
 商标分类
商标分类  商标转让
商标转让 
一种基于知识蒸馏的端到端语音合成训练方法及系统与流程
 2021-01-28 14:01:25|
2021-01-28 14:01:25| 259|
259| 起点商标网
起点商标网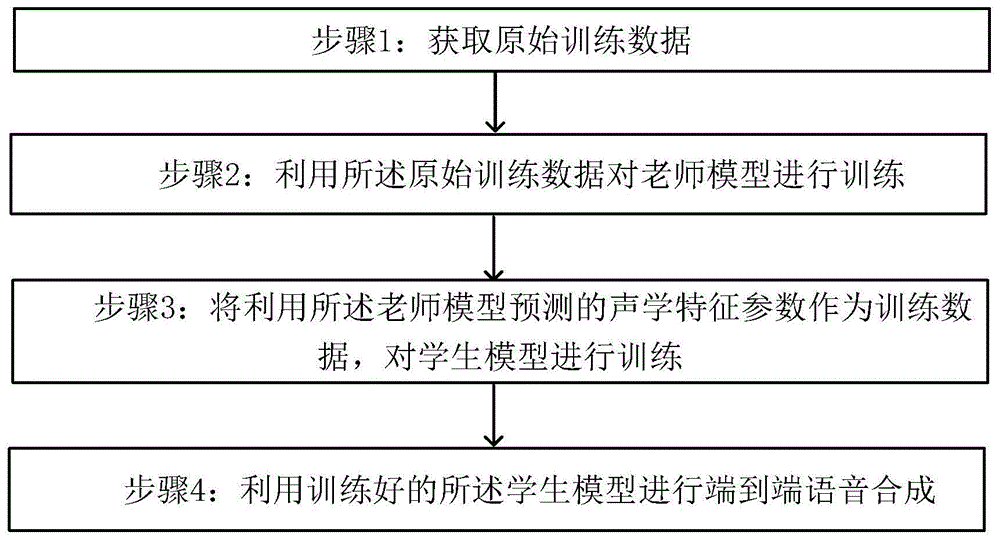
本发明涉及语音合成技术领域,特别涉及一种基于知识蒸馏的端到端语音合成训练方法及系统。
背景技术:
目前,端到端语音合成系统一般包括声学特征参数预测模块与合成器模块两部分,其中声学特征参数预测模块一般采用序列到序列的建模方法,包括embedding、encoder-decoder和post-net等子模块。合成器模块一般采用基于声学信号处理的声码器,或者神经网络声码器。而用于训练端到端合成系统的原始训练数据,包含音频数据和对应的发音文本,其中声学特征参数预测模块由发音文本数据,以及从音频中提取的声学特征参数训练得来。
声学特征参数预测模块中的decoder子模块,在训练时以前一帧的gt声学特征参数作为当前帧的输入;而在测试时,则是以上一帧的decoder预测输出为当前帧的输入。由于模型预测总是存在误差,上述模型训练和测试时分别使用gt声学特征参数和模型预测的特征参数作为输入,存在不匹配的问题,这会导致测试时集外声学特征参数预测精度变差,进而导致集外合成语音听感变差。
技术实现要素:
本发明提供一种基于知识蒸馏的端到端语音合成训练方法及系统,用以避免训练与测试不匹配导致的集外合成语音听感变差的问题。
本发明提供了一种基于知识蒸馏的端到端语音合成训练方法,所述方法执行以下步骤:
步骤1:获取原始训练数据;
步骤2:利用所述原始训练数据对老师模型进行训练;
步骤3:将利用所述老师模型预测的声学特征参数作为训练数据,对学生模型进行训练;
步骤4:利用训练好的所述学生模型进行端到端语音合成。
进一步地,在所述步骤1中,所述原始训练数据包括训练音频和与所述训练音频对应的发音文本。
进一步地,所述步骤2:利用所述原始训练数据对老师模型进行训练执行以下步骤:
步骤s21:从所述原始训练数据中的所述训练音频中提取gt声学特征参数;
步骤s22:使用所述原始训练数据中的所述发音文本和提取的所述gt声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述老师模型。
进一步地,在所述步骤s22中,在训练所述老师模型的解码子模块时,使用当前帧的gt声学特征作为目标输出,使用前一帧的gt声学特征作为输入。
进一步地,所述步骤3:将利用所述老师模型预测的声学特征参数作为训练数据,对学生模型进行训练执行以下步骤:
步骤s31:将集内训练文本输入所述老师模型,采用gta方式预测生成集内声学特征参数,以得到第一gta声学特征参数;
步骤s32:采用所述发音文本、所述gt声学特征参数和所述第一gta声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述学生模型。
进一步地,在所述步骤s32中,在训练所述学生模型的解码子模块时,采用上一帧的第一gta声学特征参数作为输入,采用当前帧的gt声学特征参数作为目标输出。
进一步地,所述步骤4:利用训练好的所述学生模型进行端到端语音合成执行以下步骤:
步骤s41:采用所述学生模型作为声学特征参数预测模型,将集内训练发音文本输入所述学生模型,采用gta方式预测生成集内声学特征参数,以得到第二gta声学特征参数;
步骤s42:采用所述训练音频以及所述学生模型预测的所述第二gta声学特征参数作为输入,训练神经网络声码器;
