm而另一个是后向lstm。获得blstm的隐藏向量作为前向lstm和后向lstm的隐藏向量的级联。
利用前向lstm,前向第t隐藏向量
其中,σ(·)是逐元素的s形函数,tanh(·)是逐元素的双曲正切函数,并且
仍然参照图14,利用后向lstm,如下地计算后向第t隐藏向量
其中,
blstm的隐藏向量是通过将前向和后向隐藏向量如下地级联而获得的:
其中,t指示假设所有向量为列向量的向量的转置操作。
为了获得更好的隐藏向量,我们可以通过将第一blstm的隐藏向量馈送至第二blstm,然后将第二blstm的隐藏向量馈送至第三blstm等等来层迭多个blstm。如果ht′是由一个blstm获得的隐藏向量,则当将其馈送给另一blstm时我们假设xt=ht′。为了减少计算,它可以仅将一个blstm的每两个隐藏向量馈送到另一blstm。在这种情况下,输出隐藏向量序列的长度变为输入声学特征序列长度的一半。
由多个blstm的下标z∈{x,h,i,f,o,c}所标识的全部参数
注意力解码器网络模块1404包括用于使用隐藏向量序列h来计算标签序列概率patt(y|x)的注意力解码器网络。假设y是长度为l的标签序列y1,y2,...,yl。为了有效地计算patt(y|x),能够通过概率链规则如下地分解概率:
并且每个标签概率patt(yl|y1,…,yl-1,x)是从标签上的概率分布而获得的,其是使用注意力解码器网络如下地估计的:
patt(y|y1,…,yl-1,x)=decoder(rl,ql-1),(15),
其中,y是表示标签的随机变量,rl称为内容向量,其具有为h的内容信息。ql-1是解码器状态向量,其包含先前标签y1,…,yl-1和先前内容向量r0,…,rl-1的上下文信息。因此,标签概率作为给定上下文的y=yl的概率而被获得,即:
patt(yl|y1,…,yl-1,x)=patt(y=yl|y1,…,yl-1,x).(16)。
内容向量rl通常作为编码器网络的隐藏向量的加权和给出,即,
其中,alt称为注意力权重,其满足∑talt=1。能够使用ql-1和h如下地计算注意力权重:
elt=wttanh(wql-1+vht+uflt+b)(18)
fl=f*al-1(19)
其中,w、v、f和u是矩阵,并且w和b是向量,它们是注意力解码器网络的可训练参数。elt是第(l-1)个状态向量ql-1与第t个隐藏向量ht之间的匹配得分,以形成时间对齐分布al={alt|t=1,…,t}。al-1表示用于预测先前标签yl-1的先前对齐分布{a(l-1)t|t=1,…,t}。fl={flt|t=1,…,t}是对于al-1与f的卷积结果,其用于将先前对齐反映到当前对齐中。“*”表示卷积运算。
利用状态向量ql-1和内容向量rl如下地获得标签概率分布:
decoder(rl,ql-1)=softmax(wqyql-1+wryrl+by),(21),
其中,wqy和wry是矩阵,并且by是向量,它们是注意力解码器网络的可训练参数。
对于,k维向量v,如下地计算softmax()函数:
其中v[i]表示v的第i元素。
之后,使用lstm将解码器状态向量ql-1如下地更新为ql:
其中,
其中,onehot(y)表示标签y的n分之一(1ofn)编码,其将标签索引转换为一个热向量表示。
由下标z∈{x,h,i,f,o,c}标识的参数
给定隐藏向量序列h,ctc模块1408计算标签序列y的ctc前向概率。请注意,ctc公式使用具有一组不同标签u的、长度为l的标签序列
其中,p(zt|zt-1,y)被认为是包含空白标签的标签变换概率。p(zt|x)是以输入序列x为条件,并通过使用双向长短期记忆(blstm)进行建模的逐帧后验分布:
其中,ht是用编码器网络获得的。
ctc的前向算法如下地执行。我们使用长度为2l+1的扩展标签序列y′=y′1,y′2,…,y′2l+1=b,y1,b,y2,…,b,yl,b,其中在每对相邻标签之间插入空白标签“b”。设αt(s)为表示针对时间帧1,…,t的标签序列y1,…,yl的后验概率的前向概率,其中s表示在扩展标签序列y′中的位置。
对于初始化,我们设:
α1(1)=p(z1=b|x)(31)
α1(2)=p(z1=y1|x)(32)
对于t=2至t,如下地递归计算αt(s):
其中,
最后,如下地获得基于ctc的标签序列概率:
pctc(y|x)=αt(2l+1)+αt(2l).(36)。
逐帧标签序列z表示输入声学特征序列x与输出标签序列y之间的对齐。当计算前向概率时,式(34)的递归强制z为单调的并且不允许在对齐z中s的循环或大跳动,这是因为获得αt(s)的递归最多仅考虑了αt-1(s)、αt-1(s-1)、αt-1(s-2)。这意味着当时间帧前进一帧时,标签从前一标签或空白变改,或保持相同的标签。该约束起强制对齐为单调的转移概率p(zt|zt-1,y)的作用。因此,在基于不规则(非单调)对齐计算pctc(y|x)时,pctc(y|x)能够为0或非常小的值。
最后,我们通过在对数域中如下地组合式(36)中的基于ctc的概率和式(14)中的基于注意力的概率来获得标签序列概率:
logp(y|x)=λlogpctc(y|x)+(1-λ)logpatt(y|x),(37),
其中,λ是使得0≤λ≤1的标量权重并且可以手动地确定。
图15是例示了根据本公开的实施方式的混合ctc/注意力语音识别模块中的神经网络的示意图。组合神经网络1500包括编码器网络模块1502、注意力解码器网络模块1504和ctc模块1508。每个箭头表示经过或不经过变换的数据传送,并且每个方形或圆形节点表示向量或预测标签。声学特征序列x=x1,…,xt被馈送到编码器网络模块1502,在编码器网络模块1502处层迭了两个blstm并且第一blstm的每两个隐藏向量被馈送给第二blstm。编码器模块1502的输出得到隐藏向量序列h=h′1,h′2,…,h′t′,其中t′=t/2。然后,h被馈送给ctc模块1508和注意解码器网络模块1504。分别用ctc模块1508和注意力解码器网络模块1504来计算基于ctc的序列概率和基于注意力的序列概率,并将其组合以获得标签序列概率。
(联合语言标识和语音识别)
独立于语言的端到端系统的关键思想是考虑作为输出标签集的、包括在所有目标语言中出现的字符集的并集的增强字符集,即,
此外,通过进一步增强输出标签集以包含语言id,我们将语言id的预测作为系统的显式部分,从而得到用作端到端语音识别的标签集
此外,对于话语中包括多种语言的情况,它允许网络始终输出多种语言id。对于
