
 商标分类
商标分类  商标转让
商标转让 
一种语音纠正融合技术的制作方法
 2021-01-28 14:01:29|
2021-01-28 14:01:29| 243|
243| 起点商标网
起点商标网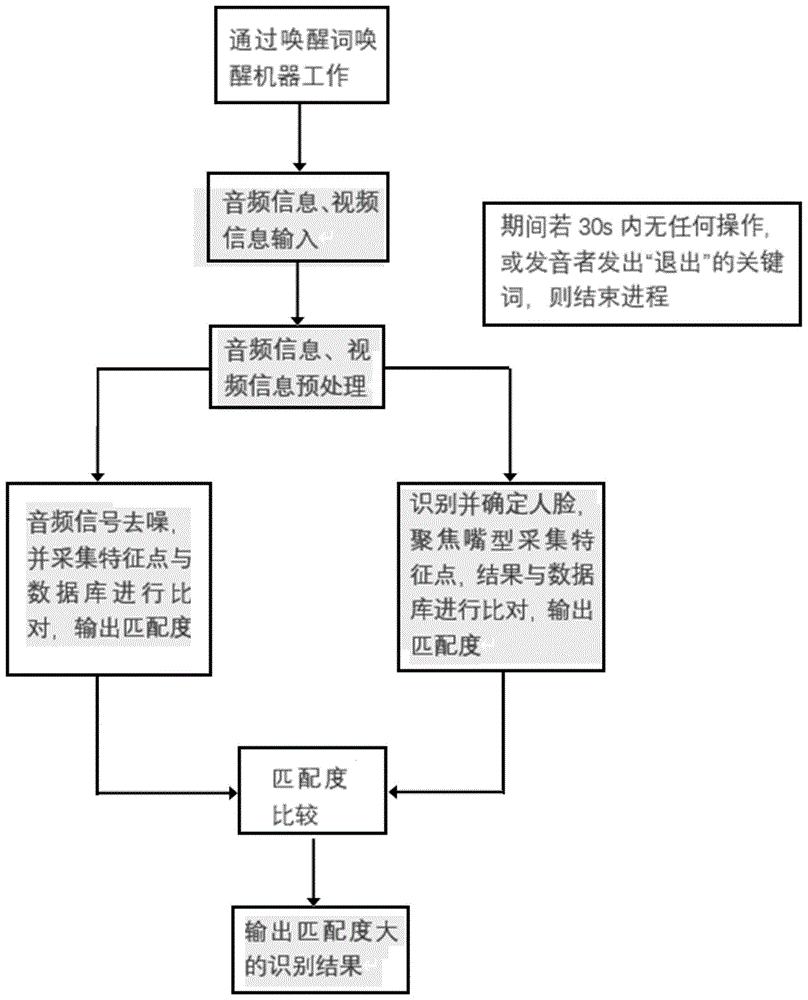
本发明属于语音识别技术领域,具体来说是一种语音纠正融合技术。
背景技术:
语音识别技术随着计算机和相关软硬件技术的发展,已越来越多的应用在各个领域,其识别率也在不断的提高。在环境安静、发音标准等特定条件下,目前应用在语音识别输入文字系统的识别率已经达到95%以上。但如果在车上或外界噪声干扰比较大、发音不标准的情况下,其识别率将大打折扣,以至于无法达到实用目的。若能采用其它方法来辅助判断以提高其语音识别的准确率,那么语音识别的实用性将显著提高。
人类的语言认知过程是一个多通道的感知过程。在人与人日常交流的过程中,通过声音来感知他人讲话的内容,在喧闹的环境或对方发音模糊不清时,还需要眼睛观察其口型,表情等的变化,才能准确地理解对方所讲的内容。现行的语音识别系统忽略了语言感知的视觉特性这一面,仅仅利用了单一的听觉特性,使得现有的语音识别系统在噪声环境或多话者条件下,其识别率都显著下降,降低了语音识别的实用性,应用范围也受限制。
技术实现要素:
1.发明要解决的技术问题
本发明的目的在于解决现有的语音识别技术识别不准确的问题。
2.技术方案
为达到上述目的,本发明提供的技术方案为:
本发明的一种语音纠正融合技术,同时采集发音者的声音数据和视频数据,对视频数据中采集的嘴型进行标点预处理,用字母标注嘴唇内部的六个点位,对预处理之后的图像进行测量并通过六个点位的位置计算嘴唇变化角度,将声音数据与音频数据库进行对比得到语音识别结果,嘴唇变化角度与嘴型数据库进行对比得到唇语识别结果;当语音识别结果和唇语识别结果匹配程度相同,则优先选择语音识别结果;当语音识别结果和唇语识别结果匹配程度不同,则优先选择唇语识别结果。
优选的,所述六个点位分别为嘴唇内侧两边嘴角处为a、f点,上嘴唇的
优选的,还选取点b、点g的连线中点为d、选取点c、点h连线中点为e,测量角∠caf和角∠baf的大小、线段af的长度和线段de的长度。
优选的,计算评价函数判断语音,具体评价函数为
pre=k*(p*angle(a,b)+q*line(laf,lde));
其中,k、p、q为各代价函数的权重系数,p、q为0.5,k为不同区域的发音系数,angle(a,b)为嘴唇夹角的代价子函数,line(laf,lde)为嘴唇张开程度的代价子函数。
优选的,在采集发音者的画面时,发音者的脸部需正对摄像头,摄像头先拍摄人脸并识别后开始拍摄发音者嘴唇位置。
优选的,在进行语音识别的过程中,需要在存储数据库中设置两个临时存储区域,用于存储音频信息和视频信息,两个临时存储区域主要存储音频流以及时间戳,在30秒内无明显音频输入则对两块区域进行保存再清空、或直接清空。
优选的,语音识别前需要进行语音唤醒,主要为通过特定的语音关键词进行唤醒,唤醒成功后开始进行语音接收和语音处理,对音频信息主要是进行去噪和特征点采集,然后将预处理之后的结果音频与数据库中的标准音频进行匹配,并输出匹配程度p1;对视频信息为先进行人脸识别,再追踪嘴唇部分,分帧提取10张图进行比对,计算所得的10个pre数值进行平均,求出结果pra,将pra与数据库中的pre值进行比对,筛选出对应范围内的值,并输出与数据库的匹配程度p2,最后比较p1、p2大小,输出对应识别的结果。
