
 商标分类
商标分类  商标转让
商标转让 
网约车安全监测装置及系统的制作方法
 2021-01-28 13:01:56|
2021-01-28 13:01:56| 298|
298| 起点商标网
起点商标网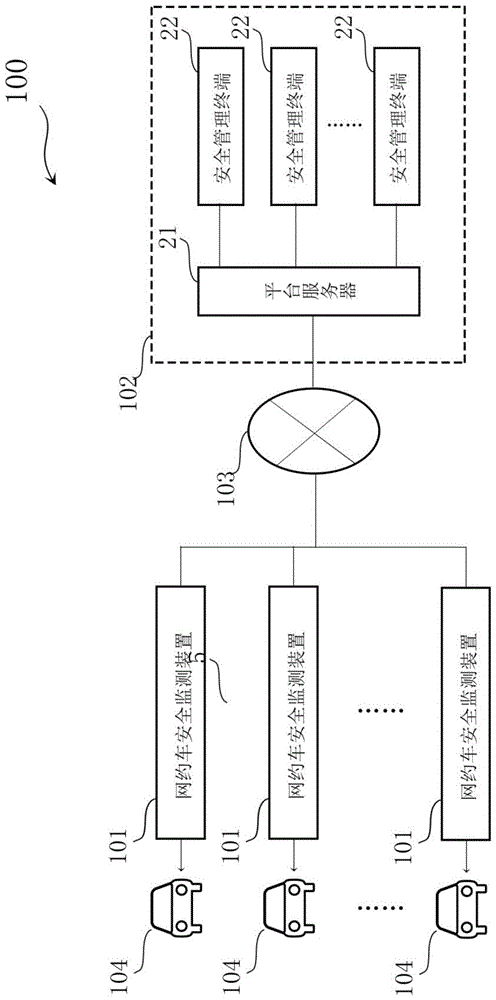
本发明涉及一种网约车安全监测装置及系统。
背景技术:
近年来,网约车的使用越发普遍,然而随之也存在着安全事故易发、难管控的问题。通常情况下,乘客利用手机等移动通信设备内的app发起行程订单,网约车的驾驶员也同样地利用app接收订单,因而一些网约车平台在app中增设了监测功能,例如行驶过程全程录音等等。然而,录音只能在事故发生后作为追溯依据,不能在事故发生的当时给予平台反馈,使得事故发生时难以得到及时处理。
为了克服录音的不及时性,现有技术也出现了一些能够实时采集车内音频数据的装置或app,这些装置或app可以通过对音频数据进行语音识别,从而识别出司机以及乘客之间的对话文本,进一步通过预设的“救命”等关键词来判断是否进行预警。
但是,这些技术必须依赖于根据语音所识别出的对话文本,才能完成相应的预警判断。而实际应用中,在乘客司机发生争吵时,往往会不自觉的使用方言,使得常规的语音识别技术无法准确地对争吵时的语音内容进行识别。另外,争吵时人们的语调和说话方式也往往会和平时不同,因此现有的语音识别技术很难在争吵时准确的识别出完整的对话文本,也就容易使得很多对话中的关键词缺失,难以采用关键词识别等手段来对车内的安全状态进行有效判断。
技术实现要素:
为解决上述问题,提供一种能够对网约车内的争吵环境进行监测完成预警,并且在争吵时还能够针对方言识别出争吵语音中的关键词从而发出紧急预警的网约车安全监测装置及系统,本发明采用了如下技术方案:
本发明提供了一种网约车安全监测装置,其特征在于,包括:音频采集部,设置在网约车内,用于实时采集车内的声音并处理为音频流;争吵环境识别判定部,具有预先至少基于含有争吵对话的争吵音频数据训练得到的争吵判别网络,用于通过争吵判别网络在音频流中识别出对话处于争吵状态的争吵语音段,并在识别出争吵语音段时判定网约车的车内环境处于争吵环境;争吵隐患提示输出部,一旦争吵环境判断部判断车内环境处于争吵环境,就生成争吵预警提示并将该争吵语音提示与争吵语音段进行对应输出;危险关键词识别部,具有预先训练好的方言关键词识别模型,用于将争吵语音段输入方言关键词识别模型进行识别从而判断争吵语音段中是否出现有预定的危险关键词;以及紧急措施提示输出部,一旦危险关键词识别部在争吵语音段中识别出危险关键词,就生成并输出紧急措施采取请求从而提示需要紧急进行应对措施,其中,方言关键词识别模型至少基于对应各种方言且含有危险关键词的关键词语音数据预先训练得到。
本发明提供的网约车安全监测装置,还可以具有这样的技术特征,其中,争吵环境检测部还包括争吵网络存储单元、语音端点检测单元、争吵音频识别单元以及争吵判断单元,争吵网络存储单元用于存储争吵判别网络,语音端点检测单元对音频流进行语音端点检测并从中识别出含有人声的语音音频段,争吵音频识别单元依次将语音音频段输入争吵判别网络并输出语音音频段是否处于争吵状态的争吵判别结果,争吵判断单元在争吵判别结果判断为是时判断车内环境为争吵环境并将相对应的语音音频段作为争吵音频段。
