
 商标分类
商标分类  商标转让
商标转让 
一种自动识别生理声音的系统及方法与流程
 2021-01-28 14:01:31|
2021-01-28 14:01:31| 238|
238| 起点商标网
起点商标网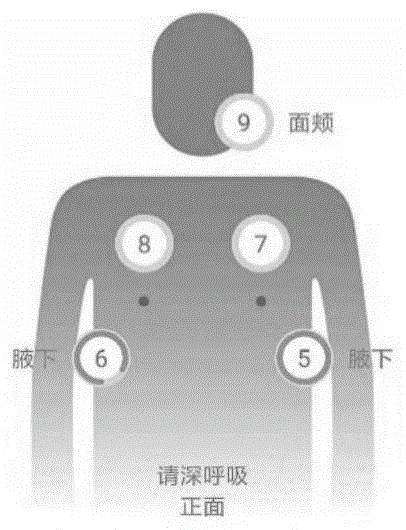
本发明涉及医疗识别技术领域,尤其涉及一种自动识别生理声音的系统及方法。
背景技术:
生理声音包括心音、肺音、肠鸣音、血管回音、气管呼吸音、支气管呼吸音以及手足呼吸音等各种器官发出的声音。其中呼吸音俗称肺音,它能够反映肺部组织、气管及胸壁等传播媒介的声学特性。心脏杂音则属于心音的一种,具体指在心音与额外心音之外,在心脏收缩或舒张时血液在心脏或血管内产生湍流所致的室壁、瓣膜或血管振动所产生的异常声音,是具有不同频率、不同强度、持续时间较长的噪杂声。通过对生理声音的准确分析以及分类,可对相关疾病诊断起到重要的决定性作用。与其他检测生理声音设备相比,听诊器不仅可以直接、简便、快捷、准确有效地获取疾病信息,而且价格低廉,具有非侵入性、无放射性、可重复性等优点。因此,作为临床最常用的疾病诊断工具之一,听诊器被广泛用于辅助诊断心呼吸和血管系统等疾病。然而,目前临床普遍使用的机械听诊器存在诸多弊端,如听诊效果易受环境噪音、患者配合度以及听诊者的水平等诸多人为因素和环境因素的影响,从而使听诊结果造成偏差,甚至产生误诊,使得临床医生不能结合呼吸音和心脏杂音的变化来及时掌握和判断患者病情变化。
同时呼吸音及其他生理声音的频率范围约为50-3000hz,而人耳的敏感频段约为1000-2000hz,传统的机械听诊器的低频响应很差,所以在听诊过程中难以捕捉微弱声音。再加上不同医生存在临床经验和疾病诊断水平的差异,对同一病人的生理声音听诊往往有不同的判断结果,甚至大相径庭,更不要说通过生理声音判断感染的部位、程度和阶段以及其中的病理生理变化、演变过程,并预判其发展方向和预后。因此通过对生理声音进行定量分析,提取生理声音的典型特征进行分类识别,建立科学的、统一的、准确的以及可量化的生理声音诊断标准,从而提高疾病诊治的水平极具必要性。因此,上述缺陷需要得到解决。
技术实现要素:
(一)要解决的技术问题
本发明要解决的问题是现有的听诊器因不同医生存在临床经验和疾病诊断水平的差异,对同一病人的生理声音听诊往往有不同的判断结果造成听诊标准不统一。
(二)技术方案
本发明一个实施例中提供的一种自动识别生理声音的系统,包括:
收集模块,用于生理声音的收集,并将采集的生理声音转化生成代表声学振动电子信号;
特征提取模块,用于从所述生理声音中提取时域特征值和频域特征值;
识别分类模块,用于分类所述的时域特征值与频域特征值并识别时域特征值与频域特征值所属的至少一个类别。
在一方面,所述收集模块是采用数字听诊器将生理声音收集,并将采集的生理声音转化生成代表声学振动电子信号。
在一方面,所述生理声音包括心音、肺音、肠鸣音、血管回音、气管呼吸音、支气管呼吸音以及手足呼吸音。
在一方面,所述时域特征值是通过将代表声学振动电子信号进行小波变换,从而把一个生理声音分解成若干不同频率的信号,计算不同频率信号的时域特征值而得到;而所述的频域特征值则是通过将代表声学振动电子信号进行小波变换,从而把一个生理声音分解成若干不同频率的信号,计算不同频率信号的频域特征值而得到。
在一方面,所述识别分类模块则是将计算出的时域特诊值和频域特诊值作为输入,通过向量机或神经网络算法训练好的模型进行分类,并识别其为正常生理声音或异常生理声音类别。
在一方面,所述生理声音为肺音,则所述识别分模块则是将计算出的时域特诊值和频域特诊值作为输入,通过向量机或神经网络算法训练好的模型进行分类,并识别其为正常肺音或水泡音类别,进而识别患者是否患有肺炎。
在另一方面,本发明提供一种使用所述系统的自动识别生理声音的方法,包括:
s1、使用收集模块收集并处理的生理声音;
s2、使用特征提取模块从生理声音中提取时域特征值和频域特征值;
s3、使用识别分类模块分类所述的时域特征值与频域特征值并识别所属的至少一个类别。
在一个方面,所述使用收集模块收集并处理的生理声音的方法,包括:
声音预处理,用于对生理声音去除重采样或弱信号;
带通滤波,对生理声音转化生成代表声学振动电子信号带通滤波。
在一方面,使用特征提取模块从生理声音中提取时域特征值和频域特征值的方法,包括
信号归一化,对生理声音转化生成代表声学振动电子信号进行小波变换并分解成若干不同频率的信号;
计算智能阈值,计算若干不同频率的信号的阈值。
在一个方面,使用识别分类模块分类所述的时域特征值与频域特征值并识别所属的至少一个类别的方法,包括:
构建识别分类参数,从生理中提取两个声音库,其中一个声音库为cracks(异常生理声音)组成,另外一个假cracks(正常生理声音)组成,提取的每个声音文件为20ms并计算出cracks和假cracks的时域特征值及频域特诊值,然后利用向量机或神经网络算法进行训练,得出识别分类参数;
找出潜在cracks,用20ms的窗沿着肺音信号移动,根据计算阈值找出所有潜在cracks;
潜在cracks特征提取,并将所有潜在cracks的时域特征和频域特征计算出来,
分类模型参数识别,根据将所有潜在cracks计算出来时域特征和频域特征与识别分类参数判断,得出潜在cracks属于cracks和假cracks;
识别所属的类别,根据生理声音平均1秒钟所含cracks的数量来判断所属的类别是正常生理声音类别还是何种异常生理声音类别。
在一方面,所述生理声音为肺音,带通滤波范围控制在100-2000hz,所属的类别为正常肺音或水泡音,并根据所属的类别判断患者为健康状况或何种疾病状况。
(三)有益效果
首先,本发明提供的自动识别生理声音的系统采用数字听诊器进行生理声音收集并转化生成方便记录及分析电子信号形式,使得每次采集的电子信号进行统一存储及分析,为后续大数据分析模型的建立积累基础,同时其电子信号为可视化可量化的数据,便于标准化诊断,在生理声音收集过程中进行预处理及带通滤波来增加收集的有效性;
其次,本发明提供的自动识别生理声音的系统采用特征提取模块对生理声音信号归一化方便后续计算得出智能阈值来减少识别的数量,增加识别正确性;
最后,本发明提供自动识别生理声音的系统利用识别分类模块中预先构件的识别分类参数来对在潜在cracks特征进行识别,并根据1秒钟所含cracks的数量来进行生理声音类别的识别,整个过程基于算法是一种可量化及标准化的系统,并且识别的准确率高。
附图说明
图1为本发明提供的实施例中患者肺音正面采集点示意图;
图2为本发明提供的实施例中患者肺音反面采集点示意图;
图3为本发明提供的实施例中含有水泡音的肺音信号及其时间轴放大后示意图;
图4为本发明提供的实施例中肺音的频率分布图;
图5为本发明提供的实施例中水泡音及正常肺音波峰幅值对照图;
图6为本发明提供的实施例中特征值提取流程示意图;
图7为本发明提供的实施例中cracks的示意图;
图8为本发明提供的实施例中假cracks的示意图;
图9为本发明提供的实施例中肺音信号处理流程示意图;
图10为本发明提供的实施例中向量机模型分类结果示意图;
图11为本发明提供的实施例中通过智能算法分析后的结果展示图。
图12为本发明提供的实施例中小波变换示意图;
图13为本发明提供的实施例中数学模型示意图;
具体实施方式
下面结合实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本发明一个实施例中提供的一种自动识别生理声音的系统,包括:
收集模块,用于生理声音的收集,并将采集的生理声音转化生成代表声学振动电子信号;特征提取模块,用于从生理声音中提取时域特征值和频域特征值;识别分类模块,用于分类的时域特征值与频域特征值并识别时域特征值与频域特征值所属的至少一个类别。
其中收集模块是采用数字听诊器将生理声音收集,并将采集的生理声音转化生成代表声学振动电子信号。生理声音包括心音、肺音、肠鸣音、血管回音、气管呼吸音、支气管呼吸音以及手足呼吸音。
置于时域特征值是通过将代表声学振动电子信号进行小波变换,从而把一个生理声音分解成若干不同频率的信号,计算不同频率信号的时域特征值而得到;而的频域特征值则是通过将代表声学振动电子信号进行小波变换,从而把一个生理声音分解成若干不同频率的信号,计算不同频率信号的频域特征值而得到。识别分类模块则是将计算出的时域特诊值和频域特诊值作为输入,通过向量机或神经网络算法训练好的模型进行分类,并识别其为正常生理声音或异常生理声音类别。
在另一方面,使用系统的自动识别生理声音的方法,包括:
s1、使用收集模块收集并处理的生理声音;
s2、使用特征提取模块从生理声音中提取时域特征值和频域特征值;
s3、使用识别分类模块分类的时域特征值与频域特征值并识别所属的至少一个类别。
其中使用收集模块收集并处理的生理声音的方法,包括:
声音预处理,用于对生理声音去除重采样或弱信号;
带通滤波,对生理声音转化生成代表声学振动电子信号带通滤波。
而使用特征提取模块从生理声音中提取时域特征值和频域特征值的方法,包括
信号归一化,对生理声音转化生成代表声学振动电子信号进行小波变换并分解成若干不同频率的信号;
计算智能阈值,计算若干不同频率的信号的阈值。