这与对包含语言id的混合语言的字符序列(诸如,“[en]how<space>are<space>you?[fr]comment<space>allez-vous?”,其中,<space>正式地表示空格字符)的分布进行建模相同。
图16是例示了根据本公开的实施方式的在多语言语音识别模块中的神经网络的示意图。混合注意力/ctc架构可以用于对此类混合语言的字符序列进行建模。当识别混合语言的话语时,网络能够切换输出序列的语言。图16示出了使用混合注意力/ctc网络1600进行的字符序列预测的示例。编码器网络通过将由日语和英语语音组成的声学特征作为输入来计算隐藏向量序列h。尽管在示例中我们假设x1,…,x5对应于日语并且x6,…,xt对应于英语,但是在实际的声学特征序列中没有用于分离语言的指示符。根据本公开的实施方式,注意力解码器网络能够预测随后跟着日语字符序列的语言id“[jp]”,并且在解码第一日语字符序列之后,网络能够进一步预测与随后的字符序列匹配的语言id,在此为“[en]”。
(用于多语言语音识别的数据生成)
为了预测混合语言的话语,需要使用一组这种混合语言的语料库来训练混合注意力/ctc网络。但是,很难收集到在相同话语中出现多语言的足够量的这种语音语料库。实际上,收集和转录这样的话语是非常昂贵和费时的。然而,能够从已经存在的一组依赖于语言的语料库中人工地生成这种语料库。
假设多个语料库中的每个话语将其相应转录作为字符序列。在下文中,解释了生成这种混合语言的语料库的方法。首先,我们将语言id插入与依赖语言的语料库中每个话语的转录中。语言id可以位于每个字符序列的开头。接下来,如下所述,我们从依赖于语言的语料库中随机地选择话语,同时注意所选话语的覆盖范围和语言转换的变化。然后将所选的话语(及其转录)级联,并视为所生成语料库中的单个话语。重复此过程,直到生成的语料库的持续时间达到原始语料库的并集的持续时间为止。
对语言进行采样的概率与原始语料库的持续时间成正比,其中为了减轻由数据尺寸所引起的选择偏差而添加常数项1/n。在我们的实验中,我们将级联话语的最大数量nconcat设置为3。对于1和nconcat之间的每个数字nconcat,我们通过基于语言和话语的采样概率采样nconcat个语言和话语,来创建由来自原始语料库的nconcat个话语组成的级联话语。为了最大程度地覆盖原始语料库,我们通过引入最大使用次数nreuse(针对训练集设置为5,而针对开发集和评估集设置为2),来防止过多地重复使用话语。我们使用此过程来生成训练集、开发集和评估集。
为了生成多讲话者的多语言训练数据,我们能够随机地选择以上所生成的多语言话语,并将它们与随机增益一起混合。
(训练过程)
将图14的编码器网络参数1403、注意力解码器网络参数1405和ctc网络参数1409联合优化,使得损失函数:
减小,其中x和y是包括声学特征序列和标签序列的训练数据。
θ表示包括图14的编码器网络参数1403、注意力解码器网络参数1405和ctc网络参数1409的一组网络参数。
可以通过随机梯度下降方法来优化网络参数集θ。矩阵和向量的尺寸可以手动地或自动地确定。例如,对于取决于标签集
接下来,将参数集θ中的编码器网络参数、解码器网络参数和ctc网络参数联合优化。基于梯度下降法,如下地重复更新参数集θ的每个元素:
直到
也可以将x和y分割成m个小子集
通过使用小的子集来更新参数,更频繁地更新参数并且损失函数更快地收敛。
应该理解的是,能够与如上所述类似地优化本公开中针对所有网络的参数。例如,关于图10,能够使用与以上描述相似的过程来联合优化针对讲话者分离网络1042、声学编码器网络1046和解码器网络1050的网络参数1041。
(标签序列搜索)
图14的标签序列搜索模块1406根据组合的标记序列概率如下地寻找最可能的标记序列
其中,根据本公开的实施方式,pctc(y|x)是式(36)是基于ctc的标签序列概率,patt(y|x)是式(14)的基于注意力的标签序列概率,并且
然而,由于可能的标签序列的数量与序列的长度成指数地增加,因此难以枚举y的所有可能的标签序列并计算λlogpctc(y|x)+(1-λ)logpatt(y|x)。因此,通常使用波束搜索技术来寻找
设ωl是长度l的部分假设的集合。在波束搜索的开始,ω0仅包含具有起始符号<sos>的一个假设。对于l=1至lmax,ωl-1中的每个部分假设通过附加可能的单个标签来扩展,并且将新假设存储在ωl中,其中lmax是要搜索的假设的最大长度。
如下地计算每个部分假设h的得分:
ψjoint(h)=λψctc(h,x)+(1-λ)ψatt(h),(44),
其中,如下地计算ψatt(h):
ψatt(h)=ψatt(g)+logpatt(y|g).(45)。
为了计算ψctc(h,x),我们利用ctc前缀概率,该ctc前缀概率被定义将h作为它们前缀的全部标签序列的累积概率:
并且,我们将ctc得分定义为:
其中,v表示除空字符串以外的所有可能的标签序列。ctc得分不能如式(45)中ψatt(h)那样递归地获得,而是能够针对每个部分假设通过在输入时间帧上保持前向概率来有效地计算。
根据本公开的实施方式,标签序列搜索模块1406根据以下过程进行寻找
在此过程中,ωl和
在第11行中使用注意力解码器网络对每个扩展的假设h进行评分,并在第12行中将每个扩展的假设h与ctc得分相结合。之后,如果y=<eos>,则假定假设h是完整的,则在第14行中存储在
能够使用修正的前向算法来计算ctc得分ψctc(h,x)。设
其中,我们假设
在此函数中,在第1行中,将给定的假设h首先分割为最后标签y和其余标签g。如果y是<eos>,则在第3行中返回假定h是完整假设的前向概率的对数。根据
如果y不是<eos>,则假定h不是完整假设,计算前向概率
(对技术概念的进一步回顾)
(语音分离-深度聚类)
在这个实验过程中,认识到在给定多个讲话者同时讲话的声学信号作为输入的情况下,深度聚类能够训练深度神经网络,以针对时频域的每个时频(tf)单位输出高维嵌入向量。这样,在输入声学信号中由同一讲话者主导的t-f单位对的嵌入彼此接近,而由不同讲话者主导的t-f单位对的嵌入相距远。因此,能够通过简单的聚类算法从嵌入推断出每个t-f单位的讲话者指配,以产生隔离每个单个讲话者的掩码。
对于具有n个t-f元素和c个讲话者的混合体声谱图,我们能够定义标签矩阵
其中,通过在话语中将全部嵌入向量vi和全部一个热向量yi垂直层迭,分别获得嵌入矩阵
本公开包括其它实施方式,其基于对k均值目标中的嵌入进行白化,使用替代成本函数来提供进一步改进:
预期的是,本公开的一些实施方式能够使用不同的深度聚类目标函数以及其它目标函数,以基于特定目标或所寻求的结果来提供进一步的改进。