本发明提供的网约车安全监测装置,还可以具有这样的技术特征,其中,争吵判别网络以及关键词识别模型预先通过如下训练步骤得到:步骤s1-1,获取多个正常对话时产生的正常语音数据、多个含有争吵对话的争吵语音数据以及对应于各种方言的若干个关键词语音数据;步骤s1-2,分别对每个正常语音数据、争吵语音数据以及关键词语音数据进行预处理并形成相应的多个正常音频数据、争吵音频数据以及若干个关键词音频数据;步骤s1-3,根据多个正常音频数据争吵音频数据对争吵判别网络进行训练使得该争吵判别网络能够判别对话是否出争吵状态;步骤s1-4,根据多个争吵音频数据以及若干个关键词音频数据对方言关键词识别模型进行联合训练使得方言关键词识别模型能够从争吵对话中识别出用方言说出的关键词。
本发明提供的网约车安全监测装置,还可以具有这样的技术特征,其中,预处理至少包括噪声混合处理,噪声混合处理为将多种预设的噪声分别与争吵语音数据以及关键词语音数据进行混合从而得到争吵音频以及关键词音频,噪声为稳态噪声以及非稳态噪声,稳态噪声至少包括风声以及发动机电机声,非稳态噪声至少包括敲击声以及开门声。
本发明提供的网约车安全监测装置,还可以具有这样的技术特征,其中,一旦争吵环境判断部识别出的争吵语音段,训练语音存储部就将被识别出的争吵语音段作为争吵语音数据进行存储。
本发明提供的网约车安全监测装置,还可以具有这样的技术特征,其中,一旦危险关键词识别部在争吵语音段中识别出危险关键词,训练语音存储部就根据危险关键词从争吵语音段中截取出对应的危险关键词语音段并作为关键词语音数据进行存储。
本发明提供的网约车安全监测装置,还可以具有这样的技术特征,其中,争吵网络模型包括输入层、两个隐藏层以及分类层,隐藏层采用lstm结构。
本发明还提供了一种网约车安全监测系统,用于让网约车平台对旗下的各个网约车进行安全监测,其特征在于,包括:多个网约车安全监测装置,分别设置在各个网约车中;以及平台安全管理装置,由网约车平台持有,与各个网约车安全监测装置分别相通信连接,其中,网约车安全监测装置为权利要求1至7中任意一项的网约车安全监测装置,平台安全管理装置用于在接收到网约车安全监测装置发送的紧急措施采取请求时提示网约车平台的安全管理人员采取相应的紧急措施。
本发明提供的网约车安全监测系统,还可以具有这样的技术特征,其中,平台安全管理装置具有争吵语音暂存部、画面存储部以及输入显示部,争吵语音暂存部暂存有从网约车安全监测装置接收到的争吵预警提示以及对应的争吵语音段,画面存储部存储有网约车安全监控画面,输入显示部显示网约车安全监控画面并显示被暂存的争吵预警提示以及对应的争吵语音段让安全管理人员查看并进行安全管理。
发明作用与效果
根据本发明的网约车安全监测装置及系统,由于具有争吵环境识别判定部以及争吵隐患提示输出部,在音频采集部在采集到网约车内声音的音频流后,可以基于预先根据争吵语音训练出的争吵判别模型,通过声学原理直接从音频流识别出由争吵产生的争吵语音段,因此实现了对车内是否处于争吵环境的判别,并在司机与乘客发生争吵时提示相应的负责人员可能需要进行干预,通过这样的方式,可以在不对司机乘客的对话进行识别的基础上,仅通过对话的语气和音量就判断出司机乘客之间是否存在发生危险可能性。
进一步,由于还具有危险关键词识别部以及紧急措施提示输出部,在识别出争吵语音后,可以在争吵语音识别是否存在有通过方言说出的危险关键词,并在识别出后发出紧急措施采取请求给负责人员立即进行干预,因此,即使因为司机乘客的争吵时不自觉的使用了方言,也能够准确地识别出对话中是否出现有预先设好的危险关键词,并在识别出这些关键词认定司机与乘客的矛盾激化,第一时间通知负责人员采取紧急措施。通过本发明这样先判断争吵再识别方言关键词的方法,可以准确、且及时地在司机乘客动手之前就发现可能发生危险,及时通知负责人员进行干预,保障乘客与司机的安全。
附图说明
图1是本发明实施例中网约车安全监测系统的结构框图;
