
 商标分类
商标分类  商标转让
商标转让 
高龄老人不完整语音智能识别方法与流程
 2021-01-28 13:01:27|
2021-01-28 13:01:27| 300|
300| 起点商标网
起点商标网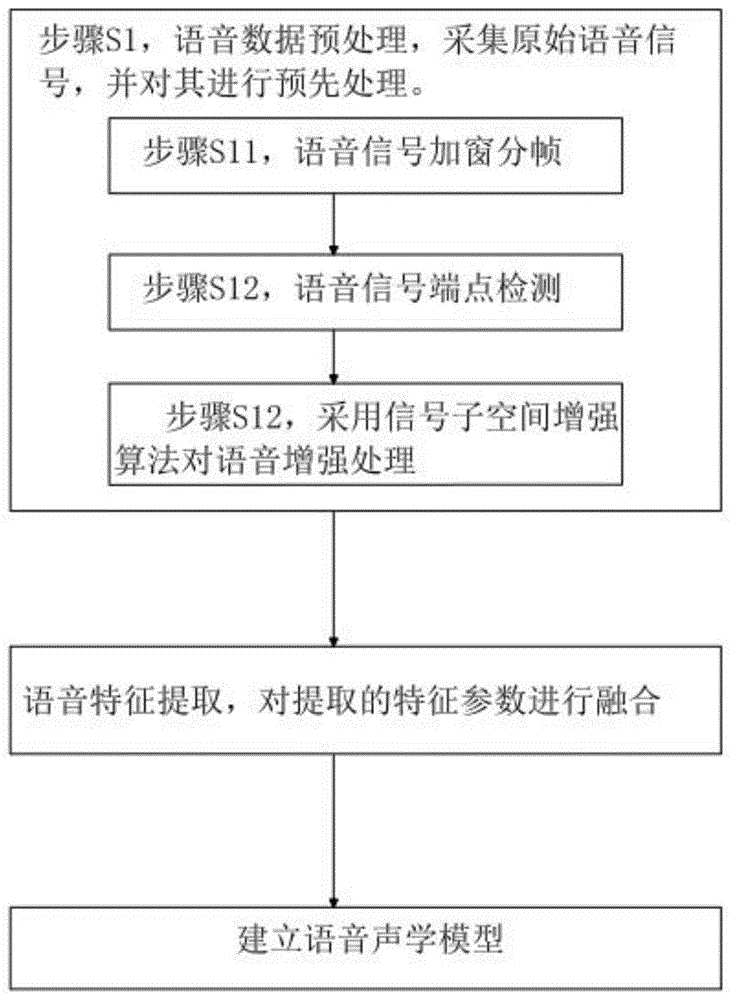
本发明涉及语音识别技术领域,尤其涉及一种高龄老人不完整语音智能识别方法。
背景技术:
高龄老人由于身体机能的衰退,会导致他们的发声器官老化,同时伴有声音口音较严重、语音比较低沉、辨识较为困难等问题,从而导致护理人员无法清楚准确的了解老人的照护需求。
语音识别,即自动语音识别(自动语音识别,asr),通俗地说就是将语音转化为文字。语音识别的研究历史可以追溯到60年前,vintsyuk提出动态时间规整算法(dynamictimewarping,dtw),有效解决了不同时长的语音之间如何比较的问题,成为了当时实现语音识别的主流方法。20世纪70年代,随着计算机性能飞速发展,语音识别技术随之快速发展。普林斯顿大学的lennybaum提出了著名的隐马尔可夫模型(hiddenmarkovmodel,hmm),这一模型被广泛应用到模式识别领域,同样成为了语音识别的流行算法,是发展进程中的一个极大的突破。80年代提出梅尔倒谱系数(melfrequencycepstrumcoeffient,mfcc)极大的改善了语音特征表达。90年代提出单状态隐马尔可夫模型,也就是高斯混合模型(gaussianmixturemodel,gmm),利用高斯分布加权可以拟合任意概率密度曲线的优势,用于和hmm相结合,有效提高了识别精准度。
在21世纪之后,人工智能、深度学习兴起,也深深影响到了语音识别技术的发展。神经网络中的深度神经网络(deepneuralnetwork,dnn)、卷积神经网络(convolutionneuralnetwork,cnn)、循环神经网络(recurrentneuralnetwork,rnn)等模型均被运用到语音识别之中。hiton利用深度置信网络(deep,beliefnetwork,dbn)和dnn对小型词汇量连续语音识别建模获得成功。dagkittlaus和adamcheyer建立siri.inc,提出了基于上下文相关的dnn-hmm模型(cd-dnn-hmm),在深度学习结合语音识别技术的研究得到重大突破。代表性的公司科大讯飞,提出前馈型序列记忆网络(feed-forwardsequential
在语音识别技术中,语音特征的获取尤为重要,老年人由于发声器官老化,导致声音口音较严、语音比较低沉平稳、辨识较为困难等问题,此时传统的语音特征模型不能够全面的表征此类老人语音特征。因此本发明针对老年人这一特定群体的语音发声特点,提出了一种高龄老人不完整语音智能识别技术,在以传统的mfcc参数为主要特征的同时进行一定改良,结合翻转mfcc系数和fisher准则提出改良后的omfcc特征参数,并结合其他语音特征参数组成新的特征向量,以全面表征老人群体的语音数据特征。
技术实现要素:
本发明的目的是提出一种高龄老人不完整语音智能识别方法,该方法对老人的不完整语音、模糊语音进行智能识别,从而获取老人当前的照顾护理需求。实现适用于高龄老人眼动机器视觉跟踪。基于该目的,本发明采用的技术方案如下:
一种高龄老人不完整语音智能识别方法,其特征在于,包括如下步骤:
步骤s1,语音数据预处理,采集原始语音信号,并对其进行预先处理,其中,具体包括如下步骤,
步骤s11,语音信号加窗分帧;
