
 商标分类
商标分类  商标转让
商标转让 
基于多特征流结构深度神经网络的残留回声抑制方法与流程
 2021-01-28 14:01:44|
2021-01-28 14:01:44| 254|
254| 起点商标网
起点商标网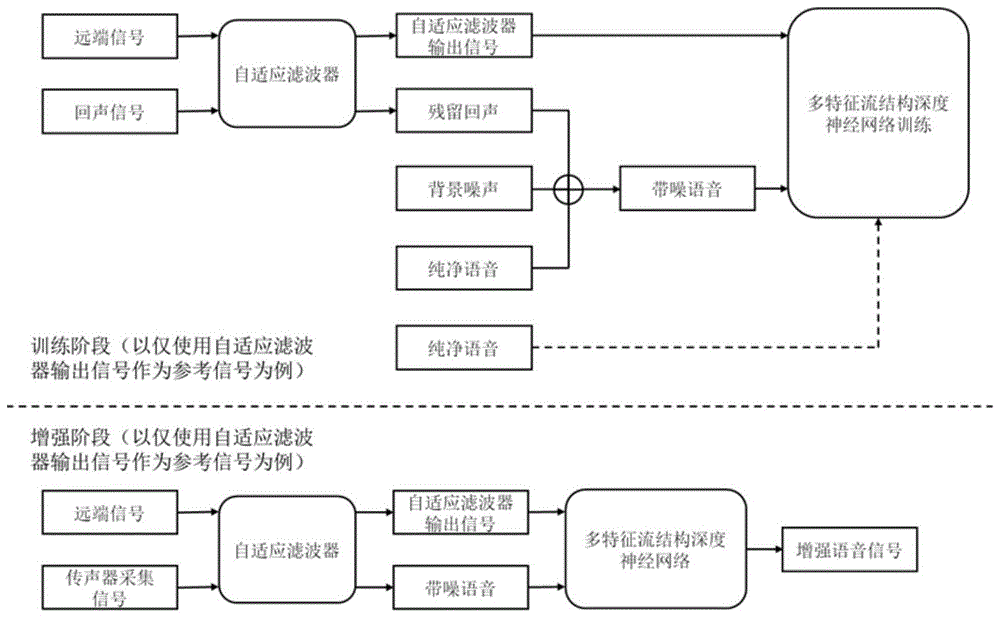
本发明属于回声抑制领域,具体涉及一种基于多特征流结构深度神经网络的非线性残留回声抑制方法。
背景技术:
在通信系统中,远端信号由扬声器系统转换为声信号后,经回声声学路径被传声器系统采集后将产生回声信号。回声信号将严重干扰语音通信的质量,并降低语音识别系统的准确性。抑制回声信号,提取近端说话人语音信号的技术称为回声抑制。
典型的回声抑制方法是使用自适应线性声回声抵消(laec)算法匹配该声回声传递路径对应的传递函数,并使用后处理滤波器进一步抑制残留回声信号。在多种自适应算法中,频域最小二乘自适应滤波器算法及其派生算法具有较快的收敛速度和较低的计算负担,常常应用于实际的回声抑制任务之中。
当回声路径存在不可忽视的非线性效应时,基于线性系统假设的回声抑制系统的性能将大幅下降,因此需要抑制laec系统处理后的信号中的残留回声。残留回声抑制系统常常使用远端信号、自适应滤波器系数以及laec系统处理后的信号对残留回声的幅度进行估计,并依此对残留回声信号进行抑制。这部分基于信号处理的方法常常难以在残留回声抑制和近端语音失真方面取得很好的平衡。针对该问题,学者们将深度神经网络引入到残留回声抑制系统中,以提高对非线性残留回声的抑制效果。其中多数都使用短时傅里叶变换提取时域特征,并以时频谱的幅值作为输入特征。一方面,短时傅里叶变换的处理时延与频域分辨率之间存在冲突;另一方面,使用幅度谱或其掩模作为训练目标无法恢复相位信息,从而限制了网络的性能。
conv-tasnet网络(luoy,mesgaranin.conv-tasnet:surpassingidealtime–frequencymagnitudemaskingforspeechseparation[j].ieeetransactionsonaudio,speech,andlanguageprocessing,2019,27(8):1256-1266.),即全卷积时域语音分离网络,是一种端到端的语音分离网络。在语音分离任务上,该网络的端到端处理使该网络可以具有较短的处理时延,也使得该网络相比基于时频谱掩模的方法获得了更好的效果。考虑到残留回声抑制任务可以视为仅针对近端语音进行提取的语音增强任务,将语音分离任务相关的conv-tasnet模型拓展至残留回声抑制领域存在可行性。
技术实现要素:
现有残留回声抑制技术在存在近端语音且残留回声干扰较高的情况下,常常难以有效抑制残留回声信号,也往往存在对近端语音的过度抑制,影响了残留回声抑制的效果。本发明提出了一种基于多特征流结构深度神经网络的残留回声抑制方法,该方法在存在较高的残留回声干扰的情况下,能有效地提取近端语音信号。
本发明采用的技术方案为:
基于多特征流结构深度神经网络的残留回声抑制方法,包括以下步骤:
步骤1,利用纯净的语音信号、背景噪声、回声信号以及与回声信号对应的远端信号,通过自适应滤波算法,构造带有残留回声和背景噪声的带噪近端语音以及自适应滤波器输出信号;
步骤2,将自适应滤波器输出信号或远端信号或以上两种信号作为参考信号;使用所述参考信号以及步骤1构造的带噪近端语音信号作为具有多特征流结构的神经网络模型的输入特征,该模型对包含参考信号的特征流a以及包含对近端语音的浅层估计信息的特征流b进行联合处理;使用纯净的近端语音作为模型的训练目标,训练模型;