步骤s43:采用所述神经网络声码器作为语音合成器,进行端到端语音合成。
本发明实施例提供的一种基于知识蒸馏的端到端语音合成训练方法,具有以下有益效果:采用知识蒸馏方法,先训练老师模型,再由老师模型预测的声学特征参数作为输入,训练学生模型,最后利用训练好的学生模型进行端到端语音合成,可以有效解决训练与测试不匹配导致的集外合成语音听感变差的问题。
本发明还提供一种基于知识蒸馏的端到端语音合成训练系统,包括:
获取模块,用于获取原始训练数据;
老师模型训练模块,用于利用所述原始训练数据对老师模型进行训练;
学生模型训练模块,用于将利用所述老师模型预测的声学特征参数作为训练数据,对学生模型进行训练;
语音合成模块,用于利用训练好的所述学生模型进行端到端语音合成。
进一步地,所述老师模型训练模块包括:
gt声学特征参数提取单元,用于从所述原始训练数据中的训练音频中提取gt声学特征参数;
老师模型训练单元,用于使用所述原始训练数据中的所述发音文本和提取的所述gt声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述老师模型。
进一步地,所述学生模型训练模块包括:
第一gta声学特征参数预测单元,用于将集内训练文本输入所述老师模型,采用gta方式预测生成集内声学特征参数,以得到第一gta声学特征参数;
学生模型训练单元,用于采用所述发音文本、所述gt声学特征参数和所述第一gta声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述学生模型。
本发明实施例提供的一种基于知识蒸馏的端到端语音合成训练系统,具有以下有益效果:采用知识蒸馏技术,利用老师模型训练模块训练老师模型,利用学生模型训练模块,由老师模型预测的声学特征参数作为输入,训练学生模型,利用训练好的学生模型进行端到端语音合成,可以有效解决训练与测试不匹配导致的集外合成语音听感变差的问题。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种基于知识蒸馏的端到端语音合成训练方法的流程示意图;
图2为本发明实施例中一种基于知识蒸馏的端到端语音合成训练系统的框图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
本发明实施例提供了一种基于知识蒸馏的端到端语音合成训练方法,如图1所示,所述方法执行以下步骤:
步骤1:获取原始训练数据;
步骤2:利用所述原始训练数据对老师模型进行训练;
步骤3:将利用所述老师模型预测的声学特征参数作为训练数据,对学生模型进行训练;
步骤4:利用训练好的所述学生模型进行端到端语音合成。
上述技术方案的工作原理为:发明人经过研究发现,传统的端到端合成系统,之所以会出现集外合成效果明显下降,一个重要的原因就是模型训练与测试不匹配。声学特征参数预测模型的解码子模块(decoder)在训练时使用上一帧的gt声学特征参数作为输入,而在测试时,却使用上一帧decoder的预测输出作为当前的输入,这种不匹配会导致测试时集外声学特征参数预测精度变差,进而导致集外合成语音听感变差。
本发明将知识蒸馏原理应用到端到端语音合成系统的训练中,在获取原始训练数据后,首先利用原始训练数据对老师模型进行训练,然后将利用老师模型预测的特征参数作为训练数据,对学生模型进行训练;最终使用训练好的学生模型来做声学特征参数的预测,以进行端到端语音合成。
其中,在所述步骤1中,所述原始训练数据包括训练音频和与所述训练音频对应的发音文本。
