
 商标分类
商标分类  商标转让
商标转让 
一种智能语音收录回放方法及其系统与流程
 2021-01-28 14:01:23|
2021-01-28 14:01:23| 220|
220| 起点商标网
起点商标网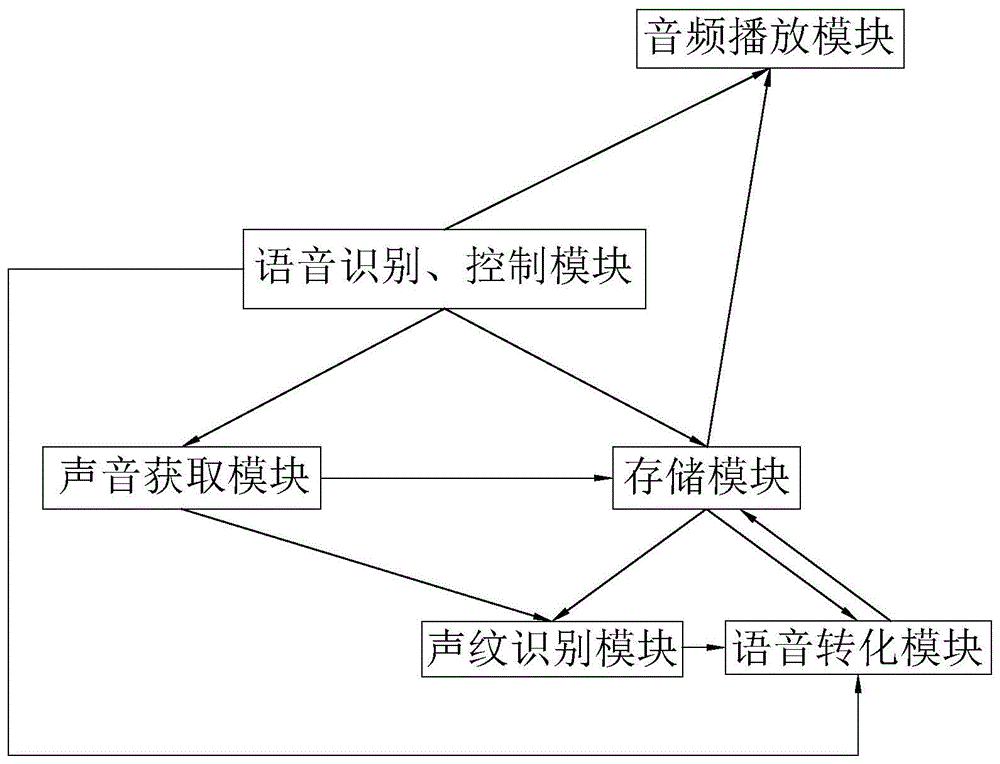
本申请涉及录音的技术领域,尤其是涉及一种智能语音收录回放方法及其系统。
背景技术:
在日常工作生活中,常常会使用到录音功能,比如说录制对话、录制会议等,而且经常需要将存储的录音内容整理形成笔记便于后续查看,现有一般通过语音识别软件来识别语音信息并将语音信息翻译形成文字信息。
现有的语音识别软件一般识别录音内的全部语音,并且直接翻译为连续的文字记录,而在对话或是会议录制的时候,通常会有两人及以上的对话,使用,需要工作人员后期再重听录音,将文字记录重新整理,导致录音整理较为繁琐。
针对上述中的相关技术,发明人认为存在有不便于整理录音的文字记录的缺陷。
技术实现要素:
为了便于整理录音内容,本申请提供一种智能语音收录回放方法及其系统。
第一方面,本申请提供的一种智能语音收录回放方法采用如下的技术方案:
一种智能语音收录回放方法,包括以下步骤,
s1:获取第一声音信息,根据第一声音信息控制收录室内声音,生成录音文件;
s2:识别室内声音的声纹特征,根据声纹特征生成声纹标志信息,以不同的声纹标志信息分隔录音文件;
s3:将录音文件按声纹标志信息分隔识别生成文字信息段,将同一录音文件内的文字信息段按照时间顺序整合形成文字信息记录表;
s4:获取第二声音信息,根据第二声音信息控制停止收录室内声音。
通过采用上述技术方案,根据声纹标志信息划分录音文件且将录音文件转化成文字信息段,从而将不同的人的一次发言转化的文字分隔开,且附上声纹特征,从而便于整理录音内容。
优选的,步骤s3还包括s31,s31:获取第三声音信息,根据第三声音信息获取当前录音文件的录音时长,生成对应当前录音时长的记录节点信息。
通过采用上述技术方案,在回放录音时,可根据记录节点信息获知对应的录音时长,从而可以按照需求跳转至所需播放的录音内容处,具有便于回放录音时定位对应录音内容的效果。
优选的,步骤s3还包括s32,s32:根据第三声音信息向文字信息记录表内写入对应当前记录节点信息的节点标号,同一录音文件内,节点标号按时间顺序设置。
通过采用上述技术方案,在文字信息记录表内写入节点标号,从而将文字信息记录表内的内容按照第三声音信息标注,人员调出文字信息记录表查看内容时,将文字信息记录表内容按照会议主题分段,便于人员寻找所需内容。
优选的,步骤s4还包括s41,s41:获取第四声音信息,根据第四声音信息控制存储录音文件以及文字信息记录表。
通过采用上述技术方案,由第四声音信息控制存储录音文件以及文字信息记录表,从而具有根据需求存储录音文件以及文字信息记录表的效果。
优选的,还包括步骤s5,s5:获取携带记录节点信息的第五声音信号,根据第五声音信号携带的记录节点信息播放录音文件。
通过采用上述技术方案,通过与文本有关的第五声音信号,不同的第五声音信号对应不同的记录节点信息,具有根据第五声音信号可定向播放录音文件的效果。
第二方面,本申请提供一种智能语音收录回放系统,采用如下的技术方案:
一种智能语音收录回放系统,包括:
语音识别、控制模块,用于识别室内声音,若室内声音为第一声音信息,生成控制开始收录室内声音的第一控制信息;若室内声音为第二声音信息,生成控制结束收录室内声音的第二控制信息;若室内声音为第三声音信息,生成存储当前录音时长的第三控制信息;若室内声音为第四声音信息,生成控制存储录音文件以及文字信息记录表的第四控制信息;
