
 商标分类
商标分类  商标转让
商标转让 
音频处理方法、装置和计算机可读存储介质与流程
 2021-01-28 14:01:30|
2021-01-28 14:01:30| 326|
326| 起点商标网
起点商标网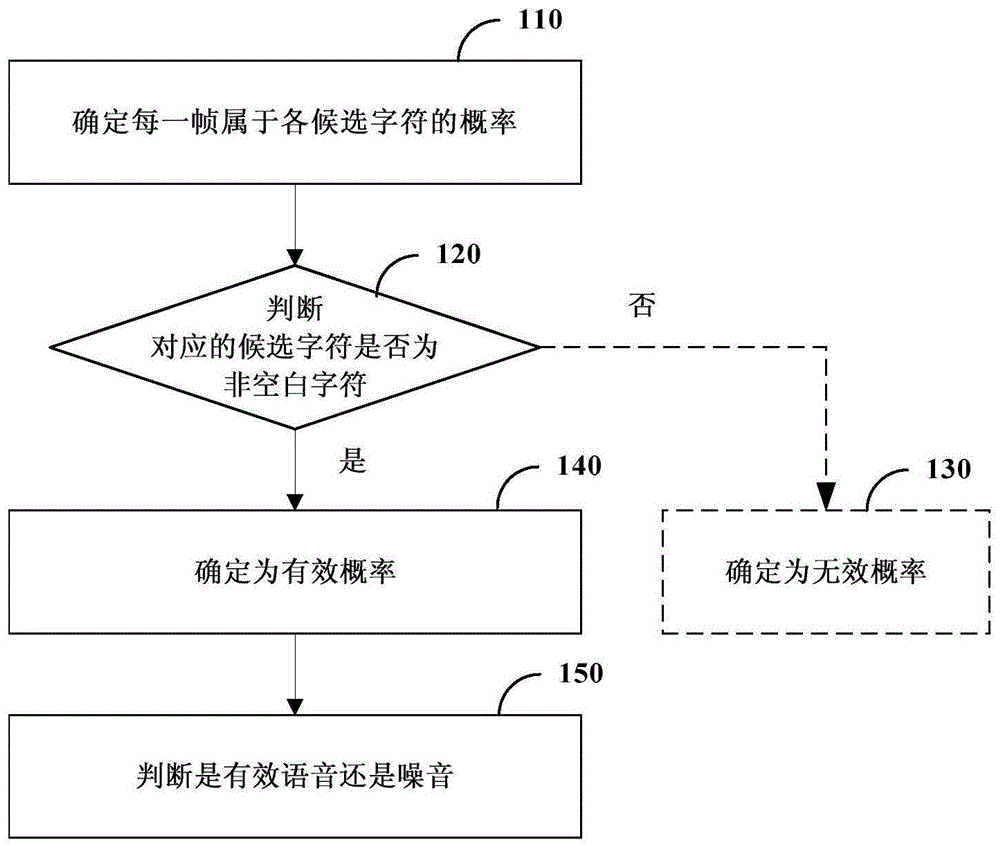
本公开涉及计算机技术领域,特别涉及一种音频处理方法、音频处理装置和计算机可读存储介质。
背景技术:
随着技术的不断发展,人机智能交互技术近年来取得了很大的进步。智能语音交互技术在客服场景的应用越来越多。
然而,用户所在环境中往往存在各种噪音(如周围人说话声、环境噪声、说话人咳嗽等)。噪音经过语音识别后被错误地识别成一段无意义的文本,从而干扰语义理解,导致自然语言处理无法建立起合理的对话流程。因此,噪音对人机智能交互流程的干扰很大。
在相关技术中,一般根据音频信号的能量判定对音频文件是噪音还是有效音。
技术实现要素:
本公开的发明人发现上述相关技术中存在如下问题:由于不同用户的说话风格、声音大小、周围环境差异较大,能量的判定阀值较难设定,从而导致噪音判断的准确率低。
鉴于此,本公开提出了一种音频处理技术方案,能够提高噪音判断的准确率。
根据本公开的一些实施例,提供了一种音频处理方法,包括:根据待处理音频中每一帧的特征信息,利用机器学习模型确定所述每一帧属于各候选字符的概率;判断所述每一帧的最大概率对应的候选字符是空白字符还是非空白字符,所述最大概率为所述每一帧属于各候选字符的概率中的最大值;在所述每一帧的最大概率对应的候选字符为非空白字符的情况下,将所述最大概率确定为有效概率;根据各有效概率,判断所述待处理音频为有效语音还是噪音。
在一些实施例中,所述根据各有效概率,判断所述待处理音频为有效语音还是噪音包括:根据所述各有效概率的加权和,计算所述待处理音频的置信度;根据所述置信度,判断所述待处理音频为有效语音还是噪音。
在一些实施例中,所述根据所述各有效概率的加权和,计算所述待处理音频的置信度包括:根据所述各有效概率的加权和与所述各有效概率的个数,计算所述置信度,所述置信度与所述各有效概率的加权和正相关,与所述各有效概率的个数负相关。
在一些实施例中,在所述待处理音频不存在有效概率的情况下,所述目标音频被判断为噪音。
在一些实施例中,所述特征信息通过滑动窗口的方式对所述每一帧进行短时傅里叶变换得到。
在一些实施例中,所述机器学习模型依次包括卷积神经网络层、循环神经网络层、全连接层和softmax层。
根据本公开的另一些实施例,提供一种音频处理装置,包括:概率确定单元,用于根据待处理音频中每一帧的特征信息,利用机器学习模型确定所述每一帧属于各候选字符的概率;字符判断单元,用于判断所述每一帧的最大概率对应的候选字符是空白字符还是非空白字符,所述最大概率为所述每一帧属于各候选字符的概率中的最大值;有效性确定单元,用于在所述每一帧的最大概率对应的候选字符为非空白字符的情况下,将所述最大概率确定为有效概率;噪音判断单元,用于根据各有效概率,判断所述待处理音频为有效语音还是噪音。
根据本公开的又一些实施例,提供一种音频处理装置,包括:存储器;和耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器装置中的指令,执行上述任一个实施例中的音频处理方法。
根据本公开的再一些实施例,提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述任一个实施例中的音频处理方法。
在上述实施例中,根据每一帧待处理音频对应的候选字符为非空白字符的概率,确定待处理音频的有效性,进而判断待处理音频是否为噪音。这样,基于待处理音频的语义进行噪音判断,能够更好地适应不同的语音环境和不同用户的语音音量,从而提高噪音判断的准确性。
附图说明
构成说明书的一部分的附图描述了本公开的实施例,并且连同说明书一起用于解释本公开的原理。
参照附图,根据下面的详细描述,可以更加清楚地理解本公开,其中:
图1示出本公开的音频处理方法的一些实施例的流程图;
