
 商标分类
商标分类  商标转让
商标转让 
一种语音合成方法及装置与流程
 2021-01-28 14:01:53|
2021-01-28 14:01:53| 285|
285| 起点商标网
起点商标网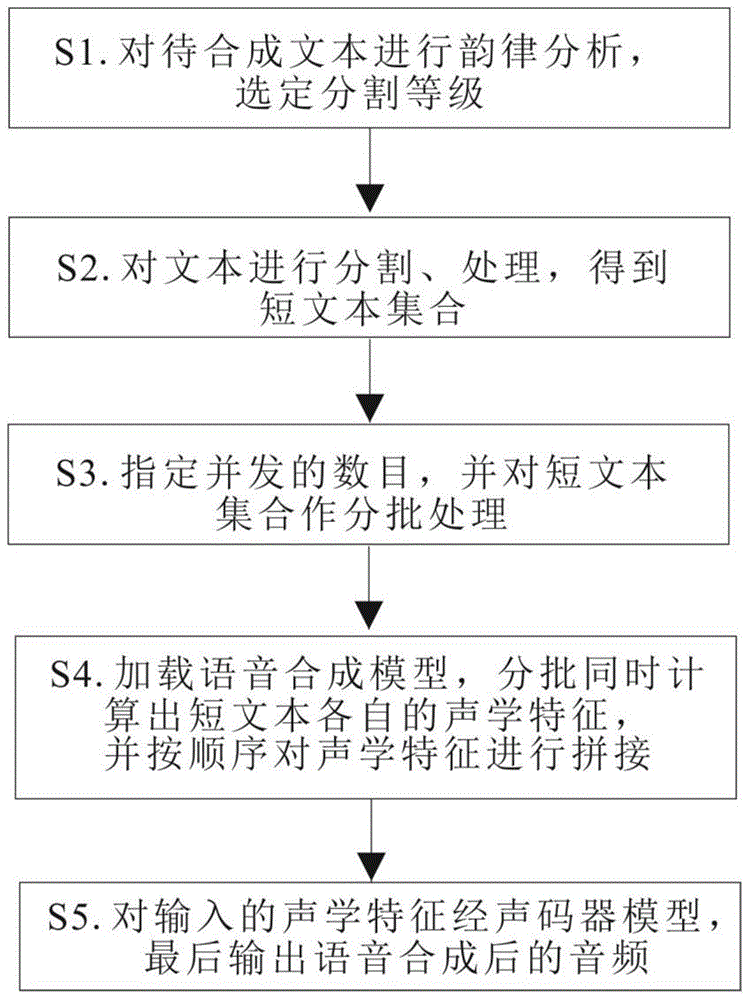
本发明涉及语音合成技术领域,尤其是一种语音合成方法及装置。
背景技术:
语音合成是一种将文本信息转换为语音信息的技术,其过程主要包括:对文本进行处理,如文本预处理、分词、韵律预测、音素标注等,然后训练声学模型,以梅尔频谱或线性频谱作为声学特征、最后利用声码器将频谱合成为声音。
目前以tacotron为代表的端到端(end-to-end)的建模方法成为主流,tacotron是google提出的合并了原先时长模型和声学模型的中段结构,可以连接任何tts前端和后端。tts前端如文本正则、韵律预测、音素转换等,而tts后端主要指声码器。
声码器主要分为三类,第一类是信号处理方法,直接将频谱信号转换为音频信号,如griffin-lim、world声码器,其优点是速度快,但缺点是往往带有机械噪声;第二类是自回归神经网络模型,如wavnet、samplernn、wavrnn声码器等,其优点是自然度高,但缺点是速度较慢;第三类是生成式模型,如最近发展的melgan声码器,其优点是自然度较高,速度快,但缺点是模型难以训练。
针对长文本的语音合成过程常存在一些问题:其一是长文本直接经处理后输入声学模型,其合成过程缓慢,耗时较长,极大的影响了语音合成系统的速度;其二是由于文本过长,声学模型很难准确的合成其声学特征,使得语音合成系统的稳定性和质量受到影响。
技术实现要素:
本发明的目的在于提供一种语音合成方法及装置,提升语音合成系统的稳定性和效率,以期解决背景技术中存在的技术问题:语音合成过程中文本过长时,语音合成速度慢,并且由于文本过长而导致无法准确合成音频的问题。
为了实现上述目的,本发明采用以下技术方案:
一种语音合成方法,包括以下步骤:
对待合成的长文本进行分析,选定分割等级;
对选定分割等级后的所述长文本进行分割、处理,得到短文本集合;
指定并发的数目,并对所述短文本集合作分批处理;
加载语音合成模型,分批同时计算出所述短文本各自的语音的声学特征,并按顺序对所述语音的声学特征进行拼接;
将拼接后的语音的声学特征输入声码器模型,输出语音合成后的音频。
进一步的,所述对待合成的长文本进行分析,选定分割等级,包括:对待合成的长文本进行韵律分析,获得停顿级别标注后,选定停顿标注的级别作为分割等级。
进一步的,所述对选定分割等级后的所述长文本进行分割、处理,得到短文本集合,包括:
按照选定的分割等级,将长文本分割为由短文本组成的集合;对短文本组成的集合进行文本处理;
所述文本处理包括将中文转换为音素、儿化音处理,并且记录短文本所在待合成的长文本中的顺序。
进一步的,所述指定并发的数目,并对所述短文本集合作分批处理,包括:
根据服务器的配置情况以及所处理文本集合的大小,指定并发数,并将短文本集合分批为相应数量的批次,并保证每个批次的短文本数量相近。
进一步的,所述加载语音合成模型,分批同时计算出所述短文本各自的语音的声学特征,并按顺序对所述语音的声学特征进行拼接,包括:
所述语音合成模型采用合并了时长模型和声学模型的中段结构tacotron模型,并且根据不同的应用场景,经过语音数据进行训练。