图2是本发明实施例中网约车安全监测装置的结构框图;
图3是本发明实施例中争吵环境识别判定部的结构框图;
图4是本发明实施例中争吵判别网络的结构示意图;
图5是本发明实施例中方言检测模型的结构框图;
图6是本发明实施例中预训练过程的流程图;
图7是本发明实施例中安全管理终端的结构框图;以及
图8是本发明实施例中安全监控过程的流程图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的网约车安全监测装置及系统作具体阐述。
<实施例>
图1是本发明实施例中网约车安全监测系统的结构框图。
如图1所示,网约车安全监测系统100包括多个网约车安全监测装置101、平台安全管理装置102以及通信网络103。
网约车安全检测装置101设置在每一辆网约车104中,用于在网约车104启动时采集车内的声音并进行安全判断,进一步在判断有危险时将相应的提醒信息发送给平台安全管理装置。
本实施例中,网约车安全检测装置101为设置在网约车中带有数据处理功能的音频采集装置。例如,该网约车安全检测装置101可以设置在驾驶位和副驾驶位之间,并通过车载电源和蓄电池供电,从而保证能够正常对司机和乘客进行音频采集。
图2是本发明实施例中网约车安全监测装置的结构框图。
如图2所示,网约车安全监测装置101包括音频采集部11、争吵环境识别判定部12、争吵隐患提示输出部13、危险关键词识别部14、紧急措施提示输出部15、训练语音存储部16、装置通信部17以及用于控制上述各部的装置控制部18。
音频采集部11用于实时采集网约车内的声音并处理为相应的音频流。
本实施例中,音频采集部11为一个麦克风,固设在网约车内,能够在车辆启动时实时采集车辆内的声音。
音频流为音频采集部11实时生成并且连续的音频数据,音频采集部11在采集到的音频流后会同步输出给争吵环境识别判定部12进行争吵环境的识别与判定。
争吵环境识别判定部12用于对音频数据进行识别并判断网约车当前的车内环境是否处于争吵环境。
图3是本发明实施例中争吵环境识别判定部的结构框图。
如图3所示,争吵环境识别判定部12包括争吵网络存储单元121、语音端点检测单元122、争吵音频识别单元123以及争吵判断单元124。
争吵网络存储单元121存储有预先训练好的争吵判别网络。
语音端点检测单元122用于对音频流进行语音端点检测并从中识别出含有人声的语音片段。
本实施例中,语音端点检测单元通过常规的端点检测方法(voiceactivitydetection,vad),检测出人的声音,并将含有人的声音的片段裁剪为语音音频段。
争吵音频判断单元123用于依次将每个语音音频段输入争吵网络存储单元121存储的争吵判别网络中并输出语音音频段的争吵判别结果。
图4是本发明实施例中争吵判别网络的结构示意图。
如图4所示,争吵判别网络1211具有输入层1231、与该输入层连接的两个隐藏层(即第一隐藏层1232以及第二隐藏层1233)以及一个分类层1234。
输入层1231用于输入语音音频段。
第一隐藏层1232以及第二隐藏层1233均采用lstmcell,用于对语音音频段进行特征提取。
分类层1234用于根据第二隐藏层1233提取出的音频特征进行分类。本实施例中,分类层为一个二分类的softmax层,能够根据音频特征进行分类并输出争吵判别结果,该争吵判别结果用于判断输入的语音音频段是否含有争吵语音。
本实施例中,上述争吵判别网络1211预先通过正常语音以及争吵语音训练得到,能够通过声学判断语音音频段中的语音是否为争吵语音。由于司机乘客在陷入争吵时,说话的语调以及音量会发生相应变化,因此争吵判别网络1211能够通过这些音频特征实现争吵语音的判别。