优选的,所述音频数据库存储有预先设置好的方言发音的嘴型数据。
3.有益效果
采用本发明提供的技术方案,与现有技术相比,具有如下有益效果:
本发明的一种语音纠正融合技术,同时采集发音者的声音数据和视频数据,对视频数据中采集的嘴型进行标点预处理,用字母标注嘴唇内部的六个点位,对预处理之后的图像进行测量并通过六个点位的位置计算嘴唇变化角度,将声音数据与音频数据库进行对比得到语音识别结果,嘴唇变化角度与嘴型数据库进行对比得到唇语识别结果;当语音识别结果和唇语识别结果匹配程度相同,则优先选择语音识别结果;当语音识别结果和唇语识别结果匹配程度不同,则优先选择唇语识别结果。在语音识别的基础上,加入了唇语识别,可以有效的去除口音对语音识别的影响,采用图像识别中的唇语识别来消除声音的影响,通过嘴唇来识别发音者所讲的话,更加准确。
附图说明
图1为本发明的流程图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述,附图中给出了本发明的若干实施例,但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例,相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。
需要说明的是,当元件被称为“固设于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件;当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件;本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同;本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明;本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
实施例1
参照附图1,本实施例的一种语音纠正融合技术,同时采集发音者的声音数据和视频数据,对视频数据中采集的嘴型进行标点预处理,用字母标注嘴唇内部的六个点位,对预处理之后的图像进行测量并通过六个点位的位置计算嘴唇变化角度,将声音数据与音频数据库进行对比得到语音识别结果,嘴唇变化角度与嘴型数据库进行对比得到唇语识别结果;当语音识别结果和唇语识别结果匹配程度相同,则优先选择语音识别结果;当语音识别结果和唇语识别结果匹配程度不同,则优先选择唇语识别结果。
所述六个点位分别为嘴唇内侧两边嘴角处为a、f点,上嘴唇的
还选取点b、点g的连线中点为d、选取点c、点h连线中点为e,测量角∠caf和角∠baf的大小、线段af的长度和线段de的长度。
计算评价函数判断语音,具体评价函数为
pre=k*(p*angle(a,b)+q*line(laf,lde));
其中,k、p、q为各代价函数的权重系数,p、q为0.5,k为不同区域的发音系数,angle(a,b)为嘴唇夹角的代价子函数,line(laf,lde)为嘴唇张开程度的代价子函数。