步骤s12,语音信号端点检测;
步骤s13,采用信号子空间增强算法对语音增强处理;
步骤s2,语音特征提取,对提取的特征参数进行融合;
步骤s3,建立语音声学模型。
进一步地,所述步骤s11中,首先使用一个带通滤波器作为抗混叠滤波器,抑制语音信号中频率超过fs/2的混叠分量;
其次,通过分帧操作将语音信号分割成大量极短时间片段,分帧的实现是将原始语音序列x(n)和窗函数w(n)相乘,公式为:
再次,通过加窗处理使得语音信号表现出一些周期性函数的特征;
式中,fs为采样频率,其中
进一步地,所述步骤s12中语音信号端点检测采用改进的双门限法对语音信号端点进行检测,具体为将语音信号先经过语音增强,再经过中值滤波的平滑处理,最后进行端点检测。
进一步地,所述信号子空间增强算法如下:
设带噪语音信号为y,纯净语音信号为x,噪音信号为n,其对应的功率谱协方差矩阵分别为ry、rx、rn,则具有以下的关系式:
y=x+n(1.2)
ry=rx+rn(1.3)
其中,y=[y1,y2,...,yk],x=[x1,x2,...,xk],n=[n1,n2,...,nk],k为语音信号长度,
rx=uλxut(1.4)
其中,
设噪声方差为
若噪声不为白噪声,则需要进行预白化,此时带噪语音信号功率谱协方差矩阵为:
其中
从式(1.7)中可以看出,同时包含噪音信号和纯净语音信号的信号子空间维度为q,只包含噪音信号的噪声子空间维度为k-q;
设h为k×k的时域线性估计器,带噪语音信号通过h可以分离开信号子空间和噪声子空间,其输出的估计值
则估计值与实际值的误差ε为:
其中εx称为语音失真,εn称为残留噪声;εx越大则增强语音失真度越大,语音畸变越大,εn越大增强后残留噪声越大;两者能量为:
得到近似最优滤波器,即求解:
其中0≤α≤1,也就是在保证残留噪音能量在一定范围下使得语音失真能量最小,当α≥1时,取h=i时为此问题最优解;用拉格朗日乘子算法,满足以下梯度方程:
其中μ为拉格朗日算子,再求梯度
λμ为拉格朗日算子对角矩阵,经过特征值分解得到:
将公式(1.16)改写为:
公式(1.17)中,g1为q×q的满秩对角矩阵,u=[u1:u2],u1∈ck×q为信号子空间的基向量,u2∈ck×(k-q)是噪声子空间的基向量;g的对角线元素表示如下:
线性滤波器hopt的性能受到拉格朗日算子μi和噪声方差
通过联合人耳听觉掩蔽效应,得到拉格朗日算子的改进估计值:
带入公式(1.18),得到矩阵g的对角元素
由此可以计算得到最佳线性估计器hopt,带入公式(1.17)中计算增强后语音信号。
进一步地,所述步骤s2中采用mfcc进行语音特征参数提取,mfcc与普通频率的关系式如下:
进一步地,所述步骤s2中,选择mfcc特征与其一、二阶差分参数组合,mfcc参数的一阶差分di(n)和二阶差分δdi(n)表达如下:
采用翻转梅尔倒谱系数(imfcc),将传统滤波器组换成翻转mel滤波器组,其imel频率与普通频率的转换关系如下:
在保证特征向量维度不增长的情况下,计算出每个特征分量对于识别算法的贡献程度,将其中贡献度最高的特征信号进行组合,进而得到的优化后的mfcc系数,记为omfcc系数,使用fisher准则来完成对特征向量对系统贡献度的表征,在模式识别中,fisher准则可以用来描述一个特征的类别可分离性:
rf为特定特征参数的fisher比,σb和σw分别是特征参数的类间散度(方差)和类内散度(方差)。
进一步地,选定融合的特征参数包括:mfcc、imfcc、改进后omfcc系数、平均短时能量en、基音周期p以及teager-kaiser能量算子tkeo。
