
 商标分类
商标分类  商标转让
商标转让 
一种基于神经网络模型的音乐创作系统的制作方法
 2021-01-28 14:01:09|
2021-01-28 14:01:09| 355|
355| 起点商标网
起点商标网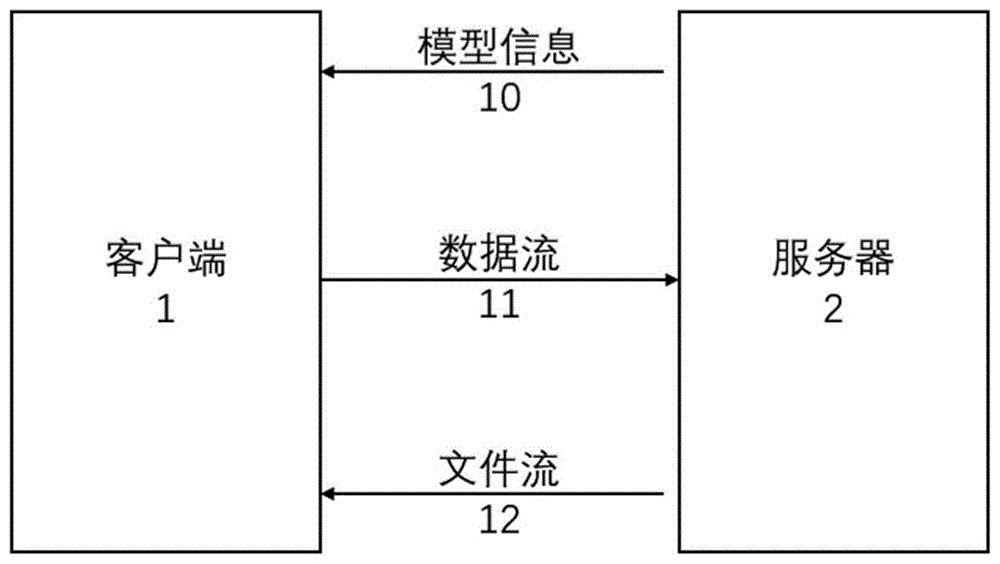
本发明涉及音乐及计算机信息处理领域,特别设计一种基于神经网络模型的音乐创作系统。
背景技术:
目前深度神经网络的应用较为广泛,尤其涉及一些关于艺术创作的应用,出现了一些可以帮助人完成画作或者编排乐谱的程序,虽然与艺术家所创作的艺术品存在一些差距,但展现了机器学习的潜力,博得很多技术人员甚至非技术人员的关注,然而对于想要尝试使用深度神经网络进行创作的非技术人员,搭建环境运行脚本等必需的工作对他们来说陌生而困难,需要一个即开即用的创作系统帮助他们使用这些前沿的技术。
作为现有技术,“magenta”是谷歌研发团队基于“tensorflow”机器学习库搭建的集成各种音乐和绘画创作的深度神经网络模型的开源项目,旨在推动机器学习在各种音乐和绘画创作领域的探索和应用。“magenta”提供了多种用于音乐创作的深度神经网络模型,可以用来创作不同风格的音乐,例如根据输入的一小段旋律创作出指定时长的乐章。这些模型要求的输入数据类型不尽相同,但是有一个共同特点:由表示钢琴琴键的音高音长和起止时间的代码组成的,然而非技术人员对这些模型要求输入的数据类型并不熟悉,只能体验现有以某一个模型作为核心功能开发的软件,没有自主选择的余地。
midi(乐器数字化接口)是一种能够通过电子设备自动地重放声音或音乐的音乐标准格式,它用音符的数字控制信号来记录音乐。使用midi标准存储在电脑里的音乐文件相较于音频类型的音乐文件,占用存储空间更小且更容易被电脑识别和处理。
技术实现要素:
有鉴于此,本发明所要解决的技术问题在于提供一种基于神经网络模型的音乐创作系统,集成以magenta开源python库为例的多种基于深度神经网络的模型,提供可视化的操作界面,为用户提供模型列表和模型信息方便用户选择,将用户在虚拟或实体琴键上的输入转化为用户选择模型支持的数据,再将模型运算输出的结果转码为可直接播放的音频文件,方便非计算机专业的用户利用各种深度神经网络模型进行各种风格的音乐创作。
为了实现上述发明目的,本发明的主要技术方案为:
一种基于神经网络模型的音乐创作系统,包括:服务器和设置于个人电脑终端的web客户端;其中:
所述web客户端,用于为用户提供可视化音乐创作界面和方法,包含:输入选择装置,用于选择乐曲的输入方式,用户可以在外接midi设备和虚拟键盘之间选择弹奏的方式;输入装置,用于接收用户在虚拟键盘或者midi设备上的输入并将音符转码为音符数据;模型选择装置,用于选择不同风格或功能的基于深度神经网络的音乐创作模型;录制装置,用于生成含有用户输入音符数据的音符序列;编码装置,用于将音符序列编码为二进制音符序列数据,并建立请求发送给服务器;播放模块,用于播放服务器返回的音频文件。
所述服务器,用于将收到的用户创作的旋律输入对应的基于深度神经网络的音乐创作模型运算得出结果,包括:转码装置,用于接收客户端发送的二进制音符序列数据并转码为模型支持的数据结构;模型管理装置和模型库,用于管理和更新基于深度神经网络的音乐创作模型;执行装置,用于将转码后的数据结构输入音乐创作模型进行运算;转码装置,用于将音乐创作模型运算输出的数据转码为wav格式的音频文件通过文件流发送给客户端。