进一步的,所述将拼接后的语音的声学特征输入声码器模型,输出语音合成后的音频,其中:所述声码器模型为melgan或wavrnn网络结构。
进一步的,所述将拼接后的语音的声学特征输入声码器模型,输出语音合成后的音频,其中:所述声学特征为梅尔频谱特征或线性频谱特征。
为解决直接对长文本进行语音合成时,语音合成系统速度较慢、稳定性较差的问题,本发明还提供了一种语音合成装置,包括:
韵律分析模块,用于对待合成的长文本进行韵律分析,获得分割等级;
文本分割处理模块,用于将获得分割等级后的长文本分割为短文本,得到短文本集合;
分批处理模块,用于对短文本集合作分批处理;
声学特征输出模块,用于加载语音合成模型,分批同时计算出短文本各自的语音的声学特征,并按照短文本在长文本中的顺序进行语音的声学特征的拼接;
声码器模块,用于将输入的拼接后的语音的声学特征输出语音合成后的音频。
进一步的,所述文本分割处理模块还用于按照选定的分割等级,将长文本分割为由短文本组成的集合;对短文本组成的集合进行文本处理;所述文本处理包括将中文转换为音素、儿化音处理,并且记录短文本所在待合成的长文本中的顺序。
进一步的,所述分批处理模块还用于根据服务器的配置情况以及所处理文本集合的大小,指定并发数,并将短文本集合分批为相应数量的批次,并保证每个批次的短文本数量相近。
本发明与现有技术相比具有的有益效果是:
本发明所述的语音合成的方法及装置,通过韵律分析得到长文本的停顿标注,指定分割等级,并根据分割等级对长文本进行分割得到短文本集合,同时记录短文本顺序,将短文本集合经过音素转换、儿化音等处理后,用语音合成模型对经处理后的短文本集合并行输出各自的声学特征,再按照短文本所在长文本中的顺序进行声学特征的拼接,将完整声学特征输出到声码器,最后得到语音合成的音频结果。
在传统语音合成方法的基础上,合理利用了对待合成的长文本以及频谱生成过程的并行处理,有效解决了文本过长时,语音合成速度慢,并且文本过长易导致语音合成模型频谱合成失败的问题,有效提高了语音合成速度,使语音合成系统更高效、稳定、自然。
附图说明
图1是本发明的一种语音合成方法的流程图。
具体实施方式
下面结合实施例对本发明作进一步的描述,所描述的实施例仅仅是本发明一部分实施例,并不是全部的实施例。基于本发明中的实施例,本领域的普通技术人员在没有做出创造性劳动前提下所获得的其他所用实施例,都属于本发明的保护范围。
实施例1:
如图1所示,一种语音合成方法,包括以下步骤:
对待合成的长文本进行分析,选定分割等级;
对选定分割等级后的所述长文本进行分割、处理,得到短文本集合;
指定并发的数目,并对所述短文本集合作分批处理;
加载语音合成模型,分批同时计算出所述短文本各自的语音的声学特征,并按顺序对所述语音的声学特征进行拼接;
将拼接后的语音的声学特征输入声码器模型,输出语音合成后的音频。
所述对待合成的长文本进行分析,选定分割等级,包括:对待合成的长文本进行韵律分析,获得停顿级别标注后,选定停顿标注的级别作为分割等级。
所述对选定分割等级后的所述长文本进行分割、处理,得到短文本集合,包括:
按照选定的分割等级,将长文本分割为由短文本组成的集合;对短文本组成的集合进行文本处理;
所述文本处理包括将中文转换为音素、儿化音处理,并且记录短文本所在待合成的长文本中的顺序。
所述指定并发的数目,并对所述短文本集合作分批处理,包括:
根据服务器的配置情况以及所处理文本集合的大小,指定并发数,并将短文本集合分批为相应数量的批次,并保证每个批次的短文本数量相近。