争吵判断单元124用于在音频识别结果判断为是(即语音音频段中含有争吵语音)时,判断车内环境为争吵环境并将相对应的语音音频段作为争吵音频段。
另外,当音频识别结果为否时,即语音音频段中司机与乘客只是正常对话,不含有争吵语音,那么争吵判断单元1234就不会进行响应。
争吵隐患提示输出部13用于在争吵环境识别判定部12判断当前的车内环境处于争吵环境时,生成争吵预警提示并将该争吵语音提示与争吵语音段进行对应输出。
本实施例中,争吵隐患提示输出部13会将争吵预警提示以及争吵语音段发送给平台安全管理装置102。
危险关键词识别部14用于对争吵音频段进行语音识别并判断音频段中是否识别出危险关键词。
本实施例中,危险关键词为预先设定的一些关键词例如“救命”等人们在危险情况下会说出的关键词。
图5是本发明实施例中方言检测模型的结构框图。
如图5所示,危险关键词识别部14具有一个方言关键词识别模型141,该方言关键词识别模型141能够从争吵环境下的对话语音中识别出一些通过方言说出的危险关键词。
本实施例中,方言关键词识别模型141的结构采用了常规的神经网络模型结构(dnn),但在针对方言关键词识别模型141进行训练时,同时通过含有争吵对话的争吵语音数据以及对应各种方言的关键词语音数据,结合语音识别和关键词检测进行联合训练,使得方言关键词识别模型141能够从争吵对话中准确的识别出通过方言说出的危险关键词。
紧急措施提示输出部15用于在危险关键词识别部14识别出危险关键词时,生成并输出紧急措施采取请求从而提示需要紧急进行应对措施。
本实施例中,在争吵环境识别判定部12判定车内处于争吵环境时,就表示司机与乘客陷入口角,此时,虽然司机与乘客可能情绪较为激动,但一般还没有采取危险行为。因此争吵隐患提示输出部13会发送争吵预警提示以及争吵语音段给平台安全管理装置102,从而让网约车平台的安全管理人员听取争吵语音段,并判断是否需要进行介入。
但是,一旦危险关键词识别部14识别出危险关键词,就表示司机与乘客在陷入口角后,情况进一步的激化并说出了危险关键词,此时就表示两者可能会采取或是已经采取了危险行为。这是紧急措施提示输出部15会发送紧急措施采取请求给平台安全管理装置102,从而让网约车平台的安全管理人员立即介入,采取电话联系安抚等措施来第一时间保证乘客和司机的安全。
上述争吵判别网络1211以及方言关键词识别模型141在实际投入使用前,需要事先根据一些训练数据进行训练,即预训练,才能完成各自的识别任务。
图6是本发明实施例中预训练过程的流程图。
如图6所示,争吵判别网络1211以及方言关键词识别模型141预训练过程包括步骤s1-1至步骤s1-4,具体如下:
步骤s1-1,获取用于训练的多个正常对话时产生的正常语音数据、多个含有争吵对话的争吵语音数据以及对应于各种方言的若干个关键词语音数据。
本实施例中,正常语音数据、争吵语音数据以及关键词语音数据均有负责训练模型的训练负责人员获取。具体地:
正常语音数据以及争吵语音数据的获取方式为:训练负责人员组织一些人员模拟各种争吵场景,并进行录音得到正常语音数据以及模拟争吵语音数据。
同时,争吵语音数据还有另一种获取方式;基于正常语音数据以及模拟争吵语音数据训练出一个能够初步区分争吵语音的初始模型,并通过该初始模型从电视剧等声音中检测出可能是争吵的数据,然后再人工筛选出真实争吵的数据作为真实争吵语音数据。
关键词语音数据通过预先录音获取,即训练负责人员组织相应人员通过方言说出危险关键词并进行录音得到。
步骤s1-2,分别对每个争吵语音数据以及关键词语音数据进行预处理并形成相应的多个争吵音频以及若干个关键词音频。