图2示出图1中步骤110的一些实施例的示意图;
图3示出图1中步骤150的一些实施例的流程图;
图4示出本公开的音频处理装置的一些实施例的框图;
图5示出本公开的音频处理的另一些实施例的框图;
图6示出本公开的音频处理的又一些实施例的框图。
具体实施方式
现在将参照附图来详细描述本公开的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本公开的范围。
同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为授权说明书的一部分。
在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
图1示出本公开的音频处理方法的一些实施例的流程图。
如图1所示,该方法包括:步骤110,确定每一帧属于各候选字符的概率;步骤120,判断对应的候选字符是否为非空白字符;步骤140,确定为有效概率;和步骤150,判断是有效语音还是噪音。
在步骤110中,根据待处理音频中每一帧的特征信息,利用机器学习模型确定每一帧属于各候选字符的概率。例如,待处理音频可以为客服场景下8khz采样率、16bit的pcm(pulsecodemodulation,脉冲编码调制)格式的音频文件。
在一些实施例中,待处理音频共有t帧{1,2,......t......t},t为正整数,t为小于t的正整数。待处理视频的特征信息为x={x1,x2,......xt......xt},xt为第t帧的特征信息。
在一些实施例中,候选字符集合中可以包含常见的中文汉字、英文字母、阿拉伯数字、标点符号等非空白字符以及空白字符<blank>。例如,候选字符集合w={w1,w2,......wi......wi},i为正整数,i为小于i的正整数,wi为第i个候选字符。
在一些实施例中,待处理音频中第t帧属于各候选字符的概率分布为pt(w|x)={pt(w1|x),pt(w2|x),......pt(wi|x)......pt(wi|x)},pt(wi|x)为第t帧属于wi的概率。
例如,可以根据应用场景(如电商客服场景、日常交流场景等),采集、配置候选字符集合中的字符。空白字符为无意义字符,表明待处理音频的当前帧无法对应候选字符集合中的任何一个具有实际意义的非空白字符。
在一些实施例中,可以通过图2中的实施例确定每一帧属于各候选字符的概率。
图2示出图1中步骤110的一些实施例的示意图。
如图2所示,可以通过特征提取模块提取待处理音频的特征信息。例如,可以通过滑动窗口的方式提取待处理音频每一帧的特征信息。例如,对滑动窗口内的信号进行短时傅里叶变换得到不同频率处的能量分布信息(spectrogram)作为特征信息。滑动窗口的大小可以为20ms,滑动的步长可以为10ms,得到的特征信息可以为一个81维向量。
在一些实施例中,可以将提取的特征信息输入机器学习模型,确定每一帧属于各候选字符的概率,即每一帧对于候选字符集合中各候选字符的概率分布。例如,机器学习模型可以包含具有双层结构的cnn(convolutionalneuralnetworks,卷积神经网络)、具有单层结构的双向rnn(recurrentneuralnetwork,循环神经网络)、具有单层结构的fc(fullyconnectedlayers,全连接层)和softmax层。cnn可以采取stride处理方式,以减少rnn的计算量。
在一些实施例中,候选字符集合中共有2748个候选字符,则机器学习模型的输出为2748维的向量(其中每一个元素对应一个候选字符的概率)。例如,向量的最后一维可以为<blank>字符的概率。
在一些实施例中,可以将在客服场景中采集的音频文件以及对应的人工标注文本作为训练数据。例如,训练样本可以为从训练数据中抽取的多条长度不等(如1秒到10秒)的标注语音句段。
在一些实施例中,可以采用ctc(connectionisttemporalclassification,连接时序分类)函数作为训练用的损失函数。ctc函数可以使得机器学习模型的输出具有稀疏尖峰特征,即在多数帧的最大概率对应的候选字符为空白字符,只有少数帧的最大概率对应的候选字符为非空白字符。这样,可以提高系统的处理效率。