所述加载语音合成模型,分批同时计算出所述短文本各自的语音的声学特征,并按顺序对所述语音的声学特征进行拼接,包括:
所述语音合成模型采用合并了时长模型和声学模型的中段结构tacotron模型,并且根据不同的应用场景,经过语音数据进行训练。
所述将拼接后的语音的声学特征输入声码器模型,输出语音合成后的音频,其中:所述声码器模型为melgan或wavrnn网络结构。
所述将拼接后的语音的声学特征输入声码器模型,输出语音合成后的音频,其中:所述声学特征为梅尔频谱特征或线性频谱特征。
下面给出具体的实施例方式加以说明:
如图1所示,一种语音合成方法,包括以下步骤;
s1.对待合成的长文本进行韵律分析,选定分割等级;
可选的,对待合成的长文本进行韵律分析,包括对待处理的长文本进行文本规则化、分词、词性标注等,将提取的综合语言学特征输入已训练的韵律预测模型中,获得停顿级别标注,选定分割等级。
举例说明,“某市对体育设施的投资将达2800亿元,其中64.3%将投向基础建设,某市将新建8个体育馆,改建13个旧场馆,加快地铁5号线及八通线的建设,计划建设130公里的公路网;对机场、火车站、电信系统、电视媒体传播系统及辅助设施进行建设和改造,同时还要加快环境整治速度”为例,首先经文本规则化处理,得到“某市对体育设施的投资将达两千八百亿元,其中百分之六十四点三将投向基础建设,某市将新建八个体育场馆,改建十三个旧场馆,加快地铁五号线及八通线的建设,计划建设一百三十公里的公路网;对机场、火车站、电信系统、电视媒体传播系统及辅助设施进行建设和改造,同时还要加快环境整治速度”,其中的阿拉伯数字“2800”、“64.3”、“8”、“13”、“5”、“130”等阿拉伯数字以及发音符号“%”根据情况转换为对应发音汉字;然后经拼音标注以及经韵律预测模型得到停顿级别标注:“mou3shi1#2dui4#1ti3yu4she4shi1de5#1tou2zi1#3jiang1da2#2liang3qian1ba1#1bai3yi4yuan2#4qi2zhong1#2bai3fen1zhi1liu4shi2#1si4dian3san1#2jiang1#2tou2xiang4#1ji1chu3#1jian4she4#3mou3shi1#2jiang1#2xin1jian4#1ba1ge4#1ti3yu4guan3#4gai3jian4#2shi2san1ge4#1jiu4chang3guan3#3jia1kuai4#1di4tie3#1wu3hao4xian4#2ji2#1ba1tong1xian4de5#1jian4she4#4ji4hua4#1jian4she4#2yi4bai3san1shi2#1gong1li3de5#2gong1lu4wang3#4dui4#1ji1chang3#2huo3che1zhan4#3dian4xin4#2xi4tong3#2dian4shi4#2mei2ti3#2chuan2bo1#1xi4tong3#2ji2#1fu3zhu4#1she4shi1#2jin4xing2#1jian4she4#1he2#1gai3zao4#3tong2shi2#2hai2yao4#1jia1kuai4#1huan2jing4#1zheng3zhi4#1su4du4#4”,其中的“#1”、“#2”、“#3”、“#4”分别表示韵律词、韵律短语、韵律短句、韵律停止,本例选定每一个“#4”作为分割等级。