利用本发明的基于神经网络模型的音乐创作系统进行音乐创作包含以下步骤:根据用户选择音乐创作模型提示用户输入音乐旋律的限制条件;录制用户输入,暂时存放在web客户端中等待用户确认;将录制的音符序列转码为二进制数据串,并与用户选择的音乐创作模型编号打包发送给服务器;服务器将接收到的数据串转码为用户选择音乐创作模型所支持的数据结构;将转码后的数据输入模型运算并得出输出的数据;将输出的数据转码为wav格式的音频文件发送给客户端。
本发明区别于现有技术的优点为:
相较于magenta开源项目,本发明利用web客户端和服务器提供给用户可视化界面,用户不用下载脚本文件和搭建脚本环境即可使用神经网络模型进行音乐创作,方便非相关专业的人员体验前沿的技术。
相较于其他利用magenta开源项目开发的web应用,本系统集成了magenta全部而非某个或几个与音乐创作有关的神经网络模型,并附有详细的介绍和使用说明,用户可以对这些模型有更清晰的对比和认识。
附图说明
图1是本发明所述音乐创作系统的总体结构示意图;
图2是本发明所述客户端的详细结构示意图;
图3是本发明所述服务器的详细结构示意图;
图4是本发明音乐创作的一种实施流程图;
图5是本发明所述客户端的外观示例图。
具体实施方式
下面通过具体实施例和附图对本发明做进一步详细说明。
图1为本发明所述音乐创作系统的总体结构示意图。参见图1,本发明提出的一种基于神经网络模型的音乐创作系统包括:客户端1、服务器2、模型信息10、数据流11和文件流12;其中:
所述客户端1为在浏览器上可访问的前端网页,用于接受服务器2发送的模型信息10,向用户展示可视化界面并收集用户输入的旋律信息,将用户输入的旋律信息打包成数据流11发送给所述服务器,并接受服务器2返回的含有可播放音频文件的文件流12。
所述服务器2为所述基于神经网络模型的音乐创作系统的服务器,设置在互联网上,用于向客户端1发送模型信息10,接收并处理客户端1发送的数据流11,并返回含有可播放音频文件的文件流12。
图2为本发明所述客户端的详细结构示意图。参见图2,该客户端1包括输入选择模块110、输入模块99、模型选择模块111、录制模块112、编码模块113和播放模块114;其中:
所述输入选择模块110为一个下拉菜单,用户可使用该模块对自己在输入模块99输入的方式进行选择。
所述输入模块99包括:屏幕琴键100,用于接收用户在屏幕上使用鼠标点击虚拟琴键的信息;电脑键盘101,用于接受用户在电脑键盘上敲击与屏幕琴键一一映射的键位信息;midi键盘102,用于接受用户在外接midi设备上弹奏的音符信息。用户可以选取三者中的任意一种输入方式进行旋律的创作。
所述模型选择模块111,用于接收服务器2发送的模型信息10并将其展示给用户进行选择,用户可根据各模型所展示的功能和创作风格选择自己需要的神经网络模型。
所述录制模块112用于将用户实时输入的旋律信息录制为一个数组,发送给编码模块113编码为二进制数据包并通过数据流11发送给服务器2。
所述播放模块114用于接收通过文件流12接收到服务器2返回的可播放音频文件,并展示音频播放器供用户播放或下载。
图3为本发明所述服务器的详细结构示意图。参见图3,该服务器2包括转码模块201和203、执行模块202、模型库210和模型管理模块211;其中:
所述转码模块201用于将客户端1通过数据流11发送的二进制数据包解码并封装成一个音符序列实体类,然后转码为神经网络模型支持的数据结构,如midi文件或者protobuf数据规范的音符序列,数据结构类型取决于模型库210中对每个神经网络模型标注的数据类型。