在中文拼音中,共有63个拼音字母,声母有23个,韵母有24个,整体认读音节有16个。大多地区方言是由于平舌或卷舌、前后鼻音、个别字母难区分等,以此使得地方不同人在讲普通话时,与标准普通话出现较大差异,故而可以通过系数k来进行一定的区域划分。k系数在第一次训练时,由于只采集了一个地区的发音状况,故初步赋值为1,在进行其他区域的训练时,通过调整k的值来保证与已建立好的标准数据库之间的差值不大。例如l与n,在标准情况下的嘴唇张角是有较大区别,但在一些地区的发音相近,嘴型的变化也比较小,此时通过将k值扩大或缩小一定量,来保证在不影响其他值的情况下,区分l与n的不同。
在采集发音者的画面时,发音者的脸部需正对摄像头,摄像头先拍摄人脸并识别后开始拍摄发音者嘴唇位置。
在进行语音识别的过程中,需要在存储数据库中设置两个临时存储区域,用于存储音频信息和视频信息,两个临时存储区域主要存储音频流以及时间戳,在30秒内无明显音频输入则对两块区域进行保存再清空、或直接清空。
语音识别前需要进行语音唤醒,主要为通过特定的语音关键词进行唤醒,唤醒成功后开始进行语音接收和语音处理,对音频信息主要是进行去噪和特征点采集,然后将预处理之后的结果音频与数据库中的标准音频进行匹配,并输出匹配程度p1;对视频信息为先进行人脸识别,再追踪嘴唇部分,分帧提取10张图进行比对,计算所得的10个pre数值进行平均,求出结果pra,将pra与数据库中的pre值进行比对,筛选出对应范围内的值,并输出与数据库的匹配程度p2,最后比较p1、p2大小,输出对应识别的结果。
所述音频数据库存储有预先设置好的方言发音的嘴型数据。
若结果仍无匹配数据,则记录当前结果,并提示发音者重新发音或者选择退出。如果继续发音并匹配成功,则将pra值进行保存,并对原数据库进行一定整改。
为提高机器的识别效率,在进行一定识别周期后,通过新的评价函数(如公式2所示),对数据库进行一次较大整改。
n_pre=k*(p*angle(p,q)+q*line(laf,lde)+m*time(t))(2)
t为权重系数更新时间周期。m为周期代价函数的权重系数,决定周期代价重要性。time(t)为整理周期代价函数。
由于识别过程会出现一些不可避免问题,针对某一些状况,进行一下分析处理,以此避免机器宕机。
情况一:语音识别、唇语识别匹配程度相同,则优先选择语音识别结果,如果选择语音识别的结果不对,则之后再将匹配程度相同的唇语识别结果输出;
情况二:在匹配过程中,会出现由于匹配一直失败,缓冲区一直被增加占用,使得缓冲区溢出。为保证机器不会宕机,可以设置识别匹配次数,若识别一定次数,仍然无法匹配成功,则生成相关日志文件,并清空缓冲区,重新进行新一轮的识别;
情况三:为加强机器工作效率,会进行联网识别,保存一些数据,为保证在网络中断的情况下,机器仍可以进行正常的运行,机器需要有一定量的本地存储空间。同时,由于不断生成日志文件,故机器需要在一定时间周期、或者一定空间限制下,对日志文件进行合并整理,及时清空不必要的文件。
以上所述实施例仅表达了本发明的某种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制;应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围;因此,本发明专利的保护范围应以所附权利要求为准。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