s2.对文本进行分割、处理,得到短文本集合;
具体的,以“#4”标注对文本进行分割得到短文本集合:{1:“mou3shi1#2dui4#1ti3yu4she4shi1de5#1tou2zi1#3jiang1da2#2liang3qian1ba1#1bai3yi4yuan2#4”,2:“qi2zhong1#2bai3fen1zhi1liu4shi2#1si4dian3san1#2jiang1#2tou2xiang4#1ji1chu3#1jian4she4#3mou3shi1#2jiang1#2xin1jian4#1ba1ge4#1ti3yu4guan3#4”,3:“gai3jian4#2shi2san1ge4#1jiu4chang3guan3#3jia1kuai4#1di4tie3#1wu3hao4xian4#2ji2#1ba1tong1xian4de5#1jian4she4#4”,4:“ji4hua4#1jian4she4#2yi4bai3san1shi2#1gong1li3de5#2gong1lu4wang3#4”,5:“dui4#1ji1chang3#2huo3che1zhan4#3dian4xin4#2xi4tong3#2dian4shi4#2mei2ti3#2chuan2bo1#1xi4tong3#2ji2#1fu3zhu4#1she4shi1#2jin4xing2#1jian4she4#1he2#1gai3zao4#3tong2shi2#2hai2yao4#1jia1kuai4#1huan2jing4#1zheng3zhi4#1su4du4#4”}。
本实施例中,对文本进行处理包括拼音转音素、儿化音处理等,具体的,经文本处理后得到:{1:“mou3shi1#2duei4#1ti3yu4she4shide5#1tou2zii1#3jiang1da2#2liang3qian1ba1#1bai3i4van2#4”,2:“qi2zhong1#2bai3fen1zhiii1liou4shiii2#1sii4dian3san1#2jiang1#2tou2xiang4#1ji1chu3#1jian4she4#3mou3shi1#2jiang1#2xin1jian4#1ba1ge4#1ao4vn4chang3guan3#4”,3:“gai3jian4#2shiii2san1ge4#1jiou4chang3guan3#3jia1kuai4#1di4tie3#1u3hao4xian4#2ji2#1ba1tong1xian4de5#1jian4she4#4”,4:“ji4hua4#1jian4she4#2i4bai3san1shiii2#1gong1li3de5#2gong1lu4uang3#4“,5:”duei4#1ji1chang3#2huo3che1zhan4#3dian4xin4#2xi4tong3#2dian4shiii4#2mei2ti3#2chuan2bo1#1xi4tong3#2ao4vn4cuen1#3ji2#1fu3zhu4#1she4shiii1#2jin4xing2#1jian4she4#1he2#1gai3zao4#3tong2shiii2#2hai2iao4#1jia1kuai4#1huan2jing4#1zheng3zhiii4#1su4du4#4”}
s3.指定并发的数目,并对短文本集合作分批处理;