进一步地,所述声学模型为gmm-hmm模型,该模型中,gmm训练初值优化算法采用模糊c均值算法,通过fcm将样本预训练一遍,再计算分类后的m类样本的权重值、聚类中心和协方差,并将其作为em算法的初始参数{ωi,μi,∑i}。
进一步地,所述声学模型为dnn-hmm模型。
相比较现有技术,本发明具有如下有益效果:本发明的高龄老人不完整语音智能识别技术能够降低由老年人发声器官老化而引起的声音幅值轻微、受环境噪声影响大的问题,采用声音参数融合的语音特征能够更加逼近高龄老人的语音特点,从而能够获取全面表征老人语音特征的数据,提高了对老人不完整语音以及模糊语音的识别度。通过实验证明,本发明的眼动机器视觉跟踪技术能够快速、精确的从视频序列中定位出眼动特征,从而实时的识别老人的护理需求。
附图说明
图1为本发明方法流程图;
图2a是采样下的语音波形;
图2b是语音预加重频谱图;
图3为语音数据分帧操作图;
图4a“左翻身”原始数据端点检测结果图;
图4b“左翻身”语音增强后端点检测结果;
图5a为原始语音信号和增强后的语音信号对比图;
图5b为叠加了白噪声的语音数据增强前后对比图;
图5c为叠加了粉红噪声的语音数据增强前后对比图;
图5d为叠加了babble噪声的语音数据增强前后对比图;
图6为“背升腿曲”的mfcc参数;
图7“左翻身”语音gmm-hmm模型;
图8为dnn-hmm模型框架;
图中,transitionprobabilities表示转移概率,observationprobabilities表示观测概率,windowoffeatureframes表示特征框窗口。
具体实施方式
下面结合实施例以及附图对本发明作进一步描述。
实施例1
如图1所示,一种高龄老人不完整语音智能识别方法,其特征在于,包括如下步骤:
步骤s1,语音数据预处理,采集原始语音信号,并对其进行预先处理,其中,具体包括如下步骤,
步骤s11,语音信号加窗分帧;
步骤s12,语音信号端点检测;
步骤s13,采用信号子空间增强算法对语音增强处理;
步骤s2,语音特征提取,对提取的特征参数进行融合;
步骤s3,建立语音声学模型。
具体地,首先使用一个带通滤波器作为抗混叠滤波器,用以抑制语音信号中频率超过fs/2(fs为采样频率)的所有混叠频率分量,防止混叠干扰对信号采样工作的影响。经过预滤波处理后的数据仍是连续数据,可以经过采样工作以得到离散的语音信号。语音识别系统中经常使用8khz、10khz或16khz作为采样频率。在经过采样处理之后,得到了时间离散的、幅度连续的语音模拟信号。为了便于后续处理,本文采用量化操作将语音模拟信号变为时间和幅度都离散的数字信号。由于人类发音会受到声门激励和口鼻辐射的影响,语音信号在高频段(≥800hz)部分会出现6db/oct的衰减(oct指倍频程)不利于后续分析,本发明在采样量化之后加入一个高通滤波器实现预加重,用以补偿语音的高频分量,使得整个语音频谱变得更加平坦,同时也可以抑制随机噪声,易于后续的频谱分析。具体对比见图2a和图2b。
具体地,由于语音信号的短时平稳性,我们可以通过分帧操作将语音信号分割成大量极短时间片段,每一段语音信号便叫做一帧,长度称为帧长。分帧操作如图3所示,分帧的实际实现,是将原始语音序列x(n)和窗函数w(n)相乘,公式为:
其中
通过加窗处理可以使全局更加平稳,避免出现gibbs效应,同时可以使得没有周期性的语音信号表现出一些周期性函数的特征。