本公开还包括使用软加权以在训练时以非常低的能量减少t-f仓(bin)的影响的其它实施方式。其中一些实施方式使用幅度比权重wmr,幅度比权重wmr被定义为在t-f仓i的混合体幅度与在话语内的所有仓的混合体幅度之和的比率:wi=|xi|/∑j|xj|,其中|x|为混合体的幅度。通过非限制性示例,还能够考虑其它类型的权重,例如二进制权重。
(语音分离-嵌合体网络)
本公开的一些实施方式训练用于语音分离的掩码推断(mi)网络。一些实施方式使用掩码近似(ma)目标,其中基于估计的掩码与参考掩码之间的距离来计算损失函数。一些实施方式使用幅度谱近似(msa),其中基于通过将估计的掩码与混合体幅度相乘而获得的目标源的估计幅度与基准幅度之间的距离来计算损失函数。一些实施方式使用相敏谱近似(psa),其中基于通过将估计的掩码与混合体幅度相乘而获得的目标源的估计幅度与和依据混合体与源之间的相位差的项相乘的基准幅度之间的距离来计算损失函数。一些实施方式使用截断的相敏谱近似(tpsa),其中基于通过将估计的掩码乘以混合体幅度而获得的目标源的估计幅度与基准幅度和依据混合体与源之间的相位差的项相乘的乘积的输出在给定范围内的截断之间的距离来计算损失函数。
通过实验了解到,将针对掩码推断网络的最后一层的逻辑s形激活与使用l1距离来测量截断的相敏近似的目标函数一起使用,得到掩码推断(mi)网络中的最佳结果:
其中,
一些实施方式使用嵌合网络,该嵌合网络以多任务学习方式将深度聚类与掩码推断相结合,利用了深度聚类损失的规则化特性和掩码推断网络的简单性。这些实施方式使用经由完全连接的层直接从blstm隐藏层输出来预测掩码的架构。正在被最小化的讲话者分离损失
其中,
其中,αemb是权重,0≤αemb≤1。例如通过使用嵌入以例如经由聚类步骤获得掩码,并且基于这些掩码将分离编码损失计算为掩码推断损失,也能够考虑其它嵌入损失和分离编码损失。
在运行时,在一些实施方式中,mi输出能够用于进行预测,在这种情况下,能够省略特定于深度聚类分支的计算。在其它实施方式中,能够使用聚类算法将深度聚类嵌入转换为掩码,在这种情况下,能够省略特定于掩码推断分支的计算。
通过将权重αdc设置为0,一些实施方式有效地训练了掩码推断网络。通过将权重αdc设置为1,一些实施方式有效地训练了深度聚类网络。
如果需要分离的信号,则能够通过将针对目标讲话者的估计掩码与输入混合体的复数谱图相乘,以获得针对该目标讲话者的估计的复数谱图,然后对估计的复数谱图应用短时傅立叶逆变换以获得时域波形信号,来重构分离的信号。
(具有显式分离的语音识别)
(语音识别-连接机制时间分类(ctc))
本公开的一些实施方式使用混合ctc/注意力架构以更好地利用每种方法的长处并减轻每种方法的缺点。
ctc将输入序列映射到长度更短的输出序列。在此,我们假定我们模型的输入是长度为t的帧激活序列
我们定义:
ctc目标能够定义为
层迭式双向长短期记忆(blstm)网络能够用于获得以所有输入x为条件的逐帧后验分布p(zt|x):
p(zt|x)=softmax(lin(ht))
ht=blstm(x).
(语音识别–基于注意力的编码器-解码器)
基于注意力的方法使用链规则yi1直接估计后验p(c|x),而无需像ctc那样进行条件独立假设:
我们将
p(cl|c1,…,cl-1,x)=decoder(rl,ql-1,cl-1)
ht=encoder(x)
alt=attention({al-1}t,ql-1,ht)
使用编码器网络将输入
(语音识别–多任务学习)
基于注意力的模型以全部先前的预测为条件进行预测,因此能够学习类似于语言模型的输出上下文。但是,在没有严格的单调性约束的情况下,这些基于注意力的解码器模型可能会太灵活,并且可以学习次优对齐,或者更缓慢地收敛到期望的对齐。
在混合系统中,由ctc和注意力解码器网络二者共享blstm编码器。与注意力模型不同,ctc的前向-后向算法在训练期间强制语音和标签序列之间单调对齐。这种方法有助于将系统向单调对齐引导。要最小化的多任务目标变为具有可调谐参数λ:0≤λ≤1的:
(语音识别–解码)
通过具有波束搜索的输出标签同步解码来执行基于注意力的语音识别的推断步骤。但是,我们还考虑了ctc概率,以寻找到输入语音的更好地对齐的假设,即,解码器根据以下在给定语音输入x的情况下寻找最可能的字符序列
在波束搜索过程中,解码器计算每个部分假设的得分。在波束搜索期间,每个长度的部分假设的数量被限制为预定数量(称为波束宽度(beamwidth)),以排除得分相对低的假设,这显著提高了搜索效率。
(联合语音分离和识别)
为将分离和识别网络组件连接到联合系统中,我们使用从嵌合体网络输出的掩码,以通过将输入混合体的幅度谱图与每个源的掩码相乘,以估计的幅度谱图的形式提取每个源。每个源的估计的幅度谱图用作针对该源的分离编码。声学编码器网络从分离编码(即,估计的幅度谱图)计算对数梅尔(log-mel)滤波器组特征,并使用以上混合ctc/注意力架构的编码器网络来输出针对每个源的识别编码。
为了在训练期间选择源转录排列,使用两个自然的选项,即,使分离信号的信号电平近似误差最小化的排列πsig,或使asr损失最小化的排列πasr:
当可用数据包括分离信号的真实值(groundtruth)时,例如,当通过将单讲话者语音人工地混合在一起已经获得了数据集中的混合体时,能够使用排列πsig。另一方面,排列πsig具有的优点在于,它不依赖于分离信号的真实值的可用性,因此将允许在仅转录级标签可用的情况下在较大且听觉上更真实的数据上进行训练。
有多种方式来训练联合分离和识别网络。例如,在一些实施方式中,首先在分离信号的真实值可用的数据上由分离网络自己来训练分离网络,在具有基准标签的干净的单讲话者语音上由识别网络自己来训练识别网络,然后通过基于由单独的识别损失或者识别损失和分离损失的加权组合组成的损失函数的进一步训练,对两个预训练的网络的组合进行微调。能够基于关于保留的验证集的性能,通过实验来确定组合中的权重。
(具有隐式分离的多讲话者语音识别)
在其它实施方式中,不执行显式分离,并且端到端asr系统被设计为在同时讲话的多个讲话者的混合体内直接识别多个目标讲话者的语音。
本公开的一些实施方式包括新的序列到序列框架,以通过以端到端的方式统一源分离和语音识别功能来直接从单个语音序列解码多个标记序列。本公开的一些方面能够包括新的目标函数,该目标函数促进隐藏向量中的非相交性以避免生成相似的假设。本公开的方面包括结合了深度聚类和端到端语音识别的两步过程,而没有执行显式语音分离步骤,这在实验中被证明是成功的。