本实施例中,针对每个正常语音数据、争吵语音数据以及关键词语音数据,相应的预处理操作具体为:
首先,对语音数据采用加窗,窗长25ms,窗移10ms,mfcc采用13维特征。
然后,通过预设的噪声对语音数据进行混合,从而模拟在车内采集到的语音数据。具体地,噪声分为稳态噪声(风声,发动机电机声),非稳态噪声(敲击声,开门声等等)。
最后,将处理后的音频作为正常音频数据、争吵音频数据以及关键词音频数据。
步骤s1-3,根据多个正常音频数据争吵音频数据对争吵判别网络1211进行训练。
本实施例中,在进行争吵判别网络1211的预训练时,会先根据模拟争吵语音数据所对应的正常音频数据以及争吵音频数据训练出一个初始网络;然后再根据真实争吵语音数据所对应的争吵音频对初始网络进行训练,直到网络的参数收敛后将识别效果最好的网络作为争吵判别网络1211。
通过这样的方式,能够使得争吵判别网络1211直接根据音频数据识别出其中的对话是否处于争吵状态,而不需要识别出对话的具体内容。
步骤s1-4,根据多个争吵音频以及若干个关键词音频对方言关键词识别模型进行联合训练。
本实施例中,关键词识别模型训练部19在进行方言关键词识别模型141的预训练时,联合争吵音频与关键词音频一起对初始模型(该初始模型为常规的dnn模型)进行训练,并在初始模型的参数收敛后将识别效果最好的初始模型作为方言关键词识别模型。这样的方式可以使得方言关键词识别模型准确地从争吵语音段中识别出带方言的危险关键词。
训练语音存储部16存储有争吵环境识别判定部12识别出的争吵语音段、以及与危险关键词识别部14识别出的危险关键词相对应的危险关键词语音段。
在本实施例中,每当争吵环境识别判定部12识别出争吵语音段以及危险关键词识别部14识别出危险关键词时,训练语音存储部16就会根据争吵语音段以及危险关键词将相应的语音作为争吵语音数据以及关键词语音数据进行对应存储。此时,在网约车安全监测装置101长期使用后,就可以定期根据训练语音存储部16中存储的争吵语音段以及危险关键词语音段对争吵判别网络1211以及方言关键词识别模型141进行优化训练,从而实现对这两个模型的迭代优化。
装置通信部17用于进行网约车安全监测装置101与平台安全管理装置102之间的数据通信。具体地,本实施例中,装置通信部17能够在争吵隐患提示输出部13以及紧急措施提示输出部15输出争吵预警提示、紧急措施采取请求和争吵语音段时,将其发送给平台安全管理装置102。
平台安全管理装置102用于接收网约车安全监测装置101发送的。该平台安全管理装置由网约车的服务平台所持有,包括平台服务器21以及多个由安全管理人员持有的安全管理终端22。
平台服务器21为网约车平台持有的服务器,通过通信网络4与各个网约车安全监测装置101进行通信,并通过平台内部的局域网与各个安全管理终端22进行通信。
本实施例中,平台服务器21在接收到网约车安全监测装置101发送的争吵预警提示、紧急措施采取请求和争吵语音段时,会发送给相应的安全管理终端让安全管理人员进行处理。
安全管理终端22为客服的个人计算机。本实施例中,安全管理人员为网约车平台的客服,该客服通过安全管理终端22确认以及听取争吵预警提示、紧急措施采取请求和争吵语音段,从而实现对网约车安全的安全监控以及管理。
图7是本发明实施例中安全管理终端的结构框图。
如图7所示,安全管理终端22具有争吵语音暂存部221、画面存储部222、输入显示部223、终端通信部224以及终端控制部225。