声音获取模块,用于获取第一控制信息,根据第一控制信息收录室内声音;用于获取第二控制信息,根据第二控制信息结束收录室内声音;
存储模块,用于存储声音获取模块收录的室内声音,并生成录音文件,获取第三控制信息,根据第三控制信息获取当前录音文件的录音时长且生成对应当前录音时长的记录节点信息;获取第四控制信息,根据第四控制信息存储录音文件;
声纹识别模块,用于识别室内声音的声纹特征,并根据声纹特征分配不同的声纹标志信息;
语音转化模块,用于获取录音文件,获取声纹标志信息,根据声纹标志信息不同分隔录音文件,且将录音文件识别生成携带声纹标志信息的文字信息段,并按照时间顺序整合文字信息段生成文字信息记录表;获取第四控制信息,根据第四控制信息将文字信息记录表发送至存储模块;获取记录节点信息,根据记录节点信息对应的录音时长于文字信息记录表内按序写入节点标号。
通过采用上述技术方案,声音获取模块获取室内声音,语音识别、控制模块,识别室内语音是否携带声音信息,从而根据声音信息生成控制信息,存储模块存储录音文件,声纹识别模块识别室内声音内的声纹特征,并且根据声纹特征生成声纹标志信息,语音转化模块,用于转换录音文件的音频信息为文字信息,录音文件由声纹标志信息划分为一段段,语音转化模块根据声纹标志信息的划分将录音文件翻译为文字信息段,并将文字信息段携带声纹标志信息形成文字信息记录表,从而具有便于整理录音内容的效果。
优选的,所述存储模块包括暂存子模块、存储子模块以及定时删除子模块;
暂存子模块,用于获取声音获取模块收录的室内声音,并存储为暂存文件;获取第三控制信息,将当前录音时长生成记录节点信息,并存储于对应暂存文件;
存储子模块,用于获取第四控制信息,根据第四控制信息存储暂存文件为录音文件;
定时删除子模块,用于获取第四控制信息,根据第四控制信息间隔第一预设时间删除暂存文件;在第二预设时间内若没有获取到第四控制信息,则在第二预设时间后删除暂存文件。
通过采用上述技术方案,由声音获取模块获取的声音信息存储与暂存子模块内,存储子模块根据第三控制信息转存暂存文件为录音文件,定时删除子模块根据获取的第四控制信息控制暂存子模块删除暂存文件,从而释放暂存子模块的空间,便于下次存储,本方案具有良好的中转、缓存效果。
优选的,还包括音频播放模块,
音频播放模块,用于接收第五控制信息,判断第五控制信息对应的记录节点信息,并由记录节点信息开始播放录音文件。
通过采用上述技术方案,音频播放模块获取第五控制信息,并由第五控制信息控制由对应记录节点信息的记录时长开始播放录音文件,具有定位播放录音文件的效果。
优选的,所述音频播放模块包括判断子模块以及播放子模块;
判断子模块,用于接收第五控制信息,获取记录节点信息,判断第五控制信息携带的记录节点信息对应的录音时长;
播放子模块,获取判断子模块判断获得的录音时长,获取录音文件或暂存文件,将录音文件或暂存文件跳转至录音时长对应的时间播放录音文件或暂存文件。
通过采用上述技术方案,通过判断子模块进行预先判断第五控制信息的信息内容,再通过播放子模块播放录音文件或暂存文件,从而具有有序控制播放录音文件的效果。
综上所述,本申请包括以下至少一种有益技术效果:
1、根据声纹标志信息划分录音文件且将录音文件转化成文字信息段,从而将不同的人的一次发言转化的文字分隔开,且附上声纹特征,从而便于整理录音内容;
2、在回放录音时,可根据记录节点信息获知对应的录音时长,从而可以按照需求跳转至所需播放的录音内容处,具有便于回放录音时定位对应录音内容的效果;