在实验期间,学习了训练过程,以通过利用基于联合ctc/注意力的编码器-解码器网络的优点用低计算成本来应用排列。实验结果表明,该模型能够将输入语音混合体直接转换为多个标签序列,而无需包括语音对齐信息或相应的非混合语音的任何明确的中间表示。
在实验期间学习的是无排列训练方案,该方案通过选择假设和参考的适当排列,将用于后向传播的输出和标记的通常的一对一映射扩展到一对多,从而使网络从单通道语音混合体生成多个独立假设。例如,当语音混合体包含s个讲话者同时说出的语音时,网络从d维输入特征向量的t帧序列生成具有ns个标签的s个标签序列
ys=gs(o),s=1,…,s,
其中,变换gs被实现为通常彼此共享一些组件的神经网络。在训练阶段,考虑n′s个基准标签的s个序列
其中,π(s)是排列π的第s个元素。例如,对于两个讲话者,
根据本公开的实施方式,基于注意力的编码器-解码器网络预测目标标签序列y=(y1,…,yn),而无需来自输入特征向量序列o和过去标签历史的中间表示。在推断时,使用先前发出的标签,而在训练时,以老师强迫方式将它们替换为基准标签序列r=(r1,…,rn)。能够以过去的历史y1:n-1为条件来计算第n标签yn的概率:
模型能够由两个主要子模块(编码器网络和解码器网络)组成。编码器网络将输入特征向量序列变换为高级表示
h=encoder(o),
yn~decoder(cn,yn-1),
cn,an=attention(an-1,en,h),
en=upate(en-1,cn-1,yn-1)。
解码器网络使用上下文向量cn和标签历史y1:n-1顺序地生成第n个标签yn:
yn~decoder(cn,yn-1)。
以基于位置的注意力机制来计算上下文向量,该基于位置的注意力机制用注意力权重am,l对c维表示序列
基于位置的注意力机制如下地定义an,l:
kn,l=wttanh(veen-1+vhhl+vffn,l+b)
fn=f*an-1,
其中,w、ve、vh、vf、b、f是可调参数,α是称为逆温度的常数,并且*是卷积运算。fn的引入使注意力机制考虑了先前的对齐信息。在某些实验中,例如能够使用宽度200的10个卷积滤波器,并能够将α设置为2。
通过更新lstm函数来递归地更新隐藏状态e:
其中,emb(·)是嵌入函数。
能够使用后向传播来训练编码器和解码器网络以使条件概率最大化:
其中,r是真实值基准标记序列,并且lossatt是交叉熵损失函数。
关于联合ctc/注意力方法,一些实施方式使用连接机制时间分类(ctc)目标函数作为辅助任务来训练网络。与注意力模型不同,ctc的前向-后向算法在训练和解码期间强制在输入语音和输出标签序列之间单调对齐。能够从编码器网络的输出如下地计算出ctc损失:
ctc损失和基于注意力的编码器-解码器损失能够与内插权重λ∈[0,1结合:
在推断步骤中也能够使用ctc和编码器-解码器网络二者。最终的假设是使加权条件概率最大化的序列:
其中,γ∈[0,1]是内插权重。
本公开的一些实施方式训练了多讲话者的端到端的基于联合ctc/注意力的网络。其中,编码器网络经由通过源独立(共享)和源依赖(特定)的编码器网络,将输入序列o转换为一组高级特征序列。选择使yctc和r之间的ctc损失最小化的标签排列,然后解码器网络使用排列后的基准标签生成输出标签序列,以用于老师强制。
为了使网络输出多个假设,在实验期间所考虑的是结合共享和非共享(或特定)神经网络模块二者的层迭架构。这种特定架构将编码器网络分为三个阶段:(第一阶段)第一阶段(也称为混合体编码器)处理输入序列并输出中间特征序列h(也称为混合体编码);(第二阶段)然后由不共享参数的s个独立编码器子网(也称为讲话者差异化编码器)处理序列或混合体编码,得到s个特征序列hs(也称为讲话者差异化编码);(第三阶段)在最后阶段,每个特征序列由同一网络(也称为识别编码器)独立处理,得到s个最终的高级表示gs(也称为识别编码)。
设u∈{1…,s}表示输出索引(对应于目标讲话者之一的语音转录),并且v∈{1...,s}表示基准索引。由encodermix表示混合体编码器,由
h=encodermix(o),
gu=encoderrec(hu)。
在用于设计这种架构的多种动机中,至少一种动机可以根据与显式地分开执行分离和识别的架构的相似性如下说明;第一阶段(即,混合体编码器)将混合体编码为能够在多个源之间进行区分的编码;依赖于源的第二阶段(即,一组讲话者差异化编码器)使用第一阶段的输出从混合体中清理出每个讲话者的语音内容,并为识别做准备;最后阶段遵循对单讲话者语音进行编码以供解码器进行最终解码的声学模型。
解码器网络从编码器网络的s个输出计算每个讲话者的条件概率。通常,解码器网络将基准标签r用作历史记录,以在训练期间以老师强制方式生成注意力权重。但是,在以上无排列训练方案中,直到计算出损失函数才确定要归因于特定输出的基准标签,其中针对所有基准标签运行注意力解码器。因此,针对编码器网络的每个输出gu的解码器输出yu,v的条件概率在针对所述输出的基准标签是rv的假设下被认为:
然后,通过考虑基准标签的全部排列来如下地计算最终损失:
为了与在考虑编码器网络的每个输出gu的所有可能基准标签rv时所涉及的成本相比而减少计算成本,能够基于仅ctc损失的最小化来固定基准标签的排列,然后也能够使用针对注意力机制的相同的排列。这能够是使用基于联合ctc/注意力的端到端语音识别的许多优点当中的至少一个优点。通过假定在由ctc的输出决定排列的情况下的同步输出,来仅针对ctc损失执行排列:
然后,能够使用具有由使ctc损失最小化的排列
与考虑全部可能基准的情况相比,基于注意力的解码仅针对编码器网络的每个输出gu运行一次。最终损失能够定义为使用内插λ的两个目标函数之和:
在推断时,由于基于ctc和基于注意力的解码二者是对相同的编码器输出gu而执行的,因此应属于同一讲话者,因此它们的得分能够如下合并:
其中,pctc(yu|gu)和patt(yu|gu)是使用相同的编码器输出gu获得的。
能够使用单个解码器网络以通过独立地解码由编码器网络生成的多个隐藏向量,来输出多个标签序列。为了使该单个解码器网络生成多个不同的标签序列,其每个输入(即,编码器网络输出的每个隐藏向量序列(也称为识别编码))应该与其它充分不同。为了促进隐藏向量之间的这种不同,能够在目标函数中引入基于负对称kullback-leibler(库尔贝克-莱布勒,kl)散度的新项。对于两个讲话者混合体的特殊情况,考虑以下附加损失函数:
其中,η是小的恒定值,并且