所述模型库210集成所有可用的神经网络模型文件的信息,存储格式如下式(1):
id+模型名+功能介绍+输入要求+输入数据类型+输出数据类型+模型文件路径(1)
其中,所述id为一个八位数字,互不重复,用于作为各模型的唯一标识,所述输入要求为用户创作的条件,包括用户输入旋律的时间长度和节拍速度,所述功能介绍为神经网络模型根据用户输入进行创作的类型,如将单音旋律扩展为复音旋律或将钢琴输入扩展为多个乐器和谐结合的管弦乐,所述输入数据类型和输出数据类型为神经网络模型支持输入输出的数据结构,如midi文件或者protobuf数据规范的音符序列,所述模型文件路径用于向程序提供模型文件在服务器上的相对路径。
所述模型管理模块211为后台管理员对模型库210进行操作的装置,所述操作包括:增加更新或删除神经网络模型,为神经网络模型标注输入要求、功能和支持的数据类型,将模型信息10发送至客户端展示并供用户选择。
所述执行模块202用于将用转码后的旋律数据输入到用户选择的神经网络模型进行运算,将输出的数据经过转码模块203转码为可播放音频文件。所述输出数据可以是midi文件、protobuf数据规范的音符序列或可播放音频文件,转码模块203负责将前两种情况下的输出数据渲染为可播放音频文件,然后通过文件流12返回给客户端1。
图4为本发明采用所述音乐创作系统进行音乐创作的一种实施流程图。实施流程开始于用户访问url进入页面并选择了输入方式和神经网络模型的操作之后,结束于服务器2返回给客户端1可播放音频文件的操作之前。参见图4,该流程包括:
步骤31、根据用户选择模型提示用户输入的限制条件。首先将模型库210中模型名和功能介绍显示在客户端上供用户参考和选择,在用户选择神经网络模型后将输入要求显示在虚拟钢琴上方。
步骤32、录制用户输入。用户点击“开始”后,客户端1将以数组的形式将用户输入的音符数据入栈,记录每个音符的起止时间、音高、乐器种类和力度。需要特别阐述的是,在实现录音功能时,开始后的每两小节如果没有获得任何输入,则重置录制的开始时间,相当于重启录音模组,直到用户开始输入,则从用户输入的这两个小节开始入栈,用户可以有充足的准备时间适应节拍节奏而不必担心录制出的音乐开头部分存在大片的空白。用户在点击“停止”按钮后,包含所有在此时间段内输入的音符数组完成了入栈,等待用户的下一步操作。如果用户点击“保存”按钮,则进行下一步骤,即步骤33。
步骤33、向服务器2发送录制片段的数据串和用户选择的模型。所述录制片段的数据串存储格式如下式(2)
总持续时间+节拍速度+音符序列(2)
其中,所述总持续时间为从第一个音符所在小节的起始时间到最后一个音符所在小节结束时间中间的时间长度,所述节拍速度为每分钟节拍个数,所述音符序列为存有各音符数据的数组,音符数据的存储格式如下式(3)
开始时间+结束时间+音高+乐器种类+力度(3)
步骤34、服务器2将接收到的数据串转码为用户选择模型支持的数据结构。按照用户选择的神经网络模型的id去数据库中检索对应神经网络模型的输入数据类型,将收到的录制片段的数据串转码为该数据类型,转码使用magenta开源项目中提供的note_sequence_io工具类,同时按照用户选择的神经网络模型的id去数据库中检索对应模型的模型文件路径,准备进入下一步骤。
步骤35、将转码后的数据输入模型运算得到输出文件。调用对应路径下模型文件对该神经网络模型支持的转码后的数据进行运算,得到输出数据为该神经网络模型处理后的midi文件、音符序列或者可播放音频文件。