3、声音获取模块获取室内声音,语音识别、控制模块,识别室内语音是否携带声音信息,从而根据声音信息生成控制信息,存储模块存储录音文件,声纹识别模块识别室内声音内的声纹特征,并且根据声纹特征生成声纹标志信息,语音转化模块,用于转换录音文件的音频信息为文字信息,录音文件由声纹标志信息划分为一段段,语音转化模块根据声纹标志信息的划分将录音文件翻译为文字信息段,并将文字信息段携带声纹标志信息形成文字信息记录表,从而具有便于整理录音内容的效果。
附图说明
图1是本申请实施例一种智能语音收录回放系统的原理框图;
图2是本申请实施例一种智能语音收录回放系统中存储模块的程序框图;
图3是本申请实施例一种智能语音收录回放系统中音频播放模块的程序框图;
图4是本申请实施例一种智能语音收录回放方法的流程框图。
具体实施方式
以下结合附图1-4对本申请作进一步详细说明。
本申请实施例公开一种智能语音收录回放系统,包括:
参照图1,语音识别、控制模块,用于识别室内声音,若室内声音为第一声音信息,生成控制开始收录室内声音的第一控制信息;若室内声音为第二声音信息,生成控制结束收录室内声音的第二控制信息;若室内声音为第三声音信息,生成存储当前录音时长的第三控制信息;若室内声音为第四声音信息,生成控制存储录音文件以及文字信息记录表的第四控制信息。
具体的,语音识别、控制模块可由处理器以及存储于计算机内的语音识别程序组成,使用时,配合语音采集终端使用,语音采集终端采集室内声音,语音识别程序对语音内容进行识别,且根据识别内容作出响应,具体的,第一声音信息为按照文本设置的信息,可以为普通话的“开始录音”,语音识别程序系识别出“开始录音”的信息,处理器生成第一控制信息;第二声音信息为按照文本设置的信息,第二声音信号可以为普通话的“结束录音”,语音识别程序识别出“结束录音”的信息,处理器生成第二控制信息;第三声音信息为按照文本设置的信息,第三声音信息可以为普通话的“下一主题”,语音识别程序识别出“下一主题”的信息,处理器生成第三控制信息;第四声音信息为按照文本设置的信息,第四声音信息可以为普通话的“保存录音”,语音识别程序识别出“保存录音”的信息,处理器生成第四控制信息。
声音获取模块,用于获取室内声音,获取第一控制信息,根据第一控制信息收录室内声音;用于获取第二控制信息,根据第二控制信息结束收录室内声音。
具体的,声音获取模块可以为具有录音功能的语音采集终端比如录音设备、话筒等,声音获取模块接收到第一控制信息,开始录音;声音获取模块接收到第二控制信息,则结束录音。
存储模块,用于存储声音获取模块收录的室内声音,并生成录音文件,获取第三控制信息,根据第三控制信息获取当前录音文件的录音时长且生成对应当前录音时长的记录节点信息;获取第四控制信息,根据第四控制信息存储录音文件。
参照图2,进一步的,存储模块包括暂存子模块、存储子模块以及定时删除子模块。
暂存子模块,用于获取声音获取模块收录的室内声音,并存储为暂存文件;获取第三控制信息,将当前录音时长生成记录节点信息,并存储于对应暂存文件。
存储子模块,用于获取第四控制信息,根据第四控制信息存储暂存文件为录音文件。
定时删除子模块,用于获取第四控制信息,根据第四控制信息间隔第一预设时间删除暂存文件;在第二预设时间内若没有获取到第四控制信息,则在第二预设时间后删除暂存文件。