能够考虑各种网络架构,特别是对于编码器网络。在一些实施方式中,我们能够使用vgg网络作为混合体编码器,对于每个讲话者差异化编码器使用具有一层或更多层的blstm,对于识别编码器使用具有一层或更多层的blstm。在一些其它实施方式中,我们能够使用vgg网络的一层或更多层作为混合体编码器,对于每个讲话者差异化编码器使用vgg网络的一层或更多层,对于识别编码器使用具有一层或更多层的blstm。在又一些其它实施方式中,我们能够使用vgg网络的一层或更多层作为混合体编码器,对于每个讲话者差异化编码器使用vgg网络的一层或更多层然后是一层或多层的blstm层,并且对于识别编码器使用具有一层或更多层的blstm。
在实现一些实施方式的实验中,具有音调特征及其德耳塔特征和德耳塔德耳塔特征(83×3=249维)的80维对数梅尔(logmel)滤波器组系数被用作输入特征。输入特征能够归一化为零均值和单位方差。
例如,在一些实验中,混合体编码器由6层vgg网络(卷积、卷积、最大池化、卷积、卷积、最大池化)组成,每个讲话者差异化编码器由2层blstm网络组成,并且识别编码器由5层blstm网络组成。vgg网络具有以下6层cnn架构,按从底(即,第一)到顶(即,最后)的次序为:
卷积(#输入=3,#输出=64,滤波器=3×3)
卷积(#输入=64,#输出=64,滤波器=3×3)
最大池化(曲面片(patch)=2×2,步幅(stride)=2×2)
卷积(#输入=64,#输出=128,滤波器=3×3)
卷积(#输入=128,#输出=128,滤波器=3×3)
最大池化(曲面片=2×2,步幅=2×2)
前三个通道是统计、德耳塔特征和德耳塔德耳塔特征。能够使用线性投影层lin(·),将blstm层定义为前向lstm
每个blstm层能够在前向lstm和后向lstm中具有320个单元,并且在线性投影层中具有320个单位。解码器网络能够具有包含320个单元的1层lstm。
在一些实验中,混合体编码器由以上6层vgg网络的底部四层(卷积、卷积、最大池化、卷积)组成,每个讲话者差异化编码器由以上6层vgg网络的顶部两层(卷积、最大池化)组成,并且识别编码器由7层blstm网络组成。
从-0.1到0.1范围内的均匀分布随机地初始化网络。adadelta算法与梯度裁剪一起用于优化。将adadelta超参数初始化为ρ=0.95和∈=10-8。∈在开发集损失降低时衰变减半。首先使用仅具有一个讲话者差异化网络的单讲话者语音对网络进行训练,然后优化网络参数以输出单讲话者的标签序列。然后复制讲话者差异化网络的架构,以获得与目标讲话者一样多的讲话者差异化网络。通过针对每个参数w复制具有随机扰动的参数w′=w×(1+uniform(-0.1,0.1)),从使用单讲话者语音训练的初始网络的讲话者差异化网络的参数来获得新添加的讲话者差异化网络的参数。能够首先训练模型而没有负kl散度损失,然后再添加具有权重η的负kl散度损失进行重新训练,其中在我们的一些实验中η被设置为0.1。例如,能够基于对保留的数据集的性能,通过实验确定目标函数中用于平衡ctc损失和注意力损失的权重λ。
在推断阶段,预训练的rnnlm(递归神经网络语言模型)能够与ctc和解码器网络并行组合。能够在波束搜索期间在对数域中线性地组合它们的标签概率,以寻找最可能的假设。
(多语言多讲话者语音识别)
本公开的一些实施方式包括端到端多语言多讲话者asr系统。系统从中选择要输出的字符的字符集能够被设置为最终的增强字符集
图17a和图17b示出了根据本公开一些实施方式的用于语音识别的其它语音识别系统的框图,具体而言,图17a包括语音识别网络,即编码器-解码器网络,并且图17b包括语音分离网络以及基于混合ctc/注意力的编码器解码器asr网络。
参照图17a,系统1700a包括配置为执行所存储的指令的处理器1702、以及存储关于自动语音识别(asr)网络、编码器解码器网络1710、基于混合ctc/注意力的编码器解码器asr网络1712的指令的存储器1704。处理器1702能够是单核处理器、多核处理器、图形处理单元(gpu)、计算集群或任何数量的其它配置。存储器/储存器1705能够包括随机存取存储器(ram)、只读存储器(rom)、闪存或任何其它合适的存储器系统。存储器1705还能够包括硬盘驱动器、光盘驱动器、拇指驱动器、驱动器阵列或它们的任何组合。处理器1702通过总线1706连接到一个或更多个输入和输出接口/装置。
存储器1705存储为了将多通道语音信号变换为文本而训练的神经网络1708,并且执行所存储的指令的处理器1702使用从存储器1705中检索到的神经网络1708来执行语音识别。神经网络1708被训练以将多通道有噪语音信号变换为文本。神经网络1708可以包括被训练以从声学信号的语音特征识别文本的编码器-解码器网络1712。
在一个实施方式中,神经网络1708还包括特征提取器(未示出),该特征提取器被配置为从将由编码器-解码器网络使用的单通道信号中提取语音特征。特征提取器是可微函数,因此能够连接到单个端到端神经网络。可微函数的示例包括通道信号的幅度的梅尔函数和通道信号的幅度的bark函数。
在一个实现中,可微函数是被训练为从通道信号中提取语音特征的另一神经子网。在该实现中,特征提取子网与编码器-解码器网络联合训练。
能够使用梯度下降法来优化可微函数,使得函数的输出接近给定输入的目标输出。还能够使用成对的输入样本和目标输出样本将函数近似为未知映射函数,使得全部输入样本尽可能正确地映射到相应的目标样本。
由于可微函数的组成也可微,因此我们能够组合各自被设计为可微函数的级联处理模块,以联合优化它们。
神经网络是可微函数。在本发明中,能够用包括多个神经网络的可微函数来实现端到端多通道语音识别的全部组件。
系统1700a能够包括输入接口(即,麦克风1720)以接受语音信号以及输出接口(即,显示接口1722)以呈现所识别的文本。例如,多个麦克风1720能够将声音转换为多通道语音信号1738。附加地或另选地,输入接口能够包括适于通过总线1706将系统1700a连接到网络1736的网络接口控制器(nic)1730。通过网络1736,能够下载并存储语音信号1738,以用于进一步处理。
仍然参照图17a,输出接口的其它示例能够包括成像接口1726和打印机接口1730。例如,系统1700a能够通过总线1706链接到适于将系统1700a连接到显示装置1724的显示接口1722,其中显示装置1724能够包括计算机监视器、相机、电视机、投影仪或移动装置等。
附加地或另选地,系统1700a能够连接至适于将系统连接至成像装置1728的成像接口1726。成像装置1728能够包括相机、计算机、扫描仪、移动装置、网络摄像机或它们的任意组合。附加地或另选地,系统1700a能够连接至适于将系统1700a连接至打印装置1732的打印机接口1731。打印装置1732能够包括液体喷墨打印机、固体墨水打印机、大规模商用打印机、热敏打印机、uv打印机或热升华打印机等。