上述技术方案的有益效果为:采用知识蒸馏方法,先训练老师模型,再由老师模型预测的声学特征参数作为输入,训练学生模型,最后利用训练好的学生模型进行端到端语音合成,可以有效解决训练与测试不匹配导致的集外合成语音听感变差的问题。
在一个实施例中,所述步骤2:利用所述原始训练数据对老师模型进行训练执行以下步骤:
步骤s21:从所述原始训练数据中的所述训练音频中提取gt声学特征参数;
步骤s22:使用所述原始训练数据中的所述发音文本和提取的所述gt声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述老师模型。
上述技术方案的工作原理为:从训练音频中提取的声学特征参数称为gt(groundtruth)声学特征参数。
进一步地,在所述步骤s22中,在训练所述老师模型的解码子模块(decoder)时,使用当前帧的gt声学特征作为目标输出,使用前一帧的gt声学特征作为输入。
上述技术方案的有益效果为:提供了利用原始训练数据对老师模型进行训练的具体步骤。
在一个实施例中,所述步骤3:将利用所述老师模型预测的声学特征参数作为训练数据,对学生模型进行训练执行以下步骤:
步骤s31:将集内训练文本输入所述老师模型,采用gta方式预测生成集内声学特征参数,以得到第一gta声学特征参数;
步骤s32:采用所述发音文本、所述gt声学特征参数和所述第一gta声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述学生模型。
上述技术方案的工作原理为:gta(groundtruthalign)方式指的是在解码子模块(decoder)中做推理时,使用上一帧的gt声学特征参数作为输入,来预测当前帧的声学特征。采用gta方式预测生成的集内声学特征参数,称为第一gta声学特征参数。通过利用老师模型采用groundtruthalign的方式来预测声学特征参数,这样可以保证gt声学特征和预测的声学特征参数在时长上是对齐的,从而解决数据时长对齐的问题。
进一步地,在所述步骤s32中,在训练所述学生模型的解码子模块时,采用上一帧的第一gta声学特征参数作为输入,采用当前帧的gt声学特征参数作为目标输出。
上述技术方案的有益效果为:提供了将利用老师模型预测的特征参数作为训练数据,对学生模型进行训练的具体步骤,可以保证gt声学特征和预测的声学特征参数在时长上是对齐的,从而解决数据时长对齐的问题。
在一个实施例中,所述步骤4:利用训练好的所述学生模型进行端到端语音合成执行以下步骤:
步骤s41:采用所述学生模型作为声学特征参数预测模型,将集内训练发音文本输入所述学生模型,采用gta方式预测生成集内声学特征参数,以得到第二gta声学特征参数;
步骤s42:采用所述训练音频以及所述学生模型预测的所述第二gta声学特征参数作为输入,训练神经网络声码器;
步骤s43:采用所述神经网络声码器作为语音合成器,进行端到端语音合成。
上述技术方案的工作原理为:首先,使用步骤3得到的学生模型,输入集内训练文本,采用gta方式预测生成集内声学特征参数;然后,采用原始训练数据中的训练音频以及学生模型预测的第二gta声学特征参数作为输入,训练神经网络声码器;最后,采用学生模型作为声学特征参数预测模型,采用上述神经网络声码器作为合成器,就是最终使用的端到端语音合成系统。
上述技术方案的有益效果为:提供了利用训练好的学生模型进行端到端语音合成的具体步骤。
如图2所示,本发明实施例提供了一种基于知识蒸馏的端到端语音合成训练系统,包括:
获取模块201,用于获取原始训练数据;
老师模型训练模块202,用于利用所述原始训练数据对老师模型进行训练;
学生模型训练模块203,用于将利用所述老师模型预测的声学特征参数作为训练数据,对学生模型进行训练;