具体地,所述步骤s12中语音信号端点检测采用改进的双门限法对语音信号端点进行检测,具体为将语音信号先经过语音增强,再经过中值滤波的平滑处理,最后进行端点检测。在采集语音的实际操作中,会在开始结束或中间时刻存在静默期,这个期间内不存在有实际意义的语音信号,只存在背景噪音信号,若将其作为语音段则对后续处理工作由不利影响,会减弱系统识别率。为了解决这一问题,本发明采用端点检测技术找出语音信号的真正起始点和结束点,将语音段和静默段相分离。目前用于端点检测的语音相关参数和端点检测方法有:短时能量及短时平均幅度、短时平均过零率、双门限法。本实施例中采用双门限法并对其进行改进。
双门限法给短时能量和短时平均过零率设置了一高一低两个门限值,较低的值对信号更加敏感,当被超过时可能是有效语音信号的起始点,也有可能是背景噪音所引起的,并不是准确的起始点,这时候可以通过高门限值的设定增加判断环节,若语音信号超过高门限值并维持一定时间,则可以认为这是有效语音信号的起始点。
传统的双门限端点检测法在语音信噪比较高时能有很好的处理效果,但是在实际情景中如果信噪比较低,若阈值设定较小则会导致误判,将噪音部分误判为语音的声母,端点判断效果大大减小。为了解决这个问题我们可以选择将语音信号先经过语音增强,再经过中值滤波的平滑处理,最后进行端点检测。语音增强可以有效提高语音信号的信噪比,从而提高端点检测的准确度。中值滤波环节,加入一个滑动窗口,滑动窗口中包含5个帧的语音数据,将其按照幅值大小排列后输出其中值。平滑操作可以去除少量的离散点,同时保证数据中不会出现阶跃变化。
图4a和4b以“左翻身”这个语音为例子,分别示意出了原始端点检测效果图和语音增强后的端点检测效果图。
现实中实际的语音数据总是伴随着各种各样的噪声,特别针对老年人群体,其噪声信号相对于语音信号更为明显,而噪声会大大影响识别系统的识别效率。本发明采用语音增强技术来实现噪声分离和噪声抑制,提高语音数据信噪比,减小语音失真度,提取尽可能纯净语音信号。
本实施例采用信号子空间增强算法,在传统方法上融合人耳听觉掩蔽效应来改善对噪音信号的抑制作用,估计信号子空间维度,并用最小值跟踪法估计噪声功率谱。改进后的信号子空间算法拥有比传统算法残存误差更小,去噪效果更加明显的优势。
信号子空间增强语音的原理就是通过特征值分解,将带噪信号空间分解为信号子空间(包含有效语音信号和噪声信号)和噪声子空间(仅含有噪音信号),将噪声子空间置零,并除去信号子空间内的噪声信号。设带噪语音信号为y,纯净语音信号为x,噪音信号为n,其对应的功率谱协方差矩阵分别为ry、rx、rn,则具有以下的关系式:
y=x+n(1.2)
ry=rx+rn(1.3)
其中,y=[y1,y2,...,yk],x=[x1,x2,...,xk],n=[n1,n2,...,nk],k为语音信号长度,
rx=uλxut(1.4)
其中,
设噪声方差为
若噪声不为白噪声,则需要进行预白化,此时带噪语音信号功率谱协方差矩阵为:
其中
从式(1.7)中可以看出,同时包含噪音信号和纯净语音信号的信号子空间维度为q,只包含噪音信号的噪声子空间维度为k-q;
设h为k×k的时域线性估计器,带噪语音信号通过h可以分离开信号子空间和噪声子空间,其输出的估计值
则估计值与实际值的误差ε为:
其中εx称为语音失真,εn称为残留噪声;εx越大则增强语音失真度越大,语音畸变越大,εn越大增强后残留噪声越大;两者能量为:
得到近似最优滤波器,即求解:
其中0≤α≤1,也就是在保证残留噪音能量在一定范围下使得语音失真能量最小,当α≥1时,取h=i时为此问题最优解;用拉格朗日乘子算法,满足以下梯度方程:
其中μ为拉格朗日算子,再求梯度
λμ为拉格朗日算子对角矩阵,经过特征值分解得到:
将公式(1.16)改写为:
公式(1.17)中,g1为q×q的满秩对角矩阵,u=[u1:u2],u1∈ck×q为信号子空间的基向量,u2∈ck×(k-q)是噪声子空间的基向量;g的对角线元素表示如下:
线性滤波器hopt的性能受到拉格朗日算子μi的噪声方差
人耳听觉掩蔽效应指的是强音会掩蔽对附近较弱语音信号的感知能力,其中强音信号称为掩蔽音,弱音信号称为被掩蔽音。当两个语音信号同时出现时称为同时掩蔽或频域掩蔽,当两者之间有时间顺序则称为异时掩蔽或时域掩蔽。在没有声音的环境中,人耳可以感知到的声音最小值组成的曲线称为安静阈值曲线,而当声音出现时,该曲线将会随之变化,形成掩蔽阈值曲线。掩蔽阈值曲线之下的声音将会被遮掩,不会被人耳感知到,也就是说无法感知到这段区域的噪音信号。
利用这种特性,我们可以用人耳听觉掩蔽效应计算听觉掩蔽阈值,估计拉格朗日算子μ,μ表示了增强后语音失真与残存噪声之间的折中,如果将增强后语音的残留噪音减小至掩蔽阈值之下,那么该噪声就不会被感知到,如此便可以改进原有的语音增强算法,增强对于残存噪声的抑制作用。最后,通过联合人耳听觉掩蔽效应,得到拉格朗日算子的改进估计值:
带入公式(1.18),得到矩阵g的对角元素
由此可以计算得到最佳线性估计器hopt,带入公式(1.17)中计算增强后语音信号。
图5a、5b、5c、5d分别为叠加了白噪声、粉红噪声和babble噪声的语音数据增强前后对比图,可以直观的看出前后差别。
具体地,步骤s2中采用mfcc进行语音特征参数提取。mfcc是在mel标度频率域使用的倒谱参数,mel标度将纯音的感知频率或音调,与其实际频率相对应,描述了人耳频率的非线性特性,也就是人类识别低频时高音的微小变化要优于高频时。结合这种标度,能将线性谱映射到听觉感知的mel非线性频谱中,然后转换到倒谱,与人类听觉模式更接近。其与普通频率的关系如下式:
具体地,本实施例利用mfcc对语音“背升腿曲”提取的结果如下图所示,每帧语音数据可以提取12维mfcc系数,可以看出维数越高,其后的参数越趋于0,也可以看出mfcc参数高频灵敏度不足的缺点,因此需要对mfcc的参数进行优化。
语音信号是连续的,而计算得到的mfcc系数都是属于当前帧的,也就是只能体现语音信号的静态特性。为了体现时域连续性,表示语音动态特性,本文选择mfcc特征与其一、二阶差分参数组合,各取12维特征参数,形成一组36维特征向量,这样既能体现语音信号的静态特性,也能体现语音信号的动态特性,能够更全面地表现语音特征,有效地提高语音的识别率。mfcc参数的一阶差分di(n)和二阶差分δdi(n)表达如下:
mfcc特征提取可知,传统的mel滤波器组在低频段密集,高频段稀疏,这一形式会忽略高频中的部分信息,通过dct求得的参数也可以看出,越往后越趋于0,高频信号虽然所含信息不如低频段,但也不可忽视,所以采用翻转梅尔倒谱系数(imfcc),将传统滤波器组换成翻转mel滤波器组。其imel频率与普通频率的转换关系如下:
本实施例中选择12维imfcc、12维一阶差分参数和12维二阶差分参数组成36维特征向量作为语音特征参数,可以同时表征语音数据的静态和动态特性。