具体的,声音获取模块获取室内声音,接收到第一控制信息,将室内声音存储于暂存子模块,暂存子模块起到中转暂存文件的作用,当存储子模块获取到第四控制信息时,将暂存文件转存于存储子模块内,进行保存,定时删除子模块获取第四控制信息,在间隔第一预设时间后将暂存子模块中的暂存文件删除,释放暂存子模块被暂存文件占用的空间,在本实施例中,第一预设时间大于存储子模块转存暂存文件所需的时间;定时删除子模块若在第二预设时间后没有获取到第四控制信息,则在第二预设时间后控制暂存子模块删除当前暂存文件,以释放暂存子模块的空间,在本实施例中,第二预设时间为声音获取模块接收第二控制信息后的一小时,实际可根据需求设置,便于定时删除不需要的暂存文件,在删除暂存文件前,具有第二预设时间缓冲,防止人员忘记保存录音文件;在实际使用中,删除暂存文件前十分钟,智能语音收录回放系统可发出灯光、声音信号以提醒即将删除暂存文件,灯光信号可采用闪烁的led灯产生,声音信号可采用蜂鸣器或是喇叭等产生;暂存子模块获取第三控制信息,暂存文件按序存储,并将当前暂存文件的录音时长后的暂存文件第一个存储地址存储于记录节点信息,且在同一暂存文件录音期间,若接收多次第三控制信息,则将记录节点信息按照时间顺序排序。
参照图1,声纹识别模块,用于识别室内声音的声纹特征,并根据声纹特征分配不同的声纹标志信息;
具体的,声纹识别模块可为存储于处理器的声纹识别程序,声纹识别模块根据不同的声纹特征,比如说话频率、口音、惯用词等识别声音获取模块获取的室内声音,在本实施例系统使用前,预先建立可能与会人员的声纹库,且建立背景模型,具体采用手段可以为预先采集若干将与会人员的说话数据,通过算法建立模型,增加声纹识别模块的识别精准度,声纹识别模块根据识别结果,生成声纹标志信息于已识别声纹特征,在同一次录音中,同一声纹特征使用同一声纹标志信息。
语音转化模块,用于获取录音文件,获取声纹标志信息,根据声纹标志信息不同分隔录音文件,且将录音文件识别生成携带声纹标志信息的文字信息段,并按照时间顺序整合文字信息段生成文字信息记录表;获取第四控制信息,根据第四控制信息将文字信息记录表发送至存储模块;获取记录节点信息,根据记录节点信息对应的录音时长于文字信息记录表内按序写入节点标号。
具体的,语音转化模块同步获取暂存文件以及暂存文件中对应的声纹标志信息,识别暂存文件中的音频信息,并且将对应的音频信息转化为文字信息,语音转化模块以不同的声纹标志信息为分隔标准,将文字信息分隔为文字信息段,并将声纹标志信息配合文字信息段按照时间顺序形成文字信息记录表,供人员查看文字信息记录表,从而获知会议内容以及会议主题数、与会人员数等信息;语音转化模块获取记录节点信息,并在对应记录节点信息的暂存文件录音时长向文字信息记录表内写入节点标号,同一文字信息记录表内的节点标号按照时间顺序以阿拉伯数字按序设置,便于查看文字信息记录表时,按照节点标号划分会议主题。
进一步的,还包括音频播放模块,
参照图3,音频播放模块,用于接收第五控制信息,判断第五控制信息对应的记录节点信息,并由记录节点信息开始播放录音文件。
进一步的,音频播放模块包括判断子模块以及播放子模块;
判断子模块,用于接收第五控制信息,获取记录节点信息,判断第五控制信息携带的记录节点信息对应的录音时长。
播放子模块,获取判断子模块判断获得的录音时长,获取录音文件或暂存文件,将录音文件或暂存文件跳转至录音时长对应的时间播放录音文件或暂存文件。
具体的,第五控制信息产生于声音识别、控制模块,声音识别、控制模块获取第五声音信号,第五声音信号可以为普通话的“播放第n主题”,n可以为1、2、3、4等,语音识别程序系识别出“播放第n主题”的信息,在本实施例中,以第五声音信号为“播放第1主题”为例,语音识别程序识别“播放第1主题”信息,处理器生成排序为1的第五控制信息,若语音识别程序识别“播放第2主题”信息,处理器生成排序为2的第五控制信息以此类推;排序为1的第五控制信息对应按时间顺序排序为1的节点记录信息,且对应按时间顺序排序为1的节点标号,在本实施例中,第五控制信息、节点记录信息以及节点标号按照时间顺序排列且一一对应;判断子模块接收第五控制信息,获取第五控制信息对应的排序,由第五控制信息对应的排序查找排序对应的记录节点信息,并且获取该记录节点信息对应的录音时长,播放子模块获取录音时长,并跳转至录音文件或暂存文件对应该录音时长的位置播放录音文件或暂存文件。