语音合成模块204,用于利用训练好的所述学生模型进行端到端语音合成。
上述技术方案的工作原理为:发明人经过研究发现,传统的端到端合成系统,之所以会出现集外合成效果明显下降,一个重要的原因就是模型训练与测试不匹配。声学特征参数预测模型的解码子模块(decoder)在训练时使用上一帧的gt声学特征参数作为输入,而在测试时,却使用上一帧decoder的预测输出作为当前的输入,这种不匹配会导致测试时集外声学特征参数预测精度变差,进而导致集外合成语音听感变差。
本发明将知识蒸馏原理应用到端到端语音合成系统的训练中,获取模块201获取原始训练数据;老师模型训练模块202利用原始训练数据对老师模型进行训练;学生模型训练模块203将利用老师模型预测的声学特征参数作为训练数据,对学生模型进行训练;语音合成模块204,用于利用训练好的学生模型来做声学特征参数的预测,以进行端到端语音合成。
其中,获取模块201获取的所述原始训练数据包括训练音频和与所述训练音频对应的发音文本。
上述技术方案的有益效果为:采用知识蒸馏技术,利用老师模型训练模块训练老师模型,利用学生模型训练模块,由老师模型预测的声学特征参数作为输入,训练学生模型,利用训练好的学生模型进行端到端语音合成,可以有效解决训练与测试不匹配导致的集外合成语音听感变差的问题。
在一个实施例中,所述老师模型训练模块202包括:
gt声学特征参数提取单元,用于从所述原始训练数据中的训练音频中提取gt声学特征参数;
老师模型训练单元,用于使用所述原始训练数据中的所述发音文本和提取的所述gt声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述老师模型。
上述技术方案的工作原理为:gt声学特征参数提取单元从训练音频中提取的声学特征参数称为gt(groundtruth)声学特征参数。
进一步地,老师模型训练单元在训练所述老师模型的解码子模块(decoder)时,使用当前帧的gt声学特征作为目标输出,使用前一帧的gt声学特征作为输入。
上述技术方案的有益效果为:借助于gt声学特征参数提取单元和老师模型训练单元,可以实现对老师模型的训练。
在一个实施例中,所述学生模型训练模块203包括:
第一gta声学特征参数预测单元,用于将集内训练文本输入所述老师模型,采用gta方式预测生成集内声学特征参数,以得到第一gta声学特征参数;
学生模型训练单元,用于采用所述发音文本、所述gt声学特征参数和所述第一gta声学特征参数作为训练数据,训练声学特征参数预测模型,训练好的所述声学特征参数预测模型作为所述学生模型。
上述技术方案的工作原理为:gta(groundtruthalign)方式指的是在解码子模块(decoder)中做推理时,使用上一帧的gt声学特征参数作为输入,来预测当前帧的声学特征。采用gta方式预测生成的集内声学特征参数,称为第一gta声学特征参数。通过利用老师模型采用groundtruthalign的方式来预测声学特征参数,这样可以保证gt声学特征和预测的声学特征参数在时长上是对齐的,从而解决数据时长对齐的问题。
进一步地,所述学生模型训练单元在训练所述学生模型的解码子模块时,采用上一帧的第一gta声学特征参数作为输入,采用当前帧的gt声学特征参数作为目标输出。
上述技术方案的有益效果为:借助于第一gta声学特征参数预测单元和学生模型训练单元,可以实现学生模型的训练,可以保证gt声学特征和预测的声学特征参数在时长上是对齐的,从而解决数据时长对齐的问题。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