争吵语音暂存部221用于在终端通信部224接收到争吵预警提示和争吵语音段时,对该争吵预警提示和争吵语音段进行暂存。本实施例中,由于争吵预警提示仅表示网约车的司机乘客处于争执,安全管理人员需要听取争吵语音段并判断是否需要介入。而该听取行为需要花费一定时间,因此争吵语音暂存部221能够暂存争吵语音段并保证安全管理人员有足够的时间进行听取以及处理这些并不是非常紧急的争吵预警提示。
画面存储部221中存储有网约车安全监控画面。
网约车安全监控画面用于在安全管理终端22启动时显示,并在该画面中显示争吵语音暂存部221中暂存的所有争吵预警提示和争吵语音段让安全管理人员进行处理。
本实施例中,一旦安全管理人员确认完一个争吵预警提示和对应的争吵语音段,争吵语音暂存部221中就相应的进行删除。另外,在实际应用中,删除的争吵预警提示和对应的争吵语音段也可以通过一个专门的数据库进行存储,从而便于网约车平台进行追溯。
另外,一旦安全管理终端22接收到紧急措施采取请求,网约车安全监控画面中就会弹出提示框让安全管理人员第一时间联系司机以及乘客进行安抚,或是进行报警,从而避免争吵的激化并引发不良后果。
输入显示部223用于显示上述网约车安全监控画面,从而让安全管理人员通过该网约车安全监控画面完成相应的人机交互。
终端通信部224用于进行安全管理终端22与平台服务器21之间的数据通信。
图8是本发明实施例中安全监控过程的流程图。
如图8所示,在网约车安全监测装置101启动后,开始如下步骤:
步骤s2-1,音频采集部11采集车内的声音并处理为音频流,然后进入步骤s2-2;
步骤s2-2,语音端点检测单元121对步骤s2-1采集的音频流进行语音端点检测从而检测是否含有人声,若没有检测出人声则进入步骤s2-1,若检测出人声则识别出含有人声的语音音频段并进入步骤s2-3;
步骤s2-3,争吵音频识别单元122将语音音频段输入争吵判别网络进行判别并输出争吵判别结果,然后进入步骤s2-4;
步骤s2-4,争吵判断单元123在争吵判别结果判断为否时进入步骤s2-1,在争吵判别结果判断为是时将相对应的语音音频段作为争吵音频段并进入步骤s2-5;
步骤s2-5,争吵隐患提示输出部13生成争吵预警提示并与争吵语音输出给平台安全管理装置102,然后进入步骤s2-6;
步骤s2-6,危险关键词识别部14将步骤s2-4识别出的争吵语音段输入方言关键词识别模型进行识别从而判断争吵语音段中是否出现有预定的危险关键词,若识别出危险关键词则进入步骤s2-7,若未是识别出则进入步骤s2-1;
步骤s2-7,紧急措施提示输出部15生成紧急措施采取请求并输出给平台安全管理装置102让安全管理人员紧急采取应对措施,然后进入步骤s2-1。
本实施例中,上述安全监控过程会在网约车安全监测装置启动后不断的循环执行。
实施例作用与效果
根据本实施例提供的网约车安全监测装置及系统,由于具有争吵环境识别判定部以及争吵隐患提示输出部,在音频采集部在采集到网约车内声音的音频流后,可以基于预先根据争吵语音训练出的争吵判别模型,通过声学原理直接从音频流识别出由争吵产生的争吵语音段,因此实现了对车内是否处于争吵环境的判别,并在司机与乘客发生争吵时提示相应的负责人员可能需要进行干预,通过这样的方式,可以在不对司机乘客的对话进行识别的基础上,仅通过对话的语气和音量就判断出司机乘客之间是否存在发生危险可能性。
进一步,由于还具有危险关键词识别部以及紧急措施提示输出部,在识别出争吵语音后,可以在争吵语音识别是否存在有通过方言说出的危险关键词,并在识别出后发出紧急措施采取请求给负责人员立即进行干预,因此,即使因为司机乘客的争吵时不自觉的使用了方言,也能够准确地识别出对话中是否出现有预先设好的危险关键词,并在识别出这些关键词认定司机与乘客的矛盾激化,第一时间通知负责人员采取紧急措施。通过本发明这样先判断争吵再识别方言关键词的方法,可以准确、且及时地在司机乘客动手之前就发现可能发生危险,及时通知负责人员进行干预,保障乘客与司机的安全。
