
 商标分类
商标分类  商标转让
商标转让 
一种基于人工智能的人机智能聊天的方法和装置与流程
 2021-01-28 14:01:25|
2021-01-28 14:01:25| 264|
264| 起点商标网
起点商标网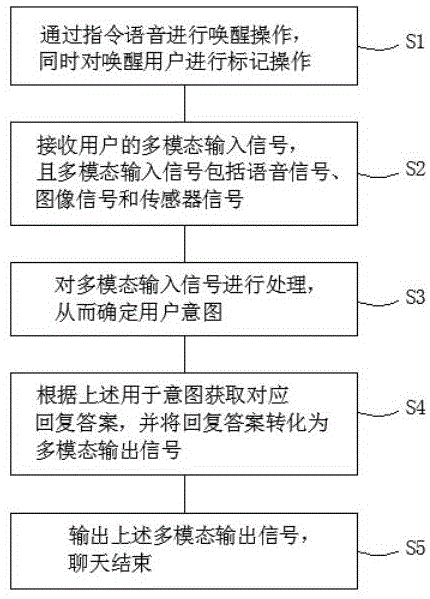
本发明属于人工智能技术领域,具体涉及一种基于人工智能的人机智能聊天的方法和装置。
背景技术:
随着人类社会信息化的不断演进以及人工服务成本的不断上升,人们越来越希望通过自然语言与计算机进行交流;
而人机智能聊天系统则能有效满足上述需求,用户通过自然语言与机器进行对话,并通过对话来指挥或者咨询计算机,完成特定的操作;
在现有市场中人机智能聊天不仅应用于单一用户的自我需要,还有效应用于一些公众场所,例如公共社区服务中心、银行或医院等公共大厅;
但在实际使用中,无论应用于何种场所均需要保证对用户的准确锁定,否则则容易受到外部环境的影响而出现回复偏差的问题,特别是在嘈杂的环境中,上述问题则凸显的更加明显;
另外,针对于上述不同的应用,其实际的聊天需求也有所不同,例如应用于单一用户时,在聊天的过程中需针对该用户进行定向性的分析和回复,才能实现更加个性化且自然的聊天;而对于公共场所下的应用,则需保证聊天分析的公平性,否则在分析过程中则会出现偏向性,影响其他用户的体验效果。
技术实现要素:
本发明的目的在于提供一种基于人工智能的人机智能聊天的方法和装置,以解决现有的人机智能聊天时仍存在在嘈杂无法准确锁定用户而影响聊天恢复准确性的问题,以及针对不同方向的应用存在不同分析需求的问题。
为实现上述目的,本发明提供如下技术方案:
1、一种基于人工智能的人机智能聊天的方法,该方法可应用于多种交互平台上,并利用语音方式实现人机之间的自然交流,具体包括以下步骤:
s1,通过指令语音进行唤醒操作,同时对唤醒用户进行标记操作;
s2,接收用户的多模态输入信号,且多模态输入信号包括语音信号、图像信号和传感器信号;
s3,对多模态输入信号进行处理,从而确定用户意图;
s4,根据上述用于意图获取对应回复答案,并将回复答案转化为多模态输出信号;
s5,输出上述多模态输出信号,聊天结束。
优选的,步骤s3中的处理操作包括对语句的结构分析、语句主体信息的筛选、语句缺失信息的补充、以及语句歧义的消除。
优选的,所述回复答案是基于聊天语境的限制、用户意图的约束、以及用户意图的关联延伸等因素的综合分析所得到的
2、基于上述方法,还包括对步骤s3中的语句分析和用户意图进行储存。
优选的,所述用户意图储存的方式包括永久储存和短期储存。
3、基于上述方法,还包括对多模态输入信号的分析,具体分析步骤包括:a,接收信号;b,筛选信号;c,屏蔽信号;d,放大信号。
优选的,所述输入信号分析是基于用户标记完成的。
优选的,所述用户标记采用声纹识别技术为标记基础。
4、基于上述方法的一种基于人工智能的人机智能聊天装置,包括接收模块、标记模块、处理模块、存储模块和输出模块;且该装置为智能终端或智能终端中的一部分。
优选的,所述接收模块用于接收用户发出的唤醒指令和多模态输入信息;
优选的,所述标记模块用于对发出唤醒指令语音的用户进行标记;
优选的,所述处理模块用于实现多模态输入信息的处理,具体包括用户输入的信息、以及相应环境中的其他信息;
优选的,所述存储模块用于分类储存历史用户意图;
优选的,所述输出模块是基于多模信号转化的基础上实现回复答案的输出,具体包括语句、图像等输出信号。
本发明与现有技术相比,具有以下有益效果:
利用多模态信号的输入与输出实现聊天语境、用户意图的进一步限制,从而使该装置能形成更精确的回复,更充分的满足用户的聊天需求;