与此同时使用识别分类模块分类的时域特征值与频域特征值并识别所属的至少一个类别的方法,包括:
构建识别分类参数,从生理中提取两个声音库,其中一个声音库为cracks(异常生理声音)组成,另外一个假cracks(正常生理声音)组成,提取的每个声音文件为20ms并计算出cracks和假cracks的时域特征值及频域特诊值,然后利用向量机或神经网络算法进行训练,得出识别分类参数;
找出潜在cracks,用20ms的窗沿着肺音信号移动,根据计算阈值找出所有潜在cracks;
潜在cracks特征提取,并将所有潜在cracks的时域特征和频域特征计算出来,
分类模型参数识别,根据将所有潜在cracks计算出来时域特征和频域特征与识别分类参数判断,得出潜在cracks属于cracks和假cracks;
识别所属的类别,根据生理声音平均1秒钟所含cracks的数量来判断所属的类别是正常生理声音类别还是何种异常生理声音类别。
生理声音为肺音作为实施例,具体试验情况如下:
在上海交通大学附属儿童医学中心呼吸内科住院部的患儿为研究对象。小儿肺炎患病率为定性变量,定性变量的样本量计算公式为:
其中:n代表样本量;u表示置信水平下,u统计量;α值通常取0.05,
在该实施例中采用9个采集点如图1和2所示,分别为后背左肩2个点,后背右肩2个点,左侧腋下1个点,右侧腋下1个点,前胸左侧1个点,前胸右侧1个点,面颊一个点。每个点采集9秒肺音,9个点每个点采集9秒数据。
采集对象主要面向住院的0-15岁患儿,采集过程中确保患儿保持安静,对于4岁以下患儿,尽量在睡眠之后采集。采集结束后,记录好患者id与采集时间。
采集过程中将两类数据文件采用随机数命名的方式,并记录文件归属。邀请4位临床专家,分为2组,人工判别同一类肺音,分为正常肺音、哮鸣音、湿罗音及无法辨别,如果两位专家辨别相同,则按判断结果标注;如果判断不同,则邀请另外一组专家辨别,如判断结果仍不同,则该数据标记为无法辨别。
根据采集结果显示,水泡音是偶发性的非连续信号,其持续时间一般小于20ms(如图3所示),其频率一般在100到2000hz范围(如图4所示)。通过对超过15000个水泡音进行统计,发现水泡音的波峰幅值是水泡音平均幅值的1.5倍以上(如图5所示)。
将肺音信号进行小波变换,从而把一个肺音分解成若干不同频率的信号。计算不同频率信号的时域特征值和频域特征值。再把计算出的时域特诊值和频域特诊值作为输入,通过向量机或神经网络算法训练好的数学模型进行分类,可以比较准确的识别肺泡音和正常肺音。
小波变换如图12所示,其中dn是高频信号,an是低频信号;
而构建数学模型如图13所示:
具体过程分为两步:
(1)通过算法及半人工参与,从肺音中提取两个声音库,过程如图6所示,其中一个声音库由图7所示的cracks(水泡音)组成,另外一个库图8所示的假cracks组成。由于cracks基本小于20ms,所以我们提取的每个声音文件为20ms。提出cracks和假cracks的时域特征值及频域特诊值,然后利用向量机进行训练,得出向量机参数。利用该向量机参数可以很好的分辨cracks和假cracks。
(2)先进行信号预处理,比如重采样或识别弱信号,然后对肺音信号进行带通滤波(肺音信号主要在100-2000hz),然后计算智能阈值(每段肺音信号都有自己的阈值,根据该阈值找出潜在cracks),然后用20ms的窗沿着肺音信号移动,找出所有潜在cracks,如中黑色圆圈及红色圆圈所标出的位置,过程如图9所示。提取潜在cracks的时域特征和频域特征,并用向量机进一步判断该潜在cracks是真cracks还是假cracks,最后根据该肺音平均1秒钟所含cracks的数量来判断该肺音是否是湿啰音,其中向量机模型分类结果参考图10所示,而过智能算法分析后的结果展示可参考图11。
最后,对上述试验过程进行验证,采用ibmspssstatistics22.0和sas9.3统计软件对临床数据进行分析。p<0.05认为具有统计学意义,0.05<p<0.1认为有可疑的统计学意义。
肺音分数根据4s检测到的最多水泡音进行判断。当前打分公式如下:
水泡音数量<=6得分100,分数通过字段“ndata”返回。
7<=水泡音数量<=20得分在80到100之间,分数通过字段“ndata”返回。
水泡音数量>20得分小于60,分数通过字段“ndata”返回。
阈值设置及正确率结果如下:
综上所述,上述实施方式并非是本发明的限制性实施方式,凡本领域的技术人员在本发明的实质内容的基础上所进行的修饰或者等效变形,均在本发明的技术范畴。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