在一些实施例中,可以采用sortagrad的方式训练机器学习模型,即按照样本长度从小到大的顺序训练首个epoch,从而提高训练的收敛速度。例如,可以经过20个epoch的训练后,选取在验证集上表现最好的模型作为最终的机器学习模型。
在一些实施例中,可以采用顺序批处理归一化(seq-wisebatchnormalization)的方法提高rnn训练的速度和准确度。
在确定了概率分布后,可以继续通过图1中的步骤完成噪音判断。
在步骤120中,判断每一帧的最大概率对应的候选字符是空白字符还是非空白字符。最大概率为每一帧属于各候选字符的概率中的最大值。例如,pt(w1|x),pt(w2|x),......pt(wi|x)......pt(wi|x)中的最大值为第t帧的最大概率。
在最大概率对应的候选字符为空白字符的情况下,执行步骤140。在一些实施例中,在最大概率对应的候选字符为空白字符的情况下,执行步骤130,确定为无效概率。
在步骤130中,将最大概率确定为无效概率。
在步骤140中,将最大概率确定为有效概率。
在步骤150中,根据各有效概率,判断待处理音频为有效语音还是噪音。
在一些实施例中,可以通过图3中的实施例实现步骤150。
图3示出图1中步骤150的一些实施例的流程图。
如图3所示,步骤150包括:步骤1510,计算置信度;和步骤1520,判断是有效语音还是噪音。
在步骤1510中,根据各有效概率的加权和,计算待处理音频的置信度。例如,可以根据各有效概率的加权和与各有效概率的个数,计算置信度。置信度与各有效概率的加权和正相关,与各有效概率的个数负相关。
在一些实施例中,可以通过如下的公式计算置信度:
函数f的定义为
上述公式中,分母为待处理音频中各帧属于各候选字符的最大概率的加权和,最大概率对应空白字符(即有效概率)权值为0,最大概率对应非空白字符(即无效概率)的权值为1;分母为对应非空白字符的最大概率的个数。例如,在待处理音频不存在有效概率的情况下(即分母部分为0),目标音频被判断为噪音(即定义α=0)。
在一些实施例中,也可以根据有效概率对应的非空白字符(如根据具体语义、应用场景、对话中的重要程度等)设置不同的权值(如大于0的权值),从而提高噪音判断的准确性。
在步骤1520中,根据置信度,判断待处理音频为有效语音还是噪音。例如,在上述情况中置信度越大待处理语音被判断为有效语音的可能性越大。因此,可以在置信度大于等于阈值的情况下,判断待处理语音为有效语音;在置信度小于阈值的情况下,判断待处理语音为噪音。
在一些实施例中,在判断结果为有效语音的情况下,可以根据机器学习模型确定的有效概率对应的候选字符,确定待处理音频对应的文本信息。这样,可以同时完成待处理音频的噪音判断和语音识别。
在一些实施例中,计算机可以对确定的文本信息进行语义理解(如自然语言处理)等后续处理,使得计算机能够理解待处理音频的语义。例如,可以基于语义理解进行语音合成后输出语音信号,从而实现人机智能交流。
在一些实施例中,在判断结果为噪音的情况下,可以直接丢弃待处理音频,不进行后续处理。这样,可以有效降低噪音对语义理解、语音合成等后续处理的不利影响,从而提高语音识别的准确性和系统的处理效率。
在上述实施例中,根据每一帧待处理音频对应的候选字符为非空白字符的概率,确定待处理音频的有效性,进而判断待处理音频是否为噪音。这样,基于待处理音频的语义进行噪音判断,能够更好地适应不同的语音环境和不同用户的语音音量,从而提高噪音判断的准确性。
图4示出本公开的音频处理装置的一些实施例的框图。
如图4所示,音频处理装置4包括概率确定单元41、字符判断单元42、有效性确定单元43和噪音判断单元44。
概率确定单元41根据待处理音频中每一帧的特征信息,利用机器学习模型确定每一帧属于各候选字符的概率。例如,特征信息通过滑动窗口的方式对每一帧进行短时傅里叶变换得到。机器学习模型可以依次包括卷积神经网络层、循环神经网络层、全连接层和softmax层。