通过组合mfcc和imfcc系数可以有效地、最大化利用语音信号中的低频和高频范围内的特征。但是直接组合会导致特征参数过多,其中会包含着部分冗余信息,不但会增加系统工作计算量,也会影响到最后的识别效果。本文在保证特征向量维度不增长的情况下,计算出每个特征分量对于识别算法的贡献程度,将其中贡献度最高的特征信号进行组合,进而得到的优化后的mfcc系数,记为omfcc系数,使用fisher准则来完成对特征向量对系统贡献度的表征。在模式识别中,fisher准则可以用来描述一个特征的类别可分离性:
rf为特定特征参数的fisher比,σb和σw分别是特征参数的类间散度(方差)和类内散度(方差)。
目前常用的语音特征还有:(1)线性预测倒谱系数(lpcc)即lpc的倒谱系数,舍弃了信号中的激励信息,能够用较少的系数描述共振峰的特征,具备良好的识别效率。(2)基音周期描述的是声门相邻两次开闭之间的时间间隔,或者描述声门开闭的频率。(3)teager-kaiser能量算子是一个非线性算子,能够跟踪信号的瞬时能量,通过对相邻采样点进行计算提取包络线,拥有很好的时间分辨率,实现简易与快速,能够完成对原始信号波形变化的实时跟踪,同时能够强化平稳和半平稳信号,抑制不平稳信号。
由于老年人语音特点,声音不如正常人清澈,幅值较低,仅用单一特征难以进行全面的描述,本实施例中将对多种特征进行尝试融合,并通过识别算法得到各组合实际识别效果,并针对结果进行分析,最终选定最佳的融合方式。选定的特征参数包括:mfcc、imfcc、改进后omfcc系数、平均短时能量en、基音周期p以及teager-kaiser能量算子tkeo。
本实施例中,采用gmm-hmm模型。hmm属于概率统计模型,用来描绘隐藏马尔可夫链随机生成不可观测的随机状态序列,再由每个状态生成可观测的随机观测序列的过程。考虑到人类在发声过程中存在的随机性,通常利用高斯混合概率密度函数,在混合成分足够多的条件下能够拟合任意概率密度的特性,来描述音素到语音信号之间的转化关系,也就是hmm之中的观测概率,基于此建立的也就是语音识别算法中的gmm-hmm模型。模型框架如图7所示,由于语音信号的特殊性,hmm状态不允许向前转换,而状态会存在自环是考虑到会有音素持续时间较长,相当于状态的自我转换,也正因为有着自环环节,才可以处理不等长的语音数据。
实验测试如下:
本实验测试中邀请了12位男性,8位女性,录制的语音数据有:背升、背降、腿升、腿降、左翻身、右翻身、背升腿曲、背平腿伸、还原、上厕所共10组语音数据,每组录制10次,每组语句200个语音数据,共2000个语音数据,测试采样频率16khz,16bit量化,预加重系数0.96,窗口长度400,帧移160。使用改进信号子空间法降噪,再对每帧语音数据提取特征参数。训练测试时将每组语句的语音数据随机均分为5组进行五折交叉验证。
本次测试共训练10组gmm-hmm模型,音素状态数设为6,gmm模型先利用模糊c均值聚类算法预训练,对每组语句的训练特征向量进行分类,将分类后的结果作为gmm模型的初始值。随后分别利用em算法对gmm和hmm参数进行训练,直到满足停止条件。实验测试1600条训练语句,400条测试语音数据,利用本文提及的特征参数组合方式进行训练仿真,取五次交叉验证中最佳的训练结果,最后实验结果如下表所示:
表4.1gmm-hmm模型测试结果
由实验结果可以看出,imfcc识别率要低于mfcc,但两者经过融合后的omfcc识别能力得到了提升,相较于mfcc系数,识别率提升了3.5%,说明这一改进能够更能充分有效地利用语音信号的低、高频信号。在结合其他特征参数的组合方式的识别率,组合参数(omfcc,tkeo,e)将识别率提高到了最高94%,对比所有参数组合方式,最终选择(omfcc,tkeo,e)这一组合方式作为gmm-hmm语音模型的特征向量,可以获得最佳的识别效果。