根据服务器的配置情况以及所处理文本集合的大小,指定并发数,并将短文本集合分为合适大小、合适数目的各个批次。
具体的,指定并发数为2,将短文本集合分为2个批次,序号分别为{1,2,3},{4,5}。
s4.加载语音合成模型,分批同时计算出短文本各自的声学特征,并按顺序对声学特征进行拼接;
经过语音合成模型同时计算各个批次的短文本集合,输出各批次的声学特征,待所有批次计算完毕,按照短文本在长文本中的切割顺序进行声学特征的拼接,最后输出完整的声学特征;语音合成模型采用合并了时长模型和声学模型的中段结构tacotron模型,并且根据不同的应用场景,经过大量语音数据进行训练。
具体的,2个批次{1,2,3}与{4,5}的声学特征计算同时进行,待所有批次计算完毕,按照序号进行声学特征的拼接,最后输出完整的声学特征。
s5.对输入的声学特征经声码器模型,最后输出语音合成后的音频。
可以理解的是,将拼接后的完整声学特征经过预训练的声码器模型输出得到音频,可选的,所述步骤s5包括但不限于melgan、wavrnn等网络结构,旨在建立声学特征与音频特征之间的映射,在此不做限制。
基于上述技术方案,本发明实施例还提出一种语音合成并行处理装置,包括韵律分析模块,用于对长文本进行韵律分析,获得停顿标注;
可选的,所述韵律分析模块还用于对待合成文本进行韵律分析,获得停顿级别标注后,选定停顿标注的级别作为分割等级。
文本分割处理模块,用于将长文本分割为短文本,得到短文本集合;
可理解的是,所述文本分割处理模块还用于按照停顿级别标注结果以及选定的分割等级,对文本进行分割,将长文本分割为由短文本组成的集合,对短文本集合进行文本处理,包括将中文转换为音素、儿化音处理等,并且记录短文本所在长文本中的顺序。
声学特征输出模块,用于对经处理后的短文本集合并行处理,生成各自的声学特征,并按照短文本在长文本中的顺序进行声学特征的拼接,最后输出完整声学特征;
可选的,所述声学特征输出模块还用于对短文本集合进行文本处理,包括将拼音转换为音素、儿化音处理等,将经过文本处理的结果,经过语音合成模型并行输出各自的声学特征,语音合成模型为合并了时长模型和声学模型的中段结构tacotron模型,并且根据不同的应用场景,经过大量语音数据进行训练,并按照短文本在长文本中的顺序进行声学特征的拼接,最后输出完整声学特征。
分批处理模块,用于对短文本集合作分批处理;
可选的,所述分批处理模块还用于根据服务器的配置情况以及所处理文本集合的大小,指定并发数,并将短文本集合分为合适大小、合适数目的各个批次;即根据服务器的配置情况以及所处理文本集合的大小,指定并发数,并将短文本集合分批为相应数量的批次,并保证每个批次的短文本数量相近。
声学特征输出模块,用于加载语音合成模型,分批同时计算出短文本各自的声学特征,并按照短文本在长文本中的顺序进行声学特征的拼接,最后输出完整声学特征;
可选的,声学特征输出模块还用于利用语音合成模型同时计算各个批次的短文本集合,输出各批次的声学特征,待所有批次计算完毕,按照短文本在长文本中的切割顺序进行声学特征的拼接,最后输出完整的声学特征。
声码器模块,用于对输入的声学特征输出语音合成后的音频;
可选的,所述声码器模型可使用melgan、wavrnn等网络结构,旨在建立声学特征与音频特征之间的映射,在此不做限制。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