参照图17b,根据本公开的一些实施方式,图17b包括语音分离网络以及基于混合ctc/注意力的编码器解码器asr网络。神经网络1708包括语音分离网络1714和基于混合ctc/注意力的编码器解码器asr网络1715。语音分离网络1714能够处理语音信号1738,以输出例如语音特征形式的、针对每个目标讲话者的分离语音,并且由基于混合ctc/注意力的编码器解码器asr网络1715进一步处理每个分离语音,以输出每个目标讲话者的文本。能够训练语音分离网络1714以从语音信号的混合体中分离语音。可以训练基于混合ctc/注意力的编码器解码器asr网络1715以从语音分离网络1714的分离语音输出文本。能够联合训练语音分离网络1714和基于混合ctc/注意力的编码器解码器asr网络1715二者,以从由同时讲话的多个讲话者的语音的混合体所组成的语音信号输出每个目标讲话者的文本。神经网络1708能够被认为是具有显式分离的多讲话者语音识别网络911的示例,如图9b中所描述的:语音分离网络1714能够被认为是讲话者分离网络942的示例,而基于混合ctc/注意力的编码器解码器asr网络1715中的编码器部分能够被认为是声学编码器网络946的示例,并且基于混合ctc/注意力的编码器解码器asr网络1715中的解码器部分能够被认为是解码器网络950的示例。
图18a是通过非限制性示例而例示的根据本公开的实施方式的能够用于实现方法和系统的一些技术的计算装置1800a的示意图。计算设备或装置1800a代表各种形式的数字计算机,诸如膝上型计算机、台式计算机、工作站、个人数字助理、服务器、刀片服务器、大型机和其它适当的计算机。
计算装置1800a能够包括全部连接到总线1850的电源1808、处理器1809、存储器1810、储存装置1811。此外,高速接口1812、低速接口1813、高速扩展端口1814和低速连接端口1815能够连接到总线1850。另外,低速扩展端口1816与总线1850连接。依据特定应用,作为非限制性示例而安装在公共母板1830上的各种组件配置是可预期的。更进一步,输入接口1817能够经由总线1850连接到外部接收器1806和输出接口1818。接收器1819能够经由总线1850连接到外部发送器1807和发送器1820。还连接到总线1850的能够是外部存储器1804、外部传感器1803、机器1802和环境1801。此外,一个或更多个外部输入/输出装置1805能够连接到总线1850。网络接口控制器(nic)1821能够适于通过总线1850连接到网络1822,其中数据或其它数据等能够呈现在计算机装置1800a外部的第三方显示装置、第三方成像装置和/或第三方打印装置上。
可预期的是,存储器1810能够存储计算机装置1800a可执行的指令、历史数据以及本公开的方法和系统能够利用的任何数据。存储器1810能够包括随机存取存储器(ram)、只读存储器(rom)、闪存或任何其它合适的存储器系统。存储器1810能够是一个或更多个易失性存储单元和/或一个或更多个非易失性存储单元。存储器1810还可以是诸如磁盘或光盘之类的另一种形式的计算机可读介质。
仍然参照图18a,储存装置1811能够适于存储计算机装置1800a所使用的补充数据和/或软件模块。例如,储存装置1811能够存储以上关于本公开所提及的历史数据和其它相关数据。附加地或另选地,储存装置1811能够存储与以上关于本公开所提及的数据类似的历史数据。储存装置1811能够包括硬盘驱动器、光盘驱动器、拇指驱动器、驱动器阵列或它们的任何组合。此外,储存装置1811能够包含包括存储局域网络或其它配置中的装置的、计算机可读介质(诸如软盘装置、硬盘装置、光盘装置或磁带装置)、闪存或其它类似固态存储装置或装置阵列。指令能够存储在信息载体中。指令在由一个或更多个处理装置(例如,处理器1809)执行时,执行诸如以上所描述的方法的一种或更多种方法。
该系统能够通过总线1850可选地链接到适于将系统连接到显示装置1825和键盘1824的显示接口或用户接口(hmi)1823,其中显示装置1825能够包括计算机监视器、相机、电视机、投影仪或移动装置等。
仍然参照图18a,计算机装置1800a能够包括适合于打印机接口(未示出)的用户输入接口1817,其也能够通过总线1850连接并适合于连接到打印装置(未示出),其中,打印装置能够包括液体喷墨打印机、固体墨打印机、大型商用打印机、热敏打印机、uv打印机或染料热升华打印机等。
高速接口1812管理计算装置1800a的带宽密集型操作(bandwidth-intensiveoperation),而低速接口1813管理低带宽密集型操作。这种功能分配仅是示例。在一些实现中,高速接口1812能够联接到存储器1810、用户接口(hmi)1823,并且联接到键盘1824和显示器1825(例如,通过图形处理器或加速器),并且连接到可以经由总线1850接受各种扩展卡(未显示)的高速扩展端口1814。在实现中,低速接口1813经由总线1850联接到储存装置1811和低速扩展端口1815。可以包括各种通信端口(例如,usb、蓝牙、以太网、无线以太网)的低速扩展端口1815可以联接至一个或更多个输入/输出装置1805、其它装置、键盘1824、定点装置(未示出)、扫描仪(未示出)或诸如交换机或路由器之类的网络装置(例如通过网络适配器)。
仍然参照图18a,计算装置1800a可以以大量不同形式实现,如图所示。例如,它可以实现为标准服务器1826,或者在一群这样的服务器中实现多次。另外,它可以在诸如膝上型计算机1827之类的个人计算机中实现。它也可以实现为机架式服务器系统1828的一部分。另选地,来自计算装置1800a的组件可以与诸如图18b的移动计算装置1800b之类的移动装置(未示出)中的其它组件组合。每个这样的装置可以包含计算装置1800a和移动计算装置1800b中的一个或更多个,并且整个系统可以由彼此通信的多个计算装置组成。
图18b是例示了根据本公开的实施方式的能够用于实现方法和系统的一些技术的移动计算装置的示意图。移动计算装置1800b包括连接处理器1861、存储器1862、输入/输出装置1863、通信接口1864以及其它组件的总线1895。总线1895还能够连接到诸如微型驱动器或其它装置之类的储存装置1865,以提供附加的存储。
参照图18a,处理器1861能够在移动计算装置1800b内执行包括存储在存储器1862中的指令在内的指令。处理器1861可以被实现为包括分离的并且多个模拟和数字处理器的芯片的芯片组。处理器1861可以提供例如移动计算装置1800b的其它组件的协调,诸如对用户接口的控制、由移动计算装置1800b运行的应用以及由移动计算装置1800b进行的无线通信。依据特别应用,通过非限制性示例,可以安装在公共主板1899上的各种组件配置是可预期的。