另外,实施例中,由于争吵环境检测部包括语音端点检测单元,因此进行争吵环境的识别前,可以对音频流的人声进行检测,并仅在检测到人声时进行争吵环境的识别,因此,可以避免争吵环境检测部对不含有人声的环境语音进行识别,节省争吵环境检测部所需要的计算资源。
另外,实施例中,由于关键词识别模型通过争吵语音数据以及对应于各种方言的关键词语音数据进行联合训练,因此使得关键词识别模型可以准确的从各类杂乱的争吵语音中,准确地识别出通过方言说出的关键词,保证本发明在司机乘客争吵时,能够有效地完成危险关键词的判断,最终保证司机乘客的安全。
另外,实施例中,由于在训练关键词识别模型以及争吵判别网络之前,还通过各种噪声对争吵语音数据以及关键词语音数据进行混合,从而能够模拟实际在车辆中采集到的音频数据,保证在实际应用时,训练关键词识别模型以及争吵判别网络能够准确的完成识别以及判别任务。
另外,实施例中,由于通过训练语音存储部对识别出的争吵音频段以及危险关键词所对应的语音进行对应存储,因此在本发明投入实际使用后,也能够不断的采集实际的争吵数据,并在一定时间后基于这些数据再次对训练关键词识别模型以及争吵判别网络进行优化训练,从而使得本发明的识别效果能够越来越准确。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
例如,在上述实施例中,平台安全管理装置包括平台服务器以及相应的安全管理终端,紧急措施采取请求被输出给网约车平台的客服并且所采取的应对措施是让客服及时沟通司机乘客进行安抚。在本发明的其他方案中,应对措施还可以采用其他方案,例如平台安全管理装置可以是警察局的报案系统,紧急措施采取请求直接被输出给警察从而进行报警;或者平台安全管理装置也可以为设置在网约车上的警报器,在接收到紧急措施采取请求时会发出巨大声响提醒周边的车主与行人让其进行制止等。
例如,在上述实施例中,网约车检测装置为一个固设在车内的音频采集装置。在本发明的其他方案中,网约车检测装置还可以是乘客或是司机的手机,用于进行识别判断的各个部件可以打包成相应的程序并作为接单和下单app的一部分装载在手机中,通过手机的麦克风采集语音并完成相应的计算处理。通过这样的方式,无论乘客还是司机的某一方故意关闭手机,另一方的手机也能够正常工作并能够及时发出紧急措施采取请求。
例如,在上述实施例中,训练语音存储部、预处理部、争吵判别网络训练部、关键词识别模型训练部均设置在网约车安全检测装置中。在本发明的其他方案中,这些训练相关的部件也可以设置在一个与网约车安全检测装置通信连接的模型管理服务器中,并在完成模型的训练后将相应的模型发送给网约车安全检测装置进行更新。
例如,在上述实施例中,训练语音存储部存储在网约车安全检测装置中。在本发明的其他方案中,该训练语音存储部也可以设置在平台服务器中,通过平台服务器定期根据训练语音存储部存储的数据对训练关键词识别模型以及争吵判别网络进行优化训练,并在优化训练后将优化后的模型发送给各个网约车安全检测装置进行更新。
例如,在上述实施例中,仅根据含有人声的语音音频段判别车内的争吵环境,并且根据争吵语音段进行针对方言的预警关键词识别。在实际应用时,网约车安全检测装置也能够同时采用一般的语音识别技术对语音音频段进行关键词识别或是情绪识别,从而保证在司机与乘客未发生争吵时的安全监控效果。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