本实施例一种智能语音收录回放系统的实施原理为:声音获取模块获取室内声音,语音识别、控制模块,识别室内语音携带的声音信息,根据声音信息生成控制信息,存储模块存储录音文件,声纹识别模块识别室内声音内的声纹特征,并且根据声纹特征生成声纹标志信息,语音转化模块,用于转换录音文件的音频信息为文字信息,录音文件由声纹标志信息划分为若干段,语音转化模块根据声纹标志信息的划分将录音文件翻译为文字信息段,并将文字信息段携带声纹标志信息形成文字信息记录表,便于整理录音内容。
本申请实施例还公开一种智能语音收录回放方法,适用于上述智能语音收录回收系统,参照图4,包括以下步骤:
s1:获取第一声音信息,根据第一声音信息控制收录室内声音,生成录音文件。
具体为,声音获取模块获取室内声音,语音识别、控制模块识别室内声音是否包含第一声音信息,若包含,则根据第一声音信息生成第一控制信息,控制声音获取模块收录室内声音并存储于存储模块。
s2:识别室内声音的声纹特征,根据声纹特征生成声纹标志信息,以不同的声纹标志信息分隔录音文件。
具体为,声纹识别模块由声音获取模块获取的室内声音中进行声纹辨别,并且对应不同的声纹生成不同的声纹标志信息,且按照声纹标志信息不同分隔录音文件,即是将录音文件分隔成不同的人的说话录音且存储于存储模块。
s3:将录音文件按声纹标志信息分隔识别生成文字信息段,将同一录音文件内的文字信息段按照时间顺序整合形成文字信息记录表。
语音转化模块将存储模块内的分隔好的录音文件转化为一段段的文字信息段,一段文字信息段对应一个人的一次发言,然后存储模块按照时间顺序将文字信息段携带对应的声纹标志信息存储于文字信息记录表,从而形成按照时间顺序以一个人一次发言为分段的文字信息记录表,便于人员获取文字信息记录表后,由文字信息记录表可直观看出与会人员数,以及每次发言的发言人员。
s31:获取第三声音信息,根据第三声音信息获取当前录音文件的录音时长,生成对应当前录音时长的记录节点信息。
具体的,开始录音时的录音时长为0时0分0秒,随着时间的增加,录音时长逐渐增加,而录音文件内的某段录音内容的起始位置可由录音时长获知,第三声音信息用于分隔会议主题,当存储模块获取第三控制信息后,即时获取当前录音文件的录音时长,将该录音时长后开始的第一个录音存储地址标记,并形成对应该录音存储地址的记录节点信息,当调用记录节点信息,即可调用对应的录音存储地址,并且由该位置开始播放录音文件。
s32:根据第三声音信息向文字信息记录表内写入对应当前记录节点信息的节点标号,同一录音文件内,节点标号按时间顺序设置。
具体的,在文字信息记录表内写入节点标号,便于查看文字信息记录表的时候,可根据节点标号获知会议主题的更换。
s4:获取第二声音信息,根据第二声音信息控制停止收录室内声音。
进一步的s4还包括s41。
s41:获取第四声音信息,根据第四声音信息控制存储录音文件以及文字信息记录表。
s5:获取携带记录节点信息的第五声音信号,根据第五声音信号携带的记录节点信息播放录音文件。
以上均为本申请的较佳实施例,并非依此限制本申请的保护范围,故:凡依本申请的结构、形状、原理所做的等效变化,均应涵盖于本申请的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