处理器1861可以通过控制接口1866和联接到显示器1868的显示接口1867与用户通信。显示器1868可以是例如tft(薄膜晶体管液晶显示器)显示器或oled(有机发光二极管)显示器或其它合适的显示技术。显示接口1867可以包括用于驱动显示器1868以向用户呈现图形和其它信息的适当电路。控制接口1866可以从用户接收命令并且将它们进行转换以提交给处理器1861。此外,外部接口1869可以提供与处理器1861的通信,以使得能够进行移动计算装置1800b与其它装置的近距离通信。例如,在一些实现中针对有线通信,或者在其它实现中针对无线通信,可以提供外部接口1869,并且也可以使用多个接口。
仍然参照图18b,存储器1862将信息存储在移动计算装置1800b内。存储器1862能够实现为一个或更多个计算机可读介质、一个或更多个易失性存储单元或一个或更多个非易失性存储单元中的一者或多者。还可以提供扩展存储器1870,并扩展存储器1870通过扩展接口1869连接到移动计算装置1899,扩展接口1869可以包括例如simm(单列存储模块)卡接口。扩展存储器1870可以为移动计算装置1899提供额外的存储空间,或者还可以为移动计算装置1899存储应用或其它信息。具体地,扩展存储器1870可以包括实施或补充以上所描述的过程的指令,并且还可能包含安全信息。因此,例如,可以提供扩展存储器1870,作为用于移动计算装置1899的安全模块,并且可以用允许安全使用移动计算装置1800b的指令来编程扩展存储器1870。另外,可以经由simm卡提供安全应用以及附加信息,诸如以不可入侵的方式置于simm卡上的标识信息。
存储器1862可以包括例如闪存和/或nvram存储器(非易失性随机存取存储器),如下所讨论的。在一些实现中,指令存储在信息载体中,该指令在被一个或更多个处理装置(例如,处理器1800b)执行时执行诸如以上描述的方法之类的一种或更多种方法。指令还能够由一个或更多个储存装置(诸如一个或更多个计算机或机器可读介质(例如,存储器1862、扩展存储器1870或处理器1862上的存储器))存储。在一些实现中,能够例如通过收发器1871或外部接口1869以传播信号来接收指令。
图18b的移动计算设备或装置1800b旨在表示诸如个人数字助理、蜂窝电话、智能电话和其它类似计算装置之类的各种形式的移动装置。移动计算装置1800b可以通过通信接口1864进行无线通信,该通信接口在必要时可以包括数字信号处理电路。通信接口1864可以在诸如以下各种模式或协议下提供通信:gsm语音呼叫(全球移动通信系统)、sms(短消息服务)、ems(增强消息服务)、或mms消息(多媒体消息服务)、cdma(码分多址)、tdma(时分多址)、pdc(个人数字蜂窝)、wcdma(宽带码分多址)、cdma2000或gprs(通用分组无线业务)等。这样的通信可以例如通过使用射频的收发器1871发生。另外,可以诸如使用蓝牙、wifi或其它此类收发器(未示出)发生短距离通信。另外,gps(全球定位系统)接收器模块1873可以向移动计算装置1800b提供附加的导航和与位置有关的无线数据,其可以由在移动计算装置1800b上运行的应用适当地使用。
移动计算装置1800b还可以使用音频编解码器1872进行听觉上的通信,该音频编解码器1872可以从用户接收所说出的信息并将其转换为可用的数字信息。音频编解码器1872可以例如在移动计算装置1800b的耳机中同样地通过诸如扬声器生成用户可听的声音。这样的声音可以包括来自语音电话呼叫的声音,可以包括所记录的声音(例如,语音消息、音乐文件等),并且还可以包括由在移动计算装置1800b上运行的应用所生成的声音。
仍然参照图18b,移动计算装置1800b可以以多种不同形式实现,如图所示。例如,它可以实现为蜂窝电话1874。它也可以实现为智能电话1875、个人数字助理或其它类似的移动装置的一部分。
(特征)
根据本公开的方面,一组识别编码能够包括针对每个目标讲话者的识别编码,并且解码器网络能够使用针对每个目标讲话者的识别编码以输出该目标讲话者的文本。另一方面能够包括编码器网络,该编码器网络包括混合体编码器网络、一组讲话者差异化编码器网络和识别编码器网络,使得讲话者差异化编码器网络的数量等于或大于目标讲话者的数量的,其中混合体编码器网络输出针对接收到的声学信号的混合体编码,每个讲话者差异化编码器网络从混合体编码输出讲话者差异化编码,并且识别编码器网络从每个讲话者差异化编码输出识别编码。其中,使用包括具有单个讲话者的语音的声学信号和相应文本标签的数据集,利用初始讲话者差异化编码器网络来预训练所存储的语音识别网络。此外,基于初始讲话者差异化编码器网络来初始化一组讲话者差异化编码器网络中的一些讲话者差异化编码器网络。其中,初始化包括随机扰动。
本公开的另一方面能够包括编码器网络,该编码器网络包括讲话者分离网络和声学编码器网络,使得讲话者分离网络输出一组分离编码,其中分离编码的数量等于或大于目标讲话者的数量,并且声学编码器网络使用一组分离编码来输出一组识别编码。其中,一组识别编码中的各个识别编码对应于一组分离编码中的各个分离编码,使得声学编码器网络输出针对每个分离编码的识别编码。此外,一组分离编码包括针对每个目标讲话者的单个分离编码,并且一组识别编码包括针对每个目标讲话者的单个识别编码,使得声学编码器网络使用针对每个目标讲话者的单个分离编码来输出针对该目标讲话者的单个识别编码。更进一步,一组分离编码和接收到的声学信号用于输出针对每个目标讲话者的分离信号。可使用包括来自多个讲话者的声学信号及其相应混合体的数据集训练至少一个讲话者分离网络,以输出分离编码。此外,使用包括具有至少一个讲话者的语音的声学信号和相应文本标签的数据集对声学编码器网络和解码器网络进行训练,以输出文本。更进一步,使用包括具有多个交叠讲话者的语音的声学信号和相应文本标签的数据集,来联合训练至少一个讲话者分离网络、声学编码器网络和解码器网络。也可以使用包括具有多个交叠讲话者的语音的声学信号和相应文本标签的数据集来训练所存储的语音识别网络,使得训练涉及使使用了解码成本和分离成本的加权组合的目标函数最小化。
本公开的另一方面能够包括:来自目标讲话者的语音包括来自一种或更多种语言的语音。其中,至少一个目标讲话者的文本包括有关该至少一个目标讲话者的语音的语言的信息。进一步的方面能够包括使用包括具有多个交叠讲话者的语音的声学信号和相应文本标签的数据集来训练所存储的语音识别网络。