步骤36、将输出文件转化为可播放音频文件。按照用户选择的模型的id去数据库中检索对应神经网络模型的输出数据类型,如果非可播放音频文件,则根据输出数据类型将输出的数据转码为可播放音频文件。转码使用magenta开源项目中提供的note_sequence_io工具类。
此后,服务器2会将可播放音频文件发送给客户端1,客户端1中的播放模块114展示音频播放器供用户播放或下载,完成一次利用神经网络模型的音乐创作。
图5是本发明所述客户端1的外观示例图,具体地,是客户端1在用户选择好输入方式和神经网络模型后展示的界面示例图,用以展示本系统的一种具体实施效果,参见图5,该界面包括节拍计数器401、提示模块402、节拍速度模块403、录制/停止按钮404、音符可视化器405、回放按钮408、保存按钮409、音量模块410、虚拟琴键模块411、音调上调按钮412、音调下调按钮413和音频组件414;其中:
所述节拍计数器401,用于显示当前节拍数,结合节拍器的声音提示用户节拍信息,方便用户在创作旋律时能够保持速度一致并且与设置的节拍数相符。
所述提示模块402,用于显示当前用户可以进行的以及建议用户进行的操作,例如:在开始输入音符前提示用户所选择模块的功能和对输入的要求,输入时提示用户正在录制中,停止录制后提示用户可以回放、重新录制或者保存提交。
所述节拍速度模块403,用于让用户设置节拍速度,输入数字为每分钟节拍数。
所述录制/停止按钮404,用于开始或停止录制,初始状态为不可点击状态,在所有组件加载完毕后显示“record”表示可以开始录制,用户点击后按钮文字变为“stop”,点击即可停止录制。
所述音符可视化器405,用于直观显示用户输入音符的信息,包括:音符线406和时间线407,其中:
所述音符线406为用户输入音符时实时地出现在音符可视化器405中的横线,音符线406垂直位置的高低由用户输入音符的音调高低决定,左端点的水平位置由音符的开始时间在每两小节中的时间先后决定,长短由音符持续时间长短决定;
所述时间线407为提示用户当前时间的竖线,从音符可视化器405左端平移到右端,每两小节重复一次。
用户按下的音符会在当前的时间线407上开始绘制,在用户抬起后在当前时间线407上停止绘制,形成一个音符线406.
所述回放按钮408用于回放用户输入的旋律,在用户停止录制前为不可用状态,点击“stop”按钮后变为可用状态,用户点击后即可播放刚才输入的旋律。
所述保存按钮409用于保存用户输入的旋律并提交,对应图4所述的步骤33。
当接收到服务器2返回的音频文件后,在页面上展示所述音频组件414,用于播放、调整音量和下载神经网络模型输出的音乐。
所述音量模块410用于分别调整用户输入时的虚拟琴键的音量、回放音量和节拍计数器401的节拍音量,用户可上下拖动滑块来调整对应的音量大小。
所述虚拟琴键模块411用于用户使用鼠标点击或者敲击键盘来弹奏虚拟钢琴411,用户在键盘上敲击虚拟琴键上标注的对应的字母可以实现对虚拟钢琴411的演奏。
所述音调上调按钮412和音调下调按钮413用于上调和下调虚拟钢琴所对应的音程,调整单位是一个八度。点击音调上调按钮412或音调下调按钮413,虚拟琴键每个琴键所对应的音高会上调或下调一个八度,由此,24个虚拟琴键可以映射到钢琴上所有88个琴键。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