步骤3,将训练完成的具有多特征流结构的神经网络模型作为后处理滤波器,对自适应滤波器处理后的信号中的残留回声和背景噪声进行抑制,增强近端说话人的音频信号。
进一步地,所述步骤2中,对包含参考信号的特征流a以及包含对近端语音的浅层估计信息的特征流b进行联合处理的方式为以下两种之一:(1)通过将特征流b与包含带噪近端语音信息的特征流相减后得到新的特征流c,将特征流a和c分别通过归一化层和卷积层处理后进行综合处理;(2)直接将特征流a和b分别通过归一化层和卷积层处理后进行综合处理;其中,综合处理是指进行维度拼接、逐点相加减乘除及其等效操作。
进一步地,所述具有多特征流结构的神经网络模型,首先通过编码器模块提取时域波形中的特征,再经过抑制器模块中多个具有不同扩张率的一维卷积模块以及多特征流卷积模块处理,得到估计的纯净语音特征谱的掩模,将该掩模应用于编码器输出的带噪语音特征谱,得到纯净语音特征谱的估计,最后经过解码器模块还原为时域波形。
本发明的方法,通过将包含参考信号信息的特征流与包含神经网络对纯净语音的浅层估计信息的特征流进行联合处理的方式,能够使得网络模型在高残留回声干扰的情况下,依然可以获得音质较高、失真较少的近端语音估计结果,有效去除残留回声对近端语音的影响,鲁棒性较高。
附图说明
图1是本发明方法的流程图。
图2是本发明实施例中采用的多特征流结构conv-tasnet模型示意图;
图3是图2模型中(a)1-dconv模块示意图,(b)miconv模块示意图;
图4是现有方法与本发明的方法在不同ser情况下的增强语音的pesq值对比图,(a)是远端信号为语音,(b)是远端信号为音乐。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本实施例在仿真中进行,提供一种基于多特征流结构conv-tasnet模型的残留回声抑制方法,适用于高残留回声干扰的情况,包括如下步骤:
1.生成训练样本
2.训练多特征流结构conv-tasnet模型
将信息属性定义为模型中模块输出的附加属性,将特征流定义为包含相同信息属性的模块输出。模型的各原始输入特征同样被视为具有信息属性的特征流,其信息属性由各原始输入特征自身信息的物理意义构成。对特征流进行操作后,该操作的输出特征流的信息属性继承自输入特征流。信息属性分为先验信息属性和后验信息属性,其中先验信息属性的确定需要对模型框架进行信息属性继承关系分析,后验信息属性的确定则需要对训练后模型的特征流的实际物理意义进行分析。当先验信息属性与后验信息属性产生冲突时,优先使用后验信息属性取代先验信息属性。将“对近端语音的浅层估计”定义为一类后验信息属性,对多个特征流进行混合操作时,该信息属性不被继承。在本实施例中,具有“对近端语音的浅层估计”属性的特征流可直接通过解码器模块输出为对近端语音的估计。这是由于这部分特征流通过skipconnection方式构成模型子图整体输出的一部分;并且,在计算模型的整体训练损失时,这部分特征流将用于单独计算损失并与模型最终输出的损失相结合。应理解,上述定义用于对权利要求书所述特征流的定义进行说明,因其过于严格而不适合用于对模型结构进行说明,下文为了说明方便并未按照上述严格定义进行特征流划分。
本实施例采用的多特征流结构conv-tasnet模型基本框图见图2,该模型接受带噪的近端语音和自适应滤波器输出信号(模型参考信号)作为模型输入。其中,编码器(encoder)模块由输出维度为n,卷积核长度为l,步长为s的单层一维卷积层和线性整流函数(relu)激活函数构成,用于将时域波形信号转变为特征谱。解码器(decoder)模块由单层一维转置卷积层构成,用于将特征谱还原为时域波形。抑制器(suppression)模块由归一化(layernorm)层,输出维度为b的1×1卷积(1×1conv)层和r个子模块组成,每个子模块包括m个扩张率分别为1,2,4,...,2m-1的一维卷积(1-dconv)模块。除了第一个子模块外,每个子模块还包含一个多特征流卷积(miconv)模块。