实施例2
本实施例与实施例1的区别是,本实施例中语音模型采用dnn-hmm模型。
一种高龄老人眼动机器视觉跟踪装置,包括眼部区域提取装置、眼动特征定位装置和注视点定位装置;所述眼部区域提取装置使用单目摄像头进行视频图像采集,并对采集的图像进行灰度化处理,进行人脸检测,提取人眼区域;所述眼动特征定位装置选用虹膜中心替代瞳孔中心作为动点,使用灰度积分投影与图像梯度相结合的方法用以定位虹膜中心;所述注视点定位装置通过前面两个装置计算得到虹膜中心坐标与眼角点坐标后,计算两者之间的坐标偏移向量即可得到眼动信息,建立眼动信息与屏幕注视点之间的映射模型。随着深度神经网络(dnn)的兴起,和其不断展示出的强大能力,人们开始考虑将dnn融入到语音识别算法中去,dnn-hmm就是由此诞生出的模型,其模型结果框架如图8所示。
和图7所展示的gmm-hmm模型图相比较可以看出,其中对于语音信号中音素状态的描述依然采用hmm,而对于音素状态与特征向量之间的观测概率,则由原来的gmm替换为了dnn。相较于原来的gmm-hmm,有如下的区别:
(1)gmm假设音素与特征分布之间满足高斯混合概率分布,dnn不需要对特征分布进行假设;
(2)gmm的输入为单帧特征,dnn的输入可以选择连续的拼接帧;
(3)在发音模式分类上,dnn要比gmm更加合适;
(4)训练dnn-hmm模型,首先要训练gmm-hmm模型,再将其中的gmm替换成dnn。计算量和耗费的资源明显增大。
经过对gmm-hmm模型以及dnn-hmm模型分析后,对于gmm-hmm模型而言,hmm与gmm的训练均使用到em算法,其中初始概率向量和状态转移概率的初值选择对识别效率影响并不大,而对于观测概率初值的选择会影响算法收敛速度,也会影响到最终识别的结果。为了解决传统的随机选取带来的缺陷,本文提出gmm训练初值优化算法。
模糊c均值算法(fcm)是一种应用相当广泛的软聚类算法,和高斯混合聚类一样,并不是把样本惟一地划分到一个类别,而是让每个样本概率地归属于各个类别。可以通过fcm将样本预训练一遍,再计算分类后的m类样本的权重值、聚类中心和协方差,并将其作为em算法的初始参数{ωi,μi,∑i},这样可以有效地加快em算法的收敛速度,并且改善陷入局部最小值的情况,从而增加识别效率。
高龄老人由于身体机能的衰退,会导致他们的发声器官老化,同时伴有声音口音较严重、语音比较低沉平稳、辨识较为困难等问题,本文通过对老年人特定群体的语音发声特点进行分析研究,提出了一种高龄老人不完整语音智能识别技术,通过语音增强算法解决语音数据因为老年人发声器官老化而引起的幅值轻微、受环境噪声影响增大的问题,改进omfcc特征参数来充分表征老年人语音特征,从而实现对老人的不完整语音、模糊语音进行智能识别,大大提高了老人与外界沟通交流的效率。同时,针对老人的发声特点,采用声音参数融合的语音特征能够更加逼近高龄老人的语音特点,从而能够获取全面表征老人语音特征的数据,提高了对老人不完整语音以及模糊语音的识别度。
最后应说明的是:以上实施例仅用以说明本发明而并非限制本发明所描述的技术方案;因此,尽管本说明书参照上述的各个实施例对本发明已进行了详细的说明,但是,本领域的普通技术人员应当理解,仍然可以对本发明进行修改或等同替换;而一切不脱离本发明的精神和范围的技术方案及其改进,其均应涵盖在本发明的权利要求范围中。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