字符判断单元42判断每一帧的最大概率对应的候选字符是空白字符还是非空白字符。最大概率为每一帧属于各候选字符的概率中的最大值。
在每一帧的最大概率对应的候选字符为非空白字符的情况下,有效性确定单元43将最大概率确定为有效概率。在一些实施例中,在每一帧的最大概率对应的候选字符为空白字符的情况下,有效性确定单元43将最大概率确定为无效概率。
噪音判断单元44根据各有效概率,判断待处理音频为有效语音还是噪音。例如,在待处理音频不存在有效概率的情况下,目标音频被判断为噪音。
在一些实施例中,噪音判断单元44根据各有效概率的加权和,计算待处理音频的置信度。噪音判断单元44根据置信度,判断待处理音频为有效语音还是噪音。例如,噪音判断单元44根据各有效概率的加权和与各有效概率的个数,计算置信度。置信度与各有效概率的加权和正相关,与各有效概率的个数负相关。
在上述实施例中,根据每一帧待处理音频对应的候选字符为非空白字符的概率,确定待处理音频的有效性,进而判断待处理音频是否为噪音。这样,基于待处理音频的语义进行噪音判断,能够更好地适应不同的语音环境和不同用户的语音音量,从而提高噪音判断的准确性。
图5示出本公开的音频处理的另一些实施例的框图。
如图5所示,该实施例的音频处理装置5包括:存储器51以及耦接至该存储器51的处理器52,处理器52被配置为基于存储在存储器51中的指令,执行本公开中任意一个实施例中的音频处理方法。
其中,存储器51例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序(bootloader)、数据库以及其他程序等。
图6示出本公开的音频处理的又一些实施例的框图。
如图6所示,该实施例的音频处理装置6包括:存储器610以及耦接至该存储器610的处理器620,处理器620被配置为基于存储在存储器610中的指令,执行前述任意一个实施例中的音频处理方法。
存储器610例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序(bootloader)以及其他程序等。
音频处理装置6还可以包括输入输出接口630、网络接口640、存储接口650等。这些接口630、640、650以及存储器610和处理器620之间例如可以通过总线660连接。其中,输入输出接口630为显示器、鼠标、键盘、触摸屏等输入输出设备提供连接接口。网络接口640为各种联网设备提供连接接口。存储接口650为sd卡、u盘等外置存储设备提供连接接口。
本领域内的技术人员应当明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用非瞬时性存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
至此,已经详细描述了根据本公开的音频处理方法、音频处理装置和计算机可读存储介质。为了避免遮蔽本公开的构思,没有描述本领域所公知的一些细节。本领域技术人员根据上面的描述,完全可以明白如何实施这里公开的技术方案。
可能以许多方式来实现本公开的方法和系统。例如,可通过软件、硬件、固件或者软件、硬件、固件的任何组合来实现本公开的方法和系统。用于所述方法的步骤的上述顺序仅是为了进行说明,本公开的方法的步骤不限于以上具体描述的顺序,除非以其它方式特别说明。此外,在一些实施例中,还可将本公开实施为记录在记录介质中的程序,这些程序包括用于实现根据本公开的方法的机器可读指令。因而,本公开还覆盖存储用于执行根据本公开的方法的程序的记录介质。
虽然已经通过示例对本公开的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本公开的范围。本领域的技术人员应该理解,可在不脱离本公开的范围和精神的情况下,对以上实施例进行修改。本公开的范围由所附权利要求来限定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



