
 商标分类
商标分类  商标转让
商标转让 
一种基于CNN与GRU网络融合的声纹识别方法与流程
 2021-01-28 13:01:16|
2021-01-28 13:01:16| 291|
291| 起点商标网
起点商标网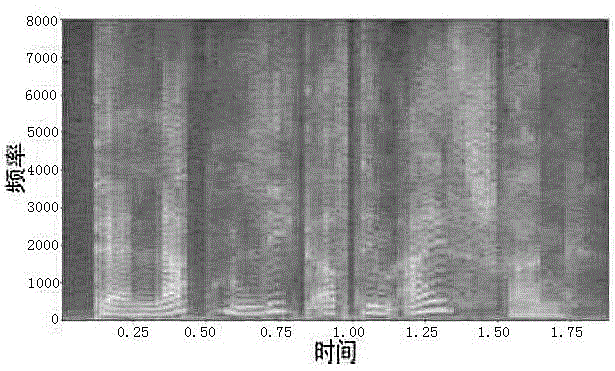
本发明涉及一种声纹识别方法,特别涉及一种基于cnn与gru网络融合(简称c-gru)的声纹识别方法。
技术背景
近些年,生物信息识别技术已经逐渐成为一种非常可靠、便利的身份信息认证方式,吸引了来自行业内外的瞩目。语音是人们交流的日常方式之一。科学证实每个人的发声器官都存在差异性,并且由于后天成长环境的不同,对发声器官的影响也会不同,这就导致了每个人发声器官拥有独特的个性。使用语音对身份进行识别有很多看得见的好处,这是人类自身所持有的特点外,还有很多其他的优点,比如采集语音非常方便,而且使用的设备很便宜并容易获取,使得这个方法就具备了相当大的潜力,还可用于远程身份认证,用户易接受等。
声纹识别技术在内容上可以分为文本相关和文本无关两个方向。在文本相关的声纹识别方法中,说话者必须按照固定好的话术来讲话,而且训练语音的文本内容和测试语音的文本内容也必须相同,这种识别方法虽然可以训练出很好的效果,但其中最大的缺点就是必须按照固定的文本来发音,一旦语音内容与文本不一致或者没有按照要求来发音,文本无关的声纹识别方法就很难保证,所以该方法在实际运用中的推广就存在很大的局限性。
传统声纹识别技术通常采用通用背景模型(gmm-ubm),首先利用大量说话人的语音书记训练一个说话人无关的模型,然后利用map算法有效解决了传统高斯混合模型存在的语音数据较少以及因多通道存在的语音失配问题,最后通过最大后验概率或最大似然回归准则,训练识别模型。但该模型在为每个说话人建模时会占用大量存储资源。神经网络方法是目前深度学习研究的基础学科,随着深度学习逐渐深入各个领域,声纹识别技术方面也逐渐转向深度学习领域进行探索研究。传统声纹识别的深度学习方法主要包括cnn与长短期记忆网络(lstm),基于cnn的声纹识别系统提取声纹特征时忽略了序列语音原本的序列特征,而lstm网络模型虽然考虑了语音特征序列,但由于lstm网络的3个门限带来的巨大运算需求导致lstm网络的训练极度困难。
技术实现要素:
针对上述现有技术不足,本发明提出了一种基于cnn与gru网络融合的声纹识别方法,利用cnn可以自主进行特征提取的优势来避免传统说话人语音特征提取方法造成频域上的信息损失,同时利用gru网络具有良好的时序特征提取的特点,采用cnn与gru网络融合的方式实现了高准确率的声纹识别。
本发明采用如下技术方案实现:
一种基于cnn与gru网络融合的声纹识别方法,包括以下步骤:
步骤1、获取待识别语音片段;
步骤2、对原始语音信号进行预处理,生成待识别语音片段的语谱图;
步骤3、将所述语谱图输入时间序列相关的组合神经网络声纹识别模型,得到待识别语音片段的身份分类信息;
所述cnn与gru网络融合的声纹识别模型的训练方法具体步骤为:
步骤201、获取语音信号的训练集以及语音信号的测试集;
步骤202、通过预加重、分帧、加窗以及端点检测等方法进行语音信号预处理;
步骤203、将语音信号通过改进rls算法提高信噪比;
步骤204、通过离散傅里叶变换等操作将语音片段训练集以及语音信号测试集每个语音片段进行转换,得到语谱图训练集与语谱图测试集;
步骤205、将语谱图的训练集输入待训练的cnn与gru网络,对待训练的cnn与gru网络进行训练;
步骤206、将语谱图的测试集输入训练后的cnn与gru网络,若输出的测试结果满足预设条件,则完成cnn与gru网络的训练,否则返回步骤205再次进行训练,直至测试结果满足预设条件为止;
所述语谱图生成过程包括:
步骤301、基于一阶数字滤波器h(z)=1-αz-1对语音片段进行预加重处理,式中α为滤波器系数;
步骤302、将预加重后的语音片段进行分帧处理,并保持帧与帧之间的平滑过渡和其连续性;
步骤303、基于公式
步骤304、基于公式e(n,k)=|x(n,k)|2=xr(n,k)2+xi(n,k)2计算每一帧信号的能量谱密度,其中x(n,k)为第n帧语音经过m点ftt变换后得到的复数序列;
步骤305、对步骤303能量谱密度取对数得到
步骤306、基于公式
所述改进rls算法包括:
步骤401、基于公式e(n)=d(n)-xt(n)ω(n-1)求得预测误差对语音信号进行增强处理;
步骤402、基于公式
步骤403、基于公式
步骤404、基于公式ω(n)=ω(n-1)+k(n)e(n)完成对滤波器系数更新;
综上所述,本发明公开了一种基于cnn与gru网络融合的声纹识别方法,包括以下步骤:步骤1、获取待识别语音片段。步骤2、对原始语音信号进行预处理,生成待识别语音片段的语谱图。步骤3、将所述语谱图输入时间序列相关的组合神经网络声纹识别模型,得到待识别语音片段的身份分类信息。本发明基于cnn与gru网络融合的特征提取方法,来避免传统说话人语音特征提取方法造成频域上的信息损失,同时利用gru网络具有良好的时序特征提取的特点,采用cnn与gru网络融合的方式实现了高准确率的声纹识别。
本发明实施提供的上述技术方案的有益效果至少为:
本发明实施提供的基于cnn与gru网络融合的声纹识别方法,该方法可以解决单一神经网络提取特征不充分,在应用于复杂问题时常受准确率的限制的问题,同时又有效提高了训练效率。
附图说明
图1为本发明实施的基于cnn与gru网络融合的声纹识别方法流程图;
图2为本发明实施的语谱图示意图;
图3为本发明实施的改进rls对比图;
图4为本发明实施的cnn与gru网络融合的结构示意图;
具体实施方式
以下结合附图对本公开作进一步详细说明。
如图1所示,本发明公开了一种基于cnn与gru网络融合的声纹识别方法,包括步骤包括。获取待识别语音片段(步骤1)。然后对原始语音信号进行预处理,生成待识别语音片段的语谱图(步骤2)。将所述语谱图输入时间序列相关的组合神经网络声纹识别模型,得到待识别语音片段的身份分类信息(步骤3)。
所得语谱图示意图如图2所示,具体生成方法包括。首先对语音信号进行预处理操作得到一帧一帧的短时语音(步骤301),基于公式
改进rls对比图如图3所示,带遗忘因子的指数加权rls算法,其代价函数为jn∑λn-ie2(i),其中λ为遗忘因子,λ越小,对时变参数的跟踪能力越强,但对噪声敏感,稳定误差较大,λ越小,跟踪能力减弱,但对噪声不敏感。基于可变遗忘因子的rls算法,跟踪能力较快,兼顾较小的参数估计误差,算法如下:
e(n)=d(n)-xt(n)ω(n-1)
ω(n)=ω(n-1)+k(n)e(n)
λ(n)=λmin+(1-λmin)2l(n)
l(n)=-round[μe2(n)]
综上,当误差变小时,λ(n)就接近1,使参数误差减小,反之方误差变大时,λ(n)变至最小值λmin。
基于以上理解,提出将下式作为修正函数,并引入参数a控制函数形状,具体函数如下:
式中常数m,n控制函数取值范围,a,b控制函数收敛速度并改善函数形状。当et较大如为6时,λ(n)趋近于n;当et等于0时,λ(n)=m+n,即n<λ(n)<m+n;实验表明当0.8<λ(n)<1是较为合适,因此m,n最终取值为m=0.2,n=0.8。
所得c-gru网络结构示意图如图4所示,其训练过程包括。首先获取语音信号的训练集以及语音信号的测试集(步骤201),通过预加重、分帧、加窗以及端点检测等方法进行语音信号预处理(步骤202),通过改进rls算法对语音信号进行增强处理(步骤203),然后通过离散傅里叶变换等操作将语音片段训练集以及语音信号测试集每个语音片段进行转换,得到语谱图训练集与语谱图测试集(步骤204),将语谱图的训练集输入待训练的cnn与gru网络,对待训练的cnn与gru网络进行训练(步骤205),最后将语谱图的测试集输入训练后的cnn与gru网络,若输出的测试结果满足预设条件,则完成cnn与gru网络的训练,否则返回步骤205再次进行训练,直至测试结果满足预设条件为止(步骤206)。
训练过程中,可以采取以下方式:将第i个说话人的第j张语谱图
本公开基于采用timit语音数据库,语料库的采样率为16khz,16bit,包含来自630人的每人10条语句。测试时选用80%的数据集作为训练样本,剩余20%的数据集作为测试集。将网络模型进行了20次迭代,其结果如表1:
c-gru网络准确率均优于其他两个网络结构下的数值,说明单一特征对声纹识别影响较大,无法满足实际需求。
以上为本公开示范实施例之一,本领域技术人员可以对本发明进行各种各样的改动而不偏离本发明的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