本公开的另一方面能够包括:讲话者差异化编码器网络的数量等于或大于目标讲话者的数量,使得混合体编码器网络输出针对所接收的声学信号的混合体编码,每个讲话者差异化编码器网络从混合体编码输出讲话者差异化编码,并且识别编码器网络从每个初步识别编码输出识别编码。另一个方面能够包括:使用包括具有单个讲话者的语音的声学信号和相应文本标签的数据集,利用初始讲话者差异化编码器网络,来预训练所存储的语音识别网络,其中,基于初始讲话者差异化编码器网络来初始化一组讲话者差异化编码器网络中的一些讲话者差异化编码器网络,使得初始化包括随机扰动。
(实施方式)
以下描述仅提供示例性实施方式,并非旨在限制本公开的范围、适用性或配置。相反,示例性实施方式的以下描述将向本领域技术人员提供用于实现一个或更多个示例性实施方式的充分描述。在不脱离如所附权利要求书中所公开的主题的精神和范围的情况下,可以在元件的功能和布置上进行的各种变型也是可预期的。
在以下描述中给出了具体细节以提供对实施方式的透彻理解。然而,本领域普通技术人员能够理解,可以在没有这些具体细节的情况下实践实施方式。例如,所公开的主题中的系统、过程和其它元件可以以框图形式示出为组件,以免在不必要的细节上模糊实施方式。在其它情况下,可以在没有非必要细节的情况下示出已知的过程、结构和技术,以避免使实施方式模糊。此外,在各个附图中相似的附图标记和标志指代相似元件
另外,各个实施方式可以被描述为被描绘为流程图、流图、数据流图、结构图或框图的过程。尽管流程图可以将操作描述为顺序过程,但是许多操作能够并行或同时执行。另外,操作顺序可以重新排列。当过程的操作完成时,过程可以终止,但是可以具有未讨论或未包含在图中的附加步骤。此外,并非在任何特定描述的过程中的全部操作可以在全部实施方式中发生。过程可以对应于方法、函数、处理、子例程、子程序等。当过程对应于函数时,函数的终止能够对应于函数返回到调用函数或主函数。
此外,所公开的主题的实施方式可以至少部分上手动地或自动地实现。可以通过使用机器、硬件、软件、固件、中间件、微代码、硬件描述语言或它们的任何组合来执行或至少辅助手动或自动实现。当以软件、固件、中间件或微代码实现时,执行必要任务的程序代码或代码段可以存储在机器可读介质中。处理器可以执行必要的任务。
此外,本公开的实施方式和本说明书中描述的功能操作能够以数字电子电路实现,以有形体现的计算机软件或固件实现、以计算机硬件实现,并且包括本说明书中公开的结构及其等同结构,或它们中的一个或更多个的组合。本公开的另外一些实施方式可以实现为一个或更多个计算机程序,即,在有形的非暂时性程序载体上编码的计算机程序指令的一个或更多个模块,以由数据处理装置执行或控制数据处理装置的操作。更进一步,程序指令能够被编码在被生成以对用于向适当接收器设备传输的信息进行编码的人工生成的传播信号(例如机器生成的电、光或电磁信号)上,以由数据处理设备执行。计算机存储介质能够是机器可读存储设备、机器可读存储基板、随机或串行访问存储设备或它们中的一个或更多个的组合。
根据本公开的实施方式,术语“数据处理设备”能够涵盖用于处理数据的各种设备、装置和机器,作为示例包括可编程处理器、计算机或多处理器或计算机。该设备能够包括专用逻辑电路,例如,fpga(现场可编程门阵列)或asic(专用集成电路)。除了硬件之外,该设备还能够包括为所讨论的计算机程序创建执行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统或它们中的一个或更多个的组合的代码。
计算机程序(其也可以称为或描述为程序、软件、软件应用、模块、软件模块、脚本或代码)能够以任何形式的编程语言(包括编译或解释语言)或声明性或程序语言编写,并且能够以包括作为独立程序或作为模块、组件、子例程或适于在计算环境中使用的其它单元的任何形式进行部署。计算机程序可以,但并非必须,对应于文件系统中的文件。程序能够存储在持有其它程序或数据的文件的一部分(例如存储在标记语言文档中的一个或更多个脚本)中,存储在专用于所讨论程序的单个文件中,或者存储在多个协调文件(例如,存储一个或更多个模块、子程序或部分代码的文件)中。能够部署计算机程序,以在一台计算机上或在位于一个站点上或分布在多个站点上并通过通信网络互连的多台计算机上执行。例如,适合于执行计算机程序的计算机作为示例包括,能够是基于通用或专用微处理器或两者、或者任何其它类型的中央处理单元。通常,中央处理单元接收来自只读存储器或随机存取存储器或两者的指令和数据。计算机的基本元件是用于执行或实施指令的中央处理单元以及用于存储指令和数据的一个或更多个存储装置。通常,计算机还将包括用于存储数据的一个或更多个大容量储存装置(例如,磁、磁光盘或光盘),或者可操作地联接以从大容量储存装置中接收数据或向大容量储存装置数据传输数据或二者。但是,计算机并非必须具有这种装置。此外,计算机能够被嵌入到另一装置中,例如,仅举几例,移动电话、个人数字助理(pda)、移动音频或视频播放器、游戏控制台、全球定位系统(gps)接收器或便携式储存装置,例如通用串行总线(usb)闪存驱动器。
为了提供与用户的交互,本说明书中描述的主题的实施方式能够在具有向用户显示信息的显示装置(例如,crt(阴极射线管)或lcd(液晶显示器)监视器)以及用户通过其能够向计算机提供输入的键盘以及定点装置(例如,鼠标或轨迹球)的计算机上实现。其它类型的装置也能够用于提供与用户的交互;例如,提供给用户的反馈能够是例如视觉反馈、听觉反馈或触觉反馈的任何形式的感官反馈;并且能够以包括声学、语音或触觉输入的任何形式接收来自用户的输入。另外,计算机能够通过向用户使用的装置发送文档或从用户使用的装置接收文档来与用户进行交互;例如,通过响应从网络浏览器接收到的请求而向用户客户端装置上的web浏览器发送网页。
能够在包括后端组件(例如,作为数据服务器)或包括中间件组件(例如,应用服务器)或包括前端组件(例如,具有用户通过其能够与本说明书中描述的主题的实现进行交互的、图形用户界面或网络浏览器的客户端计算机)、或者一个或更多个这种后端、中间件或前端组件的任何组合的计算系统中实现本说明书中描述的主题的实施方式。系统的组件能够通过任何形式或介质(例如,通信网络)的数字数据通信互连。通信网络的示例包括局域网(“lan”)和广域网(“wan”),例如互联网。
该计算系统能够包括客户端和服务器。客户端和服务器通常彼此远离,并且通常通过通信网络进行交互。客户端和服务器之间的关系是通过在各自计算机上运行并彼此具有客户端-服务器关系的计算机程序产生的。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