并且,配合用户标记操作实现对唤醒用户的准确锁定,从而有效实现聊天过程中的单人对话,降低周围环境中其他语音信息对聊天过程的干扰,进一步提高人机对话的准确性;
另外,延时性的存储操作使得本发明既能有效适用于公共环境中,又能有效适用于专人使用的环境中;其中公共环境中,用户数量较多,且某一用户重复唤醒的次数较少,使得装置内部形成短期储存,从而避免在聊天过程中出现偏向性,有效保证不同用户在使用时的公平性,并避免出现信息过度储存的问题;而专人使用环境中,用户数量单一,且重复唤醒次数角度,使得装置内部形成永久储存,便于在后续使用中依据历史数据进行专用性分析,从而更具有针对性的满足用户需求。
附图说明
图1为本发明的流程图;
图2为本发明的结构框图;
图3为本发明中接收模块的接收流程图;
图中:1-接收模块、2-标记模块、3-处理模块、4-存储模块、5-输出模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
1、本发明提供一种基于人工智能的人机智能聊天的方法,该方法可应用于多种交互平台上,并利用语音方式实现人机之间的自然交流。
如图1所示,为本发明中人机智能聊天的流程图,具体包括以下步骤:
s1,通过指令语音进行唤醒操作;
具体的,在唤醒过程中进行语音标记,从而有效实现聊天过程中的单人对话,降低周围环境中其他语音信息对聊天过程的干扰,提高用户对话的精准性。
s2,接收用户的多模态输入信号;
具体的,多模态输入信号包括语音信号、图像信号和传感器信号;
s3,对多模态输入信号进行处理,从而确定用户意图;
具体的,上述处理操作包括对语句的结构分析、语句主体信息的筛选、语句缺失信息的补充、以及语句歧义的消除;
s4,根据上述用于意图获取对应回复答案,并将回复答案转化为多模态输出信号;
具体的,回复答案的获取是基于聊天语境的限制、用户意图的约束、以及用户意图的关联延伸所实现的;
s5,输出上述多模态输出信号,聊天结束。
如图3所示,为本发明中用户多模态输入信号的接收流程图,具体包括如下步骤:
a,接收信号,包括用户信号和其他环境信号;
b,筛选信号,对用户信号和其他环境信号进行分离筛选;
c,屏蔽信号,屏蔽其他环境信号;
d,放大信号,放大用户信号;
2、本发明提供了一种应用上述智能聊天方法的装置,该装置可直接作为终端使用,也可作为终端中的一部分进行使用;
如图2所示,为上述装置的结构框图,具体包括接收模块1、标记模块2、处理模块3、存储模块4和输出模块5。
优选的,接收模块1用于接收用户发出的唤醒指令和多模态输入信息。
优选的,标记模块2用于对发出唤醒指令语音的用户进行标记,具体标记方式为利用声纹识别技术进行对应用户的语音记录,以此保证在后续信息接收的过程中能实现对用户的精准识别。
优选的,处理模块3用于实现多模态输入信息的处理,具体包括用户输入的信息、以及相应环境中的其他信息。
优选的,存储模块4用于分类储存历史用户意图,具体包括永久储存和短期储存:
(1)存储的用户意图为初始意图时(即初次进行唤醒聊天),储存为短期储存,存储时间为15天,超过15天后未进行二次意图储存则对上述初始意图进行自动清除;
(2)用户意图储存次数超过10次后(包括初始意图,即唤醒操作操作10次),则将该用户的意图转换为永久储存;
上述永久储存的用户意图可作为后续用户聊天中新意图分析的基础,以提高意图分析的定向性,从而给出更个性化的回复,使得聊天过程更加自然。
优选的,输出模块5是基于多模信号转化的基础上实现回复答案的输出,具体包括语句、图像等输出信号。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