本实施例采用指数移动平均归一化操作作为模块的归一化层,定义如下
其中,fk,j是特征谱第k帧的第j个特征,f是该特征的维度,
1-dconv模块基本框图见图3的(a)。该模块依次由输出维度为h的1×1conv层,参数线性整流单元(prelu)层,归一化(norm)层,卷积核长度为p的深度卷积(d-conv)层,prelu层,norm层以及两个并列的输出维度为b的1×1conv层构成。末端的其中一个1×1conv层的输出与模块的输入相加作为之后模块的残差输入,另一个1×1conv层作为skipconnection输出构成模型的最终输出的一部分。
miconv模块基本框图见图3的(b)。该模块接受4个特征流作为输入,分别为:(1)带噪近端语音的特征谱(streama),(2)模型参考信号的特征谱(streamb),(3)之前模块的残差输出(streamc),(4)模型之前模块的skipconnection输出之和(streamd)。sub操作用于从之前模块的输出中提取残留回声信号的特征,定义如下
其中,fa和fdi为streama和第i个streamd的特征谱,gob代表了与suppression模块中相同的输出模块(outputblock)的操作,
在训练过程中,使用streama与streamd生成的foi与模型最终的输出共同产生模型的整体训练损失losstotal,定义如下
其中,lossi是foi经decoder模块转换为的时域波形的损失,losslast是模型输出的损失,w是权重参数。本实施例中,采用sisnr作为lossi和losslast的损失函数。
3.利用多特征流结构conv-tasnet模型估计纯净的近端语音
多特征流结构conv-tasnet模型在使用过程中,只需接受带噪的近端语音和自适应滤波器输出信号作为模型输入,即可在模型输出中获得纯净近端语音的估计。因此,利用该模型估计纯净的近端语音的基本框图见图1。先使用远端信号对传声器捕获信号进行自适应滤波,再将自适应滤波后的带噪信号以及自适应滤波器信号输入该模型中,即可得到对带噪信号中残留回声进行抑制,近端语音进行增强后的信号。
至此,残留回声抑制,近端语音增强结果得出。
下面给出一个仿真案例。
1.训练及测试样本和客观评价指标
本实施在构造仿真训练数据时,考虑到智能音箱的实际使用场景,使用timit语料库作为近端语音,使用musan语料库中的音乐库和timti语料库作为远端信号。在timit语料库中随机选取了400位说话人的语音数据作为训练集数据,在剩余话者中随机选取了40位说话人的语音数据作为测试集数据。每位说话者中,选取了10段16khz采样的语音数据。从训练集中选取400段语音数据作为验证集。将musan的音乐库切分为4s的音频,从中选取19269段音频作为训练集数据,400段作为验证集数据,并选取与训练集和验证集来源于不同歌曲的400段音频作为测试集。
为了构造回声数据,首先对远端信号施加软剪切变换,定义如下
其中,xmax是x(n)最大值的80%。对经过软剪切之后的信号施加sigmoidal函数,以模拟扬声器的非线性失真,定义如下
为了模拟真实的房间混响环境,随机构造了50个长宽高在2m至5m之间,混响时间t60在150ms至450ms之间的虚拟小办公室,并在各房间内设置虚拟的扬声器和传声器单元,最后使用虚源法计算得到共500段房间冲激响应。其中400段用于构造训练集和验证集,剩余100段用于构造测试集。将经过sigmoidal变换后的信号与房间冲激响应相卷积,即得到仿真的回声信号。最后,使用基于kalman算法的线性自适应滤波器,通过对应的远端信号对上述构造的回声信号进行自适应滤波,得到残留回声信号和自适应滤波器的输出信号。本实施例中,线性自适应滤波器对回声信号能量的抑制约为14.0db。
在训练集中,共构造了36000段语音回声信号以及38578段音乐回声信号。在验证集和测试集中,共构造了400段语音回声信号以及400段音乐回声信号。
本实施例采用语音质量的感知评估(pesq)指标作为残留回声抑制性能的客观评价指标。
2.参数设置
本实施例中,encoder模块参数n设为512,l设为40,s设为10。suppression模块参数r设为4,m设为8。1-dconv模块参数b设为256,h设为512,p设为3。miconv模块中所有1×1conv层输出维度设为256,d-conv层卷积核长度设为128。指数滑动平均归一化层参数α设为0.989,nα设为640。模型整体损失函数参数w设为0.707。模型训练时采用adam优化器以0.001的学习率进行优化。训练数据以每次两组4s信号的形式输入训练网络。以近端语音训练集遍历一次作为一个训练周期,共训练120个周期。在每个训练周期结束后,对模型在验证集的性能进行评估,当4个训练周期内模型性能未得到提高,则将优化器的学习率减半。为了提高训练的鲁棒性,使用了基于二范数的梯度剪裁,其中二范数最大值设为5。
3.方法的具体实现流程
参照附图1,方法主要分为训练阶段和增强阶段。
训练阶段人为录制或构造回声信号,并使用对应的远端信号通过自适应滤波,构造残留回声信号,并与近端语音,背景噪声相叠加,构造带噪的近端语音。自适应滤波器信号或远端信号或两者兼有作为模型的参考信号。使用带噪的近端语音和模型的参考信号作为模型输入,纯净的近端语音作为模型的目标输出进行训练。在增强阶段,将对传声器采集信号进行自适应滤波后得到的信号,以及由自适应滤波器的输出信号和远端信号组成的模型参考信号输入该模型,即可得到对纯净近端语音的估计。
为了体现本发明相对于现有方法的性能提升,本实施例将和文献(zhangh,wangd.deeplearningforacousticechocancellationinnoisyanddouble-talkscenarios.[c].conferenceoftheinternationalspeechcommunicationassociation,2018:3239-3243.)中基于双向长短期记忆网络(blstm)的残留回声抑制方法和文献(carbajalg,serizelr,vincente,etal.multiple-inputneuralnetwork-basedresidualechosuppression[c].internationalconferenceonacoustics,speech,andsignalprocessing,2018:231-235.)中基于全连接网络(fcn)的残留回声抑制方法进行对比。图4a和图4b分别给出了在远端信号为语音和音乐时,不同方法在ser为-14.2db和-18.2db情况下的增强语音的pesq值柱状图。图中黑色块代表了ser为-14.2db情况下的pesq分数,浅灰色块代表了ser为-18.2db情况下的pesq分数。可以发现,本发明的方法在多种回声情况下相对于现有的基于深度神经网络的残留回声抑制方法的近端语音增强性能都有明显提升。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



